Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Creación de un trabajo híbrido
En esta sección se muestra cómo crear un trabajo híbrido usando un script de Python. Como alternativa, para crear un trabajo híbrido a partir de código Python local, como su entorno de desarrollo integrado (IDE) preferido o un cuaderno de Braket, consulte Ejecución del código local como un trabajo híbrido.
En esta sección:
Creación y ejecución
Una vez que tenga un rol con permisos para ejecutar un trabajo híbrido, estará listo para proceder. La pieza clave de su primer trabajo híbrido de Braket es el script de algoritmo. Define el algoritmo que desea ejecutar y contiene las tareas lógicas clásicas y cuánticas que forman parte de su algoritmo. Además del script de algoritmo, puede proporcionar otros archivos de dependencia. El script de algoritmo, junto con sus dependencias, se denomina módulo fuente. El punto de entrada define el primer archivo o función que se ejecutará en el módulo fuente cuando se inicie el trabajo híbrido.
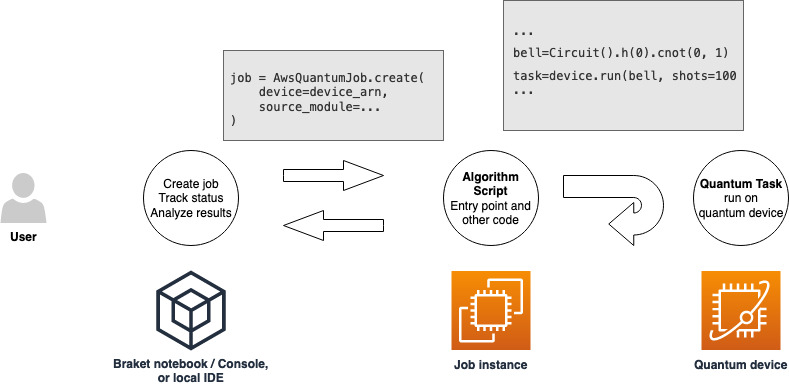
En primer lugar, consideremos el siguiente ejemplo básico de un script de algoritmo que crea cinco estados Bell e imprime los resultados de medición correspondientes.
import os from braket.aws import AwsDevice from braket.circuits import Circuit def start_here(): print("Test job started!") # Use the device declared in the job script device = AwsDevice(os.environ["AMZN_BRAKET_DEVICE_ARN"]) bell = Circuit().h(0).cnot(0, 1) for count in range(5): task = device.run(bell, shots=100) print(task.result().measurement_counts) print("Test job completed!")
Guarde este archivo con el nombre algorithm_script.py en el directorio de trabajo actual de su cuaderno de Braket o en su entorno local. El fichero algorithm_script.py tiene start_here() como punto de entrada previsto.
A continuación, cree un archivo de Python o un cuaderno de Python en el mismo directorio que el archivo algorithm_script.py. Este script inicia el trabajo híbrido y gestiona cualquier procesamiento asíncrono, como imprimir el estado o los resultados clave que nos interesen. Como mínimo, este script debe especificar su script de trabajo híbrido y su dispositivo principal.
nota
Para obtener más información sobre cómo crear un cuaderno de Braket o cargar un archivo, como el archivo algorithm_script.py, en el mismo directorio que los cuadernos, consulte Ejecución de su primer circuito utilizando el SDK de Python de Amazon Braket.
Para este primer caso básico, se utiliza un simulador de destino. Independientemente del tipo de dispositivo cuántico de destino, ya sea un simulador o una unidad de procesamiento cuántico (QPU) real, el dispositivo que especifique con device en el siguiente script se utilizará para programar el trabajo híbrido y estará disponible para los scripts del algoritmo como variable de entorno AMZN_BRAKET_DEVICE_ARN.
nota
Solo puede usar los dispositivos que estén disponibles en Región de AWS su trabajo híbrido. El SDK de Amazon Braket selecciona automáticamente esta Región de AWS. Por ejemplo, un trabajo híbrido en us-east-1 puede utilizar dispositivos IonQ, SV1, DM1 y TN1, pero no dispositivos Rigetti.
Si elige una computadora cuántica en lugar de un simulador, Braket programa sus trabajos híbridos para ejecutar todas sus tareas cuánticas con acceso prioritario.
from braket.aws import AwsQuantumJob from braket.devices import Devices job = AwsQuantumJob.create( Devices.Amazon.SV1, source_module="algorithm_script.py", entry_point="algorithm_script:start_here", wait_until_complete=True )
El parámetro wait_until_complete=True establece un modo detallado para que su trabajo imprima la salida del trabajo real mientras se está ejecutando. Debería ver un resultado similar al del siguiente ejemplo.
Initializing Braket Job: arn:aws:braket:us-west-2:111122223333:job/braket-job-default-123456789012 Job queue position: 1 Job queue position: 1 Job queue position: 1 .............. . . . Beginning Setup Checking for Additional Requirements Additional Requirements Check Finished Running Code As Process Test job started! Counter({'00': 58, '11': 42}) Counter({'00': 55, '11': 45}) Counter({'11': 51, '00': 49}) Counter({'00': 56, '11': 44}) Counter({'11': 56, '00': 44}) Test job completed! Code Run Finished 2025-09-24 23:13:40,962 sagemaker-training-toolkit INFO Reporting training SUCCESS
nota
También puedes usar tu módulo personalizado con el AwsQuantumJob.create
Supervisión de los resultados
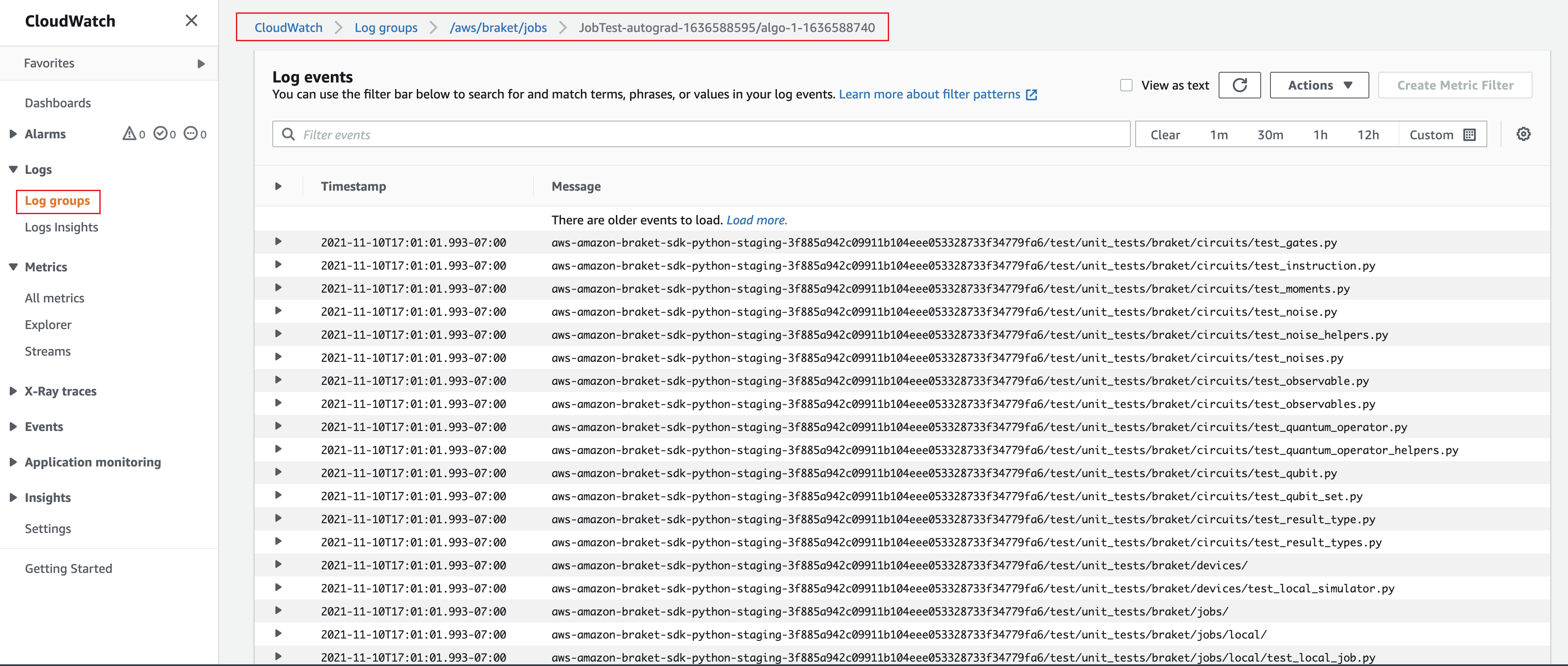
Como alternativa, puedes acceder a la salida del registro desde Amazon CloudWatch. Para ello, vaya a la pestaña Grupos de registro en el menú izquierdo de la página de detalles del trabajo, seleccione el grupo de registro aws/braket/jobs y, a continuación, elija el flujo de registro que contiene el nombre del trabajo. En el ejemplo anterior, es braket-job-default-1631915042705/algo-1-1631915190.
También puede ver el estado del trabajo híbrido en la consola seleccionando la página Trabajos híbridos y, a continuación, Configuración.
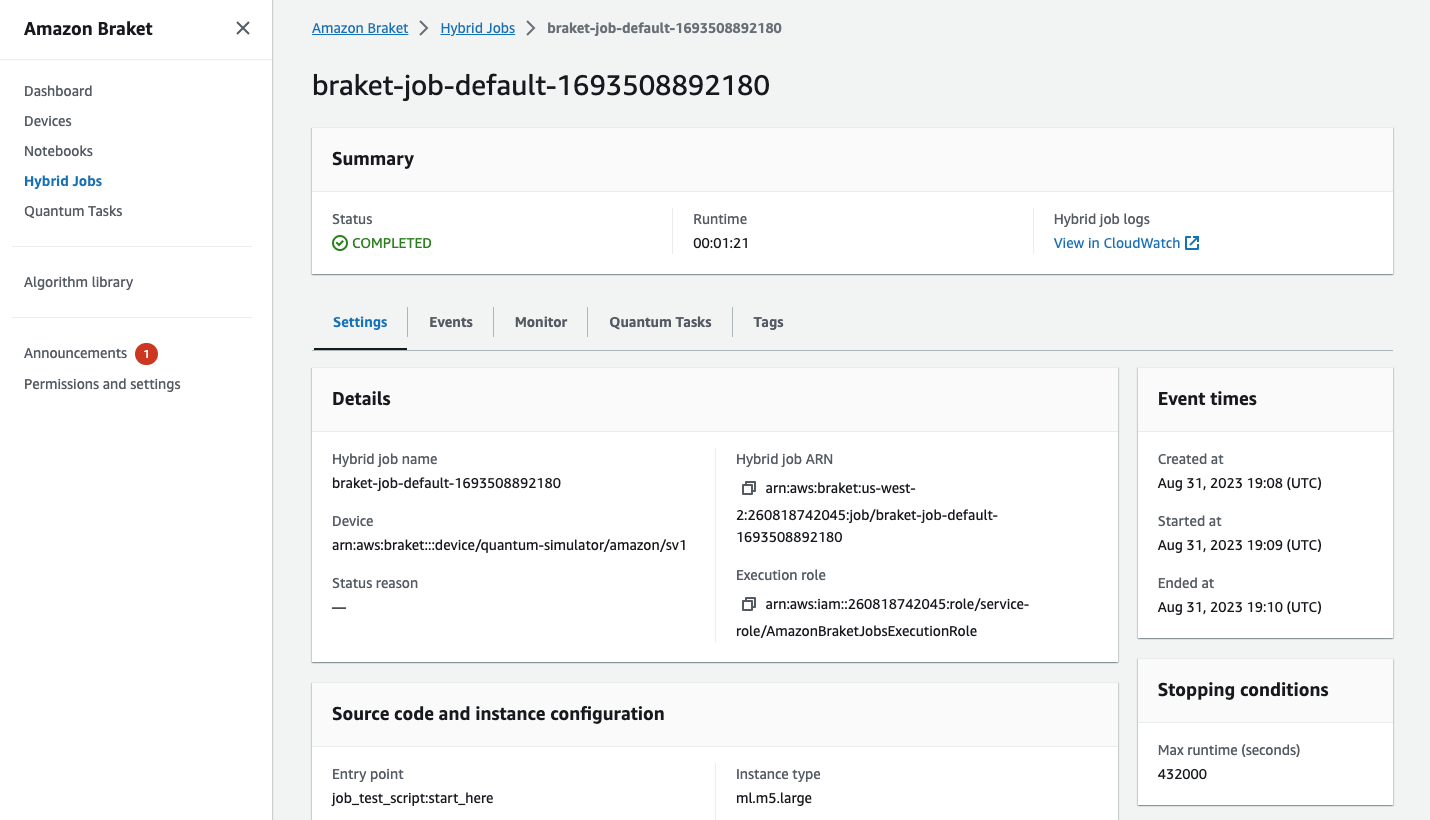
Su trabajo híbrido produce algunos artefactos en Amazon S3 mientras se ejecuta. El nombre predeterminado del bucket de S3 es amazon-braket-<region>-<accountid> y el contenido está en el jobs/<jobname>/<timestamp> directorio. Puede configurar las ubicaciones de S3 en las que se almacenan estos artefactos especificando una code_location diferente al crear el trabajo híbrido con el SDK de Python de Braket.
nota
Este depósito de S3 debe estar ubicado en el mismo lugar que su script de Región de AWS trabajo.
El directorio jobs/<jobname>/<timestamp> contiene una subcarpeta con la salida del script del punto de entrada en un archivo model.tar.gz. También hay un directorio denominado script que contiene los artefactos del script de algoritmo en un archivo source.tar.gz. Los resultados de sus tareas cuánticas reales se encuentran en el directorio denominado jobs/<jobname>/tasks.
Guardar los resultados
Puede guardar los resultados generados por el script de algoritmo para que estén disponibles en el objeto de trabajo híbrido del script de trabajo híbrido, así como en la carpeta de salida de Amazon S3 (en un archivo comprimido con tar denominado model.tar.gz).
El resultado debe guardarse en un archivo con un formato de notación de JavaScript objetos (JSON). Si los datos no se pueden serializar fácilmente en texto, como en el caso de una matriz numpy, puede pasar una opción para serializar utilizando un formato de datos pickled. Consulte el módulo braket.jobs.data_persistence
Para guardar los resultados de los trabajos híbridos, añada las siguientes líneas comentadas con #ADD al archivo algorithm_script.py.
import os from braket.aws import AwsDevice from braket.circuits import Circuit from braket.jobs import save_job_result # ADD def start_here(): print("Test job started!") device = AwsDevice(os.environ['AMZN_BRAKET_DEVICE_ARN']) results = [] # ADD bell = Circuit().h(0).cnot(0, 1) for count in range(5): task = device.run(bell, shots=100) print(task.result().measurement_counts) results.append(task.result().measurement_counts) # ADD save_job_result({"measurement_counts": results}) # ADD print("Test job completed!")
A continuación, puede mostrar los resultados del trabajo desde su script de trabajo añadiendo la línea print(job.result()) comentada con #ADD.
import time from braket.aws import AwsQuantumJob job = AwsQuantumJob.create( source_module="algorithm_script.py", entry_point="algorithm_script:start_here", device="arn:aws:braket:::device/quantum-simulator/amazon/sv1", ) print(job.arn) while job.state() not in AwsQuantumJob.TERMINAL_STATES: print(job.state()) time.sleep(10) print(job.state()) print(job.result()) # ADD
En este ejemplo, hemos eliminado wait_until_complete=True para suprimir la salida detallada. Puedes volver a añadirlo para su depuración. Cuando ejecuta este trabajo híbrido, se muestra el identificador y el job-arn, seguido del estado del trabajo híbrido cada 10 segundos hasta que el trabajo híbrido esté COMPLETED, después de lo cual le muestra los resultados del circuito Bell. Consulte el siguiente ejemplo.
arn:aws:braket:us-west-2:111122223333:job/braket-job-default-123456789012 INITIALIZED RUNNING RUNNING RUNNING RUNNING RUNNING RUNNING RUNNING RUNNING RUNNING RUNNING ... RUNNING RUNNING COMPLETED {'measurement_counts': [{'11': 53, '00': 47},..., {'00': 51, '11': 49}]}
Uso de puntos de comprobación
Puede guardar las iteraciones intermedias de sus trabajos híbridos mediante puntos de control. En el ejemplo de script de algoritmo de la sección anterior, añadiría las siguientes líneas comentadas con #ADD para crear archivos de punto de control.
from braket.aws import AwsDevice from braket.circuits import Circuit from braket.jobs import save_job_checkpoint # ADD import os def start_here(): print("Test job starts!") device = AwsDevice(os.environ["AMZN_BRAKET_DEVICE_ARN"]) # ADD the following code job_name = os.environ["AMZN_BRAKET_JOB_NAME"] save_job_checkpoint(checkpoint_data={"data": f"data for checkpoint from {job_name}"}, checkpoint_file_suffix="checkpoint-1") # End of ADD bell = Circuit().h(0).cnot(0, 1) for count in range(5): task = device.run(bell, shots=100) print(task.result().measurement_counts) print("Test hybrid job completed!")
Cuando ejecuta el trabajo híbrido, se crea el archivo <jobname>-checkpoint-1.json en sus artefactos de trabajo híbrido en el directorio de puntos de control con una ruta de /opt/jobs/checkpoints predeterminada. El script del trabajo híbrido permanece inalterado a menos que desee cambiar esta ruta predeterminada.
Si desea cargar un trabajo híbrido desde un punto de control generado por un trabajo híbrido anterior, el script de algoritmo utiliza from braket.jobs import load_job_checkpoint. La lógica que se debe cargar en el script de algoritmo es la siguiente.
from braket.jobs import load_job_checkpoint checkpoint_1 = load_job_checkpoint( "previous_job_name", checkpoint_file_suffix="checkpoint-1", )
Después de cargar este punto de control, puede continuar con su lógica basándose en el contenido cargado en el checkpoint-1.
nota
El checkpoint_file_suffix debe coincidir con el sufijo especificado previamente al crear el punto de control.
Su script de orquestación debe especificar el job-arn del trabajo híbrido anterior con la línea comentada con #ADD.
from braket.aws import AwsQuantumJob job = AwsQuantumJob.create( source_module="source_dir", entry_point="source_dir.algorithm_script:start_here", device="arn:aws:braket:::device/quantum-simulator/amazon/sv1", copy_checkpoints_from_job="<previous-job-ARN>", #ADD )
