Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Schritt 3: Stellen Sie mithilfe des Assistenten für das Bereitstellungs-Dashboard einen Anwendungsfall bereit
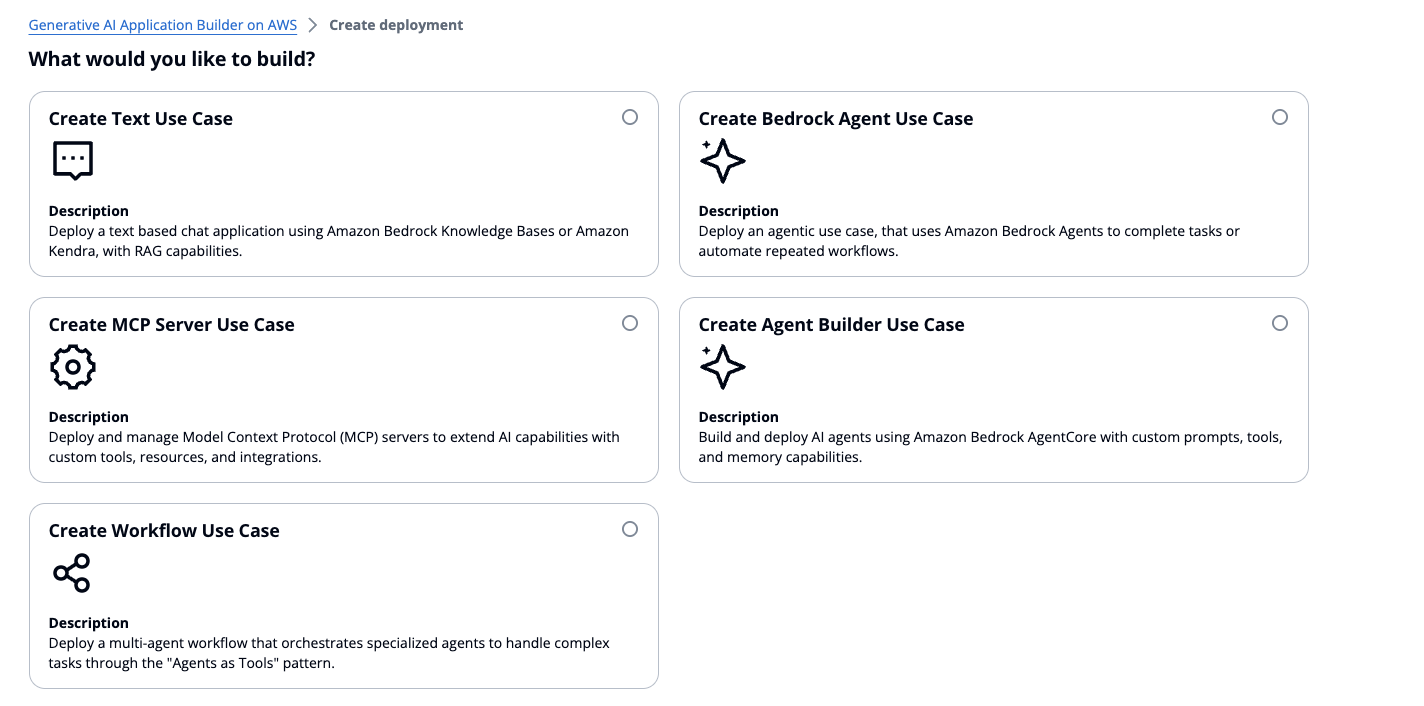
Im Assistenten für das Bereitstellungs-Dashboard müssen Sie zwischen den folgenden Optionen wählen:
-
Anwendungsfall Text — Stellt eine Chat-Anwendung mit optionalen RAG-Funktionen bereit
-
Anwendungsfall Bedrock Agent — Nutzt Amazon Bedrock Agents, um Aufgaben zu erledigen oder sich wiederholende Workflows zu automatisieren
-
MCP-Server — Stellen Sie MCP-Server mit Gateway- oder Runtime-Methoden bereit und verwalten Sie sie
-
Agent Builder — Erstellen und implementieren Sie benutzerdefinierte Agenten AgentCore mit MCP-Integration und Speicherverwaltung
-
Workflow Builder — Orchestrieren Sie mehrere Agent Builder-Agenten mithilfe hierarchischer Delegierung
Zeigt fünf Optionen: Text-Anwendungsfall erstellen, Bedrock Agent-Anwendungsfall erstellen, MCP-Server-Anwendungsfall erstellen, Agent Builder-Anwendungsfall erstellen oder Workflow-Anwendungsfall erstellen.
Schritt 3a: Stellen Sie einen Text-Anwendungsfall bereit
Dieser Abschnitt enthält Anweisungen zur Bereitstellung eines Text-Anwendungsfalls.
Wählen Sie einen Anwendungsfall
Wenn Sie „Text-Anwendungsfall erstellen“ wählen, öffnet die Benutzeroberfläche den Bildschirm „Anwendungsfall auswählen“. Geben Sie die folgenden Informationen ein:
-
Name des Anwendungsfalls.
-
Optionale E-Mail-Adresse für den Standardbenutzer des Anwendungsfalls, der dem Amazon Cognito Cognito-Benutzerpool für den Anwendungsfall hinzugefügt werden soll und dem er Berechtigungen zur Interaktion mit diesem erhält.
-
Ob Sie für diesen Anwendungsfall eine Benutzeroberfläche bereitstellen möchten. Wenn Sie keine Benutzeroberfläche mit dem Anwendungsfall bereitstellen möchten, können Sie die bereitgestellten API-Endpunkte für die Verwendung mit Ihrer Anwendung verwenden.
Details zu Anwendungsfällen
Im Schritt mit den Anwendungsfalldetails können Sie zusätzliche Einstellungen für Ihre Bereitstellung konfigurieren.
Standardmäßig erstellt und konfiguriert der Text-Anwendungsfall einen Amazon Cognito Cognito-Benutzerpool für Sie, wenn die Lösung das Deployment-Dashboard bereitstellt. Die Lösung authentifiziert neue Anwendungsfälle mit einem neu erstellten Client im selben Benutzerpool. Sie können in diesem Schritt jedoch eine bestehende Benutzerpool-ID und Client-ID angeben, wenn Sie Ihren eigenen Amazon Cognito Cognito-Benutzerpool und Client für den Anwendungsfall verwenden möchten.
Wichtig
Admin-Benutzer haben Zugriff auf alle bereitgestellten Anwendungsfälle, wenn der Amazon Cognito Cognito-Benutzerpool über den Bereitstellungsassistenten erstellt wird. Wenn Sie während der Bereitstellung Ihren eigenen Benutzerpool bereitstellen, müssen Sie sicherstellen, dass der Administrator über die Berechtigungen für den Zugriff auf die bereitgestellten Anwendungsfälle verfügt.
Sie müssen auch die Einstellungen Zulässiger Rückruf URLs und Zulässige Abmeldung URLs in Ihren App-Clients in Cognito aktualisieren. So gehen Sie vor:
-
Navigieren Sie zur Cognito-Konsole
-
Wählen Sie User Pools (Benutzerpools) aus.
-
Wählen Sie Ihren Benutzerpool.
-
Wählen Sie im linken Menü App Clients aus.
-
Wählen Sie den App-Client aus, den Sie ändern möchten.
-
Wählen Sie den Tab Anmeldeseiten.
-
Wählen Sie Bearbeiten und fügen Sie Ihre hinzu URLs.
-
Wählen Sie Änderungen speichern aus.
Wenn Sie einem Anwendungsfall weitere Benutzer hinzufügen müssen, finden Sie weitere Informationen im Abschnitt Verwaltung des Cognito-Benutzerpools.
Wählen Sie die Netzwerkkonfiguration
Mit diesem Assistentenschritt können Sie den Anwendungsfall mit einer bereits vorhandenen oder neuen Amazon Virtual Private Cloud
Auswählen eines Modells
Im Schritt Modell auswählen können Sie Ihren Modellanbieter aus dem Drop-down-Menü auswählen. Es gibt zwei Optionen: Bedrock und. SageMaker
Wenn Sie sich dafür entscheiden SageMaker, können Sie in der AI-Konsole einen SageMaker KI-Modellendpunkt erstellen und das SageMaker Eingabeschema angeben, das das Modell JSONPath für die LLM-Antwort erwartet und ausgeben wird. Sie können sich den Abschnitt Amazon SageMaker AI als LLM-Anbieter verwenden und Beispiele für SageMaker KI-Nutzlasten
Wenn Sie Amazon Bedrock auswählen, werden Ihnen vier Optionen angeboten:
-
Schnellstartmodelle — Mit einer Sammlung von Modellen mit unterschiedlichen price/performance Eigenschaften können Sie schnell loslegen. Empfohlen für die Erstellung Ihrer ersten Apps. Mit dieser Option können Sie einen Modellnamen aus der bereitgestellten Liste auswählen.
-
Andere Foundation-Modelle — Greifen Sie auf die gesamte Palette von Foundation-Modellen mit unterschiedlichen Funktionen und Spezialisierungen zu. Mit dieser Option können Sie die Modell-ID für Ihr gewünschtes Bedrock On-Demand-Foundation-Modell eingeben.
-
Inferenzprofile — Inferenzprofile nutzen die regionsübergreifende Inferenz von Bedrock, um den Durchsatz zu erhöhen und die Ausfallsicherheit zu verbessern, indem sie Ihre Anfragen bei Spitzenauslastung über mehrere AWS-Regionen weiterleiten. Mit dieser Option können Sie die ID des Inferenzprofils eingeben, das Sie verwenden möchten.
-
Bereitgestellte Modelle — Dedizierte Durchsatzkapazität für Produktionsworkloads, die eine konsistente Leistung erfordern. Mit dieser Option können Sie den ARN des provisioned/custom Modells eingeben, das von Amazon Bedrock verwendet werden soll.
Im Schritt zur Modellauswahl können Sie auch Ihre erweiterten Modelleinstellungen auswählen. Einzelheiten zur Konfiguration von Amazon Bedrock Guardrails, zum bereitgestellten Durchsatz für Amazon Bedrock und zu zusätzlichen Modellparametern finden Sie unter Erweiterte LLM-Einstellungen.
Regionsübergreifende Inferenz
Regionsübergreifende Inferenz hilft Amazon Bedrock-Benutzern, ungeplante Datenverkehrsspitzen nahtlos zu bewältigen, indem sie Rechenleistung in verschiedenen AWS-Regionen nutzen. Um regionsübergreifende Inferenz verwenden zu können, benötigen Sie das Inferenzprofil. Ein Inferenzprofil ist eine Abstraktion über einen On-Demand-Ressourcenpool aus einer konfigurierten Gruppe von AWS-Regionen. Es kann Ihre Inferenzanfrage, die aus Ihrer Quellregion stammt, an eine andere Region weiterleiten, die in diesem Pool konfiguriert ist. Dies ermöglicht die Verteilung des Datenverkehrs auf mehrere AWS-Regionen. Dies trägt zu einem höheren Durchsatz und einer verbesserten Ausfallsicherheit in Zeiten hoher Anforderungen bei.
Inferenzprofile sind nach dem Modell und den Regionen benannt, die sie unterstützen. Sie müssen ein Inferenzprofil aus einer der Regionen aufrufen, die es enthält. Wie in der folgenden Tabelle dargestellt, us.anthropic.claude-3-haiku-20240307-v1:0 ermöglicht die ID des Inferenzprofils beispielsweise die Verteilung des Datenverkehrs auf us-east-1 verschiedene us-west-2 Regionen des ausgewählten Modells. Bestimmte Modelle sind nur mit einem Inferenzprofil in einer bestimmten Region verfügbar.
| Inferenzprofil | ID des Inferenzprofils | Eingeschlossene Regionen |
|---|---|---|
|
US Anthropic Claude 3 Haiku |
|
USA Ost (Nord-Virginia) ( USA West (Oregon) ( |
Wenn Sie eine Inferenzprofil-ID anstelle einer Modell-ID verwenden möchten, müssen Sie die entsprechende Inferenzprofil-ID identifizieren. Weitere Informationen finden Sie unter Unterstützte Regionen und Modelle für Inferenzprofile im Amazon Bedrock-Benutzerhandbuch. In der Amazon Bedrock-Konsole
Nachdem Sie die zu verwendende Inferenzprofil-ID identifiziert haben, können Sie diese in der Phase Modell auswählen verwenden, indem Sie die folgenden Schritte ausführen:
-
Wählen Sie Amazon Bedrock als Modellanbieter aus.
-
Wählen Sie das Optionsfeld „Inference Profiles“ aus.
-
Geben Sie Ihre Inferenzprofil-ID in das angezeigte Textfeld ein.
Weitere Informationen zu Inferenzprofilen finden Sie unter Verbessern der Resilienz mit regionsübergreifender Inferenz im Amazon Bedrock-Benutzerhandbuch.
Wählen Sie die Wissensdatenbank aus
Wenn Sie einen Anwendungsfall ohne Retrieval Augmented Generation (RAG) implementieren möchten, können Sie diesen Schritt überspringen.
Wenn Sie RAG jedoch als Teil Ihrer Bereitstellung aktivieren möchten, können Sie jetzt entweder eine vorkonfigurierte Amazon Kendra Index-ID oder eine Amazon Bedrock Knowledge Base-ID angeben. Sie können auch einen neuen Amazon Kendra Index für die Verwendung mit der Lösung erstellen. Die Lösung unterstützt derzeit Amazon Kendra und Amazon Bedrock Knowledge Bases als Wissensdatenbanken für Ihre RAG-basierte Anwendungsfallbereitstellung.
Richtlinien zur Aufnahme von Daten in die Wissensdatenbank zur Verwendung mit Ihrer RAG-basierten Bereitstellung finden Sie im Abschnitt Konfiguration einer Wissensdatenbank.
Erweiterte RAG-Konfigurationen
Mit dem Assistenten können Sie erweiterte Optionen für Ihre RAG-Implementierung auswählen, z. B. die Anzahl der Dokumente, die jedes Mal abgerufen werden sollen, wenn eine Anfrage an Ihre Wissensdatenbank gesendet wird, eine statische Textantwort des LLM, wenn keine Dokumente in der Wissensdatenbank gefunden werden, ob Sie Dokumentquellen mit Ihrer LLM-Antwort für Plausibilitätsprüfungen anzeigen möchten usw. Sie können zusätzlich auch wissensdatenbankspezifische Konfigurationen für Amazon Kendra konfigurieren, z. B. Role-based Access Control (RBAC) oder Override Search Type, wenn Sie Amazon OpenSearch Serverless mit Amazon Bedrock Knowledge Bases verwenden. Weitere Informationen zu diesen erweiterten Einstellungen finden Sie im Abschnitt Erweiterte Knowledge Base-Einstellungen.
Anmerkung
Ihre Wissensdatenbank muss sich in demselben Konto und derselben Region befinden wie das bereitgestellte Deployment-Dashboard und die Anwendungsfall-Stacks.
Wählen Sie Eingabeaufforderungen und Token-Limits
In diesem Schritt können Sie Ihre Aufforderung für die Verwendung mit dem LLM konfigurieren. Für Eingabeaufforderungen können Platzhalter wie{input}, und erforderlich sein. {history} {context} Diese Platzhalter weisen das LLM an, woher Benutzereingaben, Konversationsverlauf und aus der Wissensdatenbank abgerufene Informationen stammen sollen.
-
Für Bedrock-Modellanbieter muss die Systemaufforderung bereitgestellt werden, die keine Einschränkungen für einen anderen Anwendungsfall als RAG enthält. Die Aufforderung zur Begriffsklärung für den Bedrock-Modellanbieter erfordert jedoch mindestens zwei Platzhalter - und
{input}{history} -
Für die Eingabeaufforderungen SageMaker Modellanbieter, System und Disambiguierung benötigen beide mindestens zwei Platzhalter — und.
{input}{history} -
Für RAG-Anwendungsfälle ist für jeden Modellanbieter zusätzlich der
{context}Platzhalter erforderlich.
Weitere Informationen finden Sie unter Konfiguration Ihrer Eingabeaufforderungen. Bei der Auswahl der Token-Limits für Ihre Eingabeaufforderungen können Sie auch den Abschnitt Tipps zur Verwaltung von Modell-Token-Limits lesen.
Aktivieren Sie die multimodale Eingabe
In diesem Schritt können Sie multimodale Eingabefunktionen für Ihren Anwendungsfall aktivieren. Wenn diese Option aktiviert ist, können Benutzer Bilder und Dokumente zusammen mit ihren Textabfragen hochladen und senden.
Unterstützte Dateitypen und Einschränkungen:
-
Bilder: Bis zu 20 Bilder pro Nachricht. Jedes Bild darf nicht größer als 3,75 MB und 8.000 Pixel hoch und breit sein. Unterstützte Formate: PNG, JPEG, GIF, Webp
-
Dokumente: Bis zu 5 Dokumente pro Nachricht. Jedes Dokument darf nicht größer als 4,5 MB sein. Unterstützte Formate: pdf, csv, doc, docx, xls, xlsx, html, txt, md
So verwenden Sie multimodale Eingaben:
-
Aktivieren Sie den MultimodalEnabledParameter während der Bereitstellung des Anwendungsfalls
-
In der Chat-Oberfläche können Benutzer Dateien auf zwei Arten hochladen:
-
Klicken Sie im Chat-Eingabefeld auf die Upload-Schaltfläche oder
-
Dateien direkt in die Chat-Oberfläche ziehen und dort ablegen
-
-
Dateien werden auf Amazon S3 hochgeladen und vom ausgewählten Modell verarbeitet
-
Hochgeladene Dateien werden nach 48 Stunden automatisch gelöscht
Verfolgung des Dateistatus:
DevOps Benutzer können Dateimetadaten in DynamoDB überwachen, einschließlich Uploadzeit und Verarbeitungsstatus. Dateien können den folgenden Status haben:
-
ausstehend — Der Datei-Upload wurde initiiert, aber noch nicht abgeschlossen. Dies ist der Anfangsstatus, wenn eine vorsignierte URL generiert wird.
-
hochgeladen — Die Datei wurde erfolgreich auf S3 hochgeladen und ist bereit für die Verarbeitung durch das Modell.
-
gelöscht — Die Datei wurde vom Benutzer gelöscht und sollte für die Verarbeitung nicht mehr zugänglich sein.
-
ungültig — Die Überprüfung der Datei hat nicht bestanden (z. B. weil der Dateityp nicht übereinstimmt oder die Sicherheitsüberprüfung fehlgeschlagen ist).
Dateien mit dem Status „Ausstehend“, die nie hochgeladen werden, werden automatisch bereinigt, wenn ihre TTL abläuft. Nur Dateien mit dem Status „Hochgeladen“ können vom Modell verarbeitet werden.
Der multimodale S3-Bucket und die DynamoDB-Metadatentabelle sind in den Ausgaben des Deployment Dashboards mit den Schlüsseln MultimodalDataBucketName bzw. MultimodalDataMetadataTable verfügbar.
Anmerkung
Nicht alle Modelle unterstützen multimodale Eingaben. Stellen Sie sicher, dass Ihr ausgewähltes Modell die Bild- und Dokumentenverarbeitung unterstützt, bevor Sie diese Funktion aktivieren. In der Dokumentation Unterstützte Foundation-Modelle in Amazon Bedrock finden Sie Informationen dazu, welches Modell Image als Eingabemodalität unterstützt.
Wichtig
Von Benutzern hochgeladene Dateien werden in Amazon S3 mit einer Lebenszyklusrichtlinie von 48 Stunden gespeichert. Metadaten zu hochgeladenen Dateien werden in Amazon DynamoDB mit einer 24-Stunden-TTL für den Konversationsverlauf gespeichert.
Überprüfen und bereitstellen
Überprüfen Sie nach diesem Schritt die ausgewählten Einstellungen und wählen Sie „Anwendungsfall bereitstellen“. Der neue Anwendungsfall wird dann bereitgestellt und in Ihrer Bereitstellungs-Dashboard-Ansicht angezeigt, sodass Sie ihn weiter verwalten können.
Schritt 3b: Stellen Sie einen Bedrock Agent-Anwendungsfall bereit
Der Bedrock Agent-Anwendungsfall bietet einen leistungsstarken und sicheren Mechanismus zum Aufrufen von Amazon Bedrock Agents in Ihren Anwendungsfällen. Diese Funktion ermöglicht es Entwicklern, die Funktionen von KI-gestützten autonomen Agenten nahtlos zu integrieren, die mehrstufige Aufgaben über verschiedene Basismodelle, Datenquellen, Softwareanwendungen und Benutzerkonversationen hinweg orchestrieren und ausführen können, während gleichzeitig robuste Sicherheitsmaßnahmen eingehalten werden.
Voraussetzungen
Bevor Sie einen Amazon Bedrock-Agenten erstellen, stellen Sie sicher, dass Sie über Folgendes verfügen:
-
Das AWS-Konto, auf dem Generative AI Application Builder auf AWS bereitgestellt wird, mit Zugriff auf die Amazon Bedrock-Konsole.
-
Entsprechende IAM-Berechtigungen zum Erstellen und Verwalten von Amazon Bedrock Agents.
Einen Amazon Bedrock Agent erstellen
Detaillierte Anweisungen zur Erstellung eines Agenten finden Sie im Amazon Bedrock-Benutzerhandbuch unter Agenten manuell erstellen und konfigurieren. Sie können Optionen konfigurieren wie:
-
Anweisungen (Eingabeaufforderungen) für Ihren Agenten
-
Wissensdatenbank, die verwendet wird, um zusätzliche Informationen auf der Grundlage von Benutzereingaben nachzuschlagen
-
Agentenspeicher, damit sich Agenten Informationen über mehrere Sitzungen hinweg merken können (für maximal 30 Tage)
Nachdem Sie erfolgreich einen Amazon Bedrock-Agenten erstellt haben, können Sie mit dem Assistentenablauf für Generative AI Application Builder on AWS Bedrock Agent fortfahren. Wählen Sie dazu im Bereitstellungs-Dashboard die Option Neuen Anwendungsfall bereitstellen und anschließend Bedrock Agent-Anwendungsfall erstellen aus. Folgen Sie dem Assistenten und verwenden Sie die folgenden Schritte, um den Anwendungsfall zu konfigurieren.
Wählen Sie einen Anwendungsfall
Dieser Schritt entspricht dem zuvor beschriebenen Text-Anwendungsfall.
Wählen Sie die Netzwerkkonfiguration
Dieser Schritt entspricht dem zuvor beschriebenen Text-Anwendungsfall
Wählen Sie einen Agenten aus
In diesem Schritt müssen Sie die Agenten-ID und die Alias-ID des Amazon Bedrock-Agenten angeben, den Sie erstellt haben.
Schritt 3c: Implementieren Sie einen MCP-Server-Anwendungsfall
Der Anwendungsfall MCP (Model Context Protocol) Server ermöglicht Ihnen die Bereitstellung und Verwaltung von MCP-Servern, die in KI-Modelle und -Agenten integriert werden können. MCP-Server bieten eine standardisierte Möglichkeit, Tools, Ressourcen und Funktionen für KI-Anwendungen bereitzustellen. Sie können entweder MCP-Server aus vorhandenen Lambda-Funktionen erstellen und/oder benutzerdefinierte MCP-Server mithilfe von Container-Images hosten. APIs
Voraussetzungen
Stellen Sie vor der Bereitstellung eines MCP-Server-Anwendungsfalls sicher, dass Sie über Folgendes verfügen:
-
Das AWS-Konto, auf dem Generative AI Application Builder auf AWS bereitgestellt wird.
-
Entsprechende IAM-Berechtigungen zum Erstellen und Verwalten von Amazon Bedrock-Ressourcen AgentCore .
-
Abhängig von der von Ihnen gewählten Erstellungsmethode:
-
Für die Gateway-Methode (Lambda/API/MCPServer): Lambda-Funktionen, API-Endpunkte mit ihren entsprechenden Schemadateien (JSON-Format für Lambda, OpenAPI/Smithy für APIs) oder MCP-Server-URL-Endpunkte
-
Für Runtime Method (ECR): Ein Docker-Container-Image, das an Amazon ECR übertragen wurde und Ihre MCP-Serverimplementierung enthält
-
Methoden zur Erstellung von MCP-Servern
Die Lösung unterstützt zwei Methoden zum Erstellen von MCP-Servern:
Aus Lambda-, API- oder MCP-Server erstellen (Gateway-Methode)
Diese Methode erstellt ein MCP-Gateway, das bestehende Lambda-Funktionen APIs, REST oder externe MCP-Server umschließt und sie als MCP-Tools zugänglich macht. Das Gateway übernimmt die Protokollübersetzung zwischen MCP und Ihren vorhandenen Diensten.
-
Lambda-Ziele: Integrieren Sie bestehende Lambda-Funktionen, indem Sie die Funktion ARN und eine JSON-Schemadatei bereitstellen, die das Format der Funktion beschreibt input/output
-
OpenAPI-Ziele: Integrieren Sie REST APIs mithilfe von OpenAPI-Spezifikationen (JSON- oder YAML-Format) mit Unterstützung für OAuth 2.0 oder API-Schlüsselauthentifizierung
-
Smithy-Ziele: Integrieren Sie, die mithilfe von Smithy-Modelldateien (.smithy- oder .json-Format) APIs definiert wurden
-
MCP-Serverziele: Stellen Sie über URL-Endpunkte eine direkte Verbindung zu externen MCP-Servern her und ermöglichen so die Integration vorhandener MCP-Server ohne Bereitstellung einer neuen Infrastruktur
Sie können mehrere Ziele (bis zu 10) innerhalb eines einzigen MCP-Gateways konfigurieren, von denen jedes ein anderes Tool oder eine andere Funktion darstellt.
Hosting über ein ECR-Image (Runtime-Methode)
Diese Methode stellt einen containerisierten MCP-Server aus einem Amazon ECR-Image bereit. Verwenden Sie diesen Ansatz, wenn Sie über eine benutzerdefinierte MCP-Serverimplementierung verfügen, die als eigenständiger Service ausgeführt werden muss.
-
Geben Sie den URI des ECR-Images an (muss ein Tag enthalten,
:latestz. B. oder):v1.0.0 -
Konfigurieren Sie optional Umgebungsvariablen, um die Konfiguration an Ihren Container zu übergeben
-
Der Container muss das MCP-Protokoll implementieren und die erforderlichen Endpunkte verfügbar machen
Bereitstellen eines MCP-Servers
Um einen MCP-Server-Anwendungsfall bereitzustellen, wählen Sie im Bereitstellungs-Dashboard die Option Neuen Anwendungsfall bereitstellen und dann MCP-Server-Anwendungsfall erstellen aus. Folgen Sie dem Assistenten und verwenden Sie die folgenden Schritte, um den Anwendungsfall zu konfigurieren.
Wählen Sie einen Anwendungsfall
Dieser Schritt entspricht dem zuvor beschriebenen Text-Anwendungsfall.
Wählen Sie die Netzwerkkonfiguration
Derzeit ist nur der öffentliche Zugriff aktiviert und VPC wird für die Netzwerkkonfiguration nicht unterstützt.
MCP-Server erstellen
In diesem Schritt konfigurieren Sie Ihre MCP-Serverbereitstellung:
Methode zur Erstellung des MCP-Servers
Wählen Sie zwischen den beiden Erstellungsmethoden:
-
Aus Lambda-, API- oder MCP-Server erstellen: Erstellen Sie ein MCP-Gateway aus vorhandenen Lambda-Funktionen, API-Spezifikationen oder externen MCP-Serverendpunkten
-
Hosting über ein ECR-Image: Stellen Sie einen benutzerdefinierten MCP-Server aus einem Container-Image bereit
Anmerkung
Die Erstellungsmethode kann nach der Bereitstellung nicht geändert werden. Wenn Sie zwischen Methoden wechseln müssen, müssen Sie einen neuen MCP-Server-Anwendungsfall bereitstellen.
Gateway-Konfiguration (für die Lambda/API/MCP Servermethode)
Wenn Sie die Gateway-Methode ausgewählt haben, konfigurieren Sie ein oder mehrere Ziele:
-
Zielname (erforderlich): Ein benutzerfreundlicher Name zur Identifizierung dieser Zielkonfiguration
-
Zielbeschreibung (optional): Eine kurze Beschreibung dessen, was dieses Ziel tut
-
Zieltyp: Wählen Sie den zu konfigurierenden Zieltyp aus:
-
Lambda: Für AWS-Lambda-Funktionen
-
OpenAPI: Für REST APIs mit OpenAPI-Spezifikationen
-
Smithy: Für Modelldefinitionen APIs mit Smithy
-
MCP-Server: Für die direkte Verbindung zu externen MCP-Servern über URL-Endpunkte
-
-
Schemadatei (erforderlich): Laden Sie die Schemadatei hoch, die Ihr Ziel beschreibt:
-
Für Lambda: JSON-Schemadatei, die das input/output Format beschreibt. Einzelheiten zur Erstellung von Lambda-Tool-Schemas finden Sie unter Lambda-Toolschema im Amazon AgentCore Bedrock Developer Guide.
-
Für OpenAPI: OpenAPI-Spezifikationsdatei (JSON oder YAML). Einzelheiten zu den OpenAPI-Schemaanforderungen finden Sie unter OpenAPI-Schema im Amazon Bedrock AgentCore Developer Guide.
-
Für die Modelldatei Smithy: Smithy (.smithy oder .json). Einzelheiten zur Erstellung von Smithy-Zielen finden Sie unter Erstellen von Smithy-Zielen im Amazon Bedrock AgentCore Developer Guide.
-
-
Lambda-Funktion ARN (für Lambda-Ziele erforderlich): Der ARN der zu integrierenden Lambda-Funktion
-
MCP-Server-URL (erforderlich für MCP-Serverziele): Der URL-Endpunkt des externen MCP-Servers, zu dem eine Verbindung hergestellt werden soll. Die URL muss richtig codiert sein und der MCP-Server muss Toolfunktionen mit den MCP-Protokollversionen 2025-06-18 unterstützen. Weitere Informationen finden Sie unter MCP-Serverziele im Amazon Bedrock AgentCore Developer Guide.
-
Ausgehende Authentifizierung (für OpenAPI-Ziele erforderlich): Konfigurieren Sie die Authentifizierung für REST-API-Aufrufe:
-
Authentifizierungstyp: Wählen Sie OAuth 2.0 oder API-Schlüssel
-
ARN des Anbieters für ausgehende Authentifizierung: Der ARN des Anmeldeinformationsanbieters im Amazon Bedrock-Tokentresor AgentCore
-
Zusätzliche Konfigurationen: Abhängig vom Authentifizierungstyp:
-
Für OAuth 2.0: Konfigurieren Sie Bereiche und benutzerdefinierte Parameter
-
Für API-Schlüssel: Geben Sie den Speicherort (Header oder Abfrageparameter), den Parameternamen und das optionale Präfix an
-
-
Sie können mehrere Ziele (bis zu 10) hinzufügen, indem Sie Weiteres Ziel hinzufügen wählen. Jedes Ziel steht für ein separates Tool oder eine separate Funktion, die von Ihrem MCP-Server bereitgestellt wird.
ECR-Konfiguration (für die ECR-Image-Methode)
Wenn Sie die Runtime-Methode ausgewählt haben, geben Sie Folgendes an:
-
ECR-Image-URI (erforderlich): Die vollständige URI Ihres Docker-Images in Amazon ECR
-
Format:
account-id.dkr.ecr.region.amazonaws.com/repository-name:tag -
Das Image muss sich in derselben AWS-Region wie Ihre Bereitstellung befinden
-
Ein Tag ist erforderlich (z. B.
:latest,:v1.0.0)
-
-
Umgebungsvariablen (optional): Konfigurieren Sie Schlüssel-Wert-Paare, die zur Laufzeit an Ihren Container übergeben werden
-
Verwenden Sie diese, um Konfigurationen, Anmeldeinformationen oder benutzerdefinierte Flags bereitzustellen
-
Sie können bis zu 10 Umgebungsvariablen hinzufügen
-
Überprüfen und bereitstellen
Überprüfen Sie nach der Konfiguration Ihres MCP-Servers die ausgewählten Einstellungen und wählen Sie Deploy Use Case aus. Der neue MCP-Server-Anwendungsfall wird dann bereitgestellt und zur weiteren Verwaltung in Ihrer Bereitstellungs-Dashboard-Ansicht angezeigt.
Anmerkung
MCP-Serverbereitstellungen erstellen Ressourcen in Amazon Bedrock AgentCore, einschließlich Gateways, Laufzeiten und Workload-Identitäten. Diese Ressourcen werden automatisch von der Lösung verwaltet und bereinigt, wenn Sie den Anwendungsfall löschen.
Schritt 3d: Stellen Sie einen Agent Builder-Anwendungsfall bereit
Mit dem Agent Builder können Sie produktionsbereite KI-Agenten auf Amazon Bedrock erstellen, konfigurieren und bereitstellen. AgentCore Diese Funktion bietet die vollständige Kontrolle über das Verhalten der Agenten durch Systemaufforderungen, Modellauswahl, MCP-Serverintegration und Speicherverwaltung.
Der Bereitstellungsprozess ist in erster Linie derselbe wie bei einem Text-Anwendungsfall, mit einigen nennenswerten Unterschieden.
Wählen Sie einen Anwendungsfall
Dieser Schritt entspricht dem zuvor beschriebenen Text-Anwendungsfall.
Details zu Anwendungsfällen
Dieser Schritt entspricht dem zuvor beschriebenen Text-Anwendungsfall.
Agent konfigurieren
In diesem Schritt konfigurieren Sie die wichtigsten Agenteneinstellungen, einschließlich der Systemaufforderung, der verfügbaren servers/Strands MCP-Tools und des Speichers.
Systemaufforderung
Die Systemaufforderung definiert das Verhalten, die Persönlichkeit und die Fähigkeiten des Agenten. Sie können:
-
Bearbeiten Sie die Standardvorlage für Systemaufforderungen
-
Verwenden Sie die Schaltfläche Auf Standard zurücksetzen, um die ursprüngliche Vorlage wiederherzustellen
-
Fügen Sie Anweisungen zur Verwendung des Tools und zur Formatierung von Antworten bei
MCP-Serverintegration (optional)
Konfigurieren Sie Model Context Protocol-Server, um Ihrem Agenten Zugriff auf Unternehmenstools und -daten zu gewähren:
-
Wählen Sie in der Dropdownliste einen der verfügbaren MCP-Server aus
-
Sehen Sie sich die verfügbaren, sofort einsatzbereiten Tools an, auf die der Agent zugreifen kann
Anmerkung
MCP-Server müssen vor der Bereitstellung konfiguriert und zugänglich sein. Anweisungen zur Servereinrichtung finden Sie in der MCP-Dokumentation.
Speicherkonfiguration
Konfigurieren Sie, wie der Agent Kontext und Wissen beibehält:
-
Kurzzeitgedächtnis: Standardmäßig für alle Agenten aktiviert. Behält den Konversationskontext innerhalb der Sitzungen bei.
-
Langzeitgedächtnis: Aktiviert diese Option, um die Extraktion und Speicherung von Erkenntnissen sitzungsübergreifend zu aktivieren. Verwendet AgentCore Speicher mit semantischer Speicherstrategie.
Überprüfen und bereitstellen
Überprüfen Sie nach diesem Schritt die ausgewählten Einstellungen und wählen Sie Anwendungsfall bereitstellen aus. Die Installation von Agent Builder ist in der Regel in 10 bis 15 Minuten abgeschlossen. Der neue Anwendungsfall wird dann in der Deployment-Dashboard-Ansicht angezeigt, sodass Sie ihn weiter verwalten können.
Schritt 3e: Implementieren Sie einen Workflow-Anwendungsfall
Mit dem Workflow Builder können Sie Supervisor-Agenten erstellen, die mehrere Agent Builder-Agenten mithilfe des Delegierungsmusters Agents as Tools orchestrieren. Mit dieser Funktion können Sie komplexe Workflows mit mehreren Agenten erstellen, indem Sie bestehende Agent Builder-Bereitstellungen wiederverwenden.
Der Bereitstellungsprozess folgt einem ähnlichen Muster wie Agent Builder, mit zusätzlichen Schritten für die Agentensuche und -auswahl.
Wählen Sie einen Anwendungsfall
Dieser Schritt entspricht dem zuvor beschriebenen Text-Anwendungsfall.
Details zu Anwendungsfällen
Dieser Schritt entspricht dem zuvor beschriebenen Text-Anwendungsfall.
Supervisor Agent konfigurieren
In diesem Schritt konfigurieren Sie den Supervisor-Agenten, der die spezialisierten Agent Builder-Agenten koordiniert.
Systemaufforderung
Die Systemaufforderung definiert, wie der Supervisor Agent Arbeit an spezialisierte Agenten delegiert. Sie können:
-
Bearbeiten Sie die Standardvorlage für Systemaufforderungen
-
Fügen Sie Anweisungen für die Auswahl und Delegierung von Agenten hinzu
-
Definieren Sie, wie die Ergebnisse mehrerer Agenten zusammengefasst werden
-
Verwenden Sie die Schaltfläche Auf Standard zurücksetzen, um die ursprüngliche Vorlage wiederherzustellen
Anmerkung
In der Systemaufforderung sollte klar beschrieben werden, wann und wie die einzelnen Spezialagenten eingesetzt werden. Agentenbeschreibungen sind für eine ordnungsgemäße Delegierung von entscheidender Bedeutung.
Auswahl des Modells
Wählen Sie das Basismodell für den Supervisor-Agenten aus. Der Supervisor-Agent verwendet dieses Modell für:
-
Benutzeranfragen verstehen
-
Wählen Sie geeignete spezialisierte Agenten aus
-
Koordinieren Sie die Ausführung der Agenten
-
Antworten aggregieren und formatieren
Wählen Sie spezialisierte Agenten aus
In diesem Schritt wählen Sie aus, an welche Agent Builder-Agenten der Supervisor Arbeit delegieren kann.
Agenten hinzufügen
-
Klicken Sie auf Agent hinzufügen, um das Dialogfeld zur Agentenauswahl zu öffnen
-
Wählen Sie einen oder mehrere Agent Builder-Agenten aus der Liste aus
-
Lesen Sie die Agentenbeschreibungen, die dem Supervisor zur Verfügung gestellt werden
-
Bestätigen Sie die Auswahl
Anmerkung
-
Für Workflows ist mindestens ein Agent Builder-Anwendungsfall als spezialisierter Agent erforderlich
-
Alle spezialisierten Agenten müssen erfolgreich bereitgestellt werden, bevor der Workflow erstellt werden kann
Überprüfen und bereitstellen
Überprüfen Sie die Workflow-Konfiguration, einschließlich:
-
Aufforderung und Modell des Supervisor-Agent-Systems
-
Liste der spezialisierten Agenten
-
Speicher-Einstellungen
Wählen Sie „Anwendungsfall bereitstellen“. Die Workflow-Bereitstellung ist in der Regel in 15 bis 20 Minuten abgeschlossen. Der neue Workflow wird in Ihrer Bereitstellungs-Dashboard-Ansicht angezeigt, sodass Sie ihn weiter verwalten können.
