Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Elegir un servicio AWS de análisis
Dar el primer paso
|
Finalidad
|
Ayude a determinar qué servicios de AWS análisis son los más adecuados para su organización.
|
|
Última actualización
|
24 de septiembre de 2025
|
|
Servicios cubiertos
|
|
Introducción
Los datos son fundamentales para las empresas modernas. Las personas y las aplicaciones deben acceder y analizar de forma segura los datos, que provienen de fuentes nuevas y diversas. El volumen de datos también aumenta constantemente, lo que puede provocar que las organizaciones tengan dificultades para capturar, almacenar y analizar todos los datos necesarios.
Para hacer frente a estos desafíos, es necesario crear una arquitectura de datos moderna que separe todos los silos de datos para obtener análisis e información (incluidos los datos de terceros) y que haga que todos los miembros de la organización puedan acceder a ellos en un solo lugar y con un buen control. end-to-end También es cada vez más importante conectar los sistemas de análisis y aprendizaje automático (ML) para permitir el análisis predictivo.
Esta guía de decisiones le ayuda a formular las preguntas correctas para construir su arquitectura de datos moderna a partir de AWS los servicios. En ella se explica cómo desglosar los silos de datos (conectando el lago de datos y los almacenes de datos), los silos del sistema (conectando el aprendizaje automático y la analítica) y los silos de personal (poniendo los datos en manos de todos los miembros de la organización).
AWS Comprenda los servicios de análisis
Una estrategia de datos moderna se basa en un conjunto de componentes tecnológicos que le ayudan a gestionar los datos, acceder a ellos, analizarlos y actuar en función de ellos. También le ofrece varias opciones para conectarse a las fuentes de datos. Una estrategia de datos moderna debería permitir a sus equipos:
-
Utilice las herramientas o técnicas que prefiera
-
Utilice la inteligencia artificial (IA) para encontrar respuestas a preguntas específicas sobre sus datos
-
Gestione quién tiene acceso a los datos con los controles de seguridad y gobierno de datos adecuados
-
Elimine los silos de datos para obtener lo mejor de los lagos de datos y de los almacenes de datos diseñados específicamente
-
Almacene cualquier cantidad de datos, a bajo costo y en formatos de datos abiertos y basados en estándares
-
Conecte sus lagos de datos, almacenes de datos, bases de datos operativas, aplicaciones y fuentes de datos federadas en un todo coherente
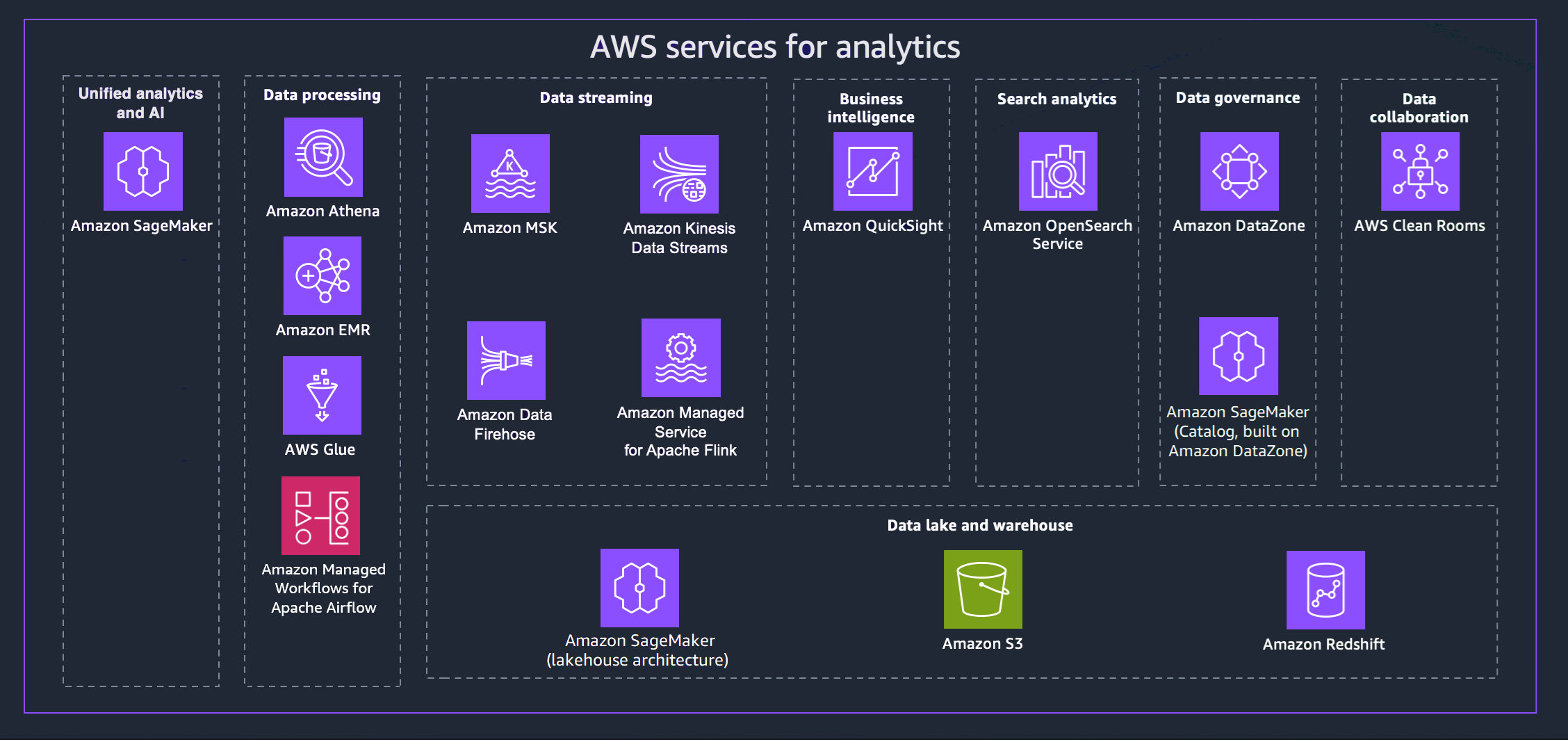
AWS ofrece una variedad de servicios para ayudarlo a lograr una estrategia de datos moderna. En el siguiente diagrama, se AWS muestran los servicios de análisis que abarca esta guía. Las pestañas siguientes proporcionan detalles adicionales.
- Unified analytics and AI
-
La próxima generación de Amazon SageMaker combina capacidades de análisis y aprendizaje AWS automático (ML) ampliamente adoptadas para ofrecer una experiencia integrada de análisis e inteligencia artificial, lo que proporciona un acceso unificado a todos sus datos. Con Amazon SageMaker Unified Studio, puede colaborar y crear más rápido con AWS herramientas conocidas para el desarrollo de modelos, el desarrollo de aplicaciones de IA generativa, el procesamiento de datos y el análisis de SQL, todo ello acelerado por Amazon Q Developer, nuestro asistente de IA generativa para el desarrollo de software. Acceda a sus datos desde lagos de datos, almacenes de datos o fuentes federadas y de terceros, con una gobernanza integrada para cumplir con los requisitos de seguridad empresarial.
- Data processing
-
-
Amazon Athena le ayuda a analizar los datos no estructurados, semiestructurados y estructurados almacenados en Amazon S3. Algunos ejemplos son datos en CSV, JSON o con formatos de columnas, como Apache Parquet y Apache ORC. Puede utilizar Athena para ejecutar consultas ad hoc con ANSI SQL y sin necesidad de agregar los datos o cargarlos en Athena. Athena se integra con Quick Suite y otros AWS servicios. AWS Glue Data Catalog También puede analizar datos a escala con Trino, sin necesidad de gestionar la infraestructura, y crear análisis en tiempo real con Apache Flink y Apache Spark.
-
Amazon EMR es una plataforma de clústeres gestionada que simplifica la ejecución de marcos de big data, como Apache Hadoop y Apache Spark, AWS para procesar y analizar grandes cantidades de datos. Mediante el uso de estos marcos de trabajo y proyectos de código abierto relacionados, puede procesar datos para fines de análisis y cargas de trabajo de inteligencia empresarial. Amazon EMR también le permite transformar y mover grandes cantidades de datos hacia y desde otros almacenes de AWS datos y bases de datos, como Amazon S3.
-
Con AWS Glueél, puede descubrir y conectarse a más de 100 fuentes de datos diferentes y administrar sus datos en un catálogo de datos centralizado. Puede crear, ejecutar y supervisar visualmente las canalizaciones de ETL para cargar datos en sus lagos de datos. Además, puede buscar y consultar datos catalogados de forma inmediata con Athena, Amazon EMR y Amazon Redshift Spectrum.
-
Amazon Managed Workflows for Apache Airflow (MWAA) es una implementación totalmente gestionada de Apache Airflow que facilita la creación, programación y supervisión de los flujos de trabajo de datos en la nube. MWAA escala automáticamente la capacidad del flujo de trabajo para satisfacer sus necesidades y se integra con los servicios de seguridad. AWS
Puede utilizar la MWAA para organizar los flujos de trabajo en todos sus servicios de análisis, incluidos el procesamiento de datos, los trabajos de ETL y los procesos de aprendizaje automático.
- Data streaming
-
Con Amazon Managed Streaming for Apache Kafka (Amazon MSK), puede crear y ejecutar aplicaciones que utilicen Apache Kafka para procesar datos de streaming. Amazon MSK proporciona las operaciones de plano de control, como las de creación, actualización y eliminación de clústeres. Le permite utilizar operaciones de plano de datos de Apache Kafka, como producir y consumir datos.
Con Amazon Kinesis Data Streams, puede recopilar y procesar grandes flujos de registros de datos en tiempo real. El tipo de datos utilizado puede incluir datos de registros de infraestructura de TI, registros de aplicaciones, redes sociales, fuentes de datos de mercado y datos de secuencias de clics en sitios web.
Amazon Data Firehose es un servicio totalmente gestionado para entregar datos de streaming en tiempo real a destinos como Amazon S3, Amazon Redshift, OpenSearch Amazon Service, Splunk y Apache Iceberg Tables. También puedes enviar datos a cualquier punto final HTTP personalizado o puntos finales HTTP propiedad de proveedores de servicios externos compatibles, como Datadog, Dynatrace, MongoDB, New Relic LogicMonitor, Coralogix y Elastic.
Con Amazon Managed Service para Apache Flink, puede usar Java, Scala, Python o SQL para procesar y analizar los datos de streaming. Puede crear y ejecutar código en fuentes de streaming y fuentes estáticas para realizar análisis de series temporales, alimentar cuadros de mando en tiempo real y métricas.
- Business intelligence
-
Quick Suite ofrece a los responsables de la toma de decisiones la oportunidad de explorar e interpretar la información en un entorno visual interactivo. En un único panel de datos, Quick Suite puede incluir AWS datos, datos de terceros, macrodatos, datos de hojas de cálculo, datos de SaaS, datos B2B y más. Con Quick Suite Q, puede utilizar un lenguaje natural para hacer preguntas sobre sus datos y recibir una respuesta. Por ejemplo, «¿Cuáles son las categorías más vendidas en California?»
- Search analytics
-
Amazon OpenSearch Service aprovisiona todos los recursos OpenSearch del clúster y lo lanza. También detecta y reemplaza automáticamente los nodos de OpenSearch servicio defectuosos, lo que reduce la sobrecarga asociada a las infraestructuras autogestionadas. Puede usar OpenSearch Service Direct Query para analizar datos en Amazon S3 y otros AWS servicios.
- Data governance
-
Con Amazon DataZone, puede gestionar y controlar el acceso a los datos mediante controles detallados. Estos controles contribuyen a garantizar el acceso con el nivel adecuado de privilegios y contexto. Amazon DataZone simplifica su arquitectura al integrar los servicios de administración de datos, incluidos Amazon Redshift, Athena, Quick Suite AWS Glue, fuentes locales y fuentes de terceros.
- Data collaboration
-
AWS Clean Roomses un espacio de trabajo de colaboración seguro en el que puede analizar conjuntos de datos colectivos sin proporcionar acceso a los datos sin procesar. Puede colaborar con otras empresas eligiendo los socios con los que quiere colaborar, seleccionando sus conjuntos de datos y configurando controles que mejoren la privacidad de esos socios. Al ejecutar consultas, AWS Clean Rooms lee los datos de la ubicación original de esos datos y aplica reglas de análisis integradas para ayudarle a mantener el control sobre esos datos.
- Data lake and data warehouse
-
La próxima generación de Amazon SageMaker es totalmente compatible con Apache Iceberg, lo que le permite unificar los datos entre los lagos de datos de Amazon Simple Storage Service (Amazon S3) y los almacenes de datos de Amazon Redshift. Esto permite crear aplicaciones de análisis, IA y aprendizaje automático (ML) en una sola copia de datos. Gracias a las integraciones sin ETL, puede transmitir datos de fuentes operativas prácticamente en tiempo real, ejecutar consultas federadas en múltiples fuentes y acceder a los datos con herramientas compatibles con Apache Iceberg. Puede proteger sus datos definiendo permisos detallados que se apliquen a todas sus herramientas y motores de análisis y aprendizaje automático.
Amazon S3 puede almacenar y proteger prácticamente cualquier cantidad y tipo de datos, que puede utilizar como base de su lago de datos. Amazon S3 proporciona funciones de gestión para que pueda optimizar, organizar y configurar el acceso a sus datos para satisfacer sus requisitos empresariales, organizativos y de conformidad específicos. Las tablas Amazon S3 proporcionan un almacenamiento S3 optimizado para las cargas de trabajo de análisis. Con sentencias SQL estándar, puede consultar las tablas con motores de consulta compatibles con Iceberg, como Athena, Amazon Redshift y Apache Spark.
Amazon Redshift es un servicio de almacenamiento de datos a escala de petabytes totalmente gestionado. Amazon Redshift se puede conectar a un almacén de datos en Amazon SageMaker, lo que le permite utilizar sus potentes capacidades analíticas de SQL en los datos unificados de los almacenes de datos de Amazon Redshift y los lagos de datos de Amazon S3. También puede usar Amazon Q en Amazon Redshift, que simplifica la creación de SQL mediante un lenguaje natural.
Tenga en cuenta los criterios para los servicios de análisis AWS
Hay muchas razones para desarrollar el análisis de datos AWS. Es posible que necesite apoyar un proyecto piloto o totalmente nuevo como primer paso en su proceso de migración a la nube. Como alternativa, puede migrar una carga de trabajo existente con la menor interrupción posible. Sea cual sea su objetivo, las siguientes consideraciones pueden resultarle útiles a la hora de elegir.
- Assess data sources and data types
-
Analice las fuentes de datos y los tipos de datos disponibles para obtener una comprensión completa de la diversidad, la frecuencia y la calidad de los datos. Comprenda los posibles desafíos relacionados con el procesamiento y el análisis de los datos. Este análisis es crucial porque:
-
Las fuentes de datos son diversas y provienen de varios sistemas, aplicaciones, dispositivos y plataformas externas.
-
Las fuentes de datos tienen una estructura, un formato y una frecuencia de actualización de datos únicos. El análisis de estas fuentes ayuda a identificar los métodos y tecnologías de recopilación de datos adecuados.
-
El análisis de los tipos de datos, como los datos estructurados, semiestructurados y no estructurados, determina los enfoques de procesamiento y almacenamiento de datos adecuados.
-
El análisis de las fuentes y los tipos de datos facilita la evaluación de la calidad de los datos y le ayuda a anticipar posibles problemas de calidad de los datos: valores faltantes, inconsistencias o imprecisiones.
- Data processing requirements
-
Determine los requisitos de procesamiento de datos para determinar cómo se ingieren, transforman, limpian y preparan los datos para el análisis. Las principales consideraciones incluyen las siguientes:
-
Transformación de datos: determine las transformaciones específicas necesarias para que los datos sin procesar sean aptos para el análisis. Esto implica tareas como la agregación, la normalización, el filtrado y el enriquecimiento de los datos.
-
Limpieza de datos: evalúe la calidad de los datos y defina los procesos para gestionar los datos faltantes, inexactos o incoherentes. Implemente técnicas de limpieza de datos para garantizar datos de alta calidad y obtener información fiable.
-
Frecuencia de procesamiento: determine si se requiere un procesamiento en tiempo real, casi en tiempo real o por lotes en función de las necesidades analíticas. El procesamiento en tiempo real permite obtener información inmediata, mientras que el procesamiento por lotes puede ser suficiente para realizar análisis periódicos.
-
Escalabilidad y rendimiento: evalúe los requisitos de escalabilidad para gestionar los volúmenes de datos, la velocidad de procesamiento y el número de solicitudes de datos simultáneas. Asegúrese de que el enfoque de procesamiento elegido pueda adaptarse al crecimiento futuro.
-
Latencia: tenga en cuenta la latencia aceptable para el procesamiento de datos y el tiempo que transcurre desde la ingesta de los datos hasta los resultados del análisis. Esto es particularmente importante para los análisis en tiempo real o urgentes.
- Storage requirements
-
Determine las necesidades de almacenamiento determinando cómo y dónde se almacenan los datos a lo largo del proceso de análisis. Entre las consideraciones importantes se incluyen las siguientes:
-
Volumen de datos: evalúe la cantidad de datos que se generan y recopilan, y calcule el crecimiento futuro de los datos para planificar una capacidad de almacenamiento suficiente.
-
Retención de datos: defina el período durante el cual se deben conservar los datos para realizar un análisis histórico o con fines de cumplimiento. Determine las políticas de retención de datos adecuadas.
-
Patrones de acceso a los datos: comprenda cómo se accederá a los datos y cómo se consultarán para elegir la solución de almacenamiento más adecuada. Tenga en cuenta las operaciones de lectura y escritura, la frecuencia de acceso a los datos y la localidad de los datos.
-
Seguridad de los datos: priorice la seguridad de los datos evaluando las opciones de cifrado, los controles de acceso y los mecanismos de protección de datos para proteger la información confidencial.
-
Optimización de costos: optimice los costos de almacenamiento seleccionando las soluciones de almacenamiento más rentables en función de los patrones de acceso y el uso de los datos.
-
Integración con los servicios de análisis: garantice una integración perfecta entre la solución de almacenamiento elegida y las herramientas de procesamiento y análisis de datos en proceso.
- Types of data
-
A la hora de decidirse por los servicios de análisis para la recopilación e ingesta de datos, tenga en cuenta los distintos tipos de datos que sean relevantes para las necesidades y los objetivos de su organización. Entre los tipos de datos más comunes que quizás deba tener en cuenta se incluyen los siguientes:
-
Datos transaccionales: incluyen información sobre interacciones o transacciones individuales, como las compras de los clientes, las transacciones financieras, los pedidos en línea y los registros de actividad de los usuarios.
-
Datos basados en archivos: se refiere a datos estructurados o no estructurados que se almacenan en archivos, como archivos de registro, hojas de cálculo, documentos, imágenes, archivos de audio y archivos de vídeo. Los servicios de análisis deberían admitir la ingesta de diferentes formatos de archivo.
-
Datos de eventos: capturan incidentes o incidentes importantes, como las acciones de los usuarios, los eventos del sistema, los eventos de las máquinas o los eventos empresariales. Los eventos pueden incluir cualquier dato que llegue a gran velocidad y que se capture para su procesamiento continuo o posterior.
- Operational considerations
-
La responsabilidad operativa se comparte entre usted y, además AWS, la división de responsabilidades varía según los diferentes niveles de modernización. Tiene la opción de autoadministrar su infraestructura de análisis AWS o de aprovechar los numerosos servicios de análisis sin servidor para reducir la carga de administración de la infraestructura.
Las opciones autogestionadas otorgan a los usuarios un mayor control sobre la infraestructura y las configuraciones, pero requieren un mayor esfuerzo operativo.
Las opciones sin servidor eliminan gran parte de la carga operativa y proporcionan escalabilidad automática, alta disponibilidad y sólidas funciones de seguridad, lo que permite a los usuarios centrarse más en crear soluciones analíticas y obtener información que en gestionar la infraestructura y las tareas operativas. Tenga en cuenta las siguientes ventajas de las soluciones de análisis sin servidor:
-
Abstracción de la infraestructura: los servicios sin servidor resumen la administración de la infraestructura, lo que libera a los usuarios de las tareas de aprovisionamiento, escalado y mantenimiento. AWS gestiona estos aspectos operativos, lo que reduce la sobrecarga de administración.
-
Escalamiento y rendimiento automáticos: los servicios sin servidor escalan automáticamente los recursos en función de las demandas de la carga de trabajo, lo que garantiza un rendimiento óptimo sin intervención manual.
-
Alta disponibilidad y recuperación ante desastres: AWS
proporciona una alta disponibilidad para los servicios sin servidor. AWS administra la redundancia, la replicación y la recuperación ante desastres de los datos para mejorar la disponibilidad y confiabilidad de los datos.
-
Seguridad y cumplimiento: AWS gestiona las medidas de seguridad, el cifrado de datos y el cumplimiento de los servicios sin servidor, siguiendo los estándares y las mejores prácticas del sector.
-
Supervisión y registro: AWS ofrece funciones integradas de supervisión, registro y alerta para los servicios sin servidor. Los usuarios pueden acceder a estadísticas y registros detallados a través de Amazon CloudWatch.
- Type of workload
-
A la hora de crear un canal de análisis moderno, decidir qué tipos de carga de trabajo se van a soportar es crucial para satisfacer las diferentes necesidades analíticas de forma eficaz. Los puntos de decisión clave que se deben tener en cuenta para cada tipo de carga de trabajo incluyen:
Carga de trabajo por lotes
-
Volumen y frecuencia de datos: el procesamiento por lotes es adecuado para grandes volúmenes de datos con actualizaciones periódicas.
-
Latencia de datos: el procesamiento por lotes puede provocar cierto retraso en la entrega de información en comparación con el procesamiento en tiempo real.
Análisis interactivo
-
Complejidad de las consultas de datos: el análisis interactivo requiere respuestas de baja latencia para obtener comentarios rápidos.
-
Visualización de datos: evalúe la necesidad de herramientas de visualización de datos interactivas que permitan a los usuarios empresariales explorar los datos de forma visual.
Transmitir cargas de trabajo
-
Velocidad y volumen de datos: las cargas de trabajo de streaming requieren un procesamiento en tiempo real para gestionar datos a alta velocidad.
-
Ventanillas de datos: defina las ventanas de datos y las agregaciones basadas en el tiempo para la transmisión de datos a fin de extraer información relevante.
- Type of analysis needed
-
Defina con claridad los objetivos empresariales y la información que pretende obtener de los análisis. Los diferentes tipos de análisis sirven para diferentes propósitos. Por ejemplo:
-
El análisis descriptivo es ideal para obtener una visión general histórica
-
El análisis de diagnóstico ayuda a comprender las razones detrás de los eventos pasados
-
El análisis predictivo prevé los resultados futuros
-
El análisis prescriptivo proporciona recomendaciones para acciones óptimas
Haga coincidir sus objetivos empresariales con los tipos de análisis pertinentes. Estos son algunos criterios de decisión clave que le ayudarán a elegir los tipos de análisis correctos:
-
Disponibilidad y calidad de los datos: los análisis descriptivos y de diagnóstico se basan en datos históricos, mientras que los análisis predictivos y prescriptivos requieren suficientes datos históricos y datos de alta calidad para crear modelos precisos.
-
Volumen y complejidad de los datos: los análisis predictivos y prescriptivos requieren importantes recursos computacionales y de procesamiento de datos. Asegúrese de que su infraestructura y sus herramientas puedan gestionar el volumen y la complejidad de los datos.
-
Complejidad de las decisiones: si las decisiones implican múltiples variables, restricciones y objetivos, el análisis prescriptivo puede ser más adecuado para guiar las acciones óptimas.
-
Tolerancia al riesgo: los análisis prescriptivos pueden ofrecer recomendaciones, pero conllevan incertidumbres asociadas. Asegúrese de que los responsables de la toma de decisiones comprendan los riesgos asociados a los resultados analíticos.
- Evaluate scalability and performance
-
Evalúe las necesidades de escalabilidad y rendimiento de la arquitectura. El diseño debe gestionar los crecientes volúmenes de datos, las demandas de los usuarios y las cargas de trabajo analíticas. Los factores de decisión clave que se deben tener en cuenta incluyen:
-
Volumen y crecimiento de datos: evalúe el volumen de datos actual y anticipe el crecimiento futuro.
-
Velocidad de los datos y requisitos de tiempo real: determine si los datos deben procesarse y analizarse en tiempo real o casi en tiempo real.
-
Complejidad del procesamiento de datos: analice la complejidad de sus tareas de procesamiento y análisis de datos. Para las tareas computacionales intensivas, los servicios como Amazon EMR proporcionan un entorno escalable y gestionado para el procesamiento de macrodatos.
-
Simultaneidad y carga de usuarios: tenga en cuenta la cantidad de usuarios simultáneos y el nivel de carga de usuarios en el sistema.
-
Capacidades de autoescalado: considere los servicios que ofrecen capacidades de autoescalado, lo que permite que los recursos se escalen automáticamente hacia arriba o hacia abajo en función de la demanda. Esto garantiza una utilización eficiente de los recursos y una optimización de los costes.
-
Distribución geográfica: considere los servicios con replicación global y acceso a los datos de baja latencia si su arquitectura de datos necesita distribuirse en varias regiones o ubicaciones.
-
Compensación entre costo y rendimiento: equilibre las necesidades de rendimiento con las consideraciones de costo. Los servicios de alto rendimiento pueden tener un costo mayor.
-
Acuerdos de nivel de servicio (SLAs): compruebe lo que SLAs ofrecen los AWS servicios para asegurarse de que cumplen sus expectativas de escalabilidad y rendimiento.
- Data governance
-
La gobernanza de los datos es el conjunto de procesos, políticas y controles que debe implementar para garantizar la administración, la calidad, la seguridad y el cumplimiento efectivos de sus activos de datos. Los puntos de decisión clave que se deben tener en cuenta incluyen:
-
Políticas de retención de datos: defina las políticas de retención de datos en función de los requisitos reglamentarios y las necesidades empresariales, y establezca procesos para la eliminación segura de los datos cuando ya no sean necesarios.
-
Registro y registro de auditoría: decida cuáles son los mecanismos de registro y auditoría para supervisar el acceso y el uso de los datos. Implemente registros de auditoría exhaustivos para realizar un seguimiento de los cambios en los datos, los intentos de acceso y las actividades de los usuarios a fin de supervisar el cumplimiento y la seguridad.
-
Requisitos de conformidad: comprenda las normas de cumplimiento de datos geográficos y específicas del sector que se aplican a su organización. Asegúrese de que la arquitectura de datos se ajuste a estas normas y directrices.
-
Clasificación de datos: clasifique los datos en función de su confidencialidad y defina los controles de seguridad adecuados para cada clase de datos.
-
Recuperación ante desastres y continuidad empresarial: planifique la recuperación ante desastres y la continuidad empresarial para garantizar la disponibilidad y la resiliencia de los datos en caso de eventos inesperados o fallos del sistema.
-
Intercambio de datos con terceros: si comparte datos con entidades de terceros, implemente protocolos y acuerdos seguros de intercambio de datos para proteger la confidencialidad de los datos y evitar el uso indebido de los mismos.
- Security
-
La seguridad de los datos en el proceso de análisis implica proteger los datos en todas las etapas del proceso para garantizar su confidencialidad, integridad y disponibilidad. Los puntos de decisión clave que se deben tener en cuenta incluyen:
-
Control y autorización de acceso: Implemente protocolos sólidos de autenticación y autorización para garantizar que solo los usuarios autorizados puedan acceder a recursos de datos específicos.
-
Cifrado de datos: elija los métodos de cifrado adecuados para los datos almacenados en bases de datos, lagos de datos y durante el movimiento de datos entre diferentes componentes de la arquitectura.
-
Enmascaramiento y anonimización de los datos: considere la necesidad de enmascarar o anonimizar los datos para proteger los datos confidenciales, como la información personal identificable o los datos empresariales confidenciales, y permitir que continúen ciertos procesos analíticos.
-
Integración segura de los datos: establezca prácticas de integración de datos seguras para garantizar que los datos fluyan de forma segura entre los diferentes componentes de la arquitectura, evitando la filtración de datos o el acceso no autorizado durante el movimiento de los datos.
-
Aislamiento de la red: considere los servicios compatibles con los puntos de enlace de Amazon VPC para evitar exponer los recursos a la Internet pública.
- Plan for integration and data flows
-
Defina los puntos de integración y los flujos de datos entre los distintos componentes de la canalización de análisis para garantizar un flujo de datos y una interoperabilidad impecables. Los puntos de decisión clave que se deben tener en cuenta incluyen:
-
Integración de las fuentes de datos: identifique las fuentes de datos desde las que se recopilarán los datos, como bases de datos, aplicaciones, archivos o fuentes externas APIs. Decida los métodos de ingesta de datos (por lotes, en tiempo real, basados en eventos) para incorporar los datos al proceso de manera eficiente y con una latencia mínima.
-
Transformación de datos: determine las transformaciones necesarias para preparar los datos para el análisis. Decida cuáles son las herramientas y los procesos para limpiar, agregar, normalizar o enriquecer los datos a medida que avanzan en el proceso.
-
Arquitectura de movimiento de datos: elija la arquitectura adecuada para el movimiento de datos entre los componentes de la canalización. Considere el procesamiento por lotes, el procesamiento en flujo o una combinación de ambos en función de los requisitos en tiempo real y el volumen de datos.
-
Replicación y sincronización de datos: decida los mecanismos de replicación y sincronización de datos para conservar los datos up-to-date en todos los componentes. Considere soluciones de replicación en tiempo real o sincronizaciones de datos periódicas en función de los requisitos de actualización de los datos.
-
Calidad y validación de los datos: Implemente controles de calidad de los datos y pasos de validación para garantizar la integridad de los datos a medida que se transfieren. Decida las medidas que se deben tomar cuando los datos no pasen la validación, como las alertas o la gestión de errores.
-
Seguridad y cifrado de los datos: determine cómo se protegerán los datos durante el tránsito y en reposo. Decida los métodos de cifrado para proteger los datos confidenciales durante todo el proceso, teniendo en cuenta el nivel de seguridad requerido en función de la confidencialidad de los datos.
-
Escalabilidad y resiliencia: asegúrese de que el diseño del flujo de datos permita la escalabilidad horizontal y pueda gestionar el aumento del tráfico y los volúmenes de datos.
- Architect for cost optimization
-
Desarrollar su cartera de análisis AWS ofrece diversas oportunidades de optimización de costes. Para garantizar la rentabilidad, tenga en cuenta las siguientes estrategias:
-
Dimensionamiento y selección de los recursos: asigne el tamaño adecuado a sus recursos en función de los requisitos reales de la carga de trabajo. Elija AWS servicios y tipos de instancias que se adapten a las necesidades de rendimiento de las cargas de trabajo y, al mismo tiempo, evite el sobreaprovisionamiento.
-
Escalado automático: Implemente el escalado automático para los servicios que experimentan cargas de trabajo variables. El escalado automático ajusta dinámicamente la cantidad de instancias en función de la demanda, lo que reduce los costos durante los períodos de poco tráfico.
-
Instancias puntuales: utilice Amazon EC2 Spot Instances para cargas de trabajo no críticas y tolerantes a errores. Las instancias puntuales pueden reducir considerablemente los costes en comparación con las instancias bajo demanda.
-
Instancias reservadas: considere la posibilidad de adquirir instancias AWS
reservadas para lograr un ahorro de costes significativo en comparación con los precios bajo demanda, ya que permite disponer de cargas de trabajo estables con un uso predecible.
-
Distribución en niveles del almacenamiento de datos: optimice los costos de almacenamiento de datos mediante el uso de diferentes clases de almacenamiento en función de la frecuencia de acceso a los datos.
-
Políticas del ciclo de vida de los datos: establezca políticas del ciclo de vida de los datos para mover o eliminar automáticamente los datos en función de su antigüedad y sus patrones de uso. Esto ayuda a administrar los costos de almacenamiento y mantiene el almacenamiento de datos alineado con su valor.
Elija los servicios AWS de análisis
Ahora que conoce los criterios para evaluar sus necesidades de análisis, está listo para elegir qué servicios de AWS análisis son los adecuados para las necesidades de su organización. La siguiente tabla alinea los conjuntos de servicios con las capacidades y los objetivos empresariales comunes.
| Categorías |
¿Para qué está optimizada? |
Servicios |
Análisis e inteligencia artificial unificados |
Desarrollo de análisis e IA
Optimizado para usar un único entorno de desarrollo, Amazon SageMaker Unified Studio, para acceder a los datos, el análisis y las capacidades de IA.
|
Amazon SageMaker |
|
Procesamiento de datos
|
Analítica interactiva
Optimizado para realizar análisis y exploración de datos en tiempo real, lo que permite a los usuarios consultar y visualizar datos de forma interactiva.
|
Amazon Athena
|
Procesamiento de macrodatos
Optimizado para procesar, mover y transformar grandes cantidades de datos.
|
Amazon EMR
|
|
Catálogo de datos
Optimizado para proporcionar información detallada sobre los datos disponibles, su estructura, características y relaciones. |
AWS Glue |
|
Orquestación del flujo de trabajo
Optimizado para crear, programar y monitorear flujos de trabajo de datos mediante Apache Airflow para coordinar los procesos de análisis y los trabajos de ETL.
|
Amazon MAA
|
Transmisión de datos |
Procesamiento de datos de streaming por Apache Kafka
Optimizado para utilizar las operaciones del plano de datos de Apache Kafka y ejecutar versiones de código abierto de Apache Kafka. |
Amazon MSK |
Procesamiento en tiempo real
Optimizado para una ingesta y agregación de datos rápidas y continuas, incluidos los datos de registro de la infraestructura de TI, los registros de las aplicaciones, las redes sociales, las fuentes de datos de mercado y los datos del flujo de clics en la web.
|
Amazon Kinesis Data Streams |
Entrega de datos en streaming en tiempo real
Optimizado para entregar datos de streaming en tiempo real a destinos como Amazon S3, Amazon Redshift, OpenSearch Service, Splunk, Apache Iceberg Tables y cualquier punto de enlace HTTP personalizado o punto de enlace HTTP propiedad de proveedores de servicios externos compatibles. |
Amazon Data Firehose |
Creación de aplicaciones de Apache Flink
Optimizado para usar Java, Scala, Python o SQL para procesar y analizar datos de streaming. |
Amazon Managed Service para Apache Flink |
Inteligencia empresarial |
Cuadros de mando y visualizaciones
Optimizados para representar visualmente conjuntos de datos complejos y proporcionar consultas de sus datos en lenguaje natural.
|
Quick Suite
|
Análisis de búsquedas |
OpenSearch Clústeres gestionados
Optimizados para el análisis de registros, la supervisión de aplicaciones en tiempo real y el análisis del flujo de clics.
|
OpenSearch Servicio Amazon
|
Gobernanza de datos |
Administrar el acceso a los datos
Optimizado para configurar la administración, la disponibilidad, la usabilidad, la integridad y la seguridad adecuadas de los datos durante todo su ciclo de vida. |
Amazon DataZone |
Colaboración de datos |
Salas limpias de datos seguras
Optimizado para colaborar con otras empresas sin compartir datos subyacentes sin procesar. |
AWS Clean Rooms |
Lago y almacén de datos |
Acceso unificado a lagos de datos y almacenes de datos
Basado en una arquitectura interna para optimizar y unificar el acceso a los datos en los lagos de datos de Amazon S3, los almacenes de datos de Amazon Redshift, las bases de datos operativas y las fuentes de datos federadas y de terceros.
|
Amazon SageMaker |
|
Almacenamiento de objetos para lagos de datos Optimizado para proporcionar una base de lago de datos con una escalabilidad prácticamente ilimitada y una alta durabilidad. |
Amazon S3 |
Almacenamiento de datos
Optimizado para almacenar, organizar y recuperar de forma centralizada grandes volúmenes de datos estructurados y, a veces, semiestructurados de diversas fuentes dentro de una organización. |
Amazon Redshift
|
Utilice los servicios de análisis AWS
Ahora debe tener una idea clara de sus objetivos empresariales y del volumen y la velocidad de los datos que va a ingerir y analizar para empezar a crear sus flujos de datos.
Para explorar cómo usar cada uno de los servicios disponibles y obtener más información sobre ellos, hemos proporcionado una guía para explorar cómo funciona cada uno de los servicios. En las siguientes secciones se proporcionan enlaces a documentación detallada, tutoriales prácticos y recursos para que pueda empezar desde el uso básico hasta una inmersión profunda más avanzada.
- Amazon Athena
-
-
Cómo empezar a usar Amazon Athena
Aprenda a usar Amazon Athena para consultar datos y crear una tabla basada en datos de muestra almacenados en Amazon S3, consultar la tabla y comprobar los resultados de la consulta.
Comience con el tutorial
-
Comience a usar Apache Spark en Athena
Utilice la experiencia de cuaderno simplificada de la consola Athena para desarrollar aplicaciones de Apache Spark con Python o Athena Notebook. APIs
Comience con el tutorial
-
Cataloga y gobierna las consultas federadas de Athena con la arquitectura Amazon Lakehouse SageMaker
Aprenda a conectarse a los datos almacenados en Amazon Redshift, DynamoDB y Snowflake, así como a gobernarlos y ejecutarlos a través del almacén de datos de Amazon. SageMaker
Lea el blog
-
Análisis de datos en Amazon S3 con Athena
Descubra cómo usar Athena en los registros de Elastic Load Balancers, generados como archivos de texto en un formato predefinido. Le mostramos cómo crear una tabla, particionar los datos en un formato utilizado por Athena, convertirlos a Parquet y comparar el rendimiento de las consultas.
Lea la entrada del blog
- AWS Clean Rooms
-
-
Configuración AWS Clean Rooms
Obtén información sobre cómo configurarla AWS Clean Rooms en tu AWS cuenta.
Lee la guía
-
Obtenga información valiosa sobre los datos de conjuntos de datos de varias partes utilizando AWS
Entity Resolution AWS Clean Rooms sin compartir los datos subyacentes
Aprenda a utilizar la preparación y la coincidencia para ayudar a mejorar la coincidencia de datos con los colaboradores.
Lee la entrada del blog
-
Cómo la privacidad diferencial ayuda a obtener información sin revelar datos a nivel individual
Descubra cómo AWS Clean Rooms Differential Privacy simplifica la aplicación de la privacidad diferencial y ayuda a proteger la privacidad de sus usuarios.
Lea el blog
- Amazon Data Firehose
-
-
Tutorial: Crear una transmisión de Firehose desde la consola
Aprende a usar el Consola de administración de AWS o un AWS SDK para crear una transmisión de Firehose con destino al destino que elijas.
Lee la guía
-
Enviar datos a una transmisión de Firehose
Aprenda a usar diferentes fuentes de datos para enviar datos a su transmisión de Firehose.
Lee la guía
-
Transforma los datos de origen en Firehose
Aprenda a invocar la función Lambda para transformar los datos de origen entrantes y entregar los datos transformados a los destinos.
Lea la guía
- Amazon DataZone
-
-
Cómo empezar con Amazon DataZone
Aprenda a crear el dominio DataZone raíz de Amazon, a obtener la URL del portal de datos y a recorrer los DataZone flujos de trabajo básicos de Amazon para productores y consumidores de datos.
Comience con el tutorial
-
Anunciamos la disponibilidad general del linaje de datos en la próxima generación de Amazon SageMaker y Amazon DataZone
Descubra cómo Amazon DataZone utiliza la captura de linaje automatizada para centrarse en recopilar y mapear automáticamente la información de linaje procedente de Amazon AWS Glue Redshift.
Lea el blog
- Amazon EMR
-
-
Cómo empezar a utilizar Amazon EMR
Aprenda a lanzar un clúster de muestra con Spark y a ejecutar un PySpark script sencillo almacenado en un bucket de Amazon S3.
Comience con el tutorial
-
Cómo empezar a utilizar Amazon EMR en Amazon EKS
Le mostramos cómo empezar a utilizar Amazon EMR en Amazon EKS mediante la implementación de una aplicación Spark en un clúster virtual.
Explore la guía
-
Comience con EMR Serverless
Descubra cómo Amazon EMR Serverless proporciona un entorno de ejecución sin servidor que simplifica el funcionamiento de las aplicaciones de análisis que utilizan los marcos de código abierto más recientes.
Comience con el tutorial
- AWS Glue
-
-
Empezando con AWS Glue DataBrew
Aprenda a crear su primer DataBrew proyecto. Carga un conjunto de datos de muestra, ejecuta transformaciones en ese conjunto de datos, crea una receta para capturar esas transformaciones y ejecuta un trabajo para escribir los datos transformados en Amazon S3.
Comience con el tutorial
-
Transforma los datos con AWS Glue DataBrew
Conozca AWS Glue DataBrew una herramienta visual de preparación de datos que permite a los analistas y científicos de datos limpiar y normalizar los datos con facilidad para prepararlos para el análisis y el aprendizaje automático. Aprenda a crear un proceso de ETL utilizando AWS Glue DataBrew.
Comience con el laboratorio
-
AWS Glue DataBrew día de inmersión
Descubra cómo limpiar y AWS Glue DataBrew normalizar los datos para el análisis y el aprendizaje automático.
Comience con el taller
-
Empezar con el AWS Glue Data Catalog
Aprenda a crear el primero AWS Glue Data Catalog, que utiliza un bucket de Amazon S3 como fuente de datos.
Comience con el tutorial
-
Catálogo de datos y rastreadores en AWS Glue
Descubra cómo puede utilizar la información del catálogo de datos para crear y supervisar sus trabajos de ETL.
Explore la guía
- Amazon Kinesis Data Streams
-
-
Tutoriales de introducción a Amazon Kinesis Data Streams
Aprenda a procesar y analizar datos bursátiles en tiempo real.
Comience con los tutoriales
-
Patrones arquitectónicos para el análisis en tiempo real mediante Amazon Kinesis Data Streams, parte 1
Conozca los patrones arquitectónicos comunes de dos casos de uso: el análisis de datos de series temporales y los microservicios basados en eventos.
Lea el blog
-
Patrones arquitectónicos para el análisis en tiempo real mediante Amazon Kinesis Data Streams, parte 2
Obtenga información sobre las aplicaciones de IA con Kinesis Data Streams en tres escenarios: inteligencia empresarial generativa en tiempo real, sistemas de recomendación en tiempo real y transmisión e inferencia de datos de Internet de las cosas.
Lea el blog
- Amazon Managed Service for Apache Flink
-
-
¿Qué es Amazon Managed Service para Apache Flink?
Comprenda los conceptos fundamentales de Amazon Managed Service para Apache Flink.
Explore la guía
-
Taller de Amazon Managed Service para Apache Flink
En este taller, aprenderá a implementar, operar y escalar una aplicación de Flink con Amazon Managed Service para Apache Flink.
Asista al taller virtual
- Amazon MSK
-
-
Cómo empezar a usar Amazon MSK
Aprenda a crear un clúster de Amazon MSK, a producir y consumir datos y a supervisar el estado de su clúster mediante métricas.
Comience con la guía
-
Taller de Amazon MSK
Profundice con este taller práctico de Amazon MSK.
Comience con el taller
- Amazon MWAA
-
-
Cómo empezar a usar Amazon MWAA
Descubra cómo crear su primer entorno MWAA, cargar un DAG en Amazon S3 y ejecutar su primer flujo de trabajo.
Comience con el tutorial
-
Creación de canalizaciones de datos con Amazon MWAA
Aprenda a crear canalizaciones de end-to-end datos que organicen otros servicios de AWS
análisis como Glue, EMR y Redshift. Esta entrada de blog analiza un enfoque simplificado y basado en la configuración para organizar los trabajos principales de dbt mediante MWAA y Cosmos, con trabajos que ejecutan transformaciones en Amazon Redshift.
Lea la publicación del blog
-
Taller de Amazon MWAA
Explore los ejercicios prácticos para aprender a implementar, configurar y usar Amazon MWAA para la organización del flujo de trabajo de datos.
Comience con el taller
-
Prácticas recomendadas para Amazon MWAA
Conozca los patrones arquitectónicos y las prácticas recomendadas para usar Amazon MWAA en sus flujos de trabajo de análisis.
Lea la guía
- OpenSearch Service
-
-
Cómo empezar con el OpenSearch servicio
Obtén información sobre cómo usar Amazon OpenSearch Service para crear y configurar un dominio de prueba.
Comience con el tutorial
-
Visualización de las llamadas de atención al cliente con el OpenSearch servicio y los paneles OpenSearch
Descubra un recorrido completo de la siguiente situación: una empresa recibe cierto número de llamadas de atención al cliente y quiere analizarlas. ¿Cuál es el tema de cada llamada? ¿Cuántas fueron positivas? ¿Cuántas negativas? ¿Cómo los gerentes pueden buscar o revisar las transcripciones de estas llamadas?
Comience con el tutorial
-
Taller de introducción a Amazon OpenSearch Serverless
Aprenda a configurar un nuevo dominio de Amazon OpenSearch Serverless en la AWS
consola. Explore los diferentes tipos de consultas de búsqueda disponibles, diseñe visualizaciones llamativas y descubra cómo proteger su dominio y sus documentos en función de los privilegios de usuario asignados.
Comience con el taller
-
Base de datos vectorial optimizada en costes: introducción a las técnicas OpenSearch de cuantificación de Amazon Service
Descubra cómo OpenSearch Service admite las técnicas de cuantificación escalar y de productos para optimizar el uso de la memoria y reducir los costos operativos.
Lea la entrada del blog
- Quick Suite
-
-
Cómo empezar con el análisis de datos de Quick Suite
Aprenda a crear su primer análisis. Utilice datos de muestra para crear un análisis simple o uno más avanzado. O bien, puede conectarse a sus propios datos para crear un análisis.
Explore la guía
-
Visualización con Quick Suite
Descubra el aspecto técnico de la inteligencia empresarial (BI) y la visualización de datos con AWS. Aprenda a integrar paneles de control en aplicaciones y sitios web, y a gestionar de forma segura el acceso y los permisos.
Comience con el curso
-
Talleres de Quick Suite
Comience con ventaja su viaje a Quick Suite con talleres
Comience con los talleres
- Amazon Redshift
-
-
Introducción a Amazon Redshift Serverless
Conozca el flujo básico de Amazon Redshift Serverless para crear recursos sin servidor, conectarse a Amazon Redshift Serverless, cargar datos de muestra y, a continuación, ejecutar consultas sobre los datos.
Explore la guía
-
Taller de análisis profundo de Amazon Redshift
Explore una serie de ejercicios que ayudan a los usuarios a empezar a utilizar la plataforma Amazon Redshift.
Comience con el taller
- Amazon S3
-
-
Cómo empezar a utilizar Amazon S3
Aprenda a crear su primer DataBrew proyecto. Carga un conjunto de datos de muestra, ejecuta transformaciones en ese conjunto de datos, crea una receta para capturar esas transformaciones y ejecuta un trabajo para escribir los datos transformados en Amazon S3.
Comience con la guía
- Amazon SageMaker
-
-
Empezando con SageMaker
Aprenda a crear un proyecto, añadir miembros y utilizar el JupyterLab cuaderno de muestra para empezar a crear.
Lea la guía
-
Presentamos la próxima generación de Amazon SageMaker: el centro de todos sus datos, análisis e inteligencia artificial
Descubra cómo empezar con el procesamiento de datos, el desarrollo de modelos y el desarrollo generativo de aplicaciones de IA.
Lea el blog
-
¿Qué es SageMaker Unified Studio?
Obtén información sobre las capacidades de SageMaker Unified Studio y cómo acceder a ellas cuando utilizas Amazon SageMaker.
Lea la guía
-
Primeros pasos con la arquitectura de casas lacustres de Amazon SageMaker
Aprende a crear un proyecto y a buscar, cargar y consultar datos para tus casos de uso empresarial en Amazon SageMaker.
Lee la guía
-
Conexiones de datos en la arquitectura Lakehouse de Amazon SageMaker
Descubra cómo la arquitectura Lakehouse proporciona un enfoque unificado para gestionar las conexiones de datos entre AWS servicios y aplicaciones empresariales.
Lea la guía
-
Cataloga y gobierna las consultas federadas de Athena con la arquitectura Lakehouse SageMaker
Aprenda a conectarse a los datos almacenados en Amazon Redshift, DynamoDB y Snowflake, así como a gestionarlos y ejecutarlos para sus proyectos de Amazon. SageMaker
Lea el blog
Explore las formas de utilizar los servicios AWS de análisis
- Editable architecture diagrams
-
Diagramas de arquitectura de referencia
Explore los diagramas de arquitectura que le ayudarán a desarrollar, escalar y probar sus soluciones de análisis AWS.
Explore las arquitecturas de referencia de análisis
- Ready-to-use code
-
|
Solución destacada
Análisis escalable con Apache Druid en AWS
Implemente un código AWS creado para ayudarle a configurar, operar y administrar Apache Druid en un entorno de alojamiento rentable AWS, de alta disponibilidad, resiliente y tolerante a errores.
Explore esta solución
|
AWS Soluciones
Explore las soluciones preconfiguradas y desplegables y sus guías de implementación, creadas por. AWS
Explore todas las AWS soluciones de seguridad, identidad y gobierno
|
- Documentation
-
|
Documentos técnicos de análisis
Consulte los documentos técnicos para obtener más información y mejores prácticas sobre la elección, la implementación y el uso de los servicios de análisis que mejor se adapten a su organización.
Explore los documentos técnicos de análisis
|
AWS Blog sobre macrodatos
Explore las publicaciones de blog que abordan casos de uso específicos de macrodatos.
Explore el blog sobre AWS macrodatos
|