Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Uso de la detección del habla tóxica
Uso de la detección del habla tóxica en una transcripción por lotes
Para utilizar la detección del habla tóxica con una transcripción por lotes, consulte los ejemplos siguientes:
-
Inicie sesión en Consola de administración de AWS
. -
En el panel de navegación, elija Trabajos de transcripción y, a continuación, seleccione Crear trabajo (arriba a la derecha). Se abrirá la página Especificar los detalles del trabajo.
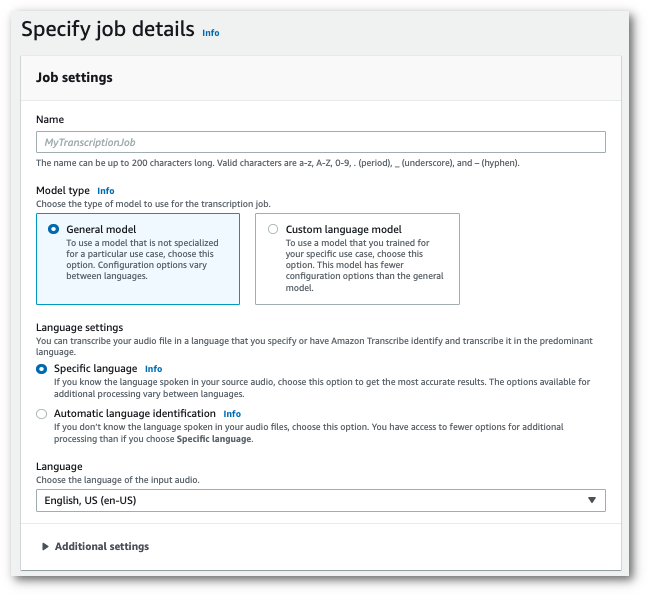
-
Si lo desea, en la página Especificar los detalles del trabajo, también puede habilitar la redacción de PII. Tenga en cuenta que las demás opciones de la lista no son compatibles con la detección de toxicidad. Seleccione Siguiente. Esto lo llevará a la página Configurar trabajo: opcional. En el panel Ajustes de audio, seleccione Detección de toxicidad.
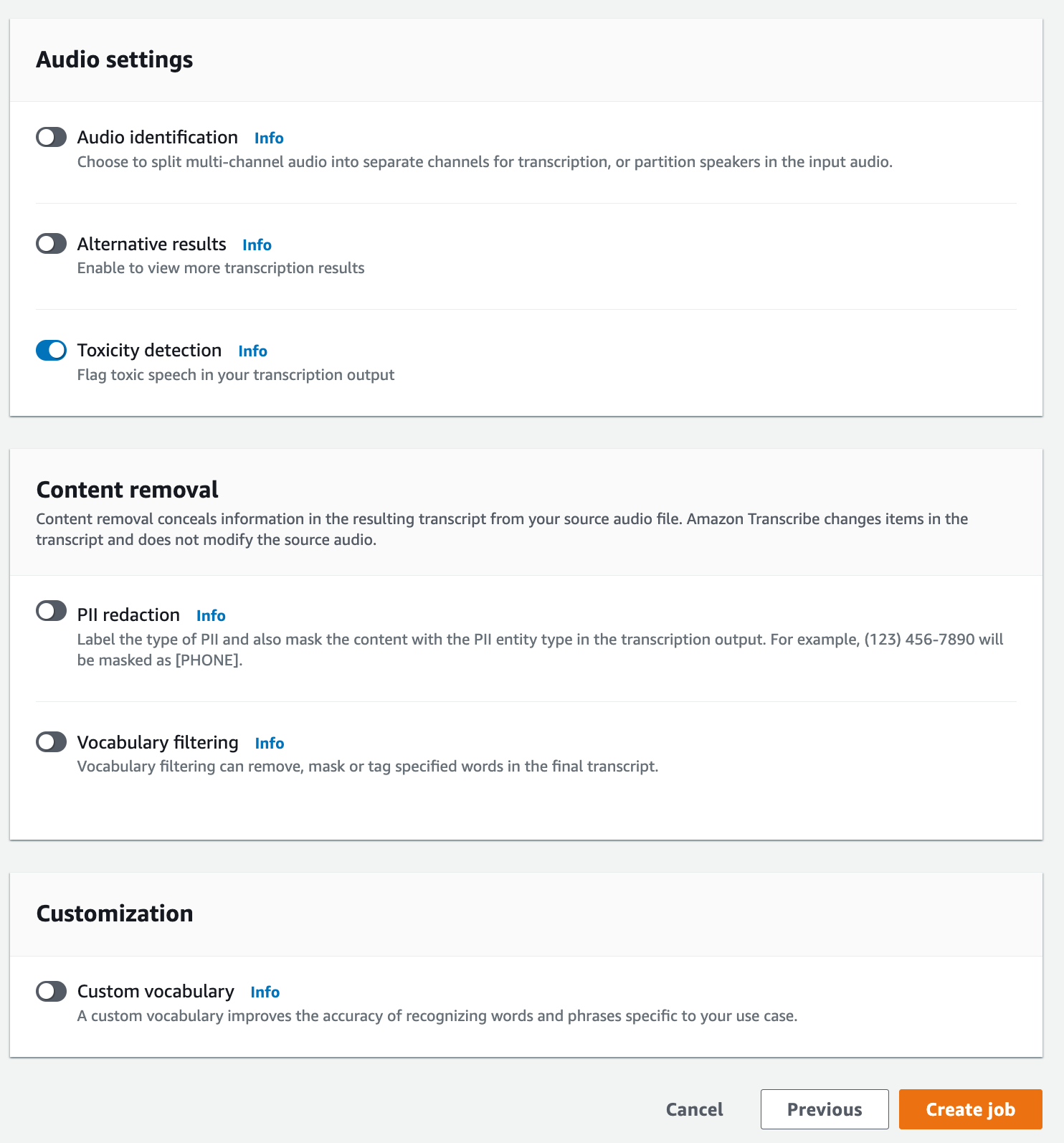
-
Seleccione Crear trabajo para ejecutar el trabajo de transcripción.
-
Una vez finalizado el trabajo de transcripción, puede descargarla desde el menú desplegable Descargar de la página de detalles del trabajo de transcripción.
En este ejemplo, se utilizan el comando start-transcription-jobToxicityDetection. Para obtener más información, consulte StartTranscriptionJob y ToxicityDetection.
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-bucket-nameamzn-s3-demo-bucket\ --output-keymy-output-files/\ --language-code en-US \ --toxicity-detection ToxicityCategories=ALL
Este es otro ejemplo en el que se utiliza el comando start-transcription-job
aws transcribe start-transcription-job \ --regionus-west-2\ --cli-input-jsonfile://filepath/my-first-toxicity-job.json
El archivo my-first-vocab-table.json contiene el siguiente cuerpo de la solicitud.
{ "TranscriptionJobName": "my-first-transcription-job", "Media": { "MediaFileUri": "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" }, "OutputBucketName": "amzn-s3-demo-bucket", "OutputKey": "my-output-files/", "LanguageCode": "en-US", "ToxicityDetection": [ { "ToxicityCategories": [ "ALL" ] } ] }
En este ejemplo, se utiliza AWS SDK para Python (Boto3) para habilitar ToxicityDetection en el método start_transcription_jobStartTranscriptionJob y ToxicityDetection.
Para ver ejemplos adicionales sobre el uso de los SDK de AWS, incluidos ejemplos de características específicas, escenarios y servicios cruzados, consulte el capítulo Ejemplos de código para Amazon Transcribe usando AWS SDKs.
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') job_name = "my-first-transcription-job" job_uri = "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" transcribe.start_transcription_job( TranscriptionJobName = job_name, Media = { 'MediaFileUri': job_uri }, OutputBucketName = 'amzn-s3-demo-bucket', OutputKey = 'my-output-files/', LanguageCode = 'en-US', ToxicityDetection = [ { 'ToxicityCategories': ['ALL'] } ] ) while True: status = transcribe.get_transcription_job(TranscriptionJobName = job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
Ejemplo de resultado
La vox tóxica se etiqueta y clasifica en el resultado de la transcripción. Cada instancia del habla tóxica se clasifica y se le asigna una puntuación de confianza (un valor entre 0 y 1). Un valor de confianza más alto indica una mayor probabilidad de que el contenido sea de habla tóxica dentro de la categoría especificada.
El siguiente es un ejemplo de salida en formato JSON que muestra el habla tóxica categorizada con las puntuaciones de confianza asociadas.
{ "jobName": "my-toxicity-job", "accountId": "111122223333", "results": { "transcripts": [...], "items":[...], "toxicity_detection": [ { "text": "What the * are you doing man? That's why I didn't want to play with your * . man it was a no, no I'm not calming down * man. I well I spent I spent too much * money on this game.", "toxicity": 0.7638, "categories": { "profanity": 0.9913, "hate_speech": 0.0382, "sexual": 0.0016, "insult": 0.6572, "violence_or_threat": 0.0024, "graphic": 0.0013, "harassment_or_abuse": 0.0249 }, "start_time": 8.92, "end_time": 21.45 }, Items removed for brevity { "text": "What? Who? What the * did you just say to me? What's your address? What is your * address? I will pull up right now on your * * man. Take your * back to , tired of this **.", "toxicity": 0.9816, "categories": { "profanity": 0.9865, "hate_speech": 0.9123, "sexual": 0.0037, "insult": 0.5447, "violence_or_threat": 0.5078, "graphic": 0.0037, "harassment_or_abuse": 0.0613 }, "start_time": 43.459, "end_time": 54.639 }, ] }, ... "status": "COMPLETED" }
