Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Schritte zur Datenvorbereitung
Die Datenvorbereitungserfahrung von Amazon Quick Sight bietet elf leistungsstarke Schritttypen, mit denen Sie Ihre Daten systematisch transformieren können. Jeder Schritt dient einem bestimmten Zweck im Datenaufbereitungs-Workflow.
Die Schritte können über eine intuitive Oberfläche im Konfigurationsbereich konfiguriert werden. Sofortiges Feedback ist im Vorschaufenster sichtbar. Die Schritte können nacheinander kombiniert werden, um komplexe Datentransformationen zu erstellen, ohne dass SQL-Kenntnisse erforderlich sind.
Jeder Schritt kann entweder Eingaben aus einer physischen Tabelle oder die Ausgabe eines vorherigen Schritts erhalten. Die meisten Schritte akzeptieren eine einzige Eingabe, wobei die Schritte Anhängen und Verbinden die Ausnahmen bilden — diese erfordern genau zwei Eingaben.
Input
Der Eingabeschritt initiiert Ihren Datenvorbereitungs-Workflow in Quick Sight, indem Sie Daten aus mehreren Quellen auswählen und importieren können, um sie in nachfolgenden Schritten zu transformieren.
Eingabeoptionen
-
Datensatz hinzufügen
Nutzen Sie bestehende Quick Sight-Datensätze als Eingabequellen und bauen Sie auf Daten auf, die bereits von Ihrem Team vorbereitet und optimiert wurden.
-
Fügen Sie eine Datenquelle hinzu
Stellen Sie eine direkte Verbindung zu Datenbanken wie Amazon Redshift, Athena, RDS oder anderen unterstützten Quellen her, indem Sie bestimmte Datenbankobjekte auswählen und Verbindungsparameter angeben.
-
Datei hinzufügen (Upload)
Importieren Sie Daten direkt aus lokalen Dateien in Formaten wie CSV, TSV, Excel oder JSON.
Konfiguration
Der Eingabeschritt erfordert keine Konfiguration. Im Vorschaufenster werden Ihre importierten Daten zusammen mit Quellinformationen wie Verbindungsdetails, Tabellennamen und Spaltenmetadaten angezeigt.
Nutzungshinweise
-
Innerhalb eines einzigen Workflows können mehrere Eingabeschritte vorhanden sein.
-
Sie können zu jedem Zeitpunkt in Ihrem Workflow Eingabeschritte hinzufügen.
Berechnete Spalten hinzufügen
Mit dem Schritt Berechnete Spalten hinzufügen können Sie neue Spalten mithilfe von Ausdrücken auf Zeilenebene erstellen, die Berechnungen für vorhandene Spalten durchführen. Sie können neue Spalten mithilfe skalarer Funktionen und Operatoren (auf Zeilenebene) erstellen und Berechnungen auf Zeilenebene anwenden, die auf vorhandene Spalten verweisen.
Konfiguration
Um den Schritt Berechnete Spalten hinzufügen zu konfigurieren, gehen Sie im Konfigurationsbereich wie folgt vor:
-
Geben Sie Ihrer neuen berechneten Spalte einen Namen.
-
Speichern Sie Ihre Berechnung.
-
Zeigen Sie eine Vorschau der Ausdrucksergebnisse an.
-
Fügen Sie nach Bedarf weitere berechnete Spalten hinzu.
Nutzungshinweise
-
In diesem Schritt werden nur skalare Berechnungen (auf Zeilenebene) unterstützt.
-
In SPICE werden berechnete Spalten materialisiert und funktionieren in nachfolgenden Schritten als Standardspalten.
Datentyp ändern
Quick Sight vereinfacht die Datentypverwaltung, indem es vier abstrakte Datentypen unterstützt: date decimalinteger,, undstring. Diese abstrakten Typen reduzieren die Komplexität, indem sie verschiedene Quelldatentypen automatisch ihren Quick Sight-Entsprechungen zuordnen. Zum Beispiel bigint sind tinyintsmallint,integer, und alle zugeordnetinteger, während, datedatetime, und zugeordnet timestamp sind. date
Diese Abstraktion bedeutet, dass Sie nur die vier Datentypen von Quick Sight verstehen müssen, da Quick Sight bei der Interaktion mit verschiedenen Datenquellen alle zugrunde liegenden Datentypkonvertierungen und Berechnungen automatisch durchführt.
Konfiguration
Gehen Sie wie folgt vor, um den Schritt Datentyp ändern im Konfigurationsbereich zu konfigurieren:
-
Wählen Sie eine Spalte aus, die konvertiert werden soll.
-
Wählen Sie den Zieldatentyp (
stringinteger,decimal, oderdate). -
Geben Sie für Datumskonvertierungen die Formateinstellungen an und zeigen Sie eine Vorschau der Ergebnisse auf der Grundlage der Eingabeformate an. Sehen Sie sich die unterstützten Datumsformate in Quick Sight an.
-
Fügen Sie nach Bedarf weitere Spalten hinzu, um sie zu konvertieren.
Nutzungshinweise
-
Konvertiert aus Effizienzgründen die Datentypen mehrerer Spalten in einem einzigen Schritt.
-
Bei Verwendung von SPICE werden alle Datentypänderungen in den importierten Daten materialisiert.
Spalten umbenennen
Mit dem Schritt „Spalten umbenennen“ können Sie Spaltennamen so ändern, dass sie aussagekräftiger und benutzerfreundlicher sind und den Benennungskonventionen Ihrer Organisation entsprechen.
Konfiguration
Gehen Sie wie folgt vor, um den Schritt „Spalten umbenennen“ im Konfigurationsbereich zu konfigurieren:
-
Wählen Sie eine Spalte aus, die Sie benennen möchten.
-
Geben Sie einen neuen Namen für die ausgewählte Spalte ein.
-
Fügen Sie nach Bedarf weitere Spalten hinzu, um sie umzubenennen.
Nutzungshinweise
-
Alle Spaltennamen müssen innerhalb Ihres Datensatzes eindeutig sein.
Wählen Sie Spalten
Mit dem Schritt „Spalten auswählen“ können Sie Ihren Datensatz optimieren, indem Sie Spalten einbeziehen, ausschließen und neu anordnen. Auf diese Weise können Sie Ihre Datenstruktur optimieren, indem unnötige Spalten entfernt und die verbleibenden Spalten für die Analyse in einer logischen Reihenfolge angeordnet werden.
Konfiguration
Gehen Sie wie folgt vor, um den Schritt „Spalten auswählen“ im Konfigurationsbereich zu konfigurieren:
-
Wählen Sie bestimmte Spalten aus, die in Ihre Ausgabe aufgenommen werden sollen.
-
Wählen Sie die Spalten in Ihrer bevorzugten Reihenfolge aus, um die Reihenfolge festzulegen.
-
Verwenden Sie „Alle auswählen“, um die verbleibenden Spalten in ihrer ursprünglichen Reihenfolge einzubeziehen.
-
Schließen Sie unerwünschte Spalten aus, indem Sie sie nicht auswählen.
Die wichtigsten Funktionen
-
Die Ausgabespalten werden in der Reihenfolge der Auswahl angezeigt.
-
Mit der Option Alle auswählen wird die ursprüngliche Reihenfolge der Spalten beibehalten.
Nutzungshinweise
-
Nicht ausgewählte Spalten werden aus nachfolgenden Schritten entfernt.
-
Optimieren Sie die Datensatzgröße, indem Sie unnötige Spalten entfernen.
Anfügen
Der Schritt Anfügen kombiniert zwei Tabellen vertikal, ähnlich einer SQL UNION ALL-Operation. Quick Sight ordnet Spalten automatisch nach Namen und nicht nach Reihenfolge zu und ermöglicht so eine effiziente Datenkonsolidierung, selbst wenn Tabellen unterschiedliche Spaltenreihenfolgen oder eine unterschiedliche Anzahl von Spalten haben.
Konfiguration
Gehen Sie im Konfigurationsbereich wie folgt vor, um den Schritt „Anhängen“ zu konfigurieren:
-
Wählen Sie zwei Eingabetabellen zum Anhängen aus.
-
Überprüfen Sie die Reihenfolge der Ausgabespalten.
-
Untersuchen Sie, welche Spalten in beiden Tabellen und welche Spalten in einzelnen Tabellen vorhanden sind.
Schlüsselfunktionen
-
Ordnet Spalten nach Namen statt nach Reihenfolge zu.
-
Behält alle Zeilen aus beiden Tabellen bei, einschließlich Duplikate.
-
Unterstützt Tabellen mit unterschiedlicher Anzahl von Spalten.
-
Folgt der Spaltenreihenfolge von Tabelle 1 für übereinstimmende Spalten und fügt dann eindeutige Spalten aus Tabelle 2 hinzu.
-
Zeigt klare Quellindikatoren für alle Spalten
Nutzungshinweise
-
Verwenden Sie zuerst einen Umbenennungsschritt, wenn Sie Spalten mit unterschiedlichen Namen anhängen.
-
Jeder Schritt „Anfügen“ kombiniert genau zwei Tabellen. Verwenden Sie zusätzliche Anfügeschritte für weitere Tabellen.
Join
Beim Verbindungsschritt werden Daten aus zwei Tabellen auf der Grundlage übereinstimmender Werte in bestimmten Spalten horizontal kombiniert. Quick Sight unterstützt die Verbindungstypen Left Outer, Right Outer, Full Outer und Inner und bietet somit flexible Optionen für Ihre Analyseanforderungen. Dieser Schritt beinhaltet eine intelligente Lösung von Spaltenkonflikten, bei der doppelte Spaltennamen automatisch behandelt werden. Self-Joins sind zwar nicht als bestimmter Verbindungstyp verfügbar, mit Workflow-Divergenz können Sie jedoch ähnliche Ergebnisse erzielen.
Konfiguration
Gehen Sie im Konfigurationsbereich wie folgt vor, um den Join-Schritt zu konfigurieren:
-
Wählen Sie zwei Eingabetabellen aus, die verknüpft werden sollen.
-
Wählen Sie Ihren Verbindungstyp (Left Outer, Right Outer, Full Outer oder Inner).
-
Geben Sie die Verbindungsschlüssel für jede Tabelle an.
-
Überprüfen Sie die automatisch gelösten Spaltennamenkonflikte.
Schlüsselfunktionen
-
Unterstützt mehrere Verbindungstypen für unterschiedliche Analyseanforderungen.
-
Löst automatisch doppelte Spaltennamen auf.
-
Akzeptiert berechnete Spalten als Join-Schlüssel.
Nutzungshinweise
-
Join-Schlüssel müssen kompatible Datentypen haben. Verwenden Sie bei Bedarf den Schritt Datentyp ändern.
-
Jeder Join-Schritt kombiniert genau zwei Tabellen. Verwenden Sie zusätzliche Join-Schritte für mehr Tabellen.
-
Erstellen Sie nach dem Verbinden einen Umbenennungsschritt, um automatisch aufgelöste Spaltenüberschriften anzupassen.
Aggregate
Mit dem Schritt Aggregieren können Sie Daten zusammenfassen, indem Sie Spalten gruppieren und Aggregationsoperationen anwenden. Diese leistungsstarke Transformation verdichtet detaillierte Daten zu aussagekräftigen Zusammenfassungen, die auf Ihren angegebenen Dimensionen basieren. Quick Sight vereinfacht komplexe SQL-Operationen über eine intuitive Oberfläche und bietet umfassende Aggregationsfunktionen, einschließlich erweiterter Zeichenkettenoperationen wie und. ListAgg ListAgg distinct
Konfiguration
Gehen Sie im Konfigurationsbereich wie folgt vor, um den Schritt Aggregieren zu konfigurieren:
-
Wählen Sie die Spalten aus, nach denen gruppiert werden soll.
-
Wählen Sie Aggregationsfunktionen für Kennzahlspalten aus.
-
Passen Sie die Namen der Ausgabespalten an.
-
Für
ListAggundListAgg distinct:-
Wählen Sie die Spalte aus, die Sie aggregieren möchten.
-
Wählen Sie ein Trennzeichen (Komma, Gedankenstrich, Semikolon oder vertikale Linie).
-
-
Zeigen Sie eine Vorschau der zusammengefassten Daten an.
Unterstützte Funktionen pro Datentyp
| Datentyp | Unterstützte Funktionen |
|---|---|
|
Numerischer Wert |
|
|
Date |
|
|
String |
|
Schlüsselfunktionen
-
Wendet verschiedene Aggregationsfunktionen auf Spalten innerhalb desselben Schritts an.
-
Group by ohne Aggregationsfunktionen funktioniert wie SQL SELECT DISTINCT.
-
ListAggverkettet alle Werte;ListAgg distinctbeinhaltet nur eindeutige Werte. -
ListAggFunktionen behalten standardmäßig die aufsteigende Sortierreihenfolge bei.
Nutzungshinweise
-
Durch die Aggregation wird die Anzahl der Zeilen in Ihrem Datensatz erheblich reduziert.
-
ListAggundListAgg distinctunterstütztdateWerte, aber nichtdatetime. -
Verwenden Sie Trennzeichen, um die Ausgabe der Zeichenkettenverkettung anzupassen.
Filter
Mit dem Schritt Filter können Sie Ihren Datensatz eingrenzen, indem Sie nur Zeilen einbeziehen, die bestimmte Kriterien erfüllen. Sie können innerhalb eines einzigen Schritts mehrere Filterbedingungen anwenden, die alle durch AND Logik kombiniert werden, um Ihre Analyse auf relevante Daten zu konzentrieren.
Konfiguration
Gehen Sie im Konfigurationsbereich wie folgt vor, um den Schritt Filter zu konfigurieren:
-
Wählen Sie eine Spalte aus, die gefiltert werden soll.
-
Wählen Sie einen Vergleichsoperator.
-
Geben Sie Filterwerte auf der Grundlage des Datentyps der Spalte an.
-
Fügen Sie bei Bedarf zusätzliche Filterbedingungen für verschiedene Spalten hinzu.
Anmerkung
-
Zeichenkettenfilter mit „ist in“ oder „ist nicht in“: Geben Sie mehrere Werte ein (einen pro Zeile).
-
Numerische Filter und Datumsfilter: Geben Sie Einzelwerte ein (außer „zwischen“, für das zwei Werte erforderlich sind).
Unterstützte Operatoren pro Datentyp
| Datentyp | Unterstützte Operatoren |
|---|---|
|
Ganzzahl und Dezimalzahl |
Entspricht, ist ungleich Größer als, Kleiner als Ist größer als oder gleich, ist kleiner als oder gleich Ist zwischen |
|
Date |
Nachher, Vorher Ist zwischen Ist danach oder gleich, Ist davor oder gleich |
|
String |
Entspricht, ist ungleich Beginnt mit, endet mit Enthält, Enthält nicht Ist drin, ist nicht drin |
Nutzungshinweise
-
Wenden Sie mehrere Filterbedingungen in einem einzigen Schritt an.
-
Kombinieren Sie Bedingungen für verschiedene Datentypen.
-
Zeigen Sie eine Vorschau der gefilterten Ergebnisse in Echtzeit an.
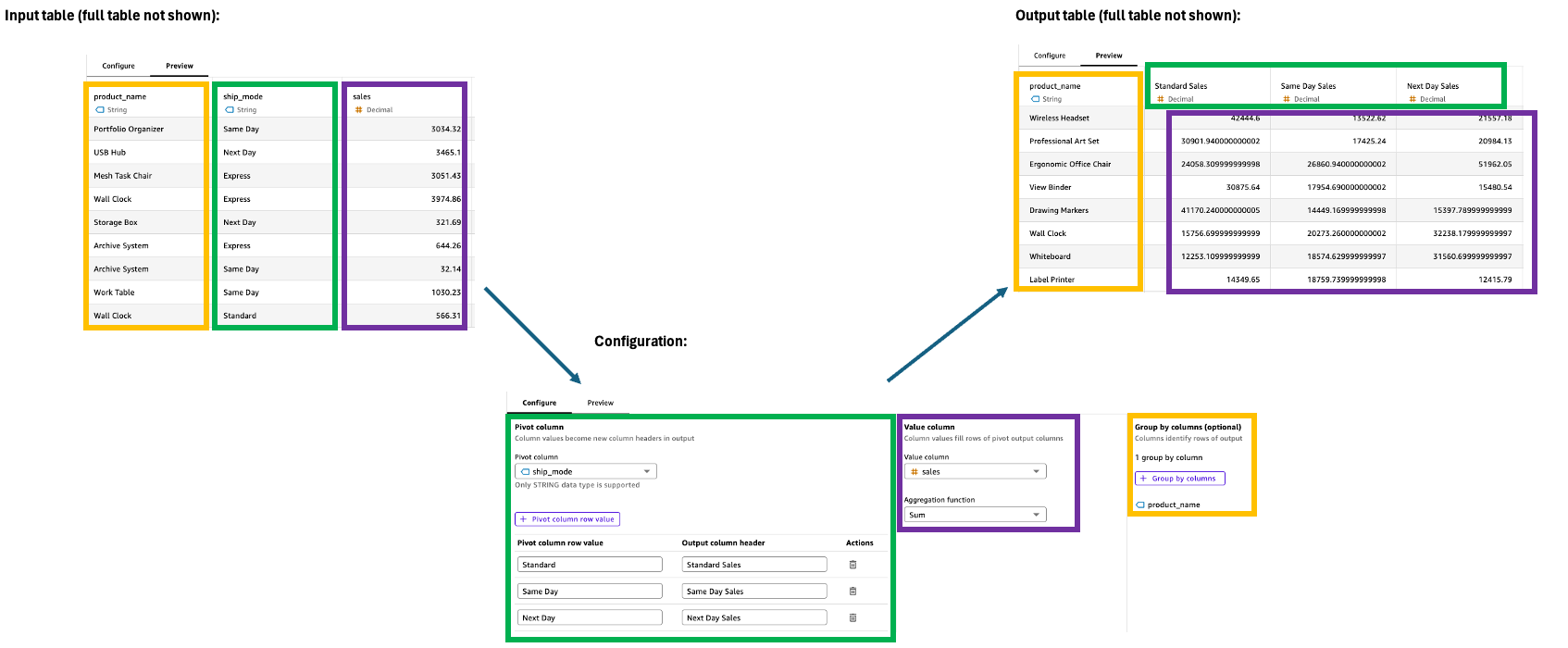
Pivot
Im Pivot-Schritt werden Zeilenwerte in eindeutige Spalten umgewandelt. Dabei werden Daten für einfachere Vergleiche und Analysen von einem Langformat in ein Breitformat konvertiert. Für diese Transformation sind Spezifikationen für die Filterung, Aggregation und Gruppierung von Werten erforderlich, um die Ausgabespalten effektiv verwalten zu können.
Konfiguration
Verwenden Sie im Konfigurationsbereich Folgendes, um den Pivot-Schritt zu konfigurieren:
-
Pivot-Spalte: Wählen Sie die Spalte aus, deren Werte zu Spaltenüberschriften werden sollen (z. B. Kategorie).
-
Spaltenzeilenwert pivotieren: Filtert bestimmte Werte, die aufgenommen werden sollen (z. B. Technologie, Bürobedarf).
-
Spaltenüberschrift ausgeben: Passen Sie neue Spaltenüberschriften an (standardmäßig werden Pivot-Spaltenwerte verwendet).
-
Wertespalte: Wählen Sie die Spalte aus, die aggregiert werden soll (z. B. Umsatz).
-
Aggregationsfunktion: Wählen Sie die Aggregationsmethode (z. B. Summe).
-
Gruppieren nach: Geben Sie die Anordnung der Spalten an (z. B. Segment).
Unterstützte Operatoren pro Datentyp
| Datentyp | Unterstützte Operatoren |
|---|---|
|
Ganzzahl und Dezimalzahl |
|
|
Date |
|
|
String |
|
Nutzungshinweise
-
Jede pivotierte Spalte enthält aggregierte Werte aus der Wertspalte.
-
Passen Sie die Spaltenüberschriften aus Gründen der Übersichtlichkeit an.
-
Sehen Sie sich eine Vorschau der Transformationsergebnisse in Echtzeit an.
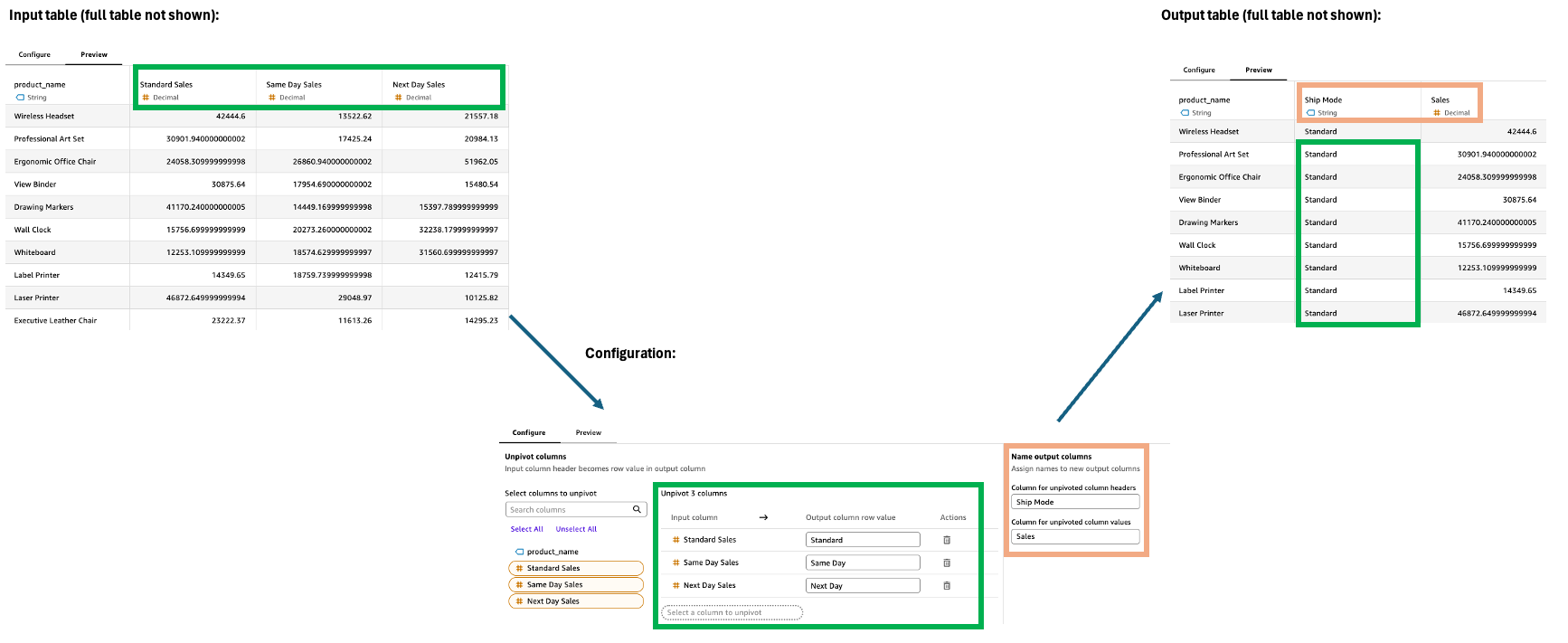
Entpivotieren
Der Schritt Unpivot wandelt Spalten in Zeilen um, wodurch breite Daten in ein längeres, schmaleres Format umgewandelt werden. Diese Transformation hilft dabei, Daten, die über mehrere Spalten verteilt sind, in einem strukturierteren Format zu organisieren, sodass sie einfacher analysiert und visualisiert werden können.
Konfiguration
Gehen Sie im Konfigurationsbereich wie folgt vor, um den Schritt „Unpivot“ zu konfigurieren:
-
Wählen Sie Spalten aus, deren Pivotierung in Zeilen aufgehoben werden soll.
-
Definieren Sie die Zeilenwerte der Ausgabespalte. Die Standardeinstellung ist der ursprüngliche Spaltenname. Einige Beispiele hierfür sind Technologie, Bürobedarf und Möbel.
-
Benennen Sie die beiden neuen Ausgabespalten.
-
Unpivotierte Spaltenüberschrift: Der Name für frühere Spaltennamen (z. B. Kategorie)
-
Spaltenwerte ohne Pivotierung: Der Name für die nicht pivotierten Werte (z. B. Vertrieb)
-
Schlüsselfunktionen
-
Behält alle nicht pivotierten Spalten in der Ausgabe bei.
-
Erstellt automatisch zwei neue Spalten: eine für frühere Spaltennamen und eine für die entsprechenden Werte.
-
Konvertiert breite Daten in ein langes Format.
Nutzungshinweise
-
Alle Spalten ohne Pivotierung müssen kompatible Datentypen haben.
-
Die Anzahl der Zeilen nimmt in der Regel zu, nachdem die Pivotierung aufgehoben wurde.
-
Zeigen Sie eine Vorschau der Änderungen in Echtzeit an, bevor Sie sie übernehmen.
