Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Überblick über maschinelles Lernen mit Amazon SageMaker AI
In diesem Abschnitt wird ein typischer Arbeitsablauf für maschinelles Lernen (ML) beschrieben und beschrieben, wie diese Aufgaben mit Amazon SageMaker AI erledigt werden können.
Bei Machine Learning lernt ein Computer, Prognosen oder Inferenzen zu erstellen. Zunächst verwenden Sie einen Algorithmus und Beispieldaten, um ein Modell zu trainieren. Dann integrieren Sie das Modell in Ihre Anwendung, um Inferenzen in Echtzeit und in großem Umfang zu generieren.
Das folgende Diagramm zeigt den typischen Workflow zum Erstellen eines ML-Modells. Es umfasst drei Phasen eines kreisförmigen Ablaufs, wie im Diagramm dargestellt, auf die wir näher eingehen werden:
-
Generieren von Beispieldaten
-
Trainieren eines Modells
-
Bereitstellen des Modells
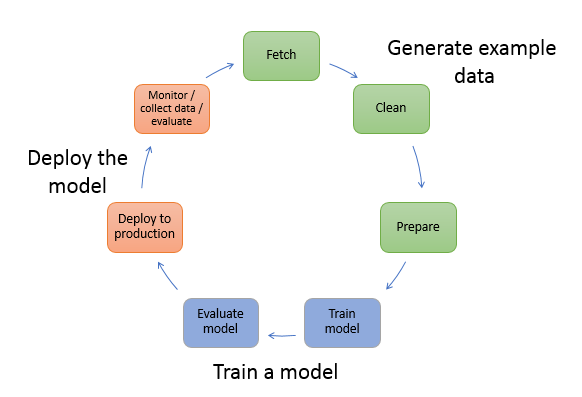
Das Diagramm zeigt, wie die folgenden Aufgaben in den meisten typischen Szenarien ausgeführt werden:
-
Generieren von Beispieldaten – Um ein Modell zu trainieren, benötigen Sie Beispieldaten. Der erforderliche Datentyp hängt von dem Geschäftsproblem ab, das Sie mit dem Modell lösen möchten. Dies bezieht sich auf die Inferenzen, die das Modell generieren soll. Angenommen, Sie möchten ein Modell erstellen, um eine Zahl anhand eines Eingabebilds mit einer handschriftlichen Ziffer zu prognostizieren. Zum Trainieren eines solchen Modells brauchen Sie Beispielbilder mit handschriftlichen Zahlen.
Häufig verbringen Datenexperten viel Zeit mit der Analyse und der Vorverarbeitung von Beispieldaten, bevor diese für die Modelltraining nutzbar sind. Für die Datenvorverarbeitung führen Sie in der Regel die folgenden Schritte aus:
-
Beschaffen der Daten – Möglicherweise verfügen Sie über interne Beispieldatenspeicher oder Sie verwenden öffentlich verfügbare Datensätze. In der Regel fassen Sie den Datensatz bzw. die Datensätze in einem einzigen Repository zusammen.
-
Bereinigen der Daten – Um das Modelltraining zu verbessern, untersuchen Sie die Daten und bereinigen Sie diese nach Bedarf. Falls die Daten beispielsweise ein
country name-Attribut mit den WertenUnited StatesundUSaufweisen, können Sie die Daten bearbeiten, damit sie konsistent sind. -
Vorbereiten oder Transformieren der Daten – Sie können weitere Datentransformationen vornehmen, um eine Leistungsverbesserung zu erzielen. Sie könnten sich beispielsweise dafür entscheiden, Attribute für ein Modell zu kombinieren, das die Bedingungen vorhersagt, unter denen ein Flugzeug enteist werden muss. Anstelle der beiden separaten Attribute für Temperatur und Luftfeuchtigkeit können Sie diese Attribute in einem neuen Attribut kombinieren und so das Modell verbessern.
In SageMaker KI können Sie Beispieldaten mithilfe von SageMaker APIs mit dem SageMaker Python-SDK
in einer integrierten Entwicklungsumgebung (IDE) vorverarbeiten. Mit SDK für Python (Boto3) können Sie Daten abrufen, untersuchen und für das Modelltraining vorbereiten. Informationen zur Datenaufbereitung, -verarbeitung und -umwandlung finden Sie unter Empfehlungen für die Auswahl des richtigen Tools zur Datenaufbereitung in SageMaker KI, Workloads zur Datentransformation mit SageMaker Verarbeitung und Erstellen, Speichern und Teilen von Features mit Feature Store. -
-
Trainieren eines Modells – Das Modelltraining umfasst sowohl das Trainieren als auch das Auswerten des Modells, wie nachfolgend erläutert:
-
Trainieren des Modells – Um ein Modell zu trainieren, benötigen Sie einen Algorithmus oder ein vortrainiertes Basismodell. Der auszuwählende Algorithmus hängt von mehreren Faktoren ab. Für eine integrierte Lösung können Sie einen der bereitgestellten Algorithmen verwenden. SageMaker Eine Liste der von bereitgestellten Algorithmen SageMaker und diesbezügliche Überlegungen finden Sie unterBuilt-in Algorithmen und vortrainierte Modelle in Amazon SageMaker. Eine UI-based Trainingslösung, die Algorithmen und Modelle bereitstellt, finden Sie unterSageMaker JumpStart vortrainierte Modelle.
Für ein Training werden zudem Ressourcen zur Datenverarbeitung benötigt. Ihr Ressourcenverbrauch hängt von der Größe des Trainingsdatensatzes ab und davon, wie schnell Sie Ergebnisse brauchen. Die verwendeten Ressourcen können von einer einzigen Allzweck-Instance bis zu einem verteilten Cluster aus GPU-Instances reichen. Weitere Informationen finden Sie unter Trainiere ein Modell mit Amazon SageMaker.
-
Auswerten des Modells – Nachdem Sie das Modell trainiert haben, werten Sie es aus und bestimmen Sie, ob die Inferenzgenauigkeit akzeptabel ist. Verwenden Sie zum Trainieren und Evaluieren Ihres Modells das SageMaker Python-SDK
, um Anfragen für Schlussfolgerungen über eine der verfügbaren IDEs an das Modell zu senden. Weitere Informationen zum Bewerten Ihres Modells finden Sie unter Überwachung der Daten- und Modellqualität mit Amazon SageMaker Model Monitor.
-
-
Bereitstellen des Modells – In der Regel überarbeiten Sie ein Modell, bevor Sie es in Ihre Anwendung integrieren und bereitstellen. Mit SageMaker KI-Hosting-Diensten können Sie Ihr Modell unabhängig bereitstellen, wodurch es von Ihrem Anwendungscode entkoppelt wird. Weitere Informationen finden Sie unter Modelle für Inference einsetzen.
Machine Learning ist ein fortlaufender Zyklus. Nach der Bereitstellung eines Modells überwachen Sie die Inferenzen, erfassen weitere hochwertige Daten und bewerten das Modell, um Abweichungen zu erkennen. Anschließend erhöhen Sie die Inferenzgenauigkeit, indem Sie die Trainingsdaten um die neu erfassten hochwertigen Daten ergänzen. Da immer mehr Beispieldaten verfügbar sind, können Sie das Modell weiterhin trainieren, um die Genauigkeit zu verbessern.
