Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Guía de integración
Toda la solución está diseñada para ser fácilmente ampliable. La capa de orquestación de esta solución se creó utilizando. LangChain
Se admite la expansión LLMs
Para añadir otro proveedor de modelos, como un proveedor de LLM personalizado, debe actualizar los tres componentes siguientes de la solución:
-
Cree una nueva pila de
TextUseCaseCDK, que despliegue la aplicación de chat configurada con su proveedor de LLM personalizado:-
Clona el GitHub repositorio
de esta solución y configura tu entorno de compilación siguiendo las instrucciones que se proporcionan en el archivo README.md. -
Copie (o cree uno nuevo) el
source/infrastructure/lib/bedrock-chat-stack.tsarchivo, péguelo en el mismo directorio y cámbiele el nombre a.custom-chat-stack.ts -
Cambie el nombre de la clase del archivo por una adecuada, como.
CustomLLMChat -
Puedes optar por añadir un secreto de Secrets Manager a esta pila, que almacena tus credenciales para tu LLM personalizado. Puede recuperar estas credenciales durante la invocación del modelo en la capa Lambda de chat que se describe en el siguiente párrafo.
-
-
Cree y adjunte una capa Lambda que contenga la biblioteca de Python del proveedor de modelos que se va a añadir. En el caso de una aplicación de chat de casos de uso de Amazon Bedrock, la biblioteca de
langchain-awsPython incluye los conectores personalizados en la parte superior del LangChain paquete para conectarse a los proveedores de modelos de AWS (Amazon Bedrock e SageMaker IA), las bases de conocimiento (bases de conocimiento de Amazon Kendra y Amazon Bedrock) y los tipos de memoria (como DynamoDB). Del mismo modo, otros proveedores de modelos tienen sus propios conectores. Esta capa le ayuda a adjuntar la biblioteca Python de este proveedor de modelos para que pueda usar estos conectores en la capa Lambda de chat, que invoca el LLM (paso 3). En esta solución, se utiliza un empaquetador de activos personalizado para crear capas Lambda, que se adjuntan mediante aspectos de CDK. Para crear una capa nueva para la biblioteca de proveedores de modelos personalizados:-
Navegue hasta la
LambdaAspectsclase en elsource/infrastructure/lib/utils/lambda-aspects.tsarchivo. -
Siga las instrucciones sobre cómo ampliar la funcionalidad de la clase de aspectos de Lambda que se proporcionan en el archivo (por ejemplo, añadir el
getOrCreateLangchainLayermétodo). Para usar este nuevo método (por ejemplo,getOrCreateCustomLLMLayer), actualice también laLLM_LIBRARY_LAYER_TYPESenumeración delsource/infrastructure/lib/utils/constants.tsarchivo.
-
-
Amplíe la función
chatLambda para implementar un generador, un cliente y un controlador para el nuevo proveedor.source/lambda/chatContiene las LangChain conexiones de las diferentes clases LLMs junto con las clases auxiliares para crearlas. LLMs Estas clases de apoyo siguen los patrones de diseño orientado a objetos y constructores para crear el LLM.Cada controlador (por ejemplo
bedrock_handler.py) crea primero un cliente, comprueba el entorno en busca de las variables de entorno necesarias y, a continuación, llama a unget_modelmétodo para obtener la clase LangChain LLM. A continuación, se llama al método generate para invocar el LLM y obtener su respuesta. LangChain actualmente admite la funcionalidad de streaming para Amazon Bedrock, pero no para la SageMaker IA. Según la funcionalidad de transmisión o no transmisión, se llama al WebSocket controlador (WebsocketStreamingCallbackHandleroWebsocketHandler) apropiado para enviar la respuesta a la WebSocket conexión mediante el método.post_to_connectionLa
clients/buildercarpeta contiene las clases que ayudan a crear un LLM Builder utilizando el patrón Builder. En primer lugar,use_case_configse recupera a de un almacén de configuraciones de DynamoDB, que almacena los detalles sobre el tipo de base de conocimientos, memoria de conversación y modelo que se debe construir. También contiene detalles relevantes del modelo, como los parámetros y las instrucciones del modelo. Luego, The Builder ayuda a seguir los pasos para crear una base de conocimientos, crear una memoria de conversación para mantener el contexto de la conversación en el caso de la LLM, configurar las LangChain llamadas apropiadas para los casos de transmisión y no transmisión y crear un modelo de LLM basado en las configuraciones del modelo proporcionadas. La configuración de DynamoDB se almacena en el momento de la creación del caso de uso cuando se implementa un caso de uso desde el panel de implementación (o cuando la proporcionan los usuarios en las implementaciones de pilas de casos de uso independientes sin el panel de implementación).La
clients/factoriessubcarpeta ayuda a configurar la memoria de conversación y la clase de base de conocimientos adecuadas, en función de la configuración de LLM. Esto permite ampliarla fácilmente a cualquier otra base de conocimientos o tipos de memoria que desee que admita su implementación.La
sharedsubcarpeta contiene implementaciones específicas de la base de conocimientos y la memoria de conversación, que el creador crea instancias en las fábricas. También contiene los recuperadores de la base de conocimientos de Amazon Kendra y Amazon Bedrock a los que se recurre LangChain para recuperar documentos para los casos de uso de RAG, junto con devoluciones de llamada, que utiliza el modelo LLM. LangChainLangChain Las implementaciones utilizan el Lenguaje de LangChain Expresión (LCEL) para componer cadenas de conversación juntas.
RunnableWithMessageHistoryLa clase se utiliza para mantener el historial de conversaciones con cadenas LCEL personalizadas, lo que permite utilizar funciones como la devolución de los documentos fuente y el uso de la pregunta reformulada (o desambiguada) enviada a la base de conocimientos para enviarla también al LLM.Para crear tu propia implementación de un proveedor personalizado, puedes:
-
Copie el
bedrock_handler.pyarchivo y cree su controlador personalizado (por ejemplo,custom_handler.py), que creará su cliente personalizado (por ejemplo,CustomProviderClient) (especificado en el siguiente paso). -
Copia
bedrock_client.pyen la carpeta de clientes. Cámbiele el nombre acustom_provider_client.py(o al nombre específico de su proveedor de modelos, por ejemploCustomProvider). Asigne un nombre apropiado a la clase que contiene, por ejemplo, laCustomProviderClientque heredaLLMChatClient.Puede usar los métodos proporcionados
LLMChatCliento escribir sus propias implementaciones para anularlos.El
get_modelmétodo crea unCustomProviderBuilder(consulte el paso siguiente) y llama alconstruct_chat_modelmétodo que construye el modelo de chat siguiendo los pasos del generador. Este método actúa como director en el patrón del generador. -
Cópielo
clients/builders/bedrock_builder.pyy cámbiele el nombrecustom_provider_builder.pyy cámbiele el nombre a la claseCustomProviderBuilderque contiene y hereda LLMBuilder ()llm_builder.py. Puedes usar los métodos proporcionados por LLMBuilder o escribir tus propias implementaciones para anularlos. Los pasos del generador se invocan en secuencia dentro delconstruct_chat_modelmétodo del cliente, por ejemploset_model_defaultsset_knowledge_base, y.set_conversation_memoryEl
set_llm_modelmétodo crearía el modelo LLM real utilizando todos los valores establecidos mediante los métodos invocados anteriormente. En concreto, puede crear un LLM RAG (CustomProviderRetrievalLLM) o no RAG (CustomProviderLLM), en función de lorag_enabled variableque se recupere de la configuración de LLM en DynamoDB.Esta configuración se obtiene en el método de la clase.
retrieve_use_case_configLLMChatClient -
Implemente su
CustomProviderRetrievalLLMimplementaciónCustomProviderLLMo implementación en lallm_modelssubcarpeta en función de si necesita un caso de uso de RAG o de otro tipo. La mayoría de las funcionalidades para implementar estos modelos se proporcionan en susRetrievalLLMclasesBaseLangChainModely, respectivamente, para casos de uso que no son RAG y RAG.Puede copiar el
llm_models/bedrock.pyarchivo y realizar los cambios necesarios para llamar al LangChain modelo que se refiera a su proveedor personalizado. Por ejemplo, Amazon Bedrock usa unaChatBedrockclase para crear un modelo de chat usando LangChain.El método generate genera la respuesta LLM mediante las cadenas LangChain LCEL.
También puede utilizar el
get_clean_model_paramsmétodo para sanear los parámetros del modelo según LangChain los requisitos de su modelo.
-
Ampliación de las herramientas de Strands compatibles
La solución le permite crear e implementar servidores MCP, agentes de IA y flujos de trabajo con múltiples agentes. Gracias a la experiencia de Agent Builder, puede conectar servidores MCP para ofrecer a sus agentes funciones adicionales. Además de los servidores MCP, puede aprovechar las herramientas integradas que proporciona Strands
De fábrica, la solución viene preconfigurada con las siguientes herramientas de Strands:
-
Hora actual (habilitada de forma predeterminada)
-
Calculadora (habilitada de forma predeterminada)
-
Entorno
La selección de servidores y herramientas MCP en el asistente de Agent Builder muestra las herramientas integradas de Strands

Para ampliar sus agentes con herramientas adicionales de Strands, siga el proceso de cuatro pasos que se describe en esta sección.
Paso 1: Busca la herramienta Strands
Explore las herramientas de Strams disponibles
Por ejemplo, para añadir las capacidades de recuperación de Amazon Bedrock Knowledge Base, utilizaría la herramienta de recuperación.
Paso 2: actualice el parámetro SSM
Para que una herramienta esté disponible en la interfaz de usuario de implementación de Agent Builder, actualice el parámetro AWS Systems Manager Parameter Store que define qué herramientas de Strands son compatibles.
-
Diríjase al almacén de parámetros de AWS Systems Manager en su cuenta de AWS.
-
Localice el parámetro:
/gaab/<stack-name>/strands-tools -
Añada la configuración de la herramienta al final de la lista existente mediante la siguiente estructura JSON:
{ "name": "Bedrock KB Retrieve", "description": "Retrieve information from Bedrock Knowledge Base", "value": "retrieve", "category": "AI", "isDefault": false }Campo Description (Descripción) name
El nombre para mostrar se muestra en la interfaz de usuario de Agent Builder
description
Breve descripción de la funcionalidad de la herramienta
value
El nombre exacto de la herramienta tal y como se define en el paquete de herramientas Strands
categoría
Categoría organizativa para agrupar herramientas en la interfaz de usuario
es el valor predeterminado
Si la herramienta debe estar habilitada de forma predeterminada para los agentes nuevos
Paso 3: Configurar las variables de entorno
Muchas herramientas de Strands requieren variables de entorno para la configuración. Puede configurar estas variables de dos maneras:
Opción 1: configuración directa en AgentCore tiempo de ejecución
Actualice el agente implementado directamente en Amazon Bedrock AgentCore Runtime con las variables de entorno necesarias.
Opción 2: Modele los parámetros en el asistente de despliegue
Añada variables de entorno durante el paso de selección del modelo en el asistente de Agent Builder mediante la sección Parámetros del modelo. Las variables de entorno que siguen la convención de nomenclatura se ENV_<ALL_CAPS_TOOL_NAME>_<env_variable_name> cargarán automáticamente durante el tiempo de ejecución en el entorno de ejecución del agente, como<env_variable_name>.
Por ejemplo:
-
ENV_RETRIEVE_KNOWLEDGE_BASE_IDse convertirá enKNOWLEDGE_BASE_ID -
ENV_RETRIEVE_MIN_SCOREse convertirá enMIN_SCORE
Sección de parámetros avanzados del modelo que muestra la configuración de ENV_RETRIEVE_KNOWLEDGE_BASE_ID

Consulte la documentación o el código fuente de la herramienta específica para identificar las variables de entorno requeridas. Para la herramienta de recuperación, puede encontrar las opciones de configuración en el código fuente
Paso 4: Añadir permisos de IAM
Añada manualmente los permisos de IAM necesarios a su función AgentCore de ejecución en tiempo de ejecución para que el agente pueda utilizar la herramienta.
Por ejemplo, para usar la herramienta de recuperación con las bases de conocimiento de Amazon Bedrock:
-
Navegue hasta la consola de IAM en su cuenta de AWS.
-
Localice la función AgentCore de ejecución en tiempo de ejecución de su agente.
-
Añada el siguiente permiso:
{ "Effect": "Allow", "Action": "bedrock:Retrieve", "Resource": "arn:aws:bedrock:region:account-id:knowledge-base/knowledge-base-id" }
Consola de IAM que muestra la StrandsRetrieveTool KBAccess política asociada a la función de ejecución en AgentCore tiempo de ejecución

Los permisos específicos necesarios variarán en función de la herramienta. Consulte la documentación de la herramienta y la documentación del servicio de AWS para determinar los permisos de IAM adecuados.
Paso 5: Pruebe el agente
Tras completar los pasos de configuración, pruebe el agente para comprobar que la herramienta funciona correctamente. Debería ver las invocaciones a las herramientas en los registros de ejecución y las respuestas del agente.
El agente utiliza correctamente la herramienta de recuperación para responder a una pregunta sobre los parques de patinaje
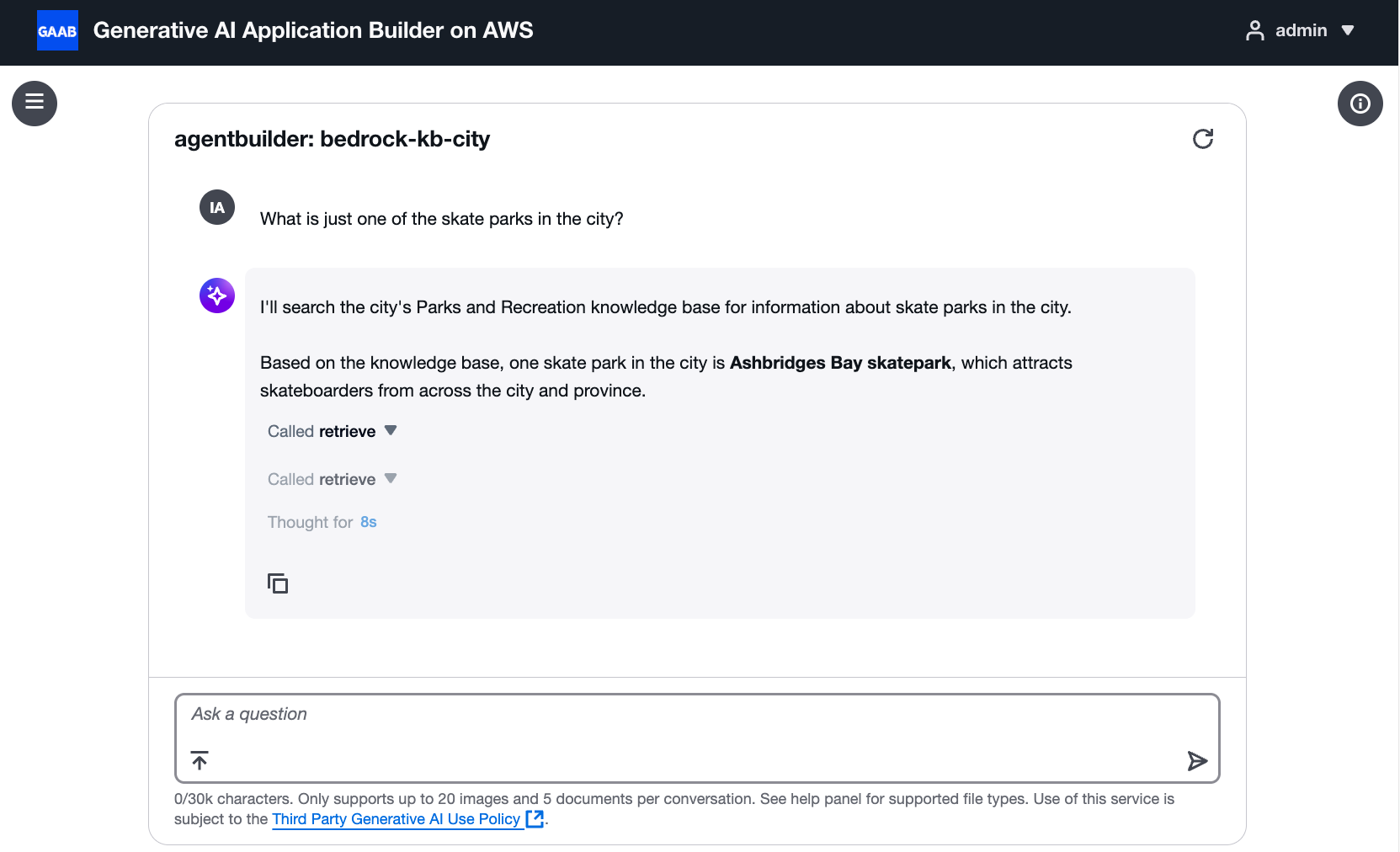
nota
Para obtener una lista completa de las herramientas de Strands disponibles y sus capacidades, consulte la documentación de las herramientas comunitarias de Strands
Ampliar las bases de conocimiento y los tipos de memoria de conversación compatibles
Para añadir sus implementaciones de la memoria de conversaciones o la base de conocimientos, añada las implementaciones necesarias a la shared carpeta y, a continuación, edite las fábricas y las enumeraciones correspondientes para crear una instancia de estas clases.
Cuando proporcione la configuración de LLM, que se almacena en el almacén de parámetros, se crearán la memoria de conversación y la base de conocimientos adecuadas para su LLM. Por ejemplo, cuando ConversationMemoryType se especifica como DynamoDB, se crea una instancia DynamoDBChatMessageHistory de (disponible en el shared_components/memory/ddb_enhanced_message_history.py interior). Cuando KnowledgeBaseType se especifica como Amazon Kendra, se crea una instancia de KendraKnowledgeBase (disponible en el interiorshared_components/knowledge/kendra_knowledge_base.py).
La creación y el despliegue del código cambian
Cree el programa con el npm run build comando. Una vez resueltos los errores, ejecútelo cdk synth para generar los archivos de plantilla y todos los activos de Lambda.
-
Puede usar el
–0—/stage-assets.shscript para almacenar manualmente cualquier activo generado en el depósito de almacenamiento provisional de su cuenta. -
Usa el siguiente comando para implementar o actualizar la plataforma:
cdk deploy DeploymentPlatformStack --parameters AdminUserEmail='admin-email@amazon.com'Todos CloudFormation los parámetros de AWS adicionales también deben proporcionarse junto con el AdminUserEmailparámetro.
