Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
¿Qué es Amazon Managed Service para Apache Flink?
Con Amazon Managed Service para Apache Flink, se puede usar Java, Scala, Python o SQL para procesar y analizar datos de streaming. El servicio le permite crear y ejecutar código en orígenes de streaming y orígenes estáticas para realizar análisis de series temporales, alimentar paneles en tiempo real y crear métricas en tiempo real.
Se puede crear aplicaciones con el lenguaje que elija en Managed Service para Apache Flink mediante bibliotecas de código abierto basadas en Apache Flink
Managed Service para Apache Flink proporciona la infraestructura subyacente para sus aplicaciones de Apache Flink. Gestiona capacidades esenciales, como el aprovisionamiento de recursos informáticos, la resiliencia de conmutación por error de zonas de disponibilidad, computación paralela, escalado automático y copias de seguridad de aplicaciones (implementadas como puntos de control e instantáneas). Se puede utilizar las características de programación de alto nivel de Flink (como operadores, funciones, fuentes y receptores) del mismo modo que las utiliza cuando aloja usted mismo la infraestructura de Flink.
Decida entre utilizar Managed Service para Apache Flink o Managed Service para Apache Flink Studio
Tiene dos opciones para ejecutar sus trabajos de Flink con Amazon Managed Service para Apache Flink. Con Managed Service para Apache Flink, puede crear aplicaciones de Flink en Java, Scala o Python (y SQL integrado) mediante un IDE de su elección y las API de tabla o de Apache Flink Datastream. Con Managed Service para Apache Flink Studio se pueden consultar flujos de datos de forma interactiva en tiempo real, y crear y ejecutar fácilmente aplicaciones de procesamiento de flujos mediante SQL, Python y Scala estándares.
Se puede seleccionar el método que mejor se adapte a su caso de uso. Si no está seguro, en esta sección se ofrecerá una guía general para ayudarle.
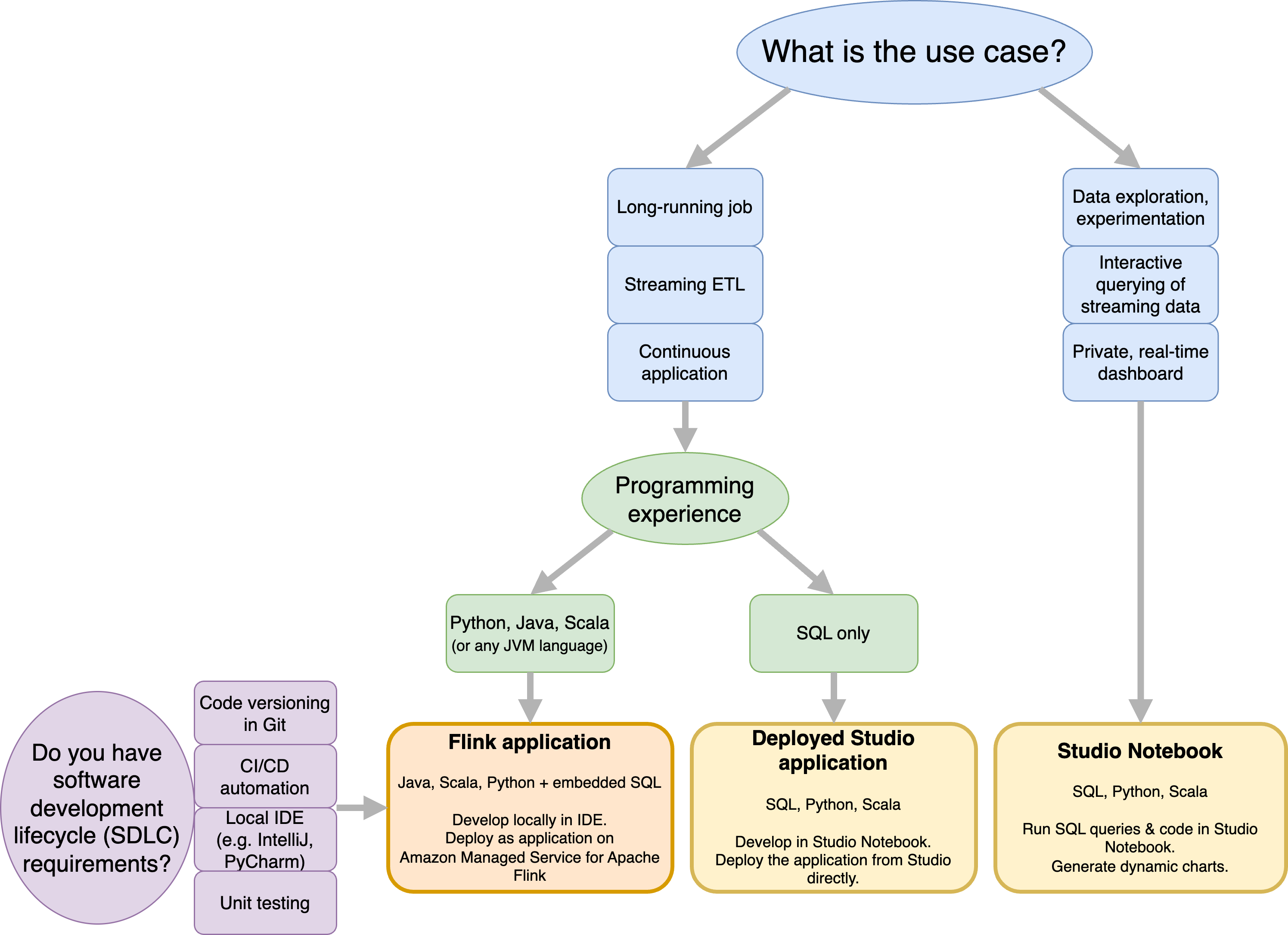
Antes de decidir si utilizar Amazon Managed Service para Apache Flink o Amazon Managed Service para Apache Flink Studio, debería considerar su caso de uso.
Si planea utilizar una aplicación de larga duración que se encargue de cargas de trabajo como el flujo de ETL o las aplicaciones continuas, debería utilizar Managed Service para Apache Flink. Esto se debe a que puede crear su aplicación Flink con las API de Flink directamente en el IDE que elija. El desarrollo local con su IDE también garantiza que pueda aprovechar los procesos y herramientas comunes del ciclo de vida de desarrollo de software (SDLC), como el control de versiones de código en Git, la CI/CD automatización o las pruebas unitarias.
Si está interesado en la exploración de datos ad hoc, desea consultar datos de streaming de forma interactiva o crear paneles privados en tiempo real, Managed Service para Apache Flink Studio le ayudará a cumplir estos objetivos con tan solo unos clics. Los usuarios familiarizados con SQL pueden implementar directamente desde Studio una aplicación de larga duración.
nota
Se puede convertir su portátil Studio en una aplicación de larga duración. Sin embargo, si desea integrarlas con sus herramientas de SDLC, como el control de versiones de código en Git y la CI/CD automatización, o técnicas como las pruebas unitarias, le recomendamos Managed Service for Apache Flink que utilice el IDE que prefiera.
Selección de las API de Apache Flink que se utilizarán en Managed Service para Apache Flink
Se pueden crear aplicaciones con Java, Python y Scala en Managed Service para Apache Flink con las API de Apache Flink en el IDE de su elección. Se pueden encontrar instrucciones sobre cómo crear aplicaciones mediante la API de Flink Datastream y la API de tabla en la documentación. Se puede seleccionar el idioma en el que crea su aplicación Flink y las API que utiliza para satisfacer mejor las necesidades de su aplicación y sus operaciones. Si no está seguro, en esta sección se ofrecer una guía general para ayudarle.
Elección de una API de Flink
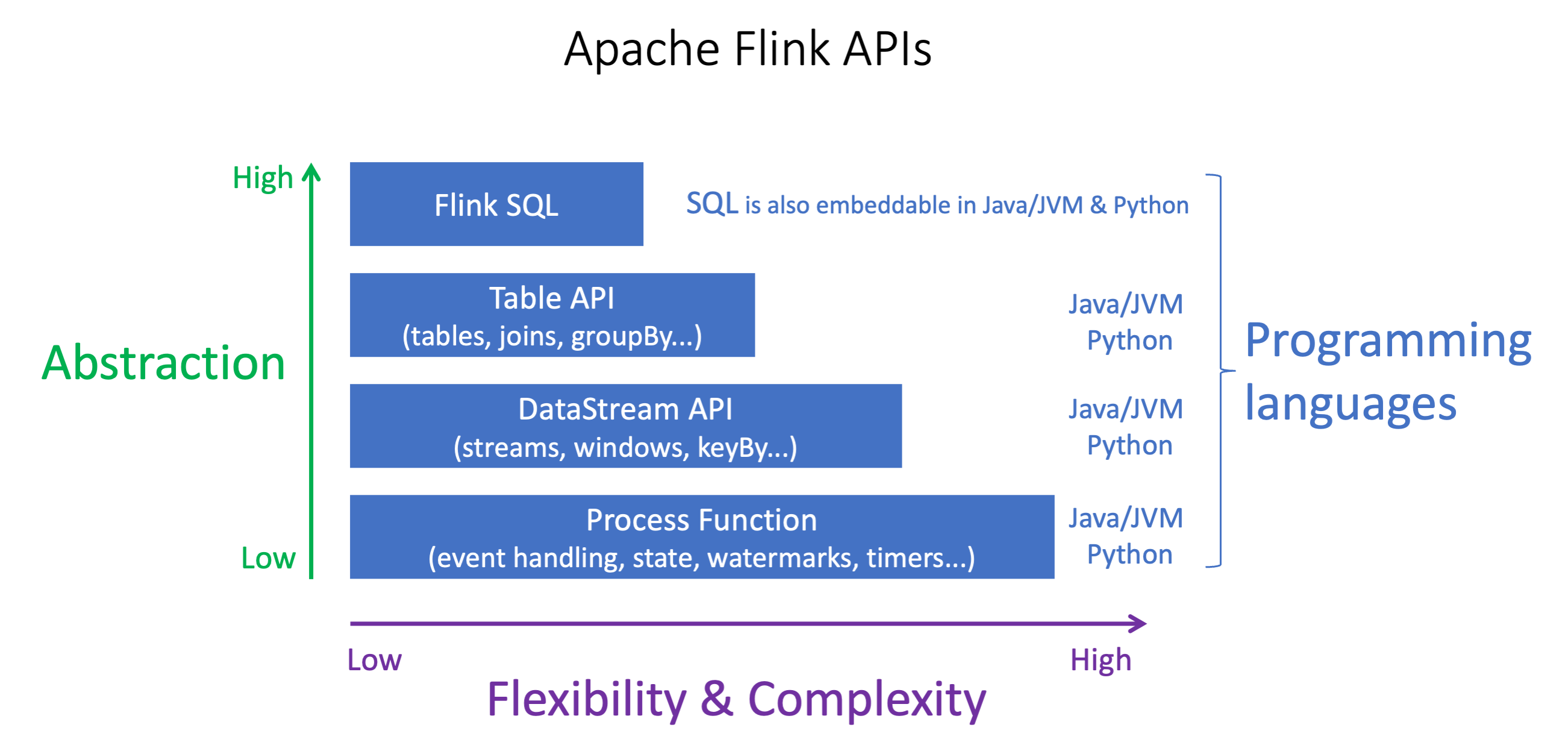
Las API de Apache Flink tienen diferentes niveles de abstracción que pueden afectar a la forma en que decida crear su aplicación. Son expresivas y flexibles y se pueden usar juntas para crear su aplicación. No es necesario utilizar una sola API de Flink. Se puede obtener más información sobre las API de Flink en la documentación de Apache Flink
Flink ofrece cuatro niveles de abstracción de API: Flink SQL, Table API, API y Process Function, que se utiliza junto con la DataStream API. DataStream Todos son compatibles con Amazon Managed Service para Apache Flink. Se recomienda empezar con un nivel de abstracción más alto siempre que sea posible; sin embargo, algunas funciones de Flink solo están disponibles con la API de Datastream, donde se puede crear su aplicación en Java, Python o Scala. Debería considerar el uso de la API de Datastream si:
Se requiere un control minucioso sobre el estado
Se desea aprovechar la posibilidad de llamar a una base de datos externa o a un punto de conexión de forma asíncrona (p. ej., para realizar inferencias)
Se desea utilizar temporizadores personalizados (p. ej., para implementar ventanas personalizadas o gestionar eventos de forma tardía)
-
Se desea tener la capacidad de modificar el flujo de su aplicación sin restablecer el estado
nota
Elección de un idioma con la API de DataStream:
SQL se puede incrustar en cualquier aplicación de Flink, independientemente del lenguaje de programación elegido.
Si planea usar la DataStream API, Python no admite todos los conectores.
Si necesita un bajo latency/high rendimiento, debería considerarlo Java/Scala independientemente de la API.
Si planea usar Async IO en la API de Process Functions, necesitará usar Java.
La elección de la API también puede afectar a su capacidad de desarrollar la lógica de la aplicación sin tener que restablecer el estado. Esto depende de una característica específica, la capacidad de establecer el UID en los operadores, que solo está disponible en la API de DataStream para Java y Python. Para obtener más información, consulte Set UUIDs For All Operators
Introducción a los flujos de datos
Se puede empezar por crear una aplicación de Managed Service para Apache Flink que lea y procese continuamente datos de streaming. A continuación, cree el código con el IDE que prefiera y pruébelo con datos de streaming en directo. También puede configurar los destinos a los que desea que Managed Service para Apache Flink envíe los resultados.
Para comenzar, se recomienda que lea las secciones siguientes:
De manera alternativa, puede comenzar con la creación de un cuaderno de Managed Service para Apache Flink Studio que le permite consultar flujos de datos de forma interactiva en tiempo real y crear y ejecutar fácilmente aplicaciones de procesamiento de flujos mediante SQL, Python y Scala estándares. Con unos pocos clics Consola de administración de AWS, puede lanzar un bloc de notas sin servidor para consultar flujos de datos y obtener resultados en cuestión de segundos. Para comenzar, se recomienda que lea las secciones siguientes:
