Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
UO de datos personales: cuenta de la aplicación de datos personales
Encuesta
Nos encantaría saber su opinión. Envíe sus comentarios sobre la AWS PRA mediante una breve encuesta
La cuenta de la aplicación de datos personales (PD) es el lugar donde la organización aloja los servicios que recopilan y procesan los datos personales. En concreto, en esta cuenta puede almacenar lo que defina como datos personales. La AWS PRA muestra varios ejemplos de configuraciones de privacidad a través de una arquitectura web sin servidor de varios niveles. Cuando se trata de operar cargas de trabajo en una AWS landing zone, las configuraciones de privacidad no deben considerarse one-size-fits-all soluciones. Por ejemplo, su objetivo podría ser comprender los conceptos subyacentes, cómo pueden mejorar la privacidad y cómo la organización puede aplicar las soluciones a sus arquitecturas y casos de uso particulares.
Cuentas de AWS En su organización que recopila, almacena o procesa datos personales, puede utilizar AWS Organizations e AWS Control Tower implementar barreras fundamentales y repetibles. Es fundamental que establezca una unidad organizativa (UO) específica para estas cuentas. Por ejemplo, tal vez desee aplicar barreras de protección para la residencia de datos solo a un subconjunto de cuentas en las que la residencia de los datos sea una consideración de diseño fundamental. Para muchas organizaciones, estas son las cuentas que almacenan y procesan los datos personales.
Su organización podría considerar la posibilidad de crear una cuenta de datos dedicada, que es donde almacena el origen autorizado de sus conjuntos de datos personales. Los orígenes de datos autorizados son la ubicación donde se almacena la versión principal de los datos, que puede considerarse la versión más fiable y precisa de los datos. Por ejemplo, puede copiar los datos del origen de datos autorizado a otras ubicaciones, como los buckets de Amazon Simple Storage Service (Amazon S3) en la cuenta de la aplicación de datos personales que se utilizan para almacenar datos de entrenamiento, un subconjunto de datos de clientes y datos con información suprimida. Al adoptar este enfoque de varias cuentas para separar los conjuntos de datos personales completos y definitivos que hay en la cuenta de datos de las cargas de trabajo de los consumidores posteriores que hay en la cuenta de la aplicación de datos personales, puede reducir el alcance del impacto en caso de acceso no autorizado a las cuentas.
El siguiente diagrama ilustra los servicios de AWS seguridad y privacidad que están configurados en las cuentas de datos y aplicaciones de PD.
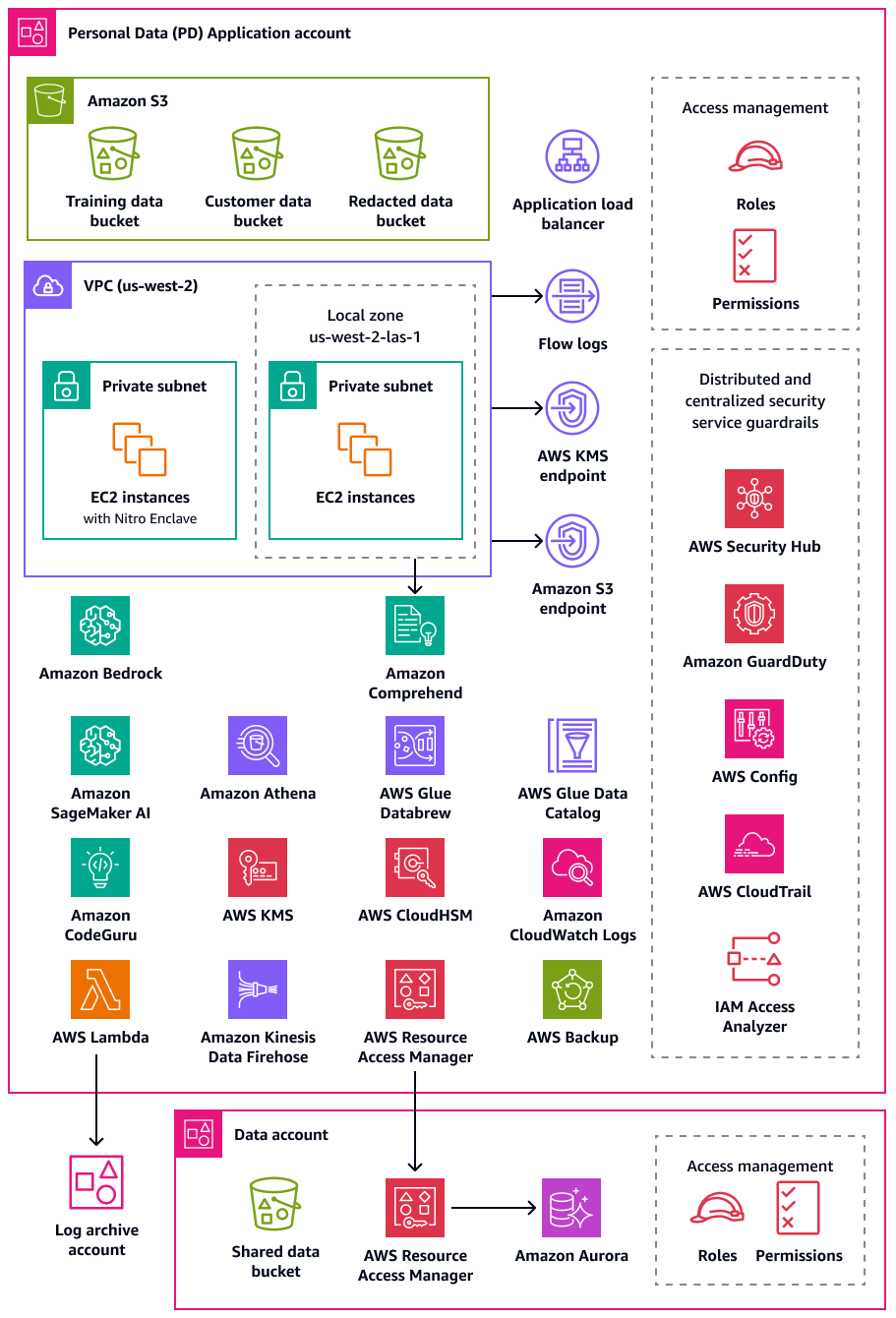
En esta sección se proporciona información más detallada sobre los siguientes Servicios de AWS que se utilizan en estas cuentas:
Amazon Athena
Puede considerar los controles de limitación de las consultas de datos para cumplir sus objetivos de privacidad. Amazon Athena es un servicio de consultas interactivo que facilita el análisis de datos en Amazon S3 con SQL estándar. No es necesario que cargue los datos en Athena; funciona directamente con los datos almacenados en los buckets de S3.
Un caso de uso habitual de Athena es proporcionar a los equipos de análisis de datos conjuntos de datos personalizados y saneados. Si los conjuntos de datos contienen datos personales, puede limpiarlos enmascarando columnas enteras de datos personales que proporcionen poco valor a los equipos de análisis de datos. Para obtener más información, consulte Anonimizar y administrar los datos de su lago de datos con Amazon Athena y AWS Lake Formation
Si su enfoque para la transformación de datos necesita más flexibilidad de la que ofrecen las funciones compatibles con Athena, puede definir funciones personalizadas, denominadas funciones definidas por el usuario (UDF). Puede invocar UDFs una consulta SQL enviada a Athena y se ejecutará. AWS Lambda Puede utilizar FILTER
SQL consultas UDFs de entrada SELECT y, además, puede invocar varias UDFs en la misma consulta. Por motivos de privacidad, puede crear UDFs dispositivos que utilicen tipos específicos de enmascaramiento de datos, como mostrar solo los últimos cuatro caracteres de cada valor de una columna.
Amazon Bedrock
Amazon Bedrock es un servicio totalmente gestionado que proporciona acceso a los modelos básicos de las principales empresas de IA, como AI21 Labs, Anthropic, Meta, Mistral AI y Amazon. Ayuda a las organizaciones a crear y escalar aplicaciones de IA generativa. Independientemente de la plataforma que se utilice, al utilizar la IA generativa, las organizaciones podrían exponerse a riesgos de privacidad, como la posible exposición de los datos personales, el acceso no autorizado a los datos y otras infracciones relacionadas con el cumplimiento.
Las Barreras de protección para Amazon Bedrock están diseñadas para ayudar a mitigar estos riesgos mediante la aplicación de las prácticas recomendadas de seguridad y cumplimiento en todas sus cargas de trabajo de IA generativa en Amazon Bedrock. Es posible que la implementación y el uso de los recursos de IA no siempre se ajusten a los requisitos de privacidad y cumplimiento de una organización. Las organizaciones pueden tener dificultades para mantener la privacidad de los datos cuando utilizan modelos de IA generativa porque estos modelos pueden memorizar o reproducir información confidencial. Las Barreras de protección para Amazon Bedrock ayudan a proteger la privacidad, ya que evalúan las entradas de los usuarios y las respuestas de los modelos. En general, si los datos de entrada contienen datos personales, existe el riesgo de que esta información quede expuesta en la salida del modelo.
Las Barreras de protección para Amazon Bedrock proporcionan mecanismos para hacer cumplir las políticas de protección de datos y ayudan a evitar la exposición no autorizada de los datos. Ofrece funciones de filtrado de contenido para detectar y bloquear los datos personales en las entradas, restricciones temáticas para evitar el acceso a temas poco adecuados o peligrosos y filtros de palabras para enmascarar o suprimir términos delicados en las peticiones y respuestas de los modelos. Estas funciones ayudan a prevenir situaciones que podrían dar lugar a infracciones de la privacidad, como las respuestas sesgadas o la erosión de la confianza de los clientes. Estas características pueden ayudarlo a garantizar que los modelos de IA no procesen ni revelen datos personales de forma accidental. Las Barreras de protección para Amazon Bedrock también admiten la evaluación de las entradas y las respuestas fuera de Amazon Bedrock. Para obtener más información, consulte Implement model-independent safety measures with Amazon Bedrock Guardrails
Con las Barreras de protección para Amazon Bedrock, puede limitar el riesgo de alucinaciones de los modelos mediante comprobaciones de fundamento contextual, que evalúan la veracidad de los hechos y la relevancia de las respuestas. Un ejemplo es la implementación de una aplicación de IA generativa orientada al cliente que utiliza orígenes de datos externos en una aplicación de generación aumentada por recuperación (RAG)
AWS Clean Rooms
A medida que las organizaciones buscan formas de colaborar entre ellas mediante el análisis de conjuntos de datos confidenciales que se cruzan o se superponen, es crucial mantener la seguridad y la privacidad de esos datos compartidos. AWS Clean Rooms lo ayuda a implementar salas limpias de datos, que son entornos seguros y neutrales en los que las organizaciones pueden analizar conjuntos de datos combinados sin compartir los propios datos sin procesar. También puede generar información única al proporcionar acceso a otras organizaciones AWS sin mover ni copiar datos de sus propias cuentas y sin revelar el conjunto de datos subyacente. Todos los datos permanecen en la ubicación de origen. Las reglas de análisis integradas limitan la salida y restringen las consultas SQL. Todas las consultas se registran y los miembros de la colaboración pueden ver cómo se consultan los datos.
Puede crear una AWS Clean Rooms colaboración e invitar a otros AWS clientes a ser miembros de esa colaboración. A continuación, concede a un miembro la posibilidad de consultar los conjuntos de datos de los miembros y elige miembros adicionales para recibir los resultados de esas consultas. Si más de un miembro tiene que consultar los conjuntos de datos, puede crear colaboraciones adicionales con los mismos orígenes de datos y distintas configuraciones de miembros. Cada miembro puede filtrar los datos que se comparten con los miembros de la colaboración, y puede usar reglas de análisis personalizadas para establecer limitaciones sobre la forma en que se pueden analizar los datos que aportan a la colaboración.
Además de restringir los datos que se presentan a la colaboración y la forma en que otros miembros pueden utilizarlos, AWS Clean Rooms ofrece las siguientes funciones que pueden ayudarle a proteger la privacidad:
-
La privacidad diferencial es una técnica matemática que mejora la privacidad del usuario al agregar a los datos una cantidad de ruido calibrada cuidadosamente. De esta forma, se reduce el riesgo de que se vuelva a identificar a los usuarios individuales en el conjunto de datos sin ocultar los valores de interés. El uso de la privacidad diferencial de AWS Clean Rooms no requiere ningún conocimiento experto en privacidad diferencial.
-
AWS Clean Rooms ML permite que dos o más partes identifiquen a usuarios similares en sus datos sin compartir directamente sus datos entre sí. Esto reduce el riesgo de ataques de inferencia de miembros, en los que un miembro de la colaboración puede identificar a las personas del conjunto de datos del otro miembro. Al crear un modelo similar y generar un segmento similar, AWS Clean Rooms ML le ayuda a comparar conjuntos de datos sin exponer los datos originales. Esto no requiere que ninguno de los miembros tenga experiencia en aprendizaje automático ni que realice ningún trabajo ajeno a ellos. AWS Clean Rooms Usted mantiene el control total y la propiedad del modelo entrenado.
-
Puede usar la computación criptográfica para Clean Rooms (C3R) con reglas de análisis para obtener información a partir de información confidencial. Limita criptográficamente lo que cualquier otra parte de la colaboración puede aprender. Al utilizar el cliente de cifrado C3R, los datos se cifran en el cliente antes de proporcionárselos. AWS Clean Rooms Como las tablas de datos se cifran con una herramienta de cifrado del cliente antes de cargarlas en Amazon S3, los datos permanecen cifrados y se conservan durante el procesamiento.
En la AWS PRA, le recomendamos que cree AWS Clean Rooms colaboraciones en la cuenta de datos. Puede utilizarlas para compartir los datos cifrados de los clientes con terceros. Úselas únicamente cuando haya una superposición en los conjuntos de datos proporcionados. Para obtener más información sobre cómo determinar la superposición, consulte la regla de análisis de listas en la AWS Clean Rooms documentación.
Amazon CloudWatch Logs
Amazon CloudWatch Logs le ayuda a centralizar los registros de todos sus sistemas y aplicaciones Servicios de AWS para que pueda supervisarlos y archivarlos de forma segura. En CloudWatch Logs, puede utilizar una política de protección de datos para los grupos de registros nuevos o existentes a fin de minimizar el riesgo de divulgación de datos personales. Las políticas de protección de datos pueden detectar información confidencial, como datos personales, en los registros. La política de protección de datos puede enmascarar esos datos cuando los usuarios acceden a los registros a través de la Consola de administración de AWS. Cuando los usuarios tengan que acceder directamente a los datos personales, de acuerdo con la especificación de finalidad general de la carga de trabajo, puede asignar permisos de logs:Unmask a esos usuarios. También tiene la opción de crear una política de protección de datos para toda la cuenta y aplicarla de forma coherente en todas las cuentas de la organización. Esto configura el enmascaramiento de forma predeterminada para todos los grupos de registros actuales y futuros en CloudWatch Logs. Además, recomendamos que active los informes de auditoría y los envíe a otro grupo de registro, a un bucket de Amazon S3 o a Amazon Data Firehose. Estos informes contienen un registro detallado de los resultados de protección de datos en cada grupo de registro.
CodeGuru Revisor de Amazon
Tanto para la privacidad como para la seguridad, para muchas organizaciones es vital respaldar el cumplimiento constante durante la fase de implementación y las fases posteriores a la implementación. AWS PRA incluye controles proactivos en las canalizaciones de implementación de las aplicaciones que procesan datos personales. Amazon CodeGuru Reviewer puede detectar posibles defectos que podrían exponer datos personales en código Java y Python. JavaScript Ofrece sugerencias a los desarrolladores para mejorar el código. CodeGuru El revisor puede identificar los defectos en una amplia gama de prácticas de seguridad, privacidad y recomendaciones generales. Está diseñado para funcionar con varios proveedores de fuentes AWS CodeCommit, incluidos Bitbucket y Amazon S3. GitHub Algunos de los defectos relacionados con la privacidad que CodeGuru Reviewer puede detectar incluyen:
-
Inyección de código SQL
-
Cookies sin protección
-
Falta la autorización
-
AWS KMS Recrificación del lado del cliente
Para obtener una lista completa de lo que CodeGuru Reviewer puede detectar, consulte la biblioteca de Amazon CodeGuru Detector.
Amazon Comprehend
Amazon Comprehend es un servicio de procesamiento de lenguaje natural (NLP) que usa machine learning para descubrir información y relaciones valiosas en documentos de texto en inglés. Amazon Comprehend puede detectar y suprimir datos personales en documentos de texto estructurados, semiestructurados o sin estructurar. Para obtener más información, consulte Personally identifiable information (PII) en la documentación de Amazon Comprehend.
Dado que Amazon Comprehend ofrece muchas opciones para la integración de aplicaciones AWS SDKs, puede utilizar Amazon Comprehend para identificar datos personales en muchos lugares diferentes donde recopila, almacena y procesa datos. Puede utilizar las capacidades de Amazon Comprehend ML para detectar y redactar datos personales en los registros de aplicaciones
-
REPLACE_WITH_PII_ENTITY_TYPEreemplaza cada entidad de PII por sus tipos. Por ejemplo, Jane Doe se sustituiría por NAME. -
MASKreemplaza los caracteres de las entidades de PII por un carácter de su elección (!, #, $, %, &, o @). Por ejemplo, Jane Doe podría sustituirse por **** ***.
Amazon Data Firehose
Puede usar Amazon Data Firehose para capturar, transformar y cargar datos de transmisión en directo en servicios posteriores, como Amazon Managed Service para Apache Flink o Amazon S3. Firehose se suele utilizar para transportar grandes cantidades de datos de transmisión en directo, como registros de aplicaciones, sin tener que crear canalizaciones de procesamiento desde cero.
Puede utilizar las funciones de Lambda para realizar un procesamiento personalizado o integrado antes de que los datos se envíen a las fases posteriores. Para conservar la privacidad, esta capacidad es compatible con los requisitos de minimización de datos y transferencia de datos transfronteriza. Por ejemplo, puede usar Lambda y Firehose para transformar los datos de registro de varias regiones antes de que se centralicen en la cuenta de archivos de registro. Para obtener más información, consulte Biogen: solución de registro centralizada para cuentas múltiples
Amazon DataZone
A medida que las organizaciones amplían su enfoque para compartir datos AWS Lake Formation, por Servicios de AWS ejemplo, quieren asegurarse de que el acceso diferencial esté controlado por quienes están más familiarizados con los datos: los propietarios de los datos. Sin embargo, es posible que estos propietarios de datos conozcan los requisitos de privacidad, como el consentimiento o las consideraciones sobre la transferencias de datos transfronterizas. Amazon DataZone ayuda a los propietarios de los datos y al equipo de gobierno de datos a compartir y consumir datos en toda la organización de acuerdo con sus políticas de gobierno de datos. En Amazon DataZone, las líneas de negocio (LOBs) administran sus propios datos y un catálogo rastrea esta propiedad. Las partes interesadas pueden buscar datos y solicitar acceso a ellos como parte de sus tareas comerciales. Siempre que cumpla con las políticas establecidas por los publicadores de datos, el propietario de los datos puede conceder el acceso a las tablas subyacentes sin necesidad de un administrador ni de mover los datos.
En un contexto de privacidad, Amazon DataZone puede ser útil en los siguientes casos de uso de ejemplo:
-
Una aplicación orientada al cliente genera datos de uso que se pueden compartir con una línea de negocio de marketing independiente. Debe asegurarse de que solo se publiquen en el catálogo los datos de los clientes que hayan aceptado la opción de marketing.
-
Los datos de los clientes europeos se publican, pero solo los usuarios LOBs locales del Espacio Económico Europeo (EEE) pueden suscribirlos. Para obtener más información, consulta Mejora la seguridad de los datos con controles de acceso detallados en Amazon
. DataZone
En la AWS PRA, puede conectar los datos del bucket compartido de Amazon S3 a Amazon DataZone como productor de datos.
AWS Glue
El mantenimiento de conjuntos de datos que contienen datos personales es un componente clave de Privacy by Design. Los datos de una organización pueden estar estructurados, semiestructurados o sin estructurar. Los conjuntos de datos personales sin estructura pueden dificultar la realización de una serie de operaciones que mejoran la privacidad, como la minimización de los datos, el seguimiento de los datos atribuidos a un solo titular de los datos como parte de una solicitud del titular, la garantía de una calidad de datos uniforme y la segmentación general de los conjuntos de datos. AWS Glue es un servicio de extracción, transformación y carga (ETL) completamente administrado. Puede ayudarle a clasificar, limpiar, enriquecer y mover datos entre almacenes de datos y flujos de datos. AWS Glue las funciones están diseñadas para ayudarlo a descubrir, preparar, estructurar y combinar conjuntos de datos para el análisis, el aprendizaje automático y el desarrollo de aplicaciones. Puede utilizarlas AWS Glue para crear una estructura común y predecible sobre sus conjuntos de datos existentes. AWS Glue Data Catalog AWS Glue DataBrew, y la calidad de AWS Glue los datos son AWS Glue funciones que pueden ayudar a cumplir los requisitos de privacidad de su organización.
AWS Glue Data Catalog
AWS Glue Data Catalog lo ayuda a establecer conjuntos de datos fáciles de mantener. El catálogo de datos contiene referencias a los datos que se utilizan como fuentes y destinos para las tareas de extracción, transformación y carga (ETL) AWS Glue. La información del Catálogo de datos se almacena como tablas de metadatos y cada tabla especifica un único almacén de datos. Ejecuta un rastreador de AWS Glue
para hacer un inventario de los datos en una variedad de tipos de almacenes de datos. Agrega clasificadores integrados y personalizados al rastreador. Estos clasificadores deducen el formato y el esquema de los datos personales. A continuación, el rastreador escribe los metadatos en el Catálogo de datos. Una tabla de metadatos centralizada puede facilitar la respuesta a las solicitudes de los interesados (como el derecho a la supresión), ya que añade estructura y previsibilidad a las distintas fuentes de datos personales de su entorno. AWS Para ver un ejemplo completo de cómo utilizar Data Catalog para responder automáticamente a estas solicitudes, consulte Gestión de las solicitudes de borrado de datos en su lago de datos con Amazon S3 Find and Forget
AWS Glue DataBrew
AWS Glue DataBrew lo ayuda a limpiar y normalizar los datos, y puede realizar transformaciones en los datos, como eliminar o enmascarar la información de identificación personal y cifrar los campos de información confidencial en las canalizaciones de datos. También puede crear un mapa visual del linaje de los datos para comprender los distintos orígenes de datos y los pasos de transformación por los que han pasado los datos. Esta función adquiere cada vez más importancia a medida que su organización trabaja para comprender mejor la procedencia de los datos personales y hacer un seguimiento de ellos. DataBrew le ayuda a ocultar los datos personales durante la preparación de los datos. Puede detectar datos personales como parte de un trabajo de elaboración de perfiles de datos y recopilar estadísticas, como el número de columnas que pueden contener datos personales y las posibles categorías. A continuación, puede utilizar técnicas integradas de transformación de datos reversibles o irreversibles, como la sustitución, el uso de algoritmos hash, el cifrado y el descifrado, todo ello sin necesidad de escribir ningún código. A continuación, puede utilizar los conjuntos de datos limpios y enmascarados en las fases posteriores para realizar tareas de análisis, elaboración de informes y machine learning. Algunas de las técnicas de enmascaramiento de datos disponibles en DataBrew incluyen:
-
Algoritmos hash: aplique funciones hash a los valores de las columnas.
-
Sustitución: sustituya los datos personales por otros valores que parezcan auténticos.
-
Anulación o eliminación: sustituya un campo concreto por un valor nulo o elimine la columna.
-
Enmascaramiento: utilice la codificación de caracteres u oculte determinadas partes de las columnas.
Estas son las técnicas de cifrado que hay disponibles:
-
Cifrado determinista: aplique algoritmos de cifrado determinista a los valores de las columnas. El cifrado determinista siempre produce el mismo texto cifrado para un valor.
-
Cifrado probabilístico: aplique algoritmos de cifrado probabilístico a los valores de las columnas. El cifrado probabilístico produce un texto cifrado diferente cada vez que se aplica.
Para obtener una lista completa de las recetas de transformación de datos personales proporcionadas en DataBrew, consulte los pasos básicos de la información de identificación personal (PII).
AWS Glue Calidad de los datos
AWS Glue La calidad de los datos le ayuda a automatizar y poner en funcionamiento la entrega de datos de alta calidad en todas las canalizaciones de datos, de forma proactiva, antes de entregarlos a sus consumidores de datos. AWS Glue Data Quality proporciona un análisis estadístico de los problemas de calidad de los datos en todos sus flujos de datos, puede activar alertas en Amazon EventBridge y puede recomendar normas de calidad para su corrección. AWS Glue Data Quality también permite la creación de reglas con un lenguaje específico del dominio para que pueda crear reglas de calidad de datos personalizadas.
AWS Key Management Service
AWS Key Management Service (AWS KMS) le ayuda a crear y controlar claves criptográficas para proteger sus datos. AWS KMS utiliza módulos de seguridad de hardware para proteger y validar AWS KMS keys en el marco del programa de validación de módulos criptográficos FIPS 140-2. Para obtener más información sobre cómo se utiliza este servicio en un contexto de seguridad, consulte la Arquitectura de referencia de seguridad de AWS.
AWS KMS se integra con la mayoría de los Servicios de AWS que ofrecen cifrado, y puede utilizar claves KMS en las aplicaciones que procesan y almacenan datos personales. Puede utilizar AWS KMS para cumplir una serie de requisitos de privacidad y proteger los datos personales, como, por ejemplo:
-
Usar claves administradas por el cliente para tener un mayor control sobre la resistencia, la rotación, la caducidad y otras opciones.
-
Usar claves administradas por el cliente exclusivas para proteger los datos personales y los secretos que permiten el acceso a los datos personales.
-
Definir los niveles de clasificación de datos y designar al menos una clave administrada por el cliente exclusiva para cada nivel. Por ejemplo, puede tener una clave para cifrar los datos operativos y otra para cifrar los datos personales.
-
Impedir el acceso entre cuentas involuntario a claves de KMS.
-
Almacenar las claves de KMS en el Cuenta de AWS mismo lugar que el recurso que se va a cifrar.
-
Implementar la separación de tareas para la administración y el uso de las claves de KMS. Para obtener más información, consulte Cómo usar KMS e IAM para habilitar controles de seguridad independientes para los datos cifrados en S3
(entrada del AWS blog). -
Impulsar la rotación automática de claves mediante barreras de protección de prevención y reacción.
De forma predeterminada, las claves de KMS se almacenan y solo se pueden utilizar en la región donde se crearon. Si la organización tiene requisitos específicos de soberanía y residencia de datos, considere si las claves de KMS de varias regiones son apropiadas para su caso de uso. Las claves multirregionales son claves de KMS con un propósito especial y diferentes Regiones de AWS que se pueden usar indistintamente. El proceso de creación de una clave multirregional traslada el material clave más allá de Región de AWS las fronteras internas AWS KMS, por lo que esta falta de aislamiento regional podría no ser compatible con los objetivos de soberanía y residencia de la organización. Una forma de solucionar este problema consiste en utilizar un tipo diferente de clave de KMS, como una clave administrada por el cliente específica de una región.
Almacenes de claves externos
Para muchas organizaciones, el almacén de AWS KMS claves predeterminado Nube de AWS puede cumplir con sus requisitos de soberanía de datos y reglamentarios generales. Sin embargo, algunas organizaciones pueden necesitar que las claves de cifrado se creen y mantengan fuera de un entorno en la nube y que disponga de rutas de autorización y auditoría independientes. Con los almacenes de claves externos AWS KMS, puede cifrar los datos personales con material clave que su organización posea y controle de forma externa. Nube de AWS Seguirá interactuando con la AWS KMS API como de costumbre, pero solo AWS KMS interactúa con el software de proxy de almacén de claves externo (proxy XKS) que usted proporcione. A continuación, el proxy del almacén de claves externo interviene en todas las comunicaciones entre AWS KMS y el administrador de claves externo.
Al utilizar un almacén de claves externo para el cifrado de datos, es importante tener en cuenta el costo operativo adicional en comparación con el mantenimiento de las claves en AWS KMS. Con un almacén de claves externo, debe crear, configurar y mantener el almacén de claves externo. Además, si hay errores en la infraestructura adicional que debe mantener, como el proxy XKS, y se pierde la conectividad, es posible que los usuarios no puedan descifrar los datos ni acceder a ellos temporalmente. Debe trabajar en estrecha colaboración con las partes interesadas en materia de cumplimiento y normativas para comprender las obligaciones legales y contractuales relativas al cifrado de datos personales y sus acuerdos de nivel de servicio en relación con la disponibilidad y la resiliencia.
AWS Lake Formation
Muchas organizaciones que catalogan y categorizan sus conjuntos de datos mediante catálogos de metadatos estructurados desean compartir esos conjuntos de datos en toda la organización. Puede usar políticas de permisos AWS Identity and Access Management (IAM) para controlar el acceso a conjuntos de datos completos, pero a menudo se requiere un control más detallado para los conjuntos de datos que contienen datos personales de diferente sensibilidad. Por ejemplo, la especificación de la finalidad y la limitación de uso
Los lagos de datos
Puede utilizar la característica de control de acceso basado en etiquetas en Lake Formation. El control de acceso basado en etiquetas es una estrategia de autorización que define permisos basados en atributos. En Lake Formation, estos atributos se denominan etiquetas LF. Con una etiqueta LF, puede adjuntar estas etiquetas a las bases de datos, tablas y columnas del Catálogo de datos y conceder las mismas etiquetas a las entidades principales de IAM. Lake Formation permite realizar operaciones en esos recursos cuando se concede acceso a la entidad principal a un valor de etiqueta que coincide con el valor de la etiqueta del recurso. En la siguiente imagen se muestra cómo asignar etiquetas LF y permisos para proporcionar un acceso diferenciado a los datos personales.

En este ejemplo, se usa la naturaleza jerárquica de las etiquetas. Ambas bases de datos contienen información de identificación personal (PII:true), pero las etiquetas en el nivel de columnas limitan las columnas específicas a los diferentes equipos. En este ejemplo, los directores de IAM que tienen la etiqueta PII:true LF pueden acceder a los recursos de la base de datos que tienen esta etiqueta. AWS Glue Las entidades principales con la etiqueta LF LOB:DataScience pueden acceder a columnas específicas que tengan esta etiqueta, y las entidades principales con la etiqueta LF LOB:Marketing solo pueden acceder a las columnas que tengan esta etiqueta. El equipo de marketing solo puede acceder a la PII que sea pertinente para los casos de uso de marketing y el equipo de ciencia de datos solo puede acceder a la PII que sea pertinente para sus casos de uso.
Zonas locales de AWS
Si necesita cumplir con los requisitos de residencia de los datos, puede implementar recursos que almacenen y procesen datos personales de forma específica Regiones de AWS para cumplir con estos requisitos. También puede utilizarlos Zonas locales de AWS, lo que le ayuda a ubicar los recursos informáticos, de almacenamiento, de bases de datos y otros AWS recursos selectos cerca de grandes centros industriales y de población. Una zona local es una extensión de una Región de AWS que se encuentra en la cercanía geográfica de una gran área metropolitana. Puede colocar tipos específicos de recursos dentro de una zona local, cerca de la región a la que corresponde la zona local. Las zonas locales pueden ayudarlo a cumplir con los requisitos de residencia de datos cuando una región no esté disponible dentro de la misma jurisdicción legal. Cuando utilice las zonas locales, tenga en cuenta los controles de residencia de datos que se hayan implementado en la organización. Por ejemplo, es posible que necesite un control para evitar las transferencias de datos de una zona local específica a otra región. Para obtener más información sobre cómo SCPs mantener las barreras de transferencia de datos transfronterizas, consulte Mejores prácticas para gestionar la residencia de datos al Zonas locales de AWS usar controles de landing zone
AWS Enclaves Nitro
Evalúe su estrategia de segmentación de datos desde el punto de vista del procesamiento, como el procesamiento de los datos personales con un servicio de computación como Amazon Elastic Compute Cloud (Amazon EC2). La computación confidencial, como parte de una estrategia de arquitectura más amplia, puede ayudarlo a aislar el procesamiento de datos personales en un enclave de CPU aislado, protegido y fiable. Los enclaves son máquinas virtuales independientes, reforzadas y muy restringidas. AWS Nitro Enclaves es una característica de Amazon EC2 que puede ayudarlo a crear estos entornos de computación aislados. Para obtener más información, consulte El diseño de seguridad del sistema AWS Nitro (documento técnico).AWS
Nitro Enclaves implementa un kernel que está separado del kernel de la instancia principal. El kernel de la instancia principal no tiene acceso al enclave. Los usuarios no pueden acceder a los datos y las aplicaciones del enclave mediante SSH ni de forma remota. Las aplicaciones que procesan datos personales pueden incrustarse en el enclave y configurarse para usar el socket Vsock del enclave, que permite que el enclave y la instancia principal se comuniquen.
Un caso de uso en el que Nitro Enclaves puede resultar útil es el procesamiento conjunto entre dos procesadores de datos que están separados Regiones de AWS y que podrían no confiar entre sí. En la siguiente imagen se muestra cómo se puede utilizar un enclave para el procesamiento centralizado, una clave de KMS para cifrar los datos personales antes de enviarlos al enclave y una política de AWS KMS key que compruebe que el enclave que solicita el descifrado tenga las medidas únicas en el documento de certificación. Para obtener más información e instrucciones, consulte Uso de la atestación criptográfica con. AWS KMS Para ver una política de claves de ejemplo, consulte Exija una certificación para usar una clave AWS KMS en esta guía.
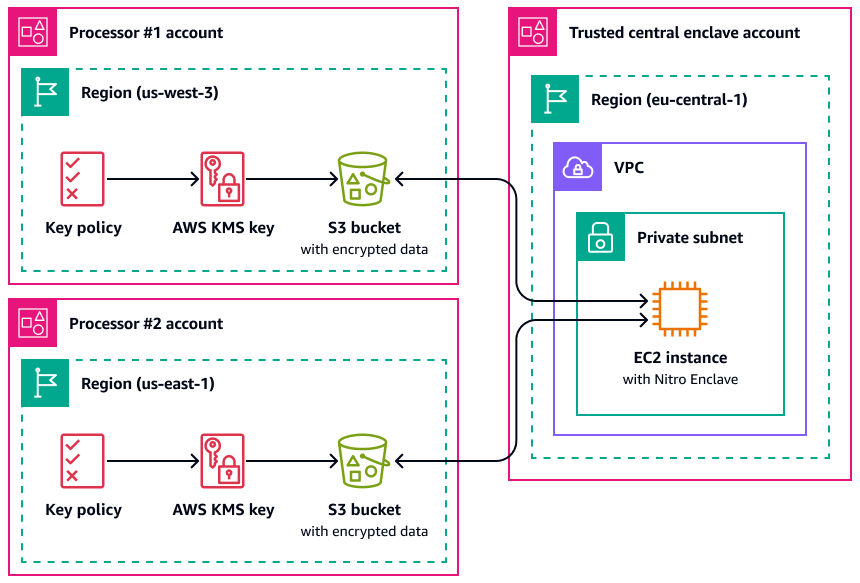
Con esta implementación, solo los procesadores de datos correspondientes y el enclave subyacente tienen acceso a los datos personales en texto plano. El único lugar donde están expuestos los datos, fuera del entorno de los correspondientes procesadores de datos, es en el propio enclave, que está diseñado para evitar el acceso y las manipulaciones.
AWS PrivateLink
Muchas organizaciones quieren limitar la exposición de los datos personales a redes que no sean de confianza. Por ejemplo, si desea mejorar la privacidad del diseño general de la arquitectura de su aplicación, puede segmentar las redes en función de la confidencialidad de los datos (de forma similar a la separación lógica y física de los conjuntos de datos que se describe en la Servicios de AWS y funciones que ayudan a segmentar los datos sección). AWS PrivateLinkle ayuda a crear conexiones unidireccionales y privadas desde sus nubes privadas virtuales (VPCs) a servicios externos a la VPC. Con AWS PrivateLink, puede configurar conexiones privadas específicas para los servicios que almacenan o procesan datos personales en su entorno; no es necesario que se conecte a los puntos de conexión públicos ni que transfiera estos datos a través de redes públicas que no sean de confianza. Al habilitar los puntos finales de AWS PrivateLink servicio para los servicios incluidos en el ámbito de aplicación, no se necesita una pasarela de Internet, un dispositivo NAT, una dirección IP pública, una conexión o una AWS Direct Connect conexión para poder AWS Site-to-Site VPN comunicarse. Cuando te conectas AWS PrivateLink a un servicio que proporciona acceso a datos personales, puedes usar políticas de puntos finales de VPC y grupos de seguridad para controlar el acceso, de acuerdo con la definición del perímetro de datos
AWS Resource Access Manager
AWS Resource Access Manager (AWS RAM) le ayuda a compartir sus recursos de forma segura Cuentas de AWS para reducir la sobrecarga operativa y ofrecer visibilidad y auditabilidad. Cuando planifique su estrategia de segmentación de varias cuentas, considere la posibilidad de AWS RAM compartir los almacenes de datos personales que almacene en una cuenta separada y aislada. Puede compartir esos datos personales con otras cuentas de confianza a fin de poderlos procesar. En AWS RAM, puedes administrar los permisos que definen qué acciones se pueden realizar en los recursos compartidos. AWS RAM Se ha iniciado sesión en todas las llamadas a la API CloudTrail. Además, puede configurar Amazon CloudWatch Events para que le notifique automáticamente eventos específicos en AWS RAM, por ejemplo, cuando se realicen cambios en un recurso compartido.
Si bien puede compartir muchos tipos de AWS recursos con otros Cuentas de AWS mediante políticas basadas en recursos en IAM o políticas de bucket en Amazon S3, AWS RAM ofrece varios beneficios adicionales en materia de privacidad. AWS proporciona a los propietarios de los datos una visibilidad adicional sobre cómo y con quién se comparten los datos en su Cuentas de AWS empresa, lo que incluye:
-
Poder compartir un recurso con una unidad organizativa completa en lugar de actualizar manualmente las listas de cuentas IDs
-
Hacer cumplir el proceso de invitación para iniciar el intercambio si la cuenta del consumidor no forma parte de la organización
-
Visibilidad de las entidades principales de IAM específicas que tienen acceso a cada recurso específico
Si ha utilizado anteriormente una política basada en recursos para administrar un recurso compartido y desea utilizarla AWS RAM en su lugar, utilice la operación de PromoteResourceShareCreatedFromPolicyAPI.
Amazon SageMaker AI
Amazon SageMaker AI
Monitor de SageMaker modelos Amazon
Muchas organizaciones tienen en cuenta la deriva de datos a la hora de entrenar modelos de ML. Una deriva de datos es una variación significativa entre los datos de producción y los datos que se utilizaron para entrenar un modelo de ML, o un cambio significativo en los datos de entrada a lo largo del tiempo. La deriva de datos puede reducir la calidad, la precisión y la imparcialidad generales de las predicciones de los modelos de machine learning. Si la naturaleza estadística de los datos que recibe un modelo de ML mientras está en producción se desvía de la naturaleza de los datos de referencia con los que se entrenó, la precisión de las predicciones podría disminuir. Amazon SageMaker Model Monitor puede monitorear continuamente la calidad de los modelos de aprendizaje automático de Amazon SageMaker AI en producción y monitorear la calidad de los datos. La detección temprana y proactiva de la deriva de datos puede ayudarlo a implementar medidas correctivas, como el nuevo entrenamiento de modelos, la auditoría de los sistemas de las fases previas o la corrección de problemas de calidad de datos. El Monitor de modelos puede reducir la necesidad de supervisar manualmente los modelos o crear más herramientas.
Amazon SageMaker Clarify
Amazon SageMaker Clarify proporciona información sobre el sesgo y la explicabilidad de los modelos. SageMaker Clarify se usa comúnmente durante la preparación de los datos del modelo de aprendizaje automático y la fase de desarrollo general. Los desarrolladores pueden especificar los atributos de interés, como el sexo o la edad, y SageMaker Clarify ejecuta un conjunto de algoritmos para detectar cualquier presencia de sesgo en esos atributos. Una vez ejecutado el algoritmo, SageMaker Clarify proporciona un informe visual con una descripción de las fuentes y las medidas del posible sesgo para que pueda identificar las medidas necesarias para subsanarlo. Por ejemplo, en un conjunto de datos financieros que contenga solo unos pocos ejemplos de préstamos empresariales concedidos a un grupo de edad en comparación con otros, SageMaker podría detectar desequilibrios para evitar un modelo que desfavorezca a ese grupo de edad. También puede comprobar si hay sesgos en los modelos ya entrenados revisando sus predicciones y supervisándolos continuamente para detectar sesgos. Por último, SageMaker Clarify está integrado con Amazon SageMaker AI Experiments para proporcionar un gráfico que explica qué características contribuyeron más al proceso general de elaboración de predicciones de un modelo. Esta información podría ser útil para obtener resultados de explicabilidad y podría ayudarlo a determinar si la entrada de un modelo en particular tiene más influencia de la que debería en el comportamiento general del modelo.
Tarjeta SageMaker modelo Amazon
Amazon SageMaker Model Card puede ayudarle a documentar detalles importantes sobre sus modelos de aprendizaje automático con fines de gobernanza y elaboración de informes. Entre estos detalles se pueden incluir el propietario del modelo, la finalidad general, los casos de uso previstos, las suposiciones realizadas, la clasificación de riesgo de un modelo, los detalles y las métricas del entrenamiento y los resultados de la evaluación. Para obtener más información, consulte Model Explainability with AWS Artificial Intelligence and Machine Learning Solutions (documentoAWS técnico).
Amazon SageMaker Data Wrangler
Amazon SageMaker Data Wrangler
Data Wrangler se puede utilizar como parte del proceso de preparación de datos e ingeniería de características en la PRA. AWS Admite el cifrado de datos en reposo y en tránsito mediante el uso AWS KMS, y utiliza las funciones y políticas de IAM para controlar el acceso a los datos y los recursos. Admite el enmascaramiento de datos a través de AWS Glue Amazon SageMaker Feature Store. Si integras Data Wrangler con AWS Lake Formation, puedes aplicar controles y permisos de acceso a los datos detallados. Incluso puede usar Data Wrangler con Amazon Comprehend para suprimir automáticamente los datos personales de los datos tabulares como parte del flujo de trabajo más amplio de las operaciones de machine learning (MLOps). Para obtener más información, consulte Redactar automáticamente la PII para el aprendizaje automático mediante Amazon SageMaker Data Wrangler
La versatilidad de Data Wrangler le permite enmascarar la información confidencial de muchos sectores, como números de cuentas, números de tarjetas de crédito, números de la seguridad social, nombres de pacientes e historiales médicos y militares. Puede limitar el acceso a cualquier información confidencial o elegir suprimirla.
AWS funciones que ayudan a gestionar el ciclo de vida de los datos
Cuando los datos personales ya no sean necesarios, puede utilizar el ciclo de vida y time-to-live las políticas para los datos de muchos almacenes de datos diferentes. Al configurar las políticas de retención de datos, debe considerar las siguientes ubicaciones que podrían contener datos personales:
-
Bases de datos, como Amazon DynamoDB y Amazon Relational Database Service (Amazon RDS)
-
Buckets de Amazon S3
-
Inicia sesión desde y CloudWatch CloudTrail
-
Datos en caché de migraciones en AWS Database Migration Service (AWS DMS) y proyectos AWS Glue DataBrew
-
Copias de seguridad e instantáneas
Las siguientes funciones Servicios de AWS y las siguientes pueden ayudarle a configurar las políticas de retención de datos en sus AWS entornos:
-
Amazon S3 Lifecycle: un conjunto de reglas que definen acciones que Amazon S3 aplica a un grupo de objetos. En la configuración de Amazon S3 Lifecyle, puede crear acciones de caducidad, que definen cuándo Amazon S3 elimina los objetos caducados en su nombre. Para obtener más información, consulte Administración del ciclo de vida del almacenamiento.
-
Amazon Data Lifecycle Manager: en Amazon EC2, cree una política que automatice la creación, la retención y la eliminación de las instantáneas de Amazon Elastic Block Store (Amazon EBS) y de las Amazon Machine Images respaldadas por EBS (). AMIs
-
Tiempo de duración (TTL) de DynamoDB: defina una marca temporal por elemento que determine cuándo ya no se necesita un elemento. Poco después de la fecha y hora de la marca temporal especificada, DynamoDB elimina el elemento de la tabla.
-
Configuración de retención de CloudWatch registros en Logs: puede ajustar la política de retención de cada grupo de registros a un valor comprendido entre 1 día y 10 años.
-
AWS Backup— Implemente políticas de protección de datos de forma centralizada para configurar, administrar y gobernar su actividad de respaldo en una variedad de AWS recursos, incluidos los buckets S3, las instancias de bases de datos de RDS, las tablas de DynamoDB, los volúmenes de EBS y muchos más. Aplique políticas de respaldo a sus AWS recursos especificando los tipos de recursos o proporcionando una granularidad adicional al aplicarlas en función de las etiquetas de recursos existentes. Audite sobre la actividad de copia de seguridad y cree informes la actividad desde una consola centralizada para cumplir con los requisitos de cumplimiento de las normas de copia de seguridad.
Servicios de AWS y funciones que ayudan a segmentar los datos
La segmentación de datos es el proceso mediante el cual se almacenan los datos en contenedores separados. Esto puede ayudarlo a proporcionar medidas de seguridad y autenticación diferenciadas para cada conjunto de datos y a reducir el alcance del impacto de la exposición en todo el conjunto de datos. Por ejemplo, en lugar de almacenar todos los datos de los clientes en una gran base de datos, puede segmentar estos datos en grupos más pequeños que sean más fáciles de administrar.
Puede utilizar la separación física y lógica para segmentar los datos personales:
-
Separación física: acción de almacenar los datos en almacenes de datos separados o de distribuirlos en recursos de AWS separados. Si bien los datos están separados físicamente, es posible que las mismas entidades principales puedan acceder a ambos recursos. Por eso le recomendamos que combine la separación física y la separación lógica.
-
Separación lógica: acción de aislar los datos mediante controles de acceso. Los diferentes puestos laborales requieren diferentes niveles de acceso a subconjuntos de datos personales. Para ver un ejemplo de política que implementa la separación lógica, consulte Concesión de acceso a atributos específicos de Amazon DynamoDB en esta guía.
La combinación de una separación lógica y física brinda flexibilidad, simplicidad y detalle a la hora de redactar políticas basadas en la identidad y en los recursos para respaldar el acceso diferenciado entre los diferentes puestos laborales. Por ejemplo, desde el punto de vista operativo, crear políticas que separen de forma lógica las diferentes clasificaciones de datos en un único bucket de S3 puede ser complejo. El uso de buckets de S3 específicos para cada clasificación de datos simplifica la configuración y la administración de las políticas.
Servicios de AWS y funciones que ayudan a descubrir, clasificar o catalogar datos
Algunas organizaciones no han empezado a usar herramientas de extracción, carga y transformación (ELT) en su entorno para catalogar los datos de forma proactiva. Es posible que estos clientes se encuentren en una fase temprana de descubrimiento de datos, en la que deseen comprender mejor los datos que almacenan y procesan AWS y cómo están estructurados y clasificados. Puede utilizar Amazon Macie para comprender mejor los datos de PII en Amazon S3. Sin embargo, Amazon Macie no puede ayudarlo a analizar otros orígenes de datos, como Amazon Relational Database Service (Amazon RDS) y Amazon Redshift. Puede usar dos enfoques para acelerar la detección inicial al comienzo de un ejercicio de asignación de datos
-
Método manual: cree una tabla que tenga dos columnas y tantas filas como necesite. En la primera columna, escriba una caracterización de los datos (como nombre de usuario, dirección o género) que pueda aparecer en el encabezado o el cuerpo de un paquete de red o en cualquier servicio que proporcione. Pida al equipo de cumplimiento que complete la segunda columna. En la segunda columna, escriba “sí” si los datos se consideran personales y “no” si no lo son. Indique cualquier tipo de datos personales que se consideren especialmente confidenciales, como la denominación religiosa o los datos sobre la salud.
-
Enfoque automatizado: utilice las herramientas que se proporcionan mediante AWS Marketplace. Una de esas herramientas es Securiti
. Estas soluciones ofrecen integraciones con las que pueden escanear y detectar datos en varios tipos de recursos de AWS , así como activos en otras plataformas de servicios en la nube. Muchas de estas mismas soluciones pueden recopilar y mantener de forma continua un inventario de activos de datos y actividades de procesamiento de datos en un catálogo de datos centralizado. Si confía en una herramienta para realizar una clasificación automatizada, es posible que tenga que ajustar las reglas de detección y clasificación para adaptarlas a la definición de datos personales de la organización.
