Uso de índices secundarios globales para consultas de agregación materializadas en DynamoDB
Mantener métricas clave y agregaciones casi en tiempo real sobre datos que cambian rápidamente es algo que las compañías cada vez valoran más, ya que les permite tomar decisiones rápidas. Por ejemplo, es posible que una biblioteca de música quiera mostrar sus canciones más descargadas casi en tiempo real o que una plataforma de comercio electrónico necesite mostrar los productos más populares por categoría.
Como DynamoDB no admite de forma nativa operaciones de agregación como SUM o COUNT entre elementos, el cálculo de estos valores en tiempo de lectura requeriría analizar un gran número de elementos, lo que puede resultar lento y caro. En su lugar, puede calcular previamente las agregaciones a medida que cambian los datos y almacenar los resultados como elementos normales de la tabla. Este patrón se llama agregación materializada.
Temas
Ejemplo de escenario y patrones de acceso
Considere una aplicación de biblioteca de música con los siguientes requisitos:
La aplicación graba descargas individuales de canciones a un volumen alto (miles por segundo).
Los usuarios deben ver las canciones más descargadas durante un mes con una latencia de un dígito de milisegundo.
La aplicación también debe admitir consultas como “las 10 mejores canciones de este mes” y “todas las canciones descargadas en un mes determinado”.
Calcular los recuentos de descargas en tiempo de lectura analizando todos los registros de descargas puede resultar caro a esta escala. En su lugar, puede mantener un recuento continuo que se actualice a medida que se produzca cada descarga y almacenarlo de forma que permita realizar consultas de forma eficaz.
Por qué calcular previamente las agregaciones
Existen varios enfoques para calcular las agregaciones. En la siguiente tabla, se comparan las alternativas más comunes y se explica por qué la agregación materializada en DynamoDB suele ser la más adecuada para este tipo de casos de uso.
| Método | Desventajas | Cuándo se debe usar |
|---|---|---|
| Análisis y recuento en tiempo de lectura | Requiere leer todos los registros de descarga de cada consulta. La latencia aumenta con el volumen de datos y consume una capacidad de lectura significativa. | Solo es adecuado para conjuntos de datos muy pequeños donde la latencia no es un problema. |
| Almacén de agregación externo (por ejemplo, Amazon ElastiCache) | Agrega complejidad operativa con la administración de un servicio independiente. Requiere una lógica de sincronización entre DynamoDB y la memoria caché. | Cuando necesite lecturas de menos de milisegundos o una lógica de agregación compleja que vaya más allá de los simples recuentos. |
| Agregación por aplicación en escritura | Acople la lógica de agregación a la ruta de escritura. Si la aplicación produce un error después de grabar la descarga pero antes de actualizar el recuento, la agregación se vuelve incoherente. | Cuando necesite una agregación sincrónica y muy coherente y pueda tolerar una latencia de escritura adicional. |
| Agregación materializada con Streams y Lambda | Desacopla la agregación de la ruta de escritura. En última instancia, la agregación es coherente (normalmente se retrasa unos segundos). Agrega los costos de invocación de Lambda. | Cuando necesita agregaciones casi en tiempo real con una latencia de lectura baja y que pueda tolerar una coherencia final. Este es el enfoque descrito en esta página. |
El enfoque de agregación materializada simplifica la ruta de escritura (basta con registrar la descarga), transfiere la agregación a un proceso asíncrono y almacena el resultado en DynamoDB, donde se puede consultar con una latencia de milisegundos de un solo dígito.
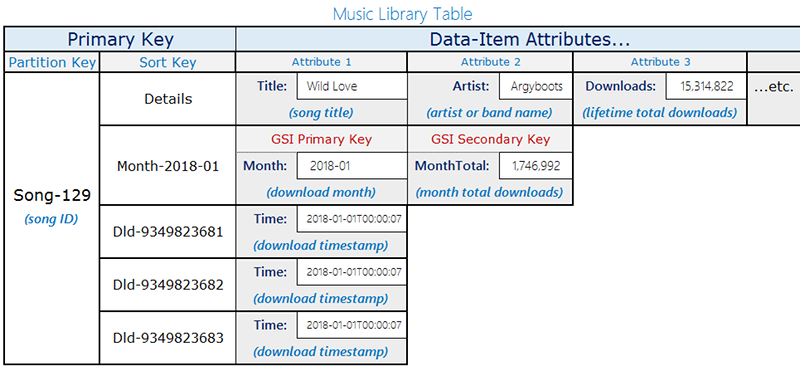
Diseño de tabla
En este diseño, se utiliza una sola tabla con dos tipos de elementos que comparten la misma clave de partición (songID) pero utilizan diferentes patrones de claves de clasificación entre ellos:
Descarga de registros: eventos de descarga individuales. La clave de clasificación es
DownloadID(un identificador único para cada descarga).Elementos de agregación mensual: recuentos de descargas precalculados por canción y mes. La clave de clasificación es el mes en formato
YYYY-MM(por ejemplo,2018-01). Estos elementos también contienen un atributoDownloadCountcon el total ejecutado.
Solo los elementos de agregación mensual contienen el atributo Month. Esta distinción es importante para el diseño de GSI disperso que se describe más adelante.
En el siguiente diagrama se muestra el diseño de la tabla con ambos tipos de elementos:
| Tipo de elemento | Clave de partición (songID) | Sort key | Atributos adicionales |
|---|---|---|---|
| Descarga de registro | song1 |
download-abc123 |
UserID, Timestamp |
| Agregación mensual | song1 |
2018-01 |
Month=2018-01,
DownloadCount=1,746,992 |
Canalización de agregación con Streams y AWS Lambda
La canalización de agregación funciona de la siguiente manera:
Cuando se descarga una canción, la aplicación escribe un nuevo elemento en la tabla con
Partition-Key=songIDySort-Key=DownloadID.DynamoDB Streams captura esta escritura como un registro de transmisión.
Una función de Lambda, adjunta a la transmisión, procesa el nuevo registro. Identifica el
songIDy el mes actual y, a continuación, actualiza el elemento de agregación mensual correspondiente incrementando el atributoDownloadCount.El elemento de agregación actualizado está entonces disponible para consultarlo a través del GSI disperso.
La función de Lambda usa una llamada de UpdateItem con una expresión ADD para incrementar de forma atómica el recuento de descargas. Esto evita las condiciones de carrera de lectura-modificación-escritura:
import boto3 dynamodb = boto3.resource('dynamodb') table = dynamodb.Table('MusicLibrary') def handler(event, context): for record in event['Records']: if record['eventName'] == 'INSERT': new_image = record['dynamodb']['NewImage'] song_id = new_image['songID']['S'] # Derive the month from the download timestamp timestamp = new_image['Timestamp']['S'] month = timestamp[:7] # Extract YYYY-MM table.update_item( Key={ 'songID': song_id, 'SK': month }, UpdateExpression='ADD DownloadCount :inc SET #m = :month', ExpressionAttributeNames={ '#m': 'Month' }, ExpressionAttributeValues={ ':inc': 1, ':month': month } )
nota
si se produce un error en una ejecución de Lambda después de escribir el valor de agregación actualizado, se puede volver a intentar el registro de flujo. Como la operación ADD incrementa el recuento cada vez que se ejecuta, al volver a intentarlo se incrementaría el recuento más de una vez para la misma descarga, lo que dejaría un valor aproximado. Para la mayoría de los casos de uso de análisis y tablas de clasificación, este pequeño margen de error es aceptable. Si necesita recuentos exactos, considere la posibilidad de agregar una lógica de idempotencia, por ejemplo, mediante una expresión de condición que compruebe si el DownloadID específico ya se ha procesado.
Diseño de GSI disperso
Para consultar de manera eficiente los resultados agregados, cree un índice secundario global con el siguiente esquema de claves:
Clave de partición de GSI:
Month(cadena)Clave de clasificación de GSI:
DownloadCount(número)
Este GSI es disperso porque solo los elementos de agregación mensuales contienen el atributo Month. Los registros de descarga individuales no tienen este atributo, por lo que se excluyen automáticamente del índice. Esto significa que GSI contiene solo los elementos de agregación calculados previamente, es decir, una pequeña fracción del total de elementos de la tabla.
Un GSI disperso ofrece dos beneficios clave:
Menor costo: dado que solo los elementos de agregación se replican en el índice, se consume mucha menos capacidad de escritura y almacenamiento en comparación con un índice que incluye todos los elementos de la tabla.
Consultas más rápidas: el índice contiene solo los datos que necesita consultar, por lo que las lecturas son eficientes y arrojan resultados con una latencia de milisegundos de un solo dígito.
Para obtener más información sobre cómo funcionan los índices dispersos, consulte Sacar partido de los índices dispersos.
Consulta del GSI
Con el GSI disperso establecido, puede responder de manera eficiente a varios tipos de consultas:
Obtenga la canción más descargada en un mes determinado:
aws dynamodb query \ --table-name "MusicLibrary" \ --index-name "MonthDownloadsIndex" \ --key-condition-expression "#m = :month" \ --expression-attribute-names '{"#m": "Month"}' \ --expression-attribute-values '{":month": {"S": "2018-01"}}' \ --scan-index-forward false \ --limit 1
La configuración de ScanIndexForward en false ordena los resultados por DownloadCount en orden descendente y Limit=1 devuelve solo la canción principal.
Obtenga las 10 mejores canciones de un mes determinado:
aws dynamodb query \ --table-name "MusicLibrary" \ --index-name "MonthDownloadsIndex" \ --key-condition-expression "#m = :month" \ --expression-attribute-names '{"#m": "Month"}' \ --expression-attribute-values '{":month": {"S": "2018-01"}}' \ --scan-index-forward false \ --limit 10
Obtenga todas las canciones descargadas en un mes determinado (ordenadas por número de descargas):
aws dynamodb query \ --table-name "MusicLibrary" \ --index-name "MonthDownloadsIndex" \ --key-condition-expression "#m = :month" \ --expression-attribute-names '{"#m": "Month"}' \ --expression-attribute-values '{":month": {"S": "2018-01"}}' \ --scan-index-forward false
Consideraciones
Tenga en cuenta lo siguiente al implementar este patrón:
Coherencia final: los valores de agregación se actualizan de forma asíncrona a través de DynamoDB Streams y Lambda. Por lo general, hay un retraso de unos segundos entre la grabación de una descarga y la actualización de la agregación. Esto significa que GSI refleja datos casi en tiempo real, no datos en tiempo real.
Simultaneidad de Lambda: si la tabla tiene un volumen de escritura alto, es posible que varias invocaciones de Lambda intenten actualizar el mismo elemento de agregación simultáneamente. La operación
ADDatómica gestiona esto de forma segura, pero debe supervisar las métricas de simultaneidad y limitación de Lambda para garantizar que la función pueda seguir el ritmo de la transmisión.Capacidad de escritura de GSI: dado que el GSI disperso solo contiene elementos de agregación, requiere una capacidad de escritura significativamente menor que la tabla base. Sin embargo, debe aprovisionar suficiente capacidad (o utilizar el modo bajo demanda) para gestionar la frecuencia de las actualizaciones de agregación.
Recuentos aproximados: como se indicó anteriormente, los reintentos de Lambda pueden provocar que los recuentos se sobrepasen ligeramente. Para los casos de uso que requieren recuentos exactos, implemente comprobaciones de idempotencia en la función de Lambda.
