Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Componentes de AWS Batch
AWS Batch simplifica la ejecución de trabajos por lotes en varias zonas de disponibilidad de una región. Puede crear entornos de computación de AWS Batch dentro de una VPC nueva o existente. Después de que un entorno de computación se ha activado y asociado a una cola de trabajos, puede precisar las definiciones de trabajo que especifican cuáles imágenes de contenedor de Docker ejecutarán sus trabajos. Las imágenes de contenedor se almacenan y se extraen desde registros de contenedor, que podrían existir dentro o fuera de la infraestructura de AWS .
Entorno de computación
Un entorno de computación es un conjunto de recursos de computación administrados o no administrados que se utilizan para ejecutar trabajos. Con los entornos de procesamiento gestionados, usted puede especificar el tipo de procesamiento deseado (Fargate o EC2) con varios niveles de detalle. Puede configurar entornos de computación que utilicen un tipo de instancia EC2 determinado, como c5.2xlarge o m5.10xlarge. O bien, usted puede elegir especificar únicamente que desea utilizar los tipos de instancias más recientes. También puede especificar la cantidad mínima, deseada y máxima de vCPU para el entorno, junto con el importe que está dispuesto a pagar por una instancia puntual como porcentaje del precio de On-Demand la instancia y del conjunto objetivo de subredes de VPC. AWS Batch lanza, administra y termina de manera eficiente los tipos de cómputo según sea necesario. También puede administrar sus propios entornos de computación. Por lo tanto, usted es responsable de configurar y escalar las instancias en un clúster de Amazon ECS que AWS Batch cree para usted. Para obtener más información, consulte Entornos informáticos para AWS Batch.
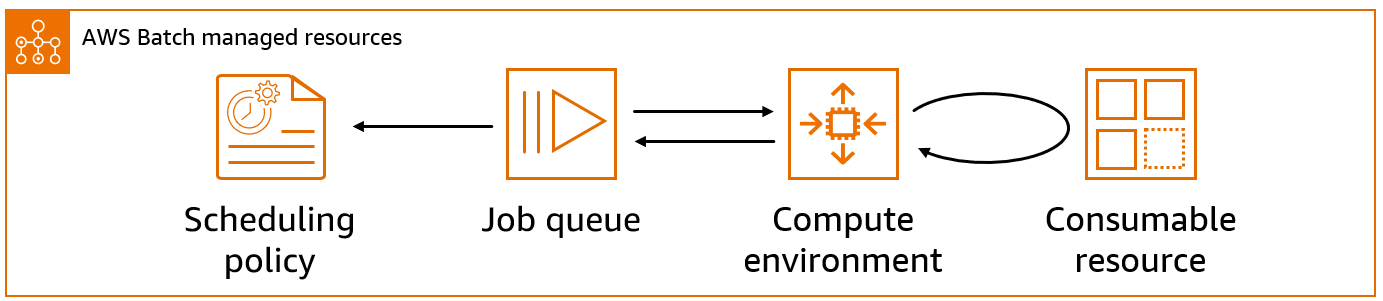
Colas de trabajos
Cuando envías un AWS Batch trabajo, lo envías a una cola de trabajos determinada, donde reside el trabajo hasta que se programa en un entorno informático. Asocie uno o más entornos de computación con una cola de trabajos. También puede asignar valores de prioridad a estos entornos de computación e incluso a las propias colas de trabajos. Por ejemplo, puede tener una cola de prioridad alta a la que envía trabajos prioritarios, y una cola de prioridad baja para los trabajos que pueden ejecutarse en cualquier momento, cuando los recursos de computación son más económicos. Para obtener más información, consulte Colas de trabajos.
Definiciones de trabajo
Una definición de trabajo especifica cómo se ejecutan los trabajos. Puede considerar una definición de trabajo como un esquema de los recursos en su trabajo. Puede asignar a su trabajo una función de IAM para proporcionar acceso a otros AWS recursos. También puede especificar los requisitos de memoria y CPU. La definición de trabajo también puede controlar las propiedades de contenedor, las variables de entorno y los puntos de montaje para un almacenamiento persistente. Muchas de las especificaciones de una definición de trabajo pueden anularse mediante la especificación de nuevos valores al enviar trabajos individuales. Para obtener más información, consulte Definiciones de trabajo
Tareas
Una unidad de trabajo (como un script de shell, un ejecutable en Linux o una imagen de contenedor Docker) que envía a AWS Batch. Tiene un nombre y se ejecuta como una aplicación contenerizada en AWS Fargate los recursos de Amazon EC2 de su entorno informático, utilizando los parámetros que especifique en una definición de trabajo. Los trabajos pueden hacer referencia a otros trabajos por nombre o ID, y puede que de ellos dependa la correcta realización de otros trabajos o de la disponibilidad de los recursos que usted especifique. Para obtener más información, consulte Tareas.
Política de programación
Puede utilizar las políticas de programación para configurar cómo se asignan los recursos de computación de una cola de trabajos entre los usuarios o las cargas de trabajo. Con las políticas de programación equitativas, puede asignar diferentes identificadores de participación a las cargas de trabajo o a los usuarios. El programador de AWS Batch tareas utiliza de forma predeterminada una estrategia de «primero en entrar, primero en salir» (FIFO). Para obtener más información, consulte Políticas de programación de reparto justo.
Recursos consumibles
Un recurso consumible es un recurso que se necesita para ejecutar los trabajos, como un token de licencia de terceros, el ancho de banda de acceso a la base de datos, la necesidad de limitar las llamadas a una API de terceros, etc. Estos recursos consumibles se deben especificar para ejecutar un trabajo, por lo tanto, Batch contempla dichas dependencias de recursos cuando realiza la programación de uno. La reducción de la infrautilización de los recursos de computación se lleva a cabo con la asignación de los trabajos que contienen todos los recursos necesarios. Para obtener más información, consulte Programación basada en los recursos.
Entornos de servicio
Un entorno de servicios define cómo se AWS Batch integra con la ejecución de los trabajos. SageMaker Los entornos de servicio permiten AWS Batch enviar y gestionar los trabajos y, SageMaker al mismo tiempo, proporcionan las capacidades de gestión de colas, programación y prioridades de AWS Batch. Los entornos de servicio definen los límites de capacidad para tipos de servicios específicos, como los trabajos SageMaker de formación. Los límites de capacidad controlan la cantidad máxima de recursos que pueden utilizar los trabajos de servicio en el entorno. Para obtener más información, consulte Entornos de servicio para AWS Batch.
Trabajo de servicio
Un trabajo de servicio es una unidad de trabajo a la que se envía AWS Batch para ejecutarse en un entorno de servicio. Los trabajos de servicio aprovechan las capacidades AWS Batch de preparación de colas y programación y, al mismo tiempo, delegan la ejecución real al servicio externo. Por ejemplo, los trabajos de SageMaker formación enviados como trabajos de servicio se ponen en cola y se les asigna prioridad AWS Batch, pero la ejecución de los trabajos de SageMaker formación se lleva a cabo dentro de la infraestructura de IA. SageMaker Esta integración permite a los científicos de datos y a los ingenieros de aprendizaje automático beneficiarse de AWS Batch la gestión automatizada de las cargas de trabajo y de las colas prioritarias para sus cargas de trabajo de formación en SageMaker IA. Los trabajos de servicio pueden hacer referencia a otros trabajos por su nombre o ID y admitir las dependencias de trabajos. Para obtener más información, consulte Trabajos de servicio en AWS Batch.
