Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
¿Qué es Amazon OpenSearch Serverless?
Amazon OpenSearch Serverless es una opción sin servidor y bajo demanda para Amazon OpenSearch Service que elimina la complejidad operativa del aprovisionamiento, la configuración y el ajuste de los clústeres. OpenSearch Es ideal para organizaciones que prefieren no administrar sus propios clústeres o que no cuentan con los recursos y el conocimiento experto necesarios para operar implementaciones a gran escala. Con OpenSearch Serverless, puede buscar y analizar grandes volúmenes de datos sin administrar la infraestructura subyacente.
Una colección OpenSearch sin servidor es un grupo de OpenSearch índices que funcionan juntos para respaldar una carga de trabajo o un caso de uso específicos. Las colecciones simplifican las operaciones en comparación con los OpenSearch clústeres autogestionados, que requieren un aprovisionamiento manual.
Las colecciones utilizan el mismo almacenamiento de alta capacidad, distribuido y de alta disponibilidad que los dominios de OpenSearch servicio aprovisionados, pero reducen aún más la complejidad al eliminar la configuración y los ajustes manuales. Los datos de una colección se cifran en tránsito. OpenSearch Serverless también es compatible con los OpenSearch paneles de control, lo que proporciona una interfaz para el análisis de datos.
OpenSearch Serverless es compatible con el código abierto. OpenSearch A medida que se lanzan nuevas versiones, OpenSearch Serverless actualiza automáticamente las colecciones para incorporar nuevas funciones, correcciones de errores y mejoras de rendimiento.
OpenSearch Serverless admite las mismas operaciones de API de ingesta y consulta que la suite de código OpenSearch abierto, por lo que puede seguir utilizando sus clientes y aplicaciones actuales. Sus clientes deben ser compatibles con la versión OpenSearch 3.x para poder funcionar con Serverless. OpenSearch Para obtener más información, consulte Ingerir datos en colecciones de Amazon OpenSearch Serverless.
Temas
Casos de uso de Serverless OpenSearch
OpenSearch Serverless admite dos casos de uso principales:
-
Análisis de registros: el segmento de análisis de registros se centra en analizar grandes volúmenes de datos de series temporales semiestructurados y generados por máquinas para obtener información operativa y sobre el comportamiento de los usuarios.
-
Full-text búsqueda: el segmento de búsqueda de texto completo potencia las aplicaciones de sus redes internas (sistemas de gestión de contenido, documentos legales) y las aplicaciones orientadas a Internet, como la búsqueda de contenido de sitios web de comercio electrónico.
Al crear una colección, debe elegir uno de estos casos de uso. Para obtener más información, consulte Elección de un tipo de colección.
Funcionamiento
OpenSearch Los clústeres tradicionales tienen un único conjunto de instancias que realizan operaciones de indexación y búsqueda, y el almacenamiento de índices está estrechamente relacionado con la capacidad de procesamiento. Por el contrario, OpenSearch Serverless utiliza una arquitectura nativa de la nube que separa los componentes de indexación (ingesta) de los componentes de búsqueda (consulta), con Amazon S3 como almacenamiento de datos principal para los índices.
Esta arquitectura desacoplada permite escalar las funciones de búsqueda e indexación de forma independiente entre ellas y de los datos indexados en S3. La arquitectura también proporciona aislamiento para las operaciones de ingesta y consulta, de modo que puedan ejecutarse de forma simultánea sin contención de recursos.
Cuando escribe datos en una colección, OpenSearch Serverless los distribuye a las unidades informáticas de indexación. Las unidades de computación de indexación ingieren los datos entrantes y mueven los índices a S3. Al realizar una búsqueda en los datos de la recopilación, OpenSearch Serverless dirige las solicitudes a las unidades de cálculo de búsqueda que contienen los datos que se están consultando. Las unidades de computación de búsqueda descargan los datos indexados de forma directa desde S3 (si aún no están almacenados en la memoria caché local), ejecutan operaciones de búsqueda y realizan agregaciones.
La siguiente imagen ilustra esta arquitectura desacoplada:
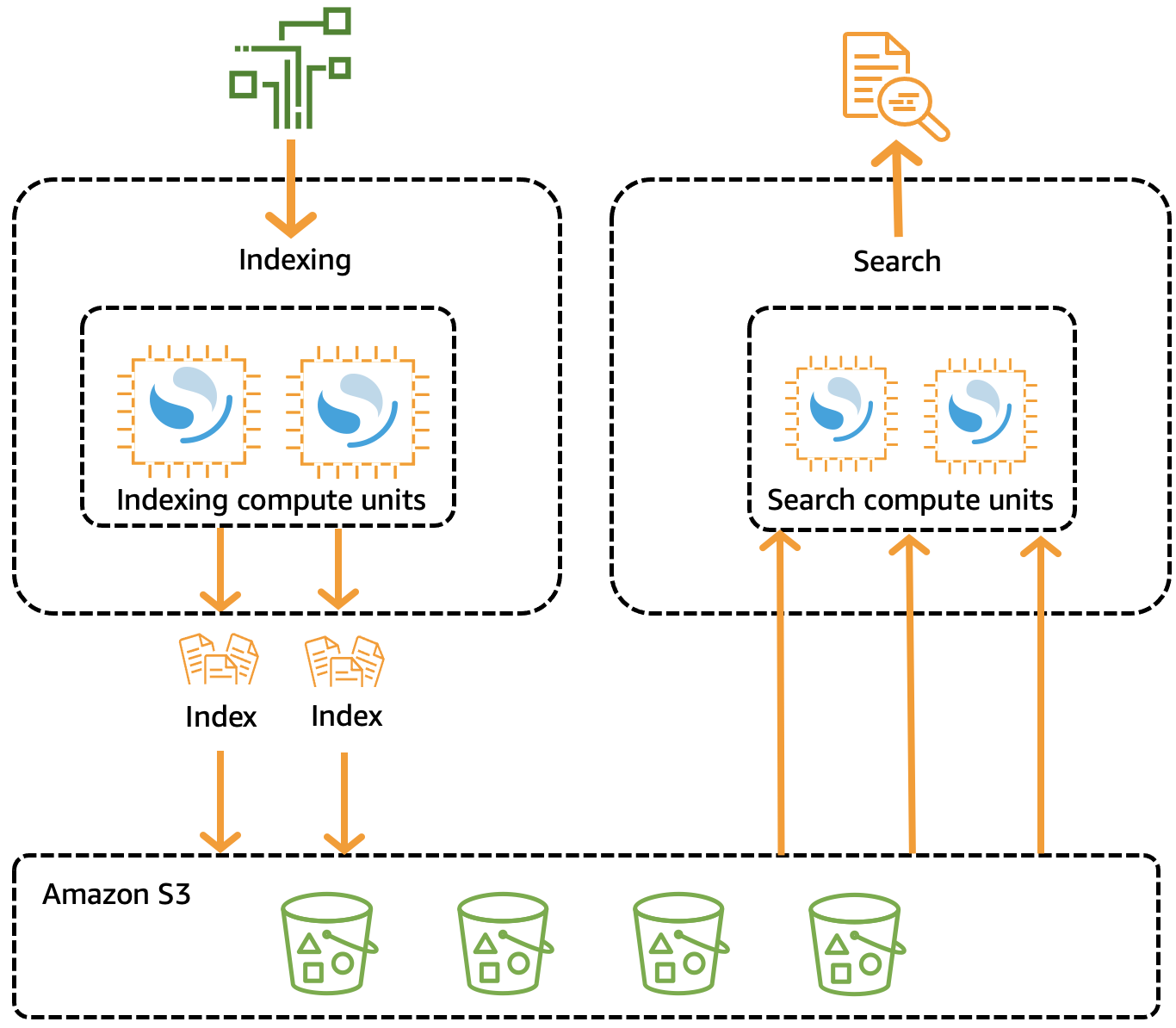
OpenSearch La capacidad de cómputo sin servidor para la ingesta, búsqueda y consulta de datos se mide en unidades de OpenSearch cómputo (OCU). Cada OCU es una combinación de 6 GiB de memoria y la CPU virtual (vCPU) correspondiente, así como la transferencia de datos a Amazon S3.
OpenSearch Serverless aprovisiona las OCU por separado para la búsqueda y la indexación. OpenSearch Serverless solo agrega OCU adicionales para buscar e ingerir según sea necesario para respaldar las colecciones, de acuerdo con los límites de capacidad que especifique. La capacidad no se reduce verticalmente a medida que disminuye el uso de computación.
Para obtener información sobre cómo se facturan estas OCU, consulta los precios de Amazon OpenSearch Service
Elección de un tipo de colección
OpenSearch Serverless admite tres tipos de recopilación principales:
Series temporales: el segmento de análisis de registros que analiza grandes volúmenes de datos semiestructurados generados por máquinas en tiempo real y que proporciona información sobre operaciones, seguridad, comportamiento de usuarios y rendimiento del negocio.
nota
Las colecciones de series temporales solo están disponibles para las colecciones clásicas. NextGenActualmente, las colecciones solo admiten los tipos de búsqueda y búsqueda vectorial.
Búsqueda: Full-text búsqueda que permite utilizar aplicaciones en redes internas, como sistemas de gestión de contenido y repositorios de documentos legales, así como aplicaciones con acceso a Internet, como la búsqueda de sitios de comercio electrónico y el descubrimiento de contenido.
Búsqueda vectorial: la búsqueda semántica basada en incrustaciones vectoriales simplifica la administración de datos vectoriales y habilita experiencias de búsqueda mejoradas con machine learning (ML). Es compatible con aplicaciones de IA generativa, como chatbots, asistentes personales y detección de fraude.
El tipo de colección se elige cuando se crea una colección por primera vez:
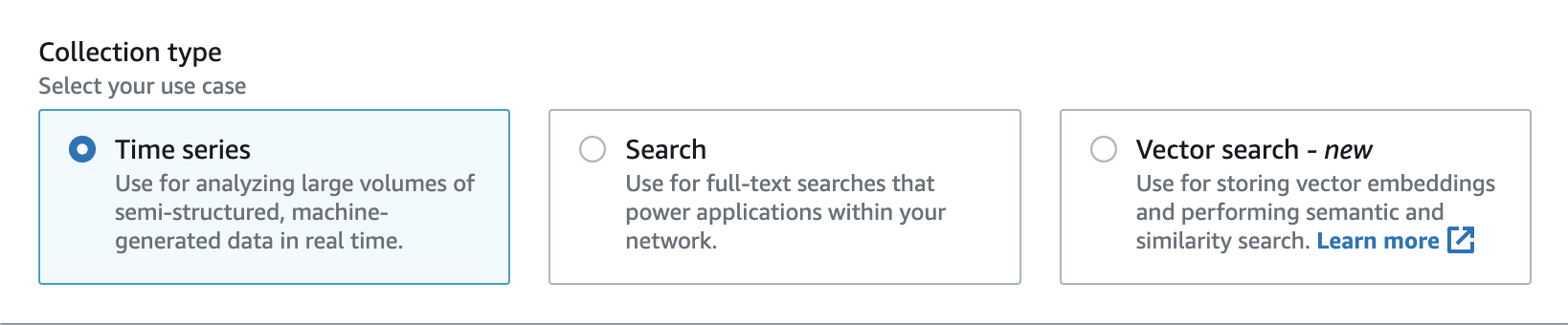
El tipo de colección que elija dependerá del tipo de datos que piensa incorporar a la colección y de cómo piensa consultarlos. No puede cambiar el tipo de colección después de crearla.
Los tipos de colecciones presentan las siguientes diferencias notables:
-
En el caso de las colecciones de búsqueda y de búsqueda vectorial, todos los datos se almacenan en un almacenamiento en caliente para garantizar tiempos de respuesta rápidos a las consultas. Las colecciones de series temporales utilizan una combinación de almacenamiento en caliente y templado, donde los datos más recientes se guardan en un almacenamiento en caliente para optimizar los tiempos de respuesta a las consultas para los datos a los que se accede con más frecuencia.
-
En el caso de las colecciones de series temporales, no puedes indexarlas por identificador de documento personalizado ni actualizarlas mediante solicitudes incompletas. Esta operación se reserva para los casos de uso de búsqueda. En su lugar, puede actualizar por ID de documento. Para obtener más información, consulte Operaciones y permisos de OpenSearch API compatibles.
-
Para las recopilaciones de series temporales y de búsqueda, no puede utilizar índices de tipo k-NN.
compatible Regiones de AWS
OpenSearch Serverless está disponible en un subconjunto de Regiones de AWS ese OpenSearch Servicio en el que está disponible. Para ver una lista de las regiones compatibles, consulta los puntos de conexión y las cuotas de Amazon OpenSearch Service en. Referencia general de AWS
Limitaciones
OpenSearch Serverless tiene las siguientes limitaciones:
-
Algunas operaciones OpenSearch de la API no son compatibles. Consulte Operaciones y permisos de OpenSearch API compatibles.
-
Algunos OpenSearch complementos no son compatibles. Consulte OpenSearch Plugins compatibles.
-
Actualmente, no hay forma de migrar automáticamente los datos de un dominio de OpenSearch servicio gestionado a una colección sin servidor. Debe volver a indexar los datos desde un dominio a una colección.
-
Cross-account no se admite el acceso a las colecciones. No puede incluir colecciones de otras cuentas en las políticas de cifrado o de acceso a los datos.
-
No se admiten los OpenSearch complementos personalizados.
-
Las instantáneas automatizadas son compatibles con las colecciones OpenSearch sin servidor. No se admiten las instantáneas manuales. Para obtener más información, consulte Hacer copias de seguridad de las colecciones mediante instantáneas.
-
Cross-Region no se admiten la búsqueda ni la replicación.
-
Hay límites para la cantidad de recursos sin servidor que puede tener en una sola cuenta y región. Consulte Cuotas OpenSearch sin servidor.
-
El intervalo de actualización de los índices de las colecciones de búsqueda y serie temporal es de aproximadamente 10 segundos.
-
El número de fragmentos, el número de intervalos y el intervalo de actualización no se pueden modificar y son gestionados por Serverless. OpenSearch La estrategia de partición se basa en el tipo de colección y el tráfico. Por ejemplo, una colección de series temporales escala las particiones principales en función de los cuellos de botella del tráfico de escritura.
