Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
¿Qué es Amazon Data Firehose?
Amazon Data Firehose es un servicio totalmente gestionado para entregar datos de streaming
Para obtener más información sobre las soluciones de AWS big data, consulte Big Data en AWS
Conozca los conceptos clave
Al empezar a utilizar Amazon Data Firehose, es recomendable comprender los siguientes conceptos.
- Flujo de Firehose
-
Entidad subyacente de Amazon Data Firehose. Para usar Amazon Data Firehose, se crea un flujo de Firehose y, a continuación, se le envían datos. Para obtener más información, consulte Tutorial: Crear un flujo de Firehose desde la consola y Enviar datos a un flujo de Firehose.
- Registro
-
Datos de interés que el productor de datos envía a un flujo de Firehose. Cada registro puede pesar hasta 1000 KB.
- Productor de datos
-
Los productores envían los registros a los flujos de Firehose. Por ejemplo, un servidor web que envía datos de registro a un flujo de Firehose es un productor de datos. También puede configurar el flujo de Firehose para que lea automáticamente los datos de un flujo de datos de Kinesis existente y los cargue en los destinos. Para obtener más información, consulte Enviar datos a un flujo de Firehose.
- Tamaño e intervalo del búfer
-
Amazon Data Firehose almacena en búfer los datos de streaming entrantes hasta un tamaño determinado o durante un período de tiempo determinado antes de entregarlos a los destinos. Buffer Sizeestá en MBs y Buffer Interval está en segundos.
Descripción del flujo de datos en Amazon Data Firehose
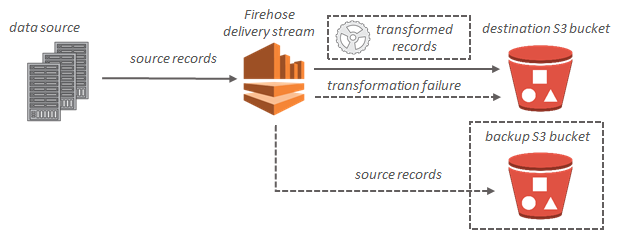
En el caso de los destinos de Amazon S3, los datos de streaming se entregan en el bucket de S3. Si habilita la transformación de datos, puede realizar una copia de seguridad de los datos de origen en otro bucket de Amazon S3.
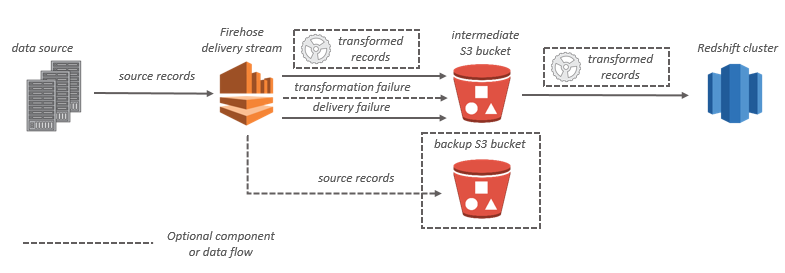
En el caso de los destinos de Amazon Redshift, los datos de streaming se entregan primero en el bucket de S3. A continuación, Amazon Data Firehose emite un comando COPY de Amazon Redshift para cargar los datos del bucket de S3 en el clúster de Amazon Redshift. Si habilita la transformación de datos, puede realizar una copia de seguridad de los datos de origen en otro bucket de Amazon S3.
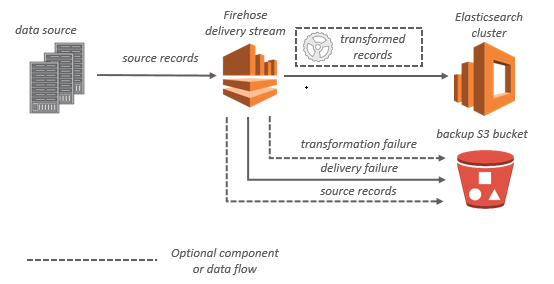
En el caso de los destinos de OpenSearch servicio, los datos de streaming se envían a su clúster de OpenSearch servicios y, si lo prefiere, se puede hacer una copia de seguridad de ellos en su bucket de S3 de forma simultánea.
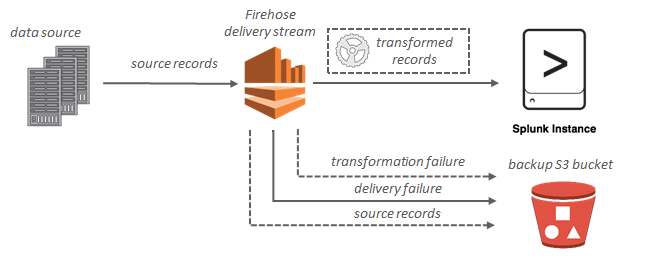
Si el destino es Splunk, los datos de streaming se entregan a Splunk y se puede hacer un backup de ellos en el bucket de S3 simultáneamente.