Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Incorporar los datos de Amazon Redshift al AWS Glue Data Catalog
Puede gestionar los datos analíticos en los almacenes de datos de Amazon Redshift en AWS Glue Data Catalog el (catálogo de datos) y unificar los lagos de datos de Amazon S3 y los almacenes de datos de Amazon Redshift. Amazon Redshift es un servicio de almacenamiento de datos en la nube totalmente gestionado y a escala de petabytes. AWS Un almacenamiento de datos de Amazon Redshift es una colección de recursos informáticos denominados nodos que se organizan en un grupo llamado clúster. Cada clúster ejecuta un motor Amazon Redshift y contiene una o más bases de datos.
En Amazon Redshift, puede crear clústeres aprovisionados y espacios de nombres sin servidor de Amazon Redshift y registrarlos con el Catálogo de datos. De este modo, puede unificar los datos en el almacenamiento administrado de Amazon Redshift (RMS) y los buckets de Amazon S3, así como acceder a los datos desde motores analíticos compatibles con Apache Iceberg.
Con el registro de los espacios de nombres y los clústeres, puede proporcionar acceso a los datos sin necesidad de copiarlos o moverlos. Para obtener más información sobre el registro de clústeres y espacios de nombres en Amazon Redshift, consulte Registro de clústeres y espacios de nombres de Amazon Redshift en el AWS Glue Data Catalog.
En Amazon Redshift, puede compartir datos a través de recursos compartidos de datos o mediante el registro de espacios de nombres y clústeres con el Catálogo de datos. Con los recursos compartidos de datos, que funcionan en el nivel de objeto de base de datos individual, debe habilitar el uso compartido de cada tabla o vista. Por el contrario, la publicación de espacios de nombres funciona en el nivel de clúster o espacio de nombres. Al registrar un clúster o un espacio de nombres en el Catálogo de datos, todas las bases de datos y tablas que contiene se comparten automáticamente, sin tener que configurar el uso compartido de objetos individuales.
En el Catálogo de datos, puede crear un catálogo federado para cada espacio de nombres o clúster. Se habla de catálogo federado cuando apunta a una entidad ajena al Catálogo de datos. Las tablas y vistas del espacio de nombres de Amazon Redshift se muestran como tablas individuales en el Catálogo de datos. Puede compartir las bases de datos y tablas en el catálogo federado con entidades principales de IAM y usuarios de SAML seleccionados en la misma cuenta o en otra cuenta con Lake Formation. También puede incluir expresiones de filtro de filas y columnas para restringir el acceso a determinados datos. Para obtener más información, consulte Filtrado de datos y seguridad de celda en Lake Formation.
El Catálogo de datos admite una jerarquía de metadatos de tres niveles que incluye catálogos, bases de datos y tablas (y vistas). Al registrar un espacio de nombres en el Catálogo de datos, la jerarquía de datos de Amazon Redshift se asigna a la jerarquía de tres niveles del Catálogo de datos de la siguiente manera:
-
El espacio de nombres de Amazon Redshift pasa a ser un catálogo de varios niveles en el Catálogo de datos.
La base de datos asociada de Amazon Redshift está registrada como catálogo en el Catálogo de datos.
-
El esquema de Amazon Redshift se convierte en una base de datos en el Catálogo de datos.
-
La tabla de Amazon Redshift se convierte en una tabla en el Catálogo de datos.
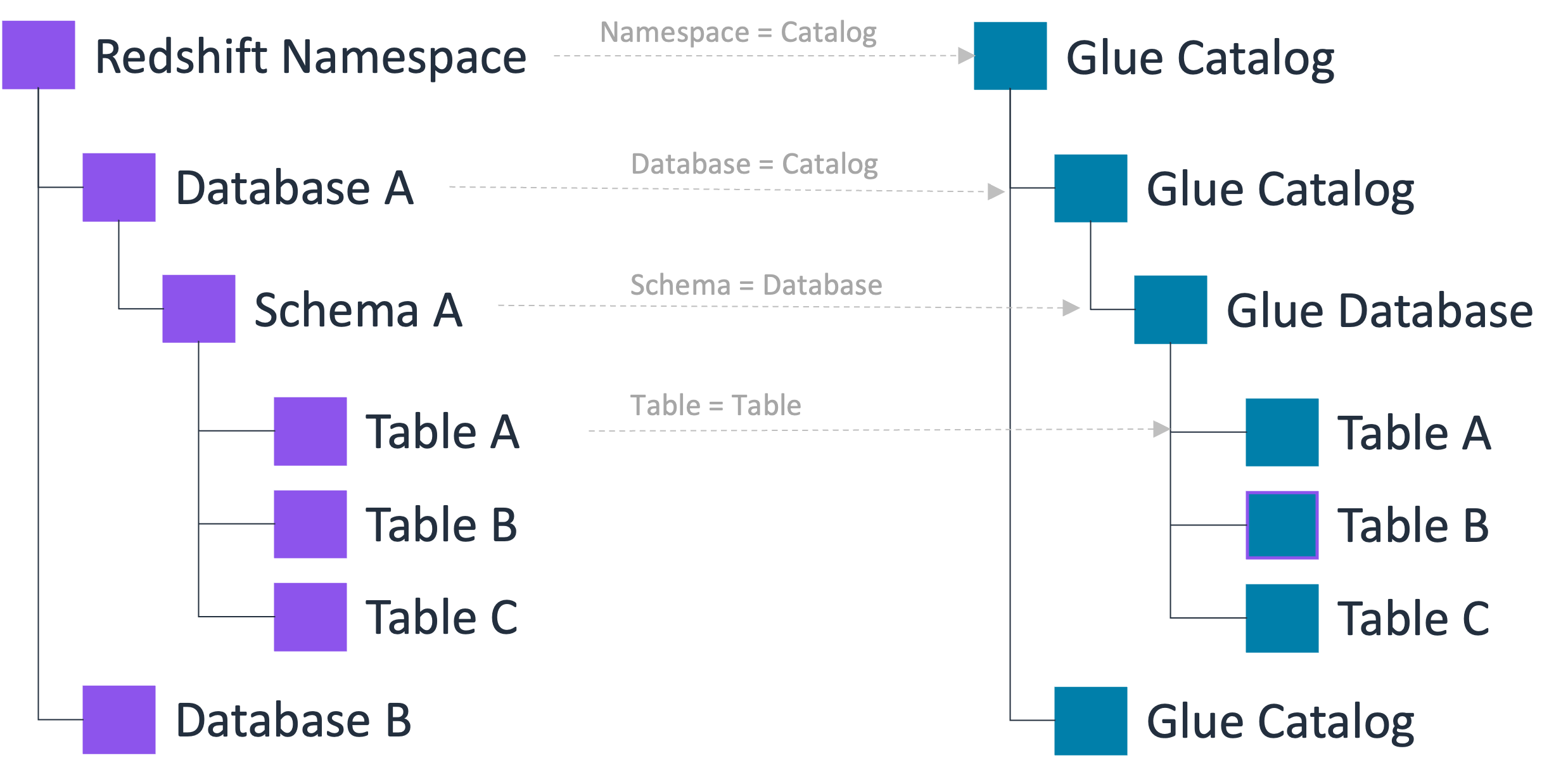
Con esta jerarquía de metadatos de tres niveles, puede acceder a las tablas de Amazon Redshift mediante la notación de tres partes: “catalog1/catalog2.database.table” del Catálogo de datos. Además, los equipos de datos pueden mantener la misma organización que Amazon Redshift utiliza para organizar las tablas dentro de la cuenta del Catálogo de datos.
En Lake Formation, puede administrar de forma segura los datos de Amazon Redshift mediante un control de acceso detallado para los recursos del Catálogo de datos. Con esta integración, puede administrar, proteger y consultar datos analíticos de un único catálogo con un mecanismo de control de acceso común.
Para conocer las limitaciones, consulte Limitaciones a la hora de incorporar los datos del almacén de datos de Amazon Redshift al AWS Glue Data Catalog.
Temas
Ventajas principales
El registro de clústeres y espacios de nombres de Amazon Redshift con los lagos de datos de Amazon S3 AWS Glue Data Catalog y los almacenes de datos de Amazon Redshift y unificar los datos entre ellos ofrece las siguientes ventajas:
Experiencia de consulta uniforme: consulte los datos administrados de Amazon Redshift y los datos en los buckets de Amazon S3 mediante cualquier motor de consultas compatible con Apache Iceberg, como Amazon EMR sin servidor y Amazon Athena, sin tener que mover ni copiar los datos.
-
Acceso uniforme a los datos en todos los servicios: no necesita actualizar los nombres de las bases de datos y las tablas de sus canalizaciones de datos cuando accede a las mismas fuentes de datos federadas desde diferentes servicios de AWS análisis, ya que las fuentes de datos están registradas en el catálogo de datos.
Control de acceso detallado: puede aplicar permisos de Lake Formation para administrar el acceso a los orígenes de datos federados mediante permisos de control de acceso detallados.
Funciones y responsabilidades
| Rol | Responsabilidad |
| Administrador de clúster productor de Amazon Redshift |
Registra el clúster o el espacio de nombres en el Catálogo de datos. |
| Administrador de lago de datos de Lake Formation |
Acepta la invitación al clúster o espacio de nombres, crea catálogos federados y concede acceso a los catálogos federados a otras entidades principales. |
| Administrador de solo lectura de Lake Formation | Descubre el catálogo federado y consulta las tablas de Amazon Redshift en el catálogo federado. |
| Rol de transferencia de datos |
Amazon Redshift asume en su nombre la transferencia de datos hacia y desde el bucket de Amazon S3. |
A continuación, se muestran los pasos generales para proporcionar acceso a los usuarios a un espacio de nombres de Amazon Redshift:
-
En Amazon Redshift, el administrador del clúster productor registra un clúster o un espacio de nombres en el Catálogo de datos.
-
El administrador del lago de datos acepta la invitación al espacio de nombres del administrador del clúster productor de Amazon Redshift y crea un catálogo federado en el Catálogo de datos.
Tras completar este paso, puede administrar el catálogo de espacios de nombres de Amazon Redshift en el Catálogo de datos.
-
Conceda permisos a los usuarios en catálogos, bases de datos y tablas. Puede compartir todo el catálogo de espacios de nombres o un subconjunto de tablas con usuarios de la misma cuenta o de otra cuenta.
