Sacar partido de los índices dispersos
En cualquier elemento de una tabla, DynamoDB escribe una entrada de índice correspondiente solo si los atributos de la clave de índice están presentes en el elemento. En el caso de un índice secundario global, esto significa que la clave de partición del índice debe estar definida en el elemento y, si el índice también tiene una clave de clasificación, ese atributo también debe estar presente. Si falta alguno de los atributos clave en un elemento, ese elemento no aparece en el índice. Un índice en el que solo aparece un subconjunto de elementos de la tabla base se llama índice disperso.
Los índices dispersos resultan útiles para las consultas que se realizan en una pequeña subsección de una tabla. Por ejemplo, supongamos que tiene una tabla en la que almacena todos los pedidos de los clientes con los siguientes atributos de clave:
-
Clave de partición: :
CustomerId -
Clave de clasificación: :
OrderId
Para hacer un seguimiento de los pedidos abiertos, puede incluir un atributo llamado isOpen en los elementos de pedido que aún no se han enviado. Posteriormente, cuando estos pedidos se envíen, podrá borrar el atributo. Si crea un índice de CustomerId (clave de partición) e isOpen (clave de ordenación), en este índice solo aparecerán los pedidos en los que isOpen está definido. Cuando tiene miles de pedidos de los cuales solo hay abiertos un pequeño número, resulta más rápido y económico consultar los pedidos abiertos de ese índice que examinar toda la tabla.
En lugar de utilizar un tipo de atributo como isOpen, podría utilizar en el índice un atributo con un valor que diera como resultado un criterio de ordenación útil. Por ejemplo, podría utilizar un atributo OrderOpenDate establecido en la fecha en la que se realizó el pedido y borrarlo cuando el pedido se haya completado. De ese modo, cuando consulte el índice disperso, los elementos devueltos estarán ordenados en función de la fecha en que se realizó cada pedido.
Ejemplos de índices dispersos en DynamoDB
De forma predeterminada, los índices secundarios globales son dispersos. Cuando crea un índice secundario global, especifica una clave de partición y, de forma opcional, una clave de ordenación. Solo los elementos de la tabla base que contienen los atributos de claves requeridos aparecen en el índice. Si a un elemento le falta la clave de partición del índice (o la clave de clasificación, si hay una definida), ese elemento se excluye del índice.
Si diseña un índice secundario global para que sea disperso, puede aprovisionarlo con un menor rendimiento de escritura que el de la tabla base y seguir disfrutando de un nivel de rendimiento excelente.
Por ejemplo, es posible que una aplicación de juego hiciera un seguimiento de todas las puntuaciones de cada usuario, pero lo normal es que solo deban consultarse unas cuentas puntuaciones. El diseño siguiente se adapta eficazmente a este escenario:
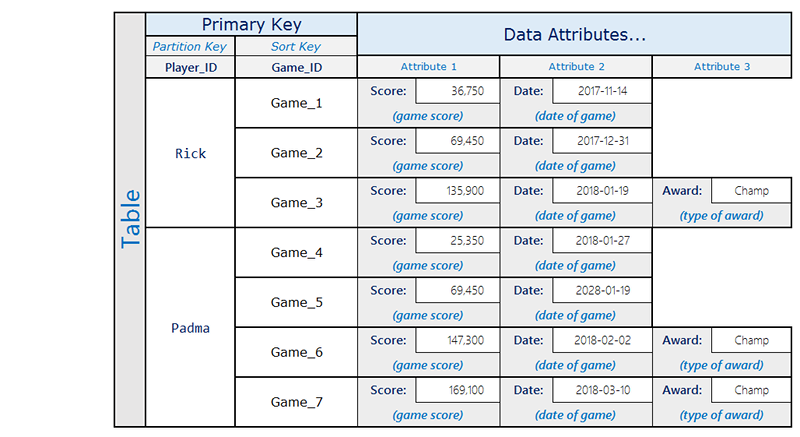
Aquí, Rick ha jugado tres partidas y ha conseguido el estado Champ en una de ellas. Padma ha jugado cuatro partidas y ha conseguido el estado Champ en dos de ellas. Observe que el atributo Award solamente está presente en los elementos en los que el usuario consiguió una recompensa. El índice secundario global asociado sería similar al siguiente:
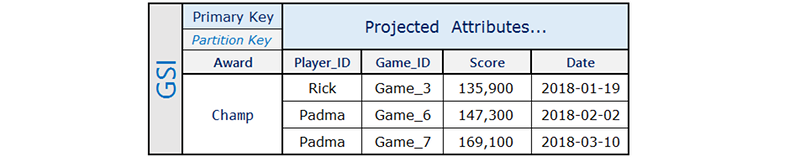
El índice secundario global únicamente contiene las puntuaciones máximas que se consultan con frecuencia, lo que conforma un pequeño subconjunto de los elementos de la tabla base.
