Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Diseño de arquitecturas de IA sin servidor
Traducir los principios de la IA sin servidores a sistemas del mundo real requiere una arquitectura bien pensada. El objetivo es integrarlos de forma flexible en canalizaciones modulares e inteligentes que se Servicios de AWS escalen de forma elástica y respondan en tiempo real.
En esta sección se proporciona una guía prescriptiva sobre cómo ensamblar sistemas de IA nativos de la nube mediante servicios AWS sin servidor, como la orquestación generativa de la IA, la inferencia en tiempo real y la computación perimetral. Cada patrón arquitectónico corresponde a un caso de uso empresarial común, lo que garantiza la relevancia y la aplicabilidad.
En esta sección
Patrones de arquitectura fundamentales
En una arquitectura de aplicaciones tradicional basada en eventos, el sistema está estructurado en cuatro capas lógicas que disocian las preocupaciones y, al mismo tiempo, permiten la escalabilidad y la capacidad de respuesta. En la parte superior, la capa de aplicación gestiona las interacciones de los usuarios y los eventos de la interfaz de usuario APIs, lo que a menudo desencadena eventos específicos del dominio en el sistema. Por debajo, la capa de orquestación gestiona los flujos de trabajo, las reglas empresariales y la secuenciación de eventos mediante herramientas como máquinas de estado o flujos de trabajo sin servidor. La capa de servicio contiene microservicios o funciones modulares y reutilizables que responden a los eventos y ejecutan la lógica central. En la base, la capa de datos es responsable de la persistencia, la transmisión y el origen de los eventos. La capa de datos aprovecha servicios como bases de datos, almacenes de objetos o registros de eventos para emitir y consumir eventos de cambio. En conjunto, estas capas dan soporte a una arquitectura flexible, escalable y fácil de mantener, en la que los eventos impulsan el flujo en todo el conjunto.
De manera similar, los sistemas de IA sin servidor están compuestos por servicios impulsados por eventos y acoplados de manera flexible que pueden escalarse, evolucionar y recuperarse de forma independiente. Para diseñar estos sistemas con coherencia y escalabilidad, es esencial ver la arquitectura en cinco capas distintas. Cada capa cumple una función específica y se asigna directamente a una capa diseñada específicamente Servicios de AWS. El siguiente diagrama muestra cada capa.
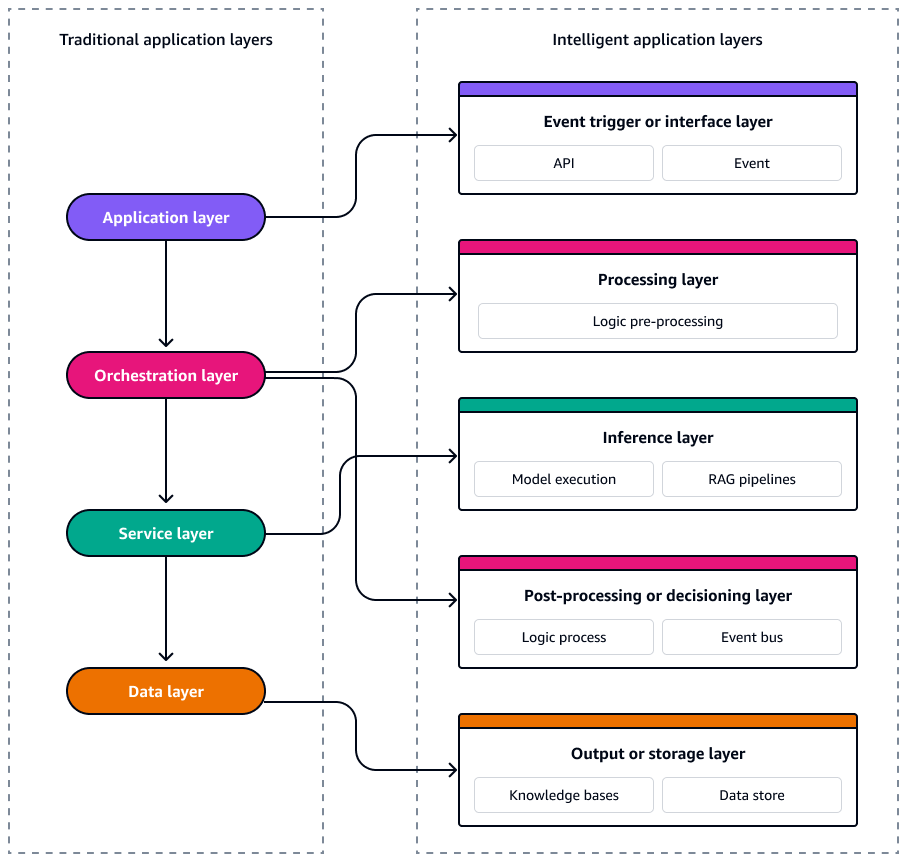
Estas cinco capas forman el modelo para crear aplicaciones inteligentes basadas en eventos que sean resilientes, observables y optimizadas tanto en términos de costes como de rendimiento.
Capa de interfaz o desencadenante de eventos
El desencadenador de eventos o la capa de interfaz es el punto de entrada a su sistema de IA sin servidor. Captura las interacciones de los usuarios, los eventos del sistema o los cambios en los datos y los emite como eventos estructurados en la arquitectura. Permite la orquestación asíncrona y desacopla las entradas anteriores de la lógica de procesamiento descendente.
Las responsabilidades de la capa de activación de eventos incluyen las siguientes:
-
Capture las acciones de los usuarios, como los clics, los mensajes y las cargas
-
Emite eventos de dominio o notificaciones de cambio
-
Normalice los datos entrantes para el consumo posterior
Servicios de AWS Entre los que se utilizan habitualmente con esta capa se incluyen los siguientes:
-
Amazon API Gateway acepta las entradas de los usuarios a través de REST o WebSocket APIs.
-
Amazon EventBridge direcciona los eventos internos o externos mediante un registro de esquemas.
-
Amazon Simple Storage Service (Amazon S3) se activa al crear objetos, como cargas de documentos y archivos multimedia.
-
Amazon Kinesis y Amazon Managed Streaming for Apache Kafka (Amazon MSK) incorporan eventos de streaming a escala.
Ejemplo: una solicitud de atención al cliente enviada a través de un formulario web activa una EventBridge regla que inicia un flujo de trabajo de agente de Amazon Bedrock en sentido descendente.
Capa de procesamiento
La capa de procesamiento transforma o enriquece los datos antes de pasarlos al modelo de IA. Gestiona las tareas de preprocesamiento, como la validación de entradas, el formateo, el etiquetado de metadatos, la detección del idioma y el enriquecimiento de datos mediante tablas de consulta o externas. APIs
Las responsabilidades de la capa de procesamiento incluyen las siguientes:
-
Valide y normalice la entrada sin procesar.
-
Extraiga o inserte metadatos, como el idioma y el identificador del cliente.
-
Lógica de ruta o bifurcación basada en los atributos de los datos.
Servicios de AWS Entre los que se utilizan habitualmente con esta capa se incluyen los siguientes:
-
AWS Lambdaes un cómputo sin estado y basado en eventos para la lógica de transformación.
-
AWS Step Functionsorganice tareas de preprocesamiento de varios pasos.
-
Amazon Comprehend proporciona detección del lenguaje, reconocimiento de entidades o análisis de sentimientos como parte del preprocesamiento.
Ejemplo: las reclamaciones de seguro cargadas se escanean para obtener información de identificación personal (PII) y el tipo de documento mediante Lambda y Amazon Comprehend antes del resumen de IA.
Capa de inferencia
Como núcleo del sistema de IA, la capa de inferencia ejecuta la inferencia del aprendizaje automático (ML) o del modelo básico (FM). Puede incluir uno o más modelos (generativos, predictivos o de clasificación) según el caso de uso.
Las responsabilidades de la capa de inferencia incluyen las siguientes:
-
Ejecute la inferencia del modelo ML o FM.
-
Genere predicciones, clasificaciones o contenido generado.
-
Integre el contexto de generación aumentada de recuperación (RAG) cuando corresponda.
Servicios de AWS Entre los que se utilizan habitualmente con esta capa se incluyen los siguientes:
-
Amazon Bedrock proporciona inferencias de modelos básicos (texto, imagen, multimodal) de proveedores como Anthropic, Amazon (para Amazon Nova) Meta y. Mistral
-
Amazon SageMaker Serverless Inference ejecuta modelos de aprendizaje automático personalizados a escala.
-
Amazon Bedrock Agents ofrece un razonamiento basado en un gran modelo de lenguaje (LLM) y una orquestación basada en objetivos.
Ejemplo: un agente de Amazon Bedrock utiliza Amazon Nova Pro para generar una respuesta a una consulta de soporte compleja, basándose en el conocimiento empresarial que utiliza RAG.
Capa de posprocesamiento o toma de decisiones
La capa de posprocesamiento o de toma de decisiones refina los resultados de la inferencia o actúa en función de ellos. Puede formatear la respuesta, registrar los resultados, invocar acciones posteriores o tomar decisiones en función de la confianza del modelo, las clasificaciones o las reglas empresariales externas.
Entre las responsabilidades de la capa de posprocesamiento o de toma de decisiones se incluyen las siguientes:
-
Formatee la salida AI para sistemas o pantallas posteriores.
-
Activa una llamada APIs o lógica condicional.
-
Enrute los datos enriquecidos para almacenarlos o analizarlos.
Servicios de AWS Entre los que se utilizan habitualmente con esta capa se incluyen los siguientes:
-
Lambda puede formatear los resultados, aplicar transformaciones o realizar llamadas. APIs
-
Amazon Simple Notification Service (Amazon SNS) y EventBridge emite más eventos en función de los resultados del modelo.
-
Step Functions aplica una lógica de cadena, por ejemplo, aumenta el caso de apoyo si el sentimiento es igual a «enfado».
Ejemplo: una recomendación de producto de un LLM se valida de forma cruzada con el inventario en tiempo real mediante una función Lambda antes de enviar la recomendación al usuario.
Capa de salida o almacenamiento
Por último, la capa de salida o almacenamiento se encarga de la entrega de los resultados a los usuarios o los sistemas y conserva los resultados estructurados para utilizarlos en circuitos de auditoría, análisis o retroalimentación.
Las responsabilidades de la capa de salida o almacenamiento incluyen las siguientes:
-
Envíe los resultados de la IA a los usuarios finales mediante APIs o UIs.
-
Conserva las salidas y los registros estructurados.
-
Introdúzcalos en lagos de datos o en procesos de reentrenamiento.
Servicios de AWS Entre los que se utilizan habitualmente con esta capa se incluyen los siguientes:
-
Amazon S3 almacena registros de inferencias, resúmenes o contenido generado.
-
Amazon DynamoDB proporciona almacenamiento de valores clave de baja latencia para la salida de IA específica de la sesión.
-
Amazon OpenSearch Service proporciona resultados estructurados de índices para búsquedas y análisis.
-
API Gateway y WebSocket APIs proporciona respuestas de retorno a clientes frontend o móviles.
Ejemplo: un resumen de un documento legal, generado por Amazon Bedrock, se almacena en Amazon S3 y se indexa en OpenSearch Service para permitir la búsqueda empresarial semántica.
Consideraciones de diseño en todas las capas
Las siguientes consideraciones y patrones de diseño clave se aplican a todas las capas arquitectónicas:
-
Resiliencia: cada capa debe fallar y volver a intentarlo de forma independiente (por ejemplo, colas de letra muerta () DLQs en Lambda).
-
Observabilidad: envía registros, trazas y métricas estructurados de cada etapa a Amazon CloudWatch para detectar desviaciones en el comportamiento.
-
Seguridad: utilice la separación de roles AWS Identity and Access Management(IAM) y AWS Key Management Service(AWS KMS) para el cifrado de datos en todas las capas.
-
Optimización de costes: utilice la ejecución asíncrona siempre que sea posible y elija modelos del tamaño adecuado.
-
Extensibilidad: el diseño modular permite reemplazar o actualizar los servicios de forma independiente.
Estas cinco capas forman una arquitectura de referencia modular, escalable y sin servidores para cargas de trabajo impulsadas por IA. AWS Cada capa se puede desarrollar, implementar y optimizar de forma independiente, lo que permite una iteración rápida, la excelencia operativa y una clara separación de las preocupaciones en todos los ámbitos empresariales.
Al utilizar este patrón de capas como estructura de diseño, las empresas pueden estandarizar su enfoque de la IA sin servidores y acelerar el paso del prototipo a la producción con confianza.
Consideraciones de diseño de la arquitectura
La arquitectura de IA sin servidor AWS le permite crear aplicaciones inteligentes que son modulares, escalables y aptas para producción. Ya sea que implemente modelos en la periferia, organice procesos de inferencia de varios pasos o cree asistentes de IA generativos, Servicios de AWS puede impulsar la próxima generación de aplicaciones nativas de la IA.
Al diseñar una arquitectura de IA sin servidor, tenga en cuenta los siguientes enfoques clave de diseño y mejores prácticas:
-
Seguridad: utilice funciones de IAM específicas, cifre las solicitudes y los resultados y restrinja el acceso a las API.
-
Observabilidad: integre y personalice los registros para CloudWatch cada AWS X-Ray etapa del proceso.
-
Escalabilidad: utilice únicamente componentes sin servidor, como Lambda, Amazon Bedrock y Serverless Inference. SageMaker
-
Latencia: aproveche Lambda @Edge, la simultaneidad aprovisionada o la inferencia asíncrona.
-
Modularidad: diseñe canalizaciones mediante activadores de eventos y funciones aisladas para cada tarea.
-
Reutilización: parametriza las indicaciones, usa capas Lambda compartidas y desacopla la lógica mediante Step Functions.
