Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Afficher l’activité détaillée du service et l’état opérationnel à l’aide de la page de détails du service
Lorsque vous instrumentez votre application, Amazon CloudWatch Application Signals cartographie tous les services découverts par votre application. Utilisez la page de détails du service pour obtenir une vue d’ensemble de vos services, opérations, dépendances, canaries et requêtes client pour un service unique. Pour afficher la page de détails du service, procédez comme suit :
-
Ouvrez la CloudWatch console
. -
Sélectionnez Services dans la section Vigie applicative CloudWatch du volet de navigation.
-
Sélectionnez le nom d’un service dans Services, Principaux services ou les tableaux de dépendances.
Sous schedule-visits, vous verrez le libellé et l’ID de compte sous le nom du service.
La page de détails du service est organisée en plusieurs onglets :
-
Vue d’ensemble : utilisez cet onglet pour obtenir une vue d’ensemble d’un service unique, y compris le nombre d’opérations, de dépendances, de synthétiques et de pages client. Cet onglet affiche les métriques clés pour l’ensemble de votre service, les opérations principales et les dépendances. Ces métriques comprennent des données de séries temporelles sur la latence, les défaillances et les erreurs pour toutes les opérations de service de ce service.
-
Opérations de service : utilisez cet onglet pour afficher la liste des opérations appelées par votre service et des graphiques interactifs avec les métriques clés qui évaluent l’état de chaque opération. Vous pouvez sélectionner un point de données dans un graphique pour obtenir des informations sur les traces, les journaux ou les métriques associées à ce point de données.
-
Dépendances : utilisez cet onglet pour afficher la liste des dépendances appelées par votre service, ainsi que la liste des indicateurs pour ces dépendances.
-
Canaries synthétiques : utilisez cet onglet pour afficher la liste des canaries synthétiques qui simulent les appels des utilisateurs vers votre service, ainsi que les indicateurs de performance clés pour ces canaries.
-
Pages client : utilisez cet onglet pour afficher la liste des pages client qui appellent votre service, ainsi que les métriques qui mesurent la qualité des interactions des clients avec votre application.
-
Métriques associées : utilisez cet onglet pour corréler les métriques associées, telles que les métriques standard, les métriques d’exécution et les métriques personnalisées pour un service, ses opérations ou ses dépendances.
Afficher la vue d’ensemble de votre service
Utilisez la page de vue d’ensemble du service pour afficher un résumé général des métriques de toutes les opérations du service en un seul endroit. Vérifiez les performances de toutes les opérations, dépendances, pages client et canaries synthétiques qui interagissent avec votre application. Utilisez ces informations pour déterminer où concentrer vos efforts afin d’identifier les problèmes, de résoudre les erreurs et de trouver des opportunités d’optimisation.
Sélectionnez n’importe quel lien dans Détails du service pour afficher les informations relatives à un service spécifique. Par exemple, pour les services hébergés dans Amazon EKS, la page de détails du service affiche les informations relatives au Cluster, à l’Espace de noms et à la Charge de travail. Pour les services hébergés dans Amazon ECS ou Amazon EC2, la page Détails du service affiche la valeur Environnement.
Sous Services, l’onglet Vue d’ensemble affiche un résumé des éléments suivants :
-
Opérations : utilisez cet onglet pour voir l’état de santé de vos opérations de service. L’état de santé est déterminé par des indicateurs de niveau de service (SLI) définis dans le cadre d’un objectif de niveau de service (SLO).
-
Dépendances : utilisez cet onglet pour consulter les principales dépendances des services appelés par votre application, classées par taux de défaillance, et pour vérifier l’état de santé de vos dépendances de service. L’état de santé est déterminé par des indicateurs de niveau de service (SLI) définis dans le cadre d’un objectif de niveau de service (SLO).
-
Canaries synthétiques : utilisez cet onglet pour consulter le résultat des appels simulés vers les points de terminaison ou les API associés à votre service, ainsi que le nombre de canaries ayant échoué.
-
Pages client : utilisez cet onglet pour voir les principales pages appelées par des clients présentant des erreurs asynchrones JavaScript et XML (AJAX).
L’illustration suivante présente une vue d’ensemble de vos services :

L’onglet Vue d’ensemble affiche également un graphique des dépendances présentant la latence la plus élevée parmi tous les services. Utilisez les métriques de latence p99, p90 et p50 pour évaluer rapidement quelles dépendances contribuent à la latence totale de votre service, comme suit :

Par exemple, le graphique précédent montre que 99 % des requêtes adressées à la dépendance customer-service ont été traitées en environ 4 950 millisecondes. Les autres dépendances ont pris moins de temps.
Les graphiques affichant les quatre principales opérations de service par latence indiquent le volume de requêtes, la disponibilité, le taux de défaillance et le taux d’erreur pour ces services, comme illustré dans l’image suivante :
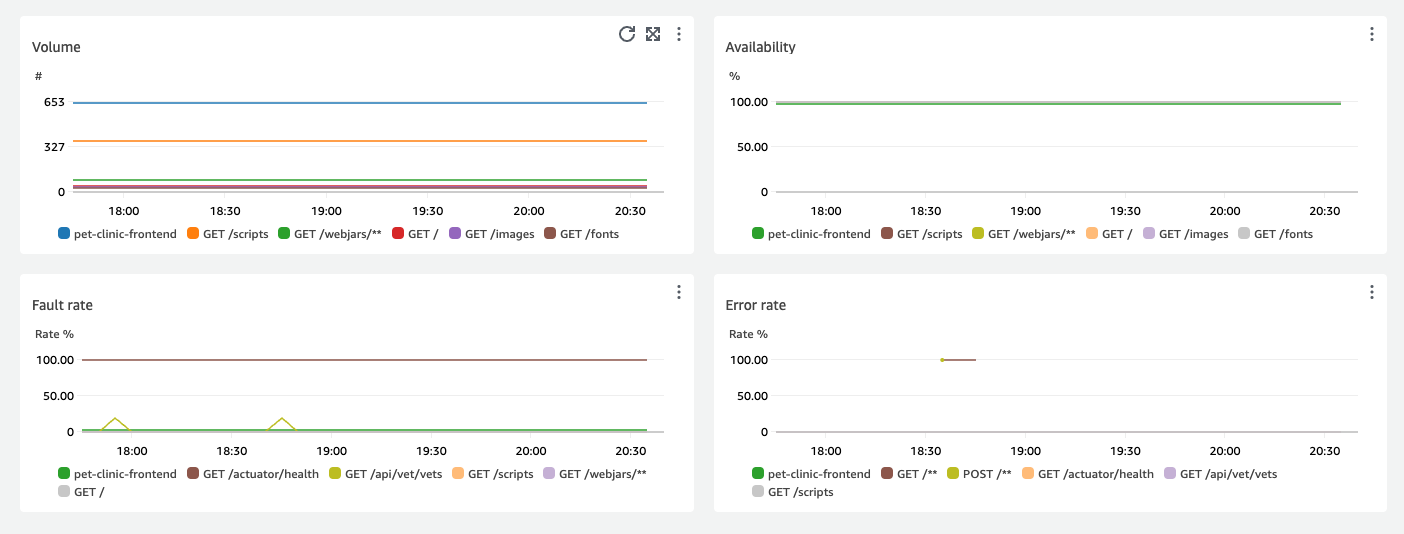
La section Détails du service affiche les détails du service, y compris l’ID de compte et le Libellé du compte.
Affichage de vos opérations de service
Lorsque vous instrumentalisez votre application, la vigie applicative détecte toutes les opérations de service appelées par votre application. Utilisez l’onglet Opérations de service pour afficher un tableau contenant les opérations de service et un ensemble de métriques qui mesurent les performances d’une opération sélectionnée. Ces métriques comprennent le statut SLI, le nombre de dépendances, la latence, le volume, les défaillances, les erreurs et la disponibilité, comme illustré dans l’image suivante :
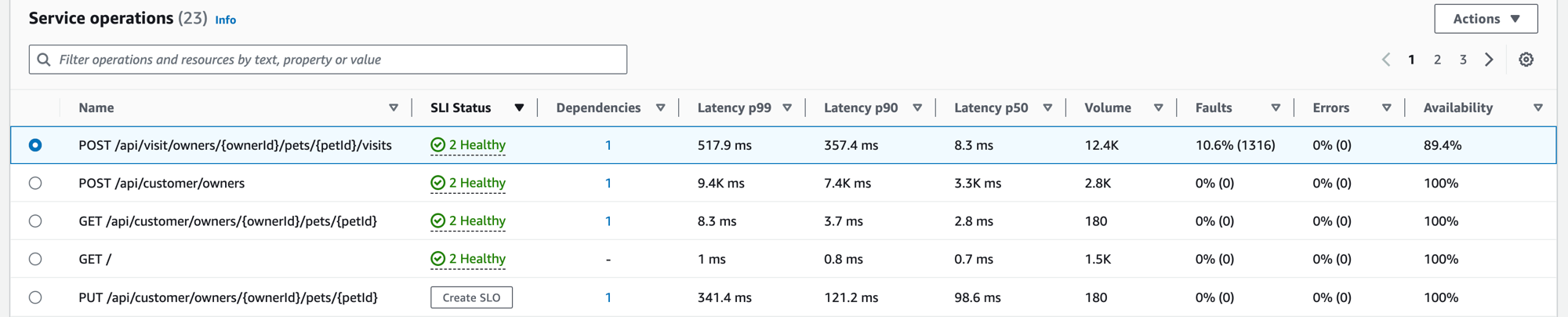
Filtrez le tableau pour faciliter la recherche d’une opération de service en sélectionnant une ou plusieurs propriétés dans la zone de texte du filtre. Au fur et à mesure que vous choisissez chaque propriété, vous êtes guidé à travers les critères de filtrage et vous verrez le filtre complet sous la zone de texte du filtre. Choisissez Effacer les filtres à tout moment pour supprimer le filtre du tableau.
Sélectionnez le statut SLI d’une opération pour afficher une fenêtre contextuelle contenant un lien vers tout SLI défaillant et un lien permettant de voir tous les SLO de l’opération, comme illustré dans le tableau suivant :
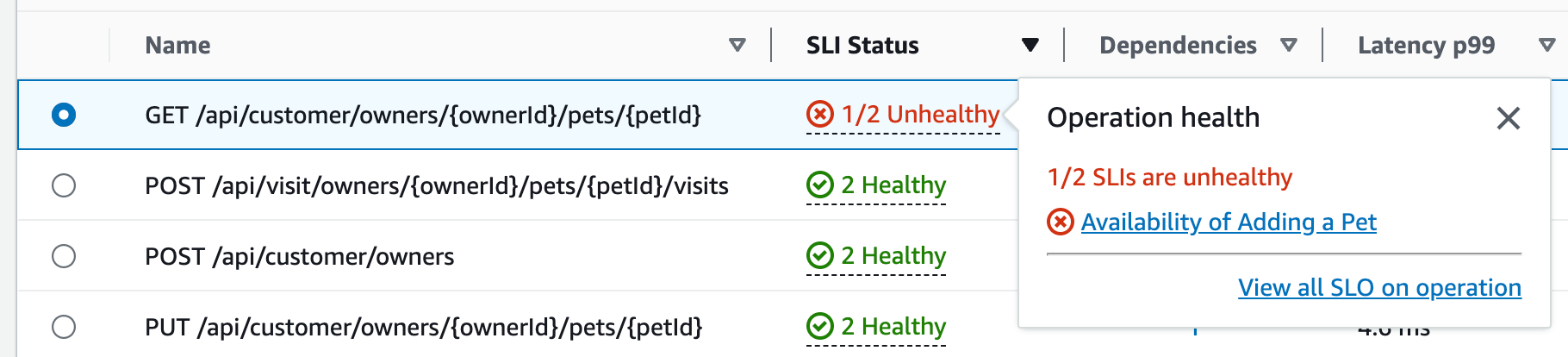
Le tableau des opérations de service répertorie le statut SLI, le nombre de SLI fonctionnels ou défaillants et le nombre total de SLO pour chaque opération.
Utilisez les SLI pour surveiller la latence, la disponibilité et d’autres métriques opérationnelles qui mesurent la santé opérationnelle d’un service. Utilisez un SLO pour vérifier les performances et l’état de vos services et opérations.
Pour créer un SLO, procédez comme suit :
-
Si une opération ne dispose pas d’un SLO, sélectionnez le bouton Créer un SLO dans la colonne Statut SLI.
-
Si une opération dispose déjà d’un SLO, procédez comme suit :
-
Sélectionnez le bouton radio à côté du nom de l’opération.
-
Sélectionnez Créer un SLO dans la liste déroulante Actions en haut à droite du tableau.
-
Pour plus d’informations, veuillez consulter la rubrique Objectifs de niveau de service (SLO).
La colonne Dépendances indique le nombre de dépendances appelées par cette opération. Choisissez ce numéro pour ouvrir l’onglet Dépendances filtré en fonction de l’opération sélectionnée.
Afficher les métriques des opérations de service, les traces corrélées et les journaux d’application
Application Signals met en corrélation les indicateurs de fonctionnement des services avec les AWS X-Ray traces, CloudWatch Container Insights et les journaux des applications. Utilisez ces métriques pour résoudre les problèmes d’état opérationnels. Pour afficher les métriques sous forme d’informations graphiques, procédez comme suit :
-
Sélectionnez une opération de service dans le tableau Opérations de service pour afficher un ensemble de graphiques pour l’opération sélectionnée au-dessus du tableau avec les métriques pour le Volume et la disponibilité, la Latence et les Défaillances et erreurs.
-
Passez la souris sur un point du graphique pour afficher plus d’informations.
-
Sélectionnez un point pour ouvrir un volet de diagnostic qui affiche les traces, les métriques et les journaux d’application corrélés pour le point sélectionné dans le graphique.
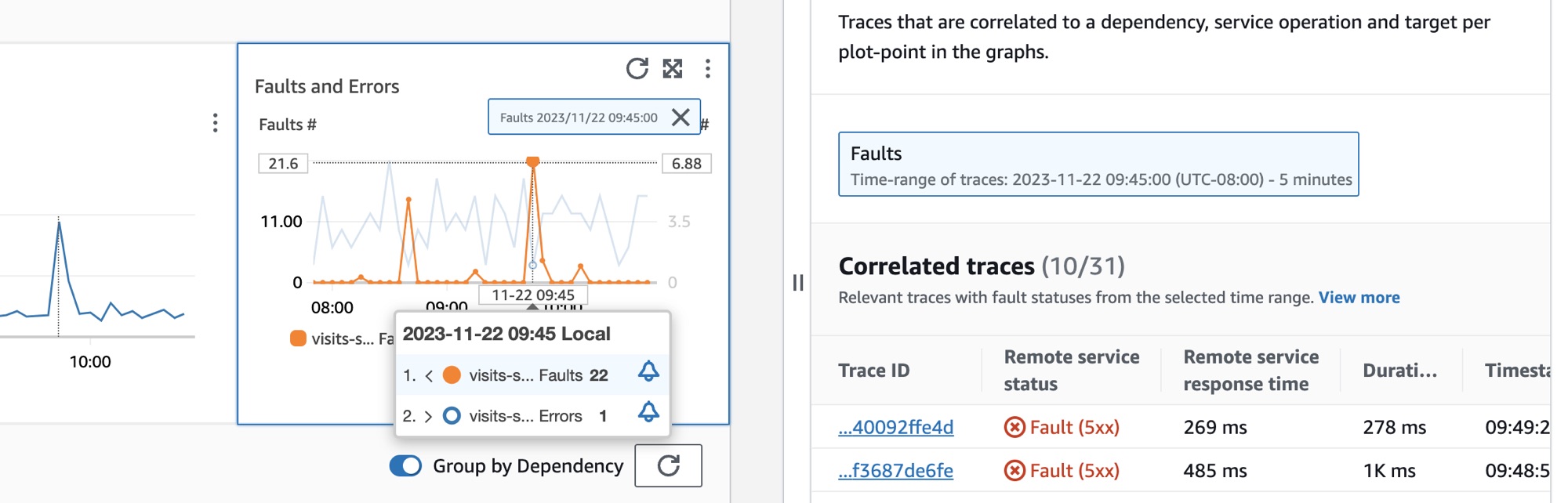
L’image suivante montre l’info-bulle qui apparaît lorsque vous survolez un point du graphique et le volet de diagnostic qui apparaît lorsque vous cliquez sur un point. L’info-bulle contient des informations sur le point de données associé dans le graphique Défaillances et erreurs. Le volet contient les Traces corrélées, les Principaux contributeurs et les Journaux d’application associés au point sélectionné.
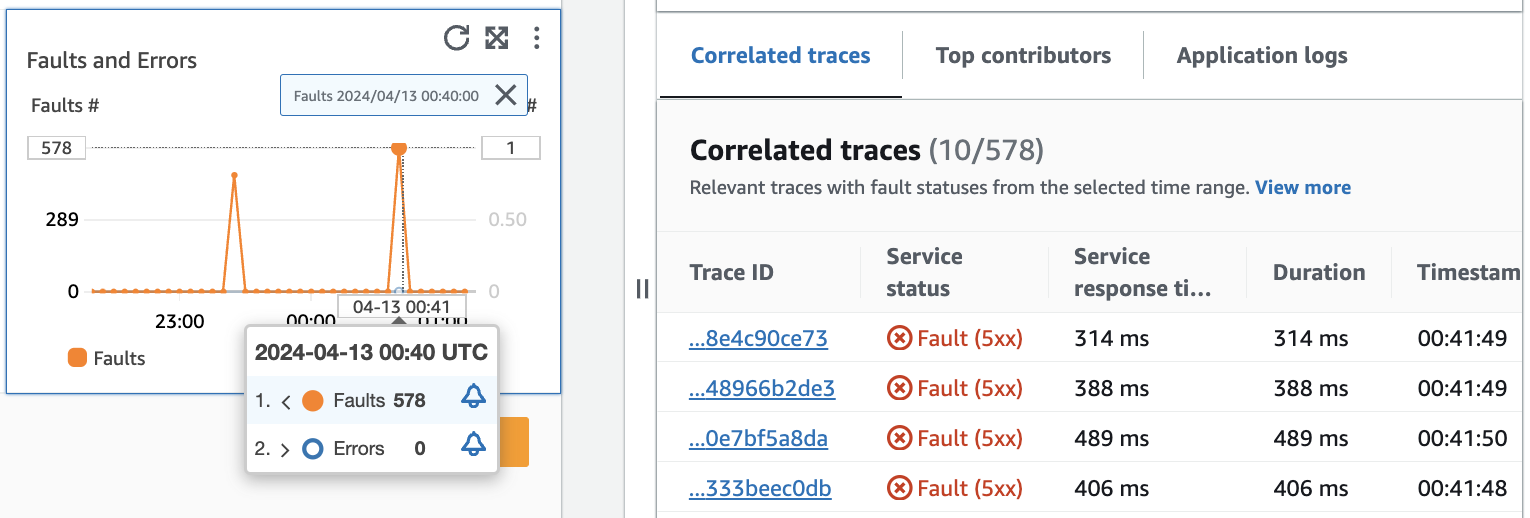
Suivis corrélés
Consultez les traces associées pour comprendre un problème sous-jacent à une trace. Vous pouvez vérifier si les traces corrélées ou les nœuds de service qui leur sont associés se comportent de manière similaire. Pour examiner les traces corrélées, choisissez un ID de trace dans le tableau des traces corrélées pour ouvrir la page des détails de la X-Ray trace sélectionnée. La page des détails de la trace contient une carte des nœuds de service associés à la trace sélectionnée et une chronologie des segments de trace.
Principaux contributeurs
Affichez les principaux contributeurs pour trouver les principales sources d’entrée d’une métrique. Regroupez les contributeurs par composants différents pour rechercher des similitudes au sein du groupe et comprendre comment le comportement des traces diffère entre eux.
L’onglet Principaux contributeurs fournit des métriques pour le Volume d’appels, la Disponibilité, la Latence moyenne, les Erreurs et les Défaillances pour chaque groupe. L’image suivante montre les principaux contributeurs à un ensemble de métriques pour une application déployée sur une plateforme Amazon EKS :
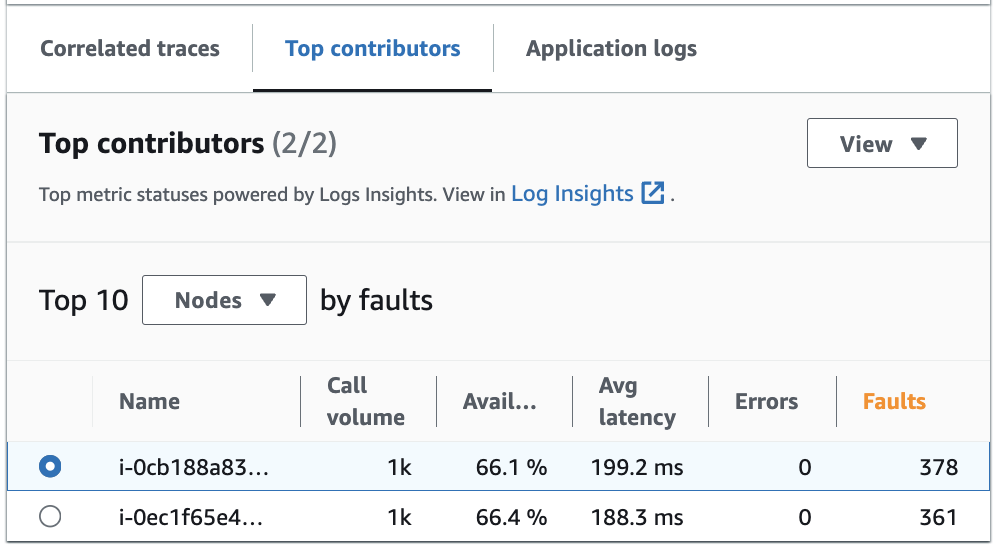
Les principaux contributeurs comprennent les métriques suivantes :
-
Volume d’appels : utilisez le volume d’appels pour comprendre le nombre de requêtes par intervalle de temps pour un groupe.
-
Disponibilité : utilisez la disponibilité pour voir le pourcentage de temps pendant lequel aucune défaillance n’a été détectée pour un groupe.
-
Latence moyenne : utilisez la latence pour vérifier le temps moyen d’exécution des requêtes pour un groupe sur un intervalle de temps qui dépend de la date à laquelle les requêtes que vous examinez ont été effectuées. Les requêtes effectuées il y a moins de 15 jours sont évaluées par intervalles d’une minute. Les requêtes effectuées entre 15 et 30 jours auparavant, inclusivement, sont évaluées par intervalles de 5 minutes. Par exemple, si vous examinez les requêtes qui ont causé une défaillance il y a 15 jours, la métrique du volume d’appels est égale au nombre de requêtes par intervalle de 5 minutes.
-
Erreurs : nombre d’erreurs par groupe mesuré sur un intervalle de temps.
-
Défaillances : nombre de défaillances par groupe sur un intervalle de temps.
Principaux contributeurs utilisant Amazon EKS ou Kubernetes
Utilisez les informations sur les principaux contributeurs aux applications déployées sur Amazon EKS ou Kubernetes pour consulter les indicateurs de santé opérationnelle regroupés par nœud, pod et PodTemplateHash. Les définitions suivantes s’appliquent :
-
Un pod est un groupe d’un ou plusieurs conteneurs Docker qui partagent du stockage et des ressources. Un pod est la plus petite unité pouvant être déployée sur une plateforme Kubernetes. Regroupez par pods pour vérifier si les erreurs sont liées à des limitations spécifiques aux pods.
-
Un nœud est un serveur qui exécute des pods. Regroupez par nœuds pour vérifier si les erreurs sont liées à des limitations spécifiques aux nœuds.
-
Un hachage de modèle de pod est utilisé pour trouver une version particulière d’un déploiement. Regroupez par hachage de modèle de pod pour vérifier si les erreurs sont liées à un déploiement particulier.
Principaux contributeurs utilisant Amazon EC2
Utilisez les informations sur les principaux contributeurs pour les applications déployées sur Amazon EKS afin de consulter les métriques de santé opérationnelle regroupées par ID d’instance et groupe Auto Scaling. Les définitions suivantes s’appliquent :
-
Un ID d’instance est un identifiant unique pour l’instance Amazon EC2 sur laquelle votre service s’exécute. Regroupez par ID d’instance pour vérifier si les erreurs sont liées à une instance Amazon EC2 spécifique.
-
Un groupe Auto Scaling est un ensemble d’instances Amazon EC2 qui vous permet d’augmenter ou de réduire les ressources dont vous avez besoin pour répondre aux requêtes de votre application. Regroupez par groupe Auto Scaling si vous voulez vérifier si les erreurs sont limitées aux instances du groupe.
Principaux contributeurs utilisant une plateforme personnalisée
Utilisez les informations sur les principaux contributeurs pour les applications déployées à l’aide d’instruments personnalisés afin de consulter les métriques d’état opérationnelles regroupées par Nom d’hôte. Les définitions suivantes s’appliquent :
-
Un nom d’hôte identifie un appareil tel qu’un point de terminaison ou une instance Amazon EC2 connecté à un réseau. Regroupez par nom d’hôte pour vérifier si vos erreurs sont liées à un appareil physique ou virtuel spécifique.
Afficher les principaux contributeurs dans Log Insights et Container Insights
Affichez et modifiez la requête automatique qui a généré les métriques pour vos principaux contributeurs dans Log Insights. Affichez les métriques de performances de l’infrastructure par groupes spécifiques tels que les pods ou les nœuds dans Container Insights. Vous pouvez trier les clusters, les nœuds ou les charges de travail par consommation de ressources et identifier rapidement les anomalies ou atténuer les risques de manière proactive avant que l’expérience de l’utilisateur final ne soit affectée. Une image illustrant la manière de sélectionner ces options est fournie ci-dessous :
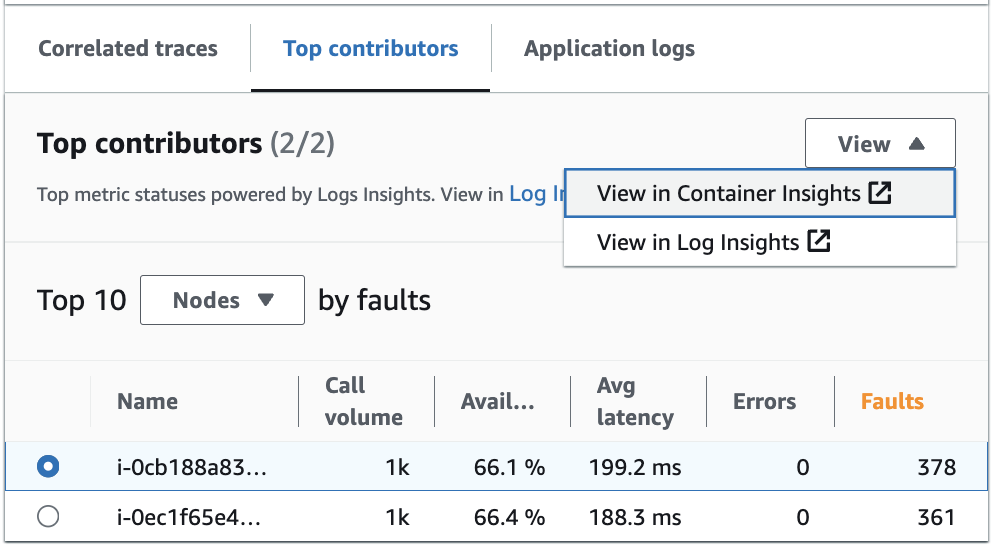
Dans Informations sur le conteneur, vous pouvez afficher les métriques de votre conteneur Amazon EKS ou Amazon ECS qui sont spécifiques au regroupement de vos principaux contributeurs. Par exemple, si vous avez regroupé par pod pour un conteneur EKS afin de générer les principaux contributeurs, Container Insights affichera les métriques et les statistiques filtrées pour votre pod.
Dans Informations sur le journal, vous pouvez modifier la requête qui a généré les métriques sous Principaux contributeurs en suivant les étapes suivantes :
-
Sélectionnez Afficher dans Log Insights. La page Informations sur le journal qui s’ouvre contient une requête générée automatiquement et comprend les informations suivantes :
-
Le nom du groupe de cluster de journaux.
-
L'opération sur laquelle vous enquêtiez CloudWatch.
-
L’agrégat de la métrique d’état opérationnelle avec laquelle vous avez interagi sur le graphique.
Les résultats du journal sont automatiquement filtrés pour afficher les données des cinq dernières minutes avant que vous n’ayez sélectionné le point de données sur le graphique du service.
-
-
Pour modifier la requête, remplacez le texte généré par vos modifications. Vous pouvez également utiliser le Générateur de requêtes pour vous aider à générer une nouvelle requête ou à mettre à jour la requête existante.
Journaux d'application
Utilisez la requête dans l’onglet Journaux d’application pour générer des informations enregistrées pour votre groupe de journaux, votre service actuel et insérer un horodatage. Un groupe de journaux est un ensemble de flux de journaux que vous pouvez définir lors de la configuration de votre application.
Utilisez un groupe de journaux pour organiser les journaux présentant des caractéristiques similaires, notamment les suivantes :
-
Capturez les journaux d’une organisation, d’une source ou d’une fonction spécifique.
-
Capturer les journaux auxquels un utilisateur particulier a accès.
-
Capturez les journaux pour une période spécifique.
Utilisez ces flux de journaux pour suivre des groupes ou des périodes spécifiques. Vous pouvez également configurer des règles de surveillance, des alarmes et des notifications pour ces groupes de journaux. Pour plus d’informations sur les groupes de journaux, consultez Utilisation des groupes de journaux et des flux de journaux.
La requête des journaux d’application renvoie les journaux, les modèles de texte récurrents et les visualisations graphiques pour vos groupes de journaux.
Pour exécuter la requête, sélectionnez Exécuter la requête dans Logs Insights afin d’exécuter la requête générée automatiquement ou de la modifier. Pour modifier la requête, remplacez le texte généré automatiquement par vos modifications. Vous pouvez également utiliser le Générateur de requêtes pour vous aider à générer une nouvelle requête ou à mettre à jour la requête existante.
L’image suivante montre l’exemple de requête générée automatiquement en fonction du point sélectionné dans le graphique des opérations du service :
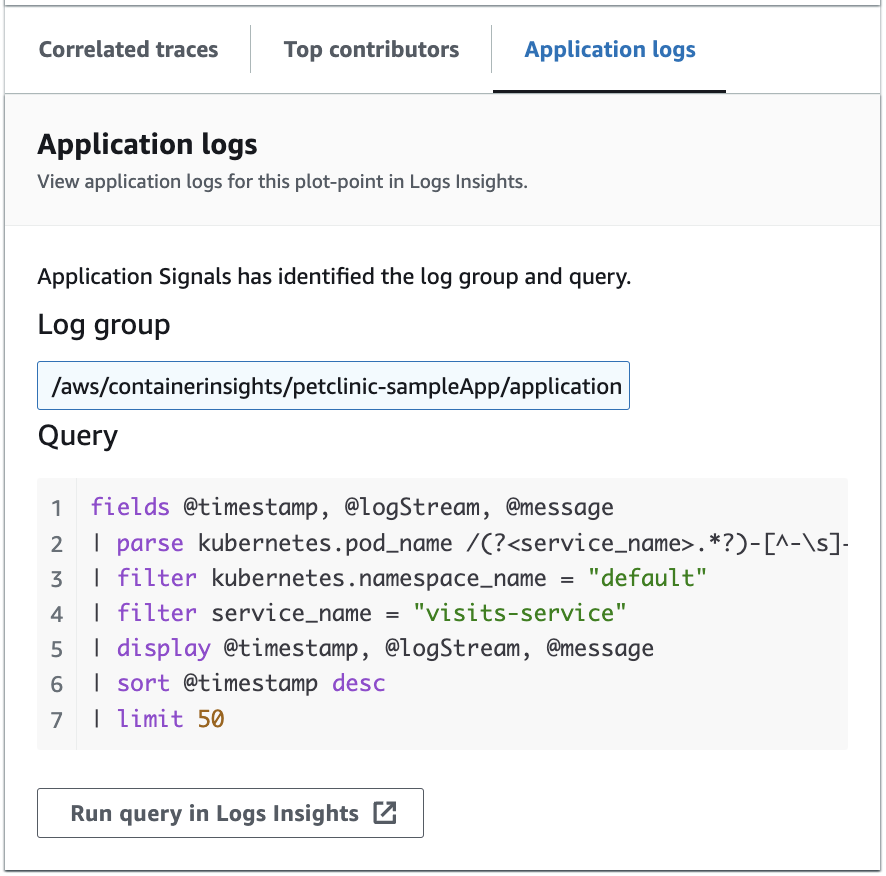
Dans l'image précédente, CloudWatch a automatiquement détecté le groupe de log associé au point sélectionné et l'a inclus dans une requête générée.
Affichage de vos dépendances de service
Choisissez l’onglet Dépendances pour afficher le tableau Dépendances et un ensemble de métriques relatives aux dépendances de toutes les opérations de service ou d’une seule opération. Le tableau contient une liste des dépendances détectées par la vigie applicative, y compris les métriques relatives au statut SLI, à la latence, au volume d’appels, au taux de défaillance, au taux d’erreur et à la disponibilité.
En haut de la page, sélectionnez une opération dans la liste déroulante pour afficher ses dépendances, ou sélectionnez Tout pour afficher les dépendances de toutes les opérations.
Filtrez le tableau pour faciliter la recherche de ce que vous recherchez en choisissant une ou plusieurs propriétés dans la zone de texte du filtre. Au fur et à mesure que vous choisissez chaque propriété, vous êtes guidé à travers les critères de filtrage et vous verrez le filtre complet sous la zone de texte du filtre. Choisissez Effacer les filtres à tout moment pour supprimer le filtre du tableau. Sélectionnez Grouper par dépendance en haut à droite du tableau pour regrouper les dépendances par nom de service et d’opération. Lorsque le regroupement est activé, développez ou réduisez un groupe de dépendances à l’aide de l’icône + à côté du nom de la dépendance.
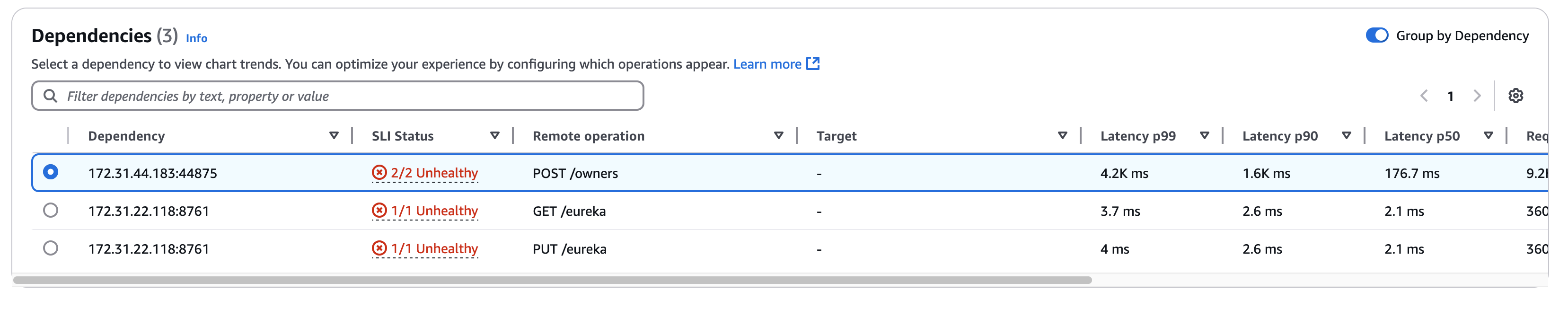
La colonne Dépendance affiche le nom du service de dépendance, tandis que la colonne Opération à distance affiche le nom de l’opération de service. La colonne Statut SLI affiche le nombre de SLI sains ou non sains ainsi que le nombre total de SLI pour chaque dépendance. Lorsque vous appelez AWS des services, la colonne Target affiche la AWS ressource, telle que la table DynamoDB ou la file d'attente Amazon SNS.
Pour sélectionner une dépendance, sélectionnez l’option située à côté d’une dépendance dans le tableau Dépendances. Cela affiche un ensemble de graphiques qui présentent des métriques détaillées pour le volume d’appels, la disponibilité, les défaillances et les erreurs. Survolez un point d’un graphique pour afficher une fenêtre contextuelle contenant plus d’informations. Sélectionnez un point dans un graphique pour ouvrir un volet de diagnostic qui affiche les traces corrélées pour le point sélectionné dans le graphique. Choisissez un ID de trace dans le tableau des traces corrélées pour ouvrir la X-Ray page des détails de la trace sélectionnée.
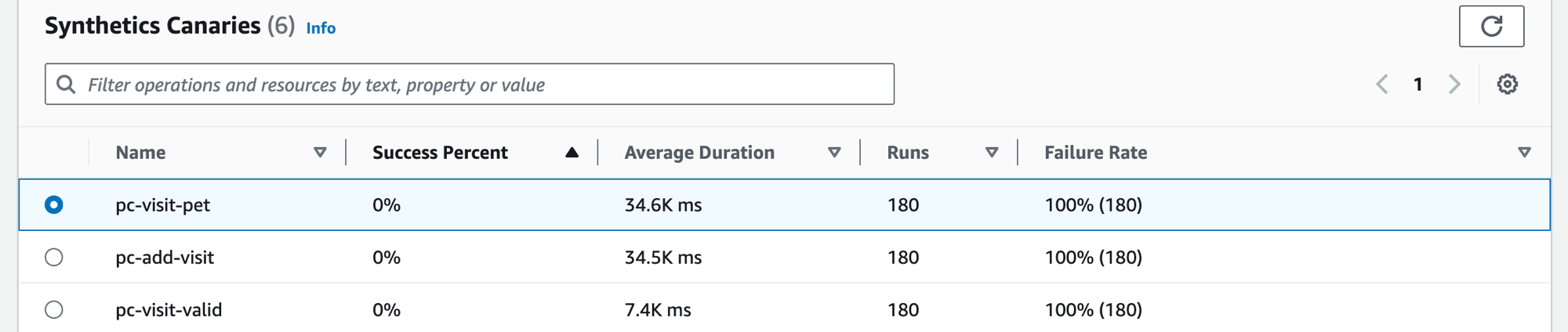
Affichage de vos scripts canary Synthetics
Choisissez l’onglet Scripts canary Synthetics pour afficher le tableau Scripts canary Synthetics et un ensemble de métriques pour chaque script canary du tableau. Le tableau inclut des mesures relatives au pourcentage de réussite, à la durée moyenne, aux cycles et au taux d’échec. Seuls les canaris dont le AWS X-Ray traçage est activé sont affichés.
Utilisez la zone de texte du filtre dans le tableau des canaris synthétiques pour trouver le canary qui vous intéresse. Chaque filtre que vous créez apparaît sous la zone de texte du filtre. Choisissez Effacer les filtres à tout moment pour supprimer le filtre du tableau.
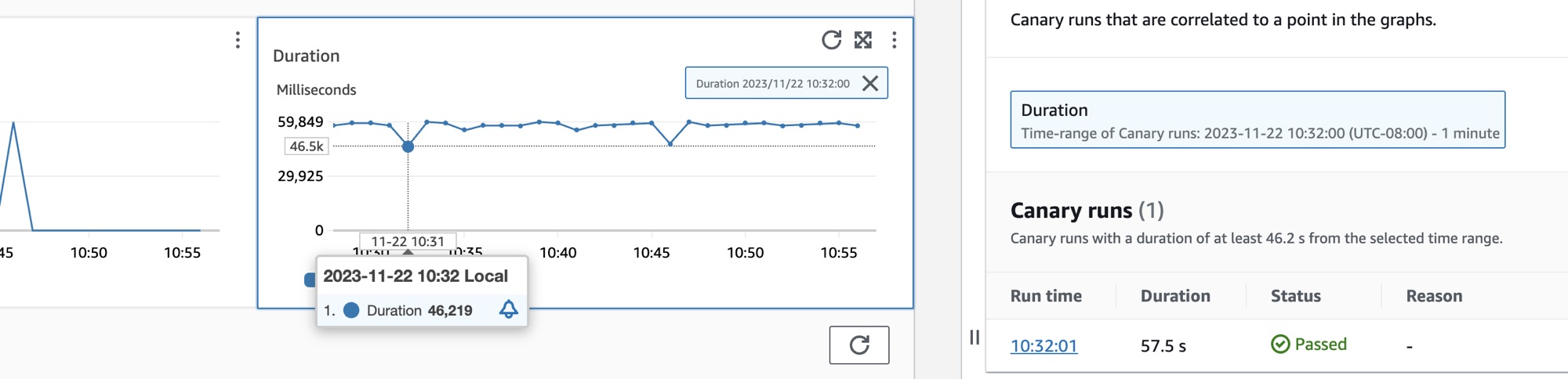
Cochez la case d’option à côté du nom du canary pour afficher un ensemble d’onglets contenant des graphiques avec des mesures détaillées, notamment le pourcentage de réussite, les erreurs et la durée. Survolez un point d’un graphique pour afficher une fenêtre contextuelle contenant plus d’informations. Sélectionnez un point dans un graphique pour ouvrir un volet de diagnostic qui affiche les exécutions de canary corrélées au point sélectionné. Sélectionnez une exécution de canary et choisissez la Durée d’exécution pour afficher les artefacts de l’exécution de canary sélectionnée, notamment les journaux, les fichiers d’archive HTTP (HAR), les captures d’écran et les suggestions pour vous aider à résoudre les problèmes. Choisissez En savoir plus pour ouvrir la page CloudWatch Synthetics Canaries à côté de Canary runs.
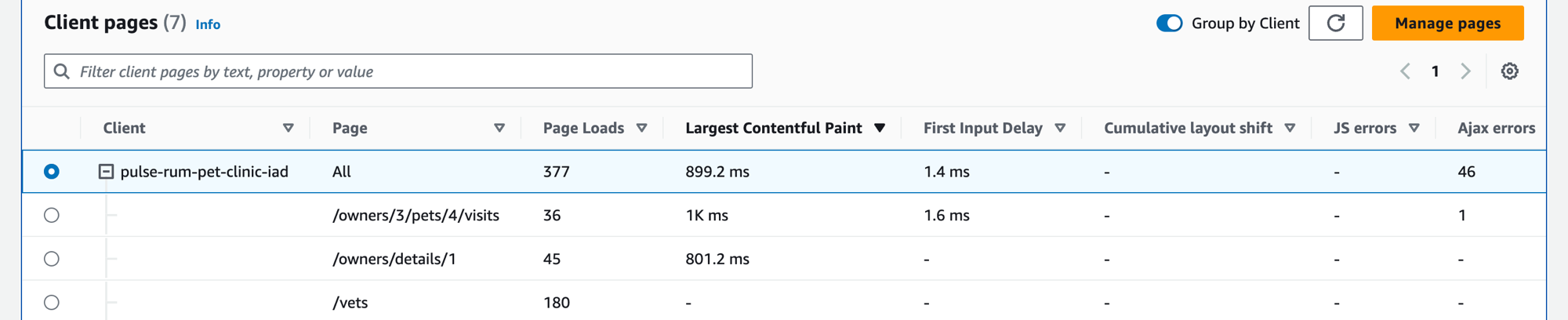
Consultation de vos pages clients
Sélectionnez l’onglet Pages client pour afficher la liste des pages Web client qui appellent votre service. Utilisez l’ensemble de métriques pour la page client sélectionnée afin d’évaluer la qualité de l’expérience de votre client lorsqu’il interagit avec un service ou une application. Ces métriques comprennent les chargements de pages, les indicateurs Web vitaux et les erreurs.
Pour afficher vos pages client dans le tableau, vous devez configurer votre client Web CloudWatch RUM pour le X-Ray suivi et activer les métriques Application Signals pour vos pages client. Sélectionnez Gérer les pages pour choisir les pages activées pour les métriques de la vigie applicative.
Utilisez la zone de texte du filtre pour rechercher la page client ou le moniteur d’application qui vous intéresse sous la zone de texte du filtre. Sélectionnez Effacer les filtres pour supprimer le filtre du tableau. Sélectionnez Grouper par client pour regrouper les pages client par client. Lorsque vous êtes groupés, cliquez sur l’icône + à côté du nom d’un client pour développer la ligne et afficher toutes les pages relatives à ce client.
Pour sélectionner une page client, sélectionnez l’option située à côté d’une page client dans le tableau Pages client. Vous verrez un ensemble de graphiques affichant des métriques détaillées. Survolez un point d’un graphique pour afficher une fenêtre contextuelle contenant plus d’informations. Sélectionnez un point dans un graphique pour ouvrir un volet de diagnostic qui affiche les événements de navigation de performances corrélés pour le point sélectionné dans le graphique. Choisissez un identifiant d'événement dans la liste des événements de navigation pour ouvrir la vue de la page CloudWatch RUM pour l'événement choisi.
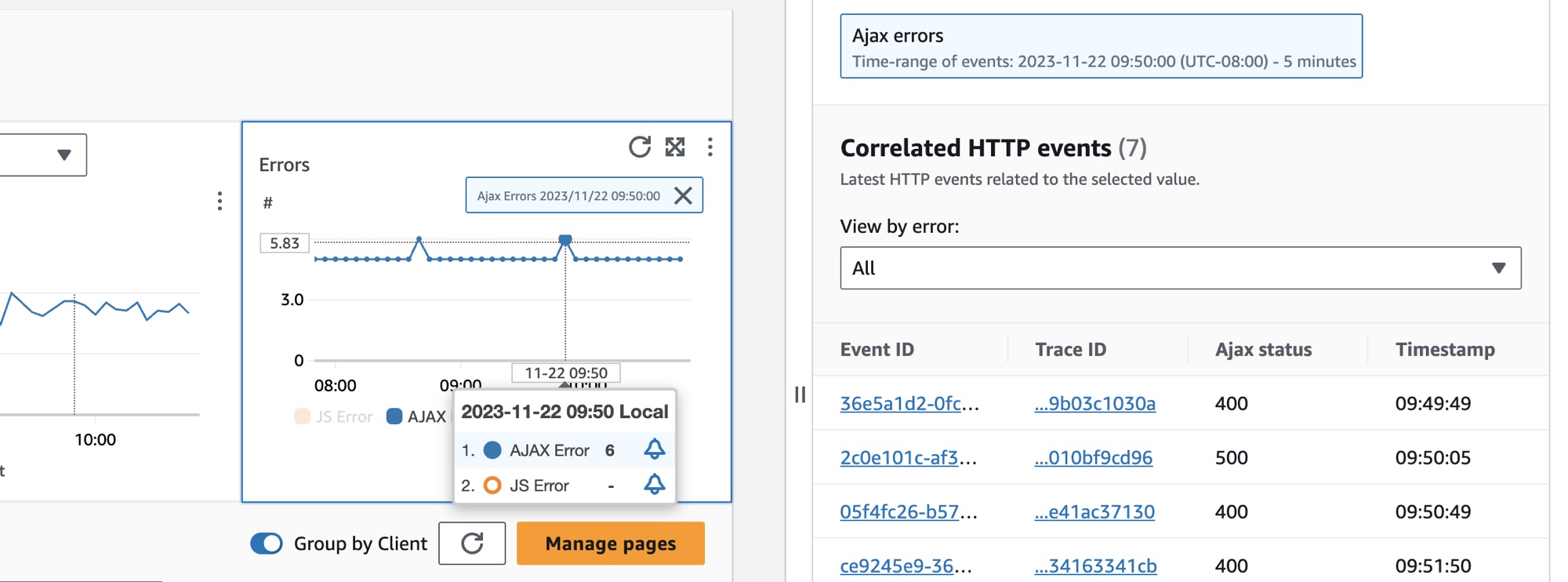
Note
Pour voir les erreurs AJAX dans vos pages client, utilisez le client Web CloudWatch RUM version 1.15 ou ultérieure.
Jusqu’à 100 opérations, canaries et pages client, ainsi que jusqu’à 250 dépendances, peuvent être affichés par service.
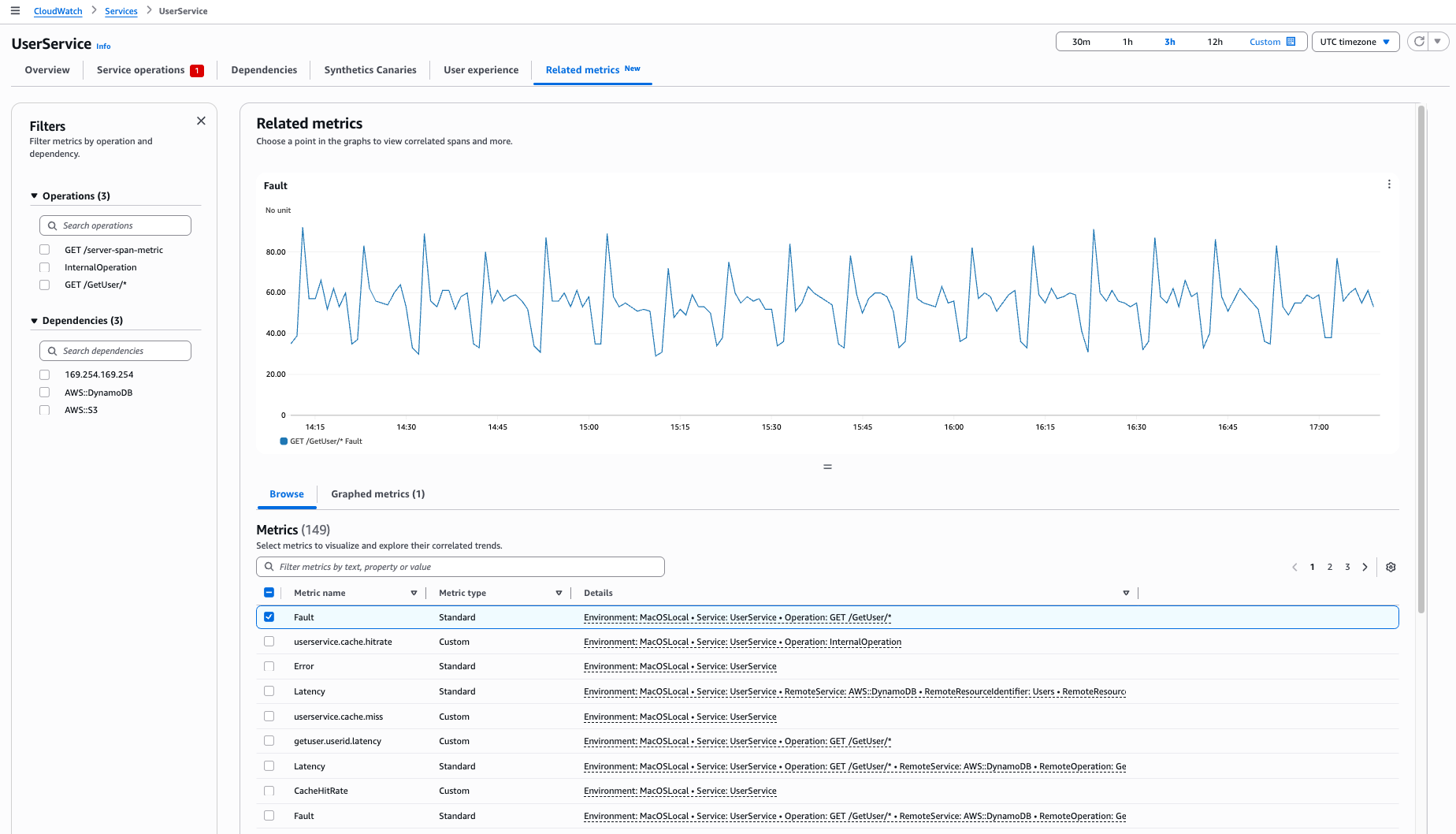
Afficher les métriques associées
Utilisez l’onglet Métriques associées pour visualiser plusieurs métriques, identifier des modèles de corrélation et déterminer une cause racine des problèmes.
Le tableau des métriques affiche trois types de métriques :
Métriques standard : la vigie applicative collecte les métriques d’application standard à partir des services qu’il détecte. Pour plus d’informations, consultez Métriques d’application standard collectées
Métriques d'exécution — Application Signals utilise le OpenTelemetry SDK AWS Distro for pour collecter automatiquement OpenTelemetry-compatible les métriques de vos applications Java et Python. Pour plus d’informations, consultez Métriques d’exécution
Métriques personnalisées : la vigie applicative vous permet de générer des métriques personnalisées à partir de votre application. Pour de plus amples informations, consultez Métriques personnalisées avec la vigie applicative.
Vous pouvez accéder à l’onglet Métriques associées à partir des onglets Vue d’ensemble du service, Opérations du service, Dépendances, Canaries synthétiques ou RUM.
-
Le volet de navigation de gauche s’ouvre avec toutes les opérations et dépendances désélectionnées
-
Le graphique affiche initialement la métrique de défaillance de l’opération présentant le taux de défaillance le plus élevé
Avant de commencer l’analyse de corrélation, assurez-vous que les points de données sont visibles dans Opérations du service ou Dépendances. Pour analyser les corrélations :
Ouvrez la page Opérations du service ou Dépendances.
Sélectionnez un point de données sur n’importe quel graphique.
Dans le volet de droite, choisissez Corrélation avec d’autres métriques.
Dans l’onglet Métriques associées qui s’ouvre, vous verrez :
L’opération ou la dépendance que vous avez sélectionnée dans le volet de navigation gauche
La métrique que vous avez sélectionnée représentée sous forme de graphique dans le tableau Parcourir les métriques
Les intervalles corrélés lorsque vous sélectionnez un point de données
Pour représenter plusieurs métriques sous forme de graphique, sélectionnez une ou plusieurs métriques dans la vue Parcourir de l’onglet Métriques associées. Choisissez Métriques représentées graphiquement pour afficher toutes les métriques représentées graphiquement.
Pour filtrer les métriques, utilisez les filtres du volet de gauche afin de vous concentrer sur des opérations ou des dépendances spécifiques, et utilisez la barre de filtrage de l’en-tête du tableau pour effectuer une recherche par nom, type ou autres attributs. Ces options de filtrage vous aident à détecter des modèles et à résoudre les problèmes plus efficacement.
Pour analyser en détail les métriques associées, sélectionnez un point de données dans l’onglet Métriques associées. Vous pouvez ensuite afficher :
Principaux contributeurs : analyse les statistiques en exécutant CloudWatch des requêtes Logs Insights. Ces requêtes traitent les enregistrements au format EMF (Enhanced Metrics Format) qui contiennent des attributs clés pour une analyse détaillée des éléments suivants :
Mesures de latence
Occurrence de défaillance
Métriques de disponibilité des services
Les métriques suivantes ne prennent pas en charge les principaux contributeurs :
Métriques OTEL
Server-side Métriques de la durée
Vous pouvez consulter les principaux contributeurs pour RED Metrics et Client-side Span Metrics.
Portées corrélées : la section Portées corrélées fonctionne de manière cohérente avec l’onglet Opérations de service. Pour vous aider à identifier les traces et les métriques associées, le mécanisme de corrélation fonctionne de la manière suivante :
Comparaison des noms de métriques avec les attributs de portée
Identification des modèles correspondants pendant la période sélectionnée
Affichage des informations de trace pertinentes
Pour analyser efficacement vos métriques et vos portées ensemble, vous devez comprendre comment les différents types de métriques sont corrélés. Voici les principales limitations :
Les métriques OTEL ne sont pas corrélées aux portées, car elles utilisent des systèmes de nommage indépendants
Pour corréler les métriques du serveur ou de l' Client-side intervalle avec les intervalles, procédez comme suit :
Inclure un champ Dimension de service dans votre configuration
Sans cette Dimension de service, vous ne pouvez pas corréler ces métriques avec les portées
Applications de journalisation : pour plus d’informations sur l’application de journalisation, consultez Journaux d’application
