Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Desacoplar las relaciones de las tablas durante la descomposición de la base de datos
En esta sección se proporciona orientación sobre cómo desglosar las relaciones de tablas complejas y las operaciones de unión durante la descomposición monolítica de una base de datos. Una combinación de tablas combina filas de dos o más tablas en función de una columna relacionada entre ellas. El objetivo de separar estas relaciones es reducir el alto grado de acoplamiento entre tablas y, al mismo tiempo, mantener la integridad de los datos en todos los microservicios.
Esta sección contiene los siguientes temas:
Estrategia de desnormalización
La desnormalización es una estrategia de diseño de bases de datos que implica introducir intencionalmente redundancia mediante la combinación o duplicación de datos en las tablas. Al dividir una base de datos grande en bases de datos pequeñas, podría tener sentido duplicar algunos datos entre los servicios. Por ejemplo, almacenar los detalles básicos de los clientes, como el nombre y las direcciones de correo electrónico, tanto en un servicio de marketing como en un servicio de pedidos elimina la necesidad de realizar búsquedas constantes entre servicios. El servicio de marketing puede necesitar las preferencias de los clientes y la información de contacto para la segmentación de las campañas, mientras que el servicio de pedidos requiere los mismos datos para procesar los pedidos y las notificaciones. Si bien esto crea cierta redundancia de datos, puede mejorar considerablemente el rendimiento y la independencia del servicio, lo que permite al equipo de marketing gestionar sus campañas sin tener que depender de las consultas de atención al cliente en tiempo real.
Al implementar la desnormalización, céntrese en los campos de acceso frecuente que identifique mediante un análisis cuidadoso de los patrones de acceso a los datos. Puede utilizar herramientas, como Oracle AWR informes opg_stat_statements, para comprender qué datos se recuperan habitualmente juntos. Los expertos en el campo también pueden proporcionar información valiosa sobre las agrupaciones de datos naturales. Recuerde que la desnormalización no es un all-or-nothing enfoque, sino solo datos duplicados que, de forma demostrable, mejoran el rendimiento del sistema o reducen las dependencias complejas.
Reference-by-key estrategia
Una reference-by-key estrategia es un patrón de diseño de base de datos en el que las relaciones entre las entidades se mantienen mediante claves únicas en lugar de almacenar los datos relacionados reales. En lugar de las relaciones tradicionales de clave externa, los microservicios modernos suelen almacenar solo los identificadores únicos de los datos relacionados. Por ejemplo, en lugar de mantener todos los detalles del cliente en la tabla de pedidos, el servicio de pedidos solo almacena el identificador del cliente y recupera información adicional del cliente mediante una llamada a la API cuando es necesario. Este enfoque mantiene la independencia del servicio y, al mismo tiempo, garantiza el acceso a los datos relacionados.
Patrón CQRS
El patrón de segregación de responsabilidades de consultas de comandos (CQRS) separa las operaciones de lectura y escritura de un almacén de datos. Este patrón es particularmente útil en sistemas complejos con requisitos de alto rendimiento, especialmente aquellos con cargas asimétricas read/write . Si su aplicación necesita con frecuencia datos combinados de varias fuentes, puede crear un modelo CQRS dedicado en lugar de uniones complejas. Por ejemplo, en lugar de unir Product Inventory tablas y tablas en cada solicitud, mantenga una Product Catalog tabla consolidada que contenga los datos necesarios. Pricing Los beneficios de este enfoque pueden superar los costos de la tabla adicional.
Considere un escenario en el que ProductPrice, y Inventory los servicios necesiten con frecuencia información sobre el producto. En lugar de configurar estos servicios para acceder directamente a las tablas compartidas, cree un Product Catalog servicio dedicado. Este servicio mantiene su propia base de datos que contiene la información consolidada del producto. Actúa como una fuente única de información fiable para las consultas relacionadas con los productos. Cuando los detalles del producto, los precios o los niveles de inventario cambian, los servicios respectivos pueden publicar eventos para actualizar el Product Catalog servicio. Esto proporciona coherencia en los datos y, al mismo tiempo, mantiene la independencia del servicio. La siguiente imagen muestra esta configuración, en la que Amazon EventBridge
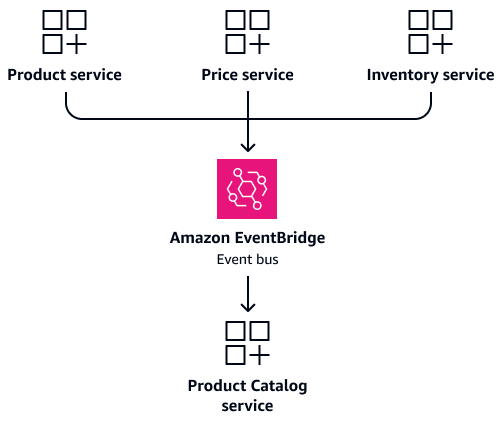
Como se explica en Sincronización de datos basada en eventos la siguiente sección, mantenga el modelo CQRS actualizado durante los eventos. Cuando los detalles del producto, los precios o los niveles de inventario cambian, los servicios respectivos publican los eventos. El Product Catalog servicio se suscribe a estos eventos y actualiza su vista consolidada. Esto proporciona lecturas rápidas sin uniones complejas y mantiene la independencia del servicio.
Sincronización de datos basada en eventos
La sincronización de datos basada en eventos es un patrón en el que los cambios en los datos se capturan y propagan como eventos, lo que permite que diferentes sistemas o componentes mantengan los estados de los datos sincronizados. Cuando los datos cambien, en lugar de actualizar inmediatamente todas las bases de datos relacionadas, publique un evento para notificar a los servicios suscritos. Por ejemplo, cuando un cliente cambia su dirección de envío en el Customer servicio, un CustomerUpdated evento inicia las actualizaciones del Order servicio y del Delivery servicio según la programación de cada servicio. Este enfoque reemplaza las uniones rígidas de tablas por actualizaciones flexibles y escalables basadas en eventos. Es posible que algunos servicios tengan datos desactualizados durante un período breve, pero la compensación es una mejor escalabilidad del sistema y una mayor independencia del servicio.
Implementar alternativas a las uniones de tablas
Comience la descomposición de la base de datos con operaciones de lectura, ya que suelen ser más fáciles de migrar y validar. Una vez que las rutas de lectura estén estables, aborde las operaciones de escritura más complejas. Para requisitos críticos de alto rendimiento, considere la posibilidad de implementar el patrón CQRS. Utilice una base de datos independiente y optimizada para las lecturas y mantenga otra para las escrituras.
Cree sistemas resilientes añadiendo lógica de reintento para las llamadas entre servicios e implementando las capas de almacenamiento en caché adecuadas. Supervise de cerca las interacciones de los servicios y configure alertas para detectar problemas de coherencia de los datos. El objetivo final no es una coherencia perfecta en todas partes, sino crear servicios independientes que funcionen bien y, al mismo tiempo, mantengan una precisión de datos aceptable para las necesidades de su empresa.
La naturaleza disociada de los microservicios introduce las siguientes nuevas complejidades en la administración de datos:
-
Los datos se distribuyen. Los datos ahora residen en bases de datos independientes, que son administradas por servicios independientes.
-
La sincronización en tiempo real entre los servicios no suele ser práctica y, en última instancia, requiere un modelo de coherencia.
-
Las operaciones que antes se realizaban dentro de una sola transacción de base de datos ahora abarcan varios servicios.
Para hacer frente a estos desafíos, haga lo siguiente:
-
Implemente una arquitectura basada en eventos: utilice las colas de mensajes y la publicación de eventos para propagar los cambios en los datos entre los servicios. Para obtener más información, consulte Creación de arquitecturas impulsadas por eventos
en entornos sin servidores. -
Adopte el patrón de orquestación tipo saga: este patrón le ayuda a gestionar las transacciones distribuidas y a mantener la integridad de los datos en todos los servicios. Para obtener más información, consulte Crear una aplicación distribuida sin servidor utilizando un patrón de orquestación tipo saga
en blogs. AWS -
Diseñe pensando en los errores: incorpore mecanismos de reintento, disyuntores y transacciones de compensación para gestionar los problemas de la red o los fallos del servicio.
-
Utilice el sello de versiones: realice un seguimiento de las versiones de los datos para gestionar los conflictos y asegurarse de que se apliquen las actualizaciones más recientes.
-
Conciliación periódica: implemente procesos de sincronización de datos periódicos para detectar y corregir cualquier incoherencia.
Ejemplo basado en escenarios
El siguiente ejemplo de esquema tiene dos tablas, una Customer tabla y una tabla: Order
-- Customer table CREATE TABLE customer ( customer_id INT PRIMARY KEY, first_name VARCHAR(100), last_name VARCHAR(100), email VARCHAR(255), phone VARCHAR(20), address TEXT, created_at TIMESTAMP ); -- Order table CREATE TABLE order ( order_id INT PRIMARY KEY, customer_id INT, order_date TIMESTAMP, total_amount DECIMAL(10,2), status VARCHAR(50), FOREIGN KEY (customer_id) REFERENCES customers(id) );
El siguiente es un ejemplo de cómo se puede utilizar un enfoque desnormalizado:
CREATE TABLE order ( order_id INT PRIMARY KEY, customer_id INT, -- Reference only customer_first_name VARCHAR(100), -- Denormalized customer_last_name VARCHAR(100), -- Denormalized customer_email VARCHAR(255), -- Denormalized order_date TIMESTAMP, total_amount DECIMAL(10,2), status VARCHAR(50) );
La nueva Order tabla tiene el nombre del cliente y las direcciones de correo electrónico que están desnormalizados. customer_idSe hace referencia a y no hay ninguna restricción de clave externa en la tabla. Customer Los beneficios de este enfoque desnormalizado son los siguientes:
-
El
Orderservicio puede mostrar el historial de pedidos con los detalles del cliente y no requiere llamadas a la API al microservicio.Customer -
Si el
Customerservicio no funciona, sigue siendo completamente funcional.Order -
Las consultas para el procesamiento de pedidos y la elaboración de informes se ejecutan más rápido.
El siguiente diagrama muestra una aplicación monolítica que recupera los datos de los pedidos mediante getOrder(customer_id) llamadas a la createOrder(Order
order) API y a la API al Order microservicio. getOrder(order_id) getCustomerOders(customer_id)
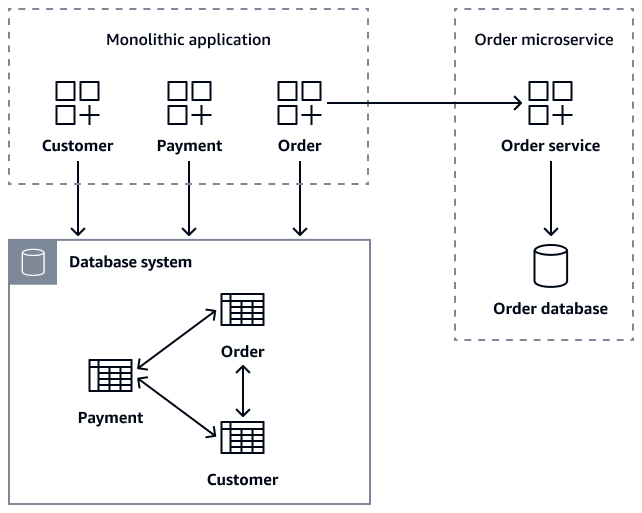
Durante la migración de los microservicios, puede mantener la Order tabla en la base de datos monolítica como medida de seguridad transitoria y garantizar que la aplicación antigua siga funcionando. Sin embargo, es fundamental que todas las nuevas operaciones relacionadas con los pedidos se envíen a través de la API de Order microservicios, que mantiene su propia base de datos y, al mismo tiempo, graba en la base de datos antigua como respaldo. Este patrón de escritura doble proporciona una red de seguridad. Permite una migración gradual y, al mismo tiempo, mantiene la estabilidad del sistema. Una vez que todos los clientes hayan migrado correctamente al nuevo microservicio, puede dejar obsoleta la Order tabla antigua de la base de datos monolítica. Tras descomponer la aplicación monolítica y su base de datos en microservicios independientes Customer y Order microservicios, mantener la coherencia de los datos se convierte en el principal desafío.
