Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Visualisieren Sie AI/ML Modellergebnisse mit Flask und AWS Elastic Beanstalk
Chris Caudill und Durga Sury, Amazon Web Services
Zusammenfassung
Die Visualisierung der Ergebnisse von Diensten für künstliche Intelligenz und maschinelles Lernen (KI/ML) erfordert häufig komplexe API-Aufrufe, die von Ihren Entwicklern und Technikern angepasst werden müssen. Dies kann ein Nachteil sein, wenn Ihre Analysten schnell einen neuen Datensatz untersuchen möchten.
Sie können die Zugänglichkeit Ihrer Dienste verbessern und eine interaktivere Form der Datenanalyse bereitstellen, indem Sie eine webbasierte Benutzeroberfläche (UI) verwenden, über die Benutzer ihre eigenen Daten hochladen und die Modellergebnisse in einem Dashboard visualisieren können.
Dieses Muster verwendet Flask
Voraussetzungen und Einschränkungen
Voraussetzungen
Ein aktiver AWS-Konto.
AWS Command Line Interface (AWS CLI), auf Ihrem lokalen Computer installiert und konfiguriert. Weitere Informationen dazu finden Sie in der AWS CLI Dokumentation unter Grundlagen der Konfiguration. Sie können auch eine AWS Cloud9 integrierte Entwicklungsumgebung (IDE) verwenden. Weitere Informationen dazu finden Sie in der AWS Cloud9 Dokumentation unter Python-Tutorial für AWS Cloud9 und Vorschau laufender Anwendungen in der AWS Cloud9 IDE.
Hinweis: AWS Cloud9 ist für Neukunden nicht mehr verfügbar. Bestandskunden von AWS Cloud9 können den Service weiterhin wie gewohnt nutzen. Weitere Informationen
Ein Verständnis des Webanwendungs-Frameworks von Flask. Weitere Informationen zu Flask finden Sie im Schnellstart
in der Flask-Dokumentation. Python Version 3.6 oder höher, installiert und konfiguriert. Sie können Python installieren, indem Sie den Anweisungen unter Einrichten Ihrer Python-Entwicklungsumgebung in der AWS Elastic Beanstalk Dokumentation folgen.
Elastic Beanstalk Command Line Interface (EB CLI), installiert und konfiguriert. Weitere Informationen dazu finden Sie in der Elastic Beanstalk Beanstalk-Dokumentation unter Installieren der EB-CLI und Konfigurieren der EB-CLI.
Einschränkungen
Die Flask-Anwendung dieses Musters wurde für die Arbeit mit CSV-Dateien entwickelt, die eine einzige Textspalte verwenden und auf 200 Zeilen beschränkt sind. Der Anwendungscode kann an andere Dateitypen und Datenmengen angepasst werden.
Die Anwendung berücksichtigt keine Datenspeicherung und aggregiert weiterhin hochgeladene Benutzerdateien, bis sie manuell gelöscht werden. Sie können die Anwendung mit Amazon Simple Storage Service (Amazon S3) für persistenten Objektspeicher integrieren oder eine Datenbank wie Amazon DynamoDB für die serverlose Speicherung von Schlüsselwerten verwenden.
Die Anwendung berücksichtigt nur Dokumente in englischer Sprache. Sie können Amazon Comprehend jedoch verwenden, um die Hauptsprache eines Dokuments zu ermitteln. Weitere Informationen zu den unterstützten Sprachen für jede Aktion finden Sie in der API-Referenz in der Amazon Comprehend Comprehend-Dokumentation.
Architektur
Die Architektur der Flask-Anwendung
Flask ist ein leichtes Framework für die Entwicklung von Webanwendungen in Python. Es wurde entwickelt, um die leistungsstarke Datenverarbeitung von Python mit einer umfangreichen Weboberfläche zu kombinieren. Die Flask-Anwendung des Musters zeigt Ihnen, wie Sie eine Webanwendung erstellen, die es Benutzern ermöglicht, Daten hochzuladen, die Daten zur Inferenz an Amazon Comprehend zu senden und dann die Ergebnisse zu visualisieren. Die Anwendung hat die folgende Struktur:
static— Enthält alle statischen Dateien, die die Weboberfläche unterstützen (z. JavaScript B. CSS und Bilder)templates— Enthält alle HTML-Seiten der AnwendunguserData— Speichert hochgeladene Benutzerdatenapplication.py— Die Flask-Anwendungsdateicomprehend_helper.py— Funktionen zum Durchführen von API-Aufrufen an Amazon Comprehendconfig.py— Die Konfigurationsdatei der Anwendungrequirements.txt— Die von der Anwendung benötigten Python-Abhängigkeiten
Das application.py Skript enthält die Kernfunktionalität der Webanwendung, die aus vier Flask-Routen besteht. Das folgende Diagramm zeigt diese Flask-Routen.

/ist das Stammverzeichnis der Anwendung und leitet Benutzer auf dieupload.htmlSeite weiter (die imtemplatesVerzeichnis gespeichert ist)./saveFileist eine Route, die aufgerufen wird, nachdem ein Benutzer eine Datei hochgeladen hat. Diese Route empfängt einePOSTAnfrage über ein HTML-Formular, das die vom Benutzer hochgeladene Datei enthält. Die Datei wird imuserDataVerzeichnis gespeichert und die Route leitet Benutzer zur/dashboardRoute weiter./dashboardsendet Benutzer auf diedashboard.htmlSeite. Im HTML-Code dieser Seite wird der JavaScript Code ausgeführt, derstatic/js/core.jsDaten aus der/dataRoute liest und dann Visualisierungen für die Seite erstellt./dataist eine JSON-API, die die zu visualisierenden Daten im Dashboard präsentiert. Diese Route liest die vom Benutzer bereitgestellten Daten und verwendet die Funktionen, um die Benutzerdatencomprehend_helper.pyzur Stimmungsanalyse und Named Entity Recognition (NER) an Amazon Comprehend zu senden. Die Amazon Comprehend Comprehend-Antwort wird formatiert und als JSON-Objekt zurückgegeben.
Architektur der Bereitstellung
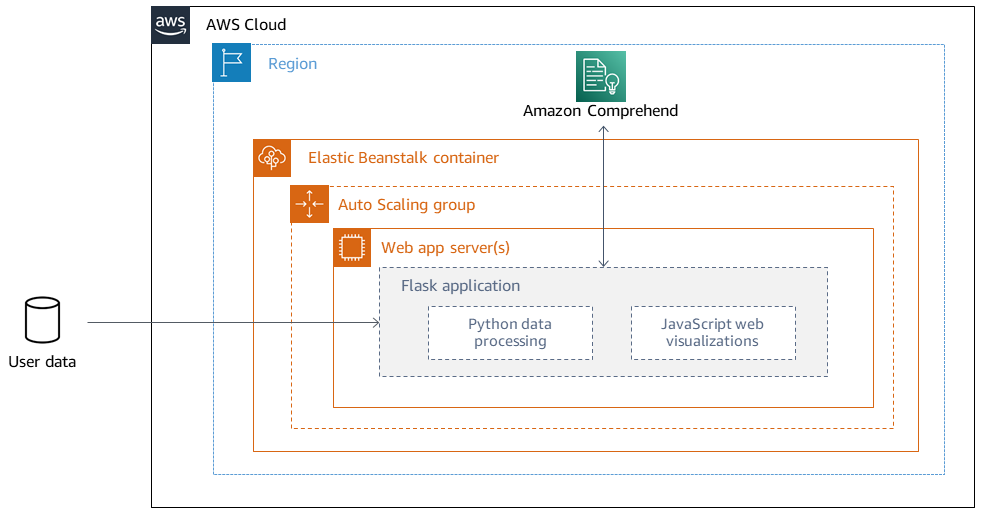
Weitere Informationen zu Designüberlegungen für Anwendungen, die mit Elastic Beanstalk auf dem bereitgestellt werden AWS Cloud, finden Sie in der AWS Elastic Beanstalk Dokumentation.
Technologie-Stack
Amazon Comprehend
Elastic Beanstalk
Flask
Automatisierung und Skalierung
Elastic Beanstalk Beanstalk-Bereitstellungen werden automatisch mit Load Balancern und Auto Scaling-Gruppen eingerichtet. Weitere Konfigurationsoptionen finden Sie unter Konfiguration von Elastic Beanstalk Beanstalk-Umgebungen in der Elastic Beanstalk Beanstalk-Dokumentation.
Tools
AWS Command Line Interface (AWS CLI) ist ein einheitliches Tool, das eine konsistente Schnittstelle für die Interaktion mit allen Teilen von AWS bietet.
Amazon Comprehend verwendet Natural Language Processing (NLP), um Erkenntnisse über den Inhalt von Dokumenten zu gewinnen, ohne dass eine spezielle Vorverarbeitung erforderlich ist.
AWS Elastic Beanstalkhilft Ihnen dabei, Anwendungen schnell bereitzustellen und zu verwalten, AWS Cloud ohne sich mit der Infrastruktur vertraut machen zu müssen, auf der diese Anwendungen ausgeführt werden.
Elastic Beanstalk CLI (EB CLI) ist eine Befehlszeilenschnittstelle AWS Elastic Beanstalk , die interaktive Befehle bereitstellt, um das Erstellen, Aktualisieren und Überwachen von Umgebungen aus einem lokalen Repository zu vereinfachen.
Das Flask-Framework
führt Datenverarbeitung und API-Aufrufe mit Python durch und bietet interaktive Webvisualisierung mit Plotly.
Code-Repository
Der Code für dieses Muster ist im GitHub Visualize AI/ML Model Results using Flask and AWS Elastic Beanstalk
Epen
| Aufgabe | Description | Erforderliche Fähigkeiten |
|---|---|---|
Klonen Sie das GitHub Repository. | Rufen Sie den Anwendungscode mithilfe von Flask und dem AWS Elastic Beanstalk Repository aus den GitHub AI/ML Visualize-Modellergebnissen
AnmerkungStellen Sie sicher, dass Sie Ihre SSH-Schlüssel mit konfigurieren. GitHub | Developer |
Installieren Sie die Python-Module. | Nachdem Sie das Repository geklont haben, wird ein neues lokales
| Python-Entwickler |
Testen Sie die Anwendung lokal. | Starten Sie den Flask-Server, indem Sie den folgenden Befehl ausführen:
Dies gibt Informationen über den laufenden Server zurück. Sie sollten auf die Anwendung zugreifen können, indem Sie einen Browser öffnen und http://localhost:5000 aufrufen AnmerkungWenn Sie die Anwendung in einer AWS Cloud9 IDE ausführen, müssen Sie den
Sie müssen diese Änderung vor der Bereitstellung rückgängig machen. | Python-Entwickler |
| Aufgabe | Description | Erforderliche Fähigkeiten |
|---|---|---|
Starten Sie die Elastic Beanstalk Beanstalk-Anwendung. | Um Ihr Projekt als Elastic Beanstalk Beanstalk-Anwendung zu starten, führen Sie den folgenden Befehl im Stammverzeichnis Ihrer Anwendung aus:
Wichtig
Führen Sie den | Architekt, Entwickler |
Stellen Sie die Elastic Beanstalk Beanstalk-Umgebung bereit. | Führen Sie den folgenden Befehl im Stammverzeichnis der Anwendung aus:
Anmerkung
| Architekt, Entwickler |
Autorisieren Sie Ihre Bereitstellung für die Verwendung von Amazon Comprehend. | Obwohl Ihre Anwendung möglicherweise erfolgreich bereitgestellt wurde, sollten Sie Ihrer Bereitstellung auch Zugriff auf Amazon Comprehend gewähren. Fügen Sie die
Wichtig
| Entwickler, Sicherheitsarchitekt |
Besuchen Sie Ihre bereitgestellte Anwendung. | Nachdem Ihre Anwendung erfolgreich bereitgestellt wurde, können Sie sie aufrufen, indem Sie den Sie können den | Architekt, Entwickler |
| Aufgabe | Description | Erforderliche Fähigkeiten |
|---|---|---|
Autorisieren Sie Elastic Beanstalk, auf das neue Modell zuzugreifen. | Stellen Sie sicher, dass Elastic Beanstalk über die erforderlichen Zugriffsberechtigungen für Ihren neuen Modellendpunkt verfügt. Wenn Sie beispielsweise einen Amazon SageMaker AI-Endpunkt verwenden, benötigt Ihre Bereitstellung die Erlaubnis, den Endpunkt aufzurufen. Weitere Informationen dazu finden Sie InvokeEndpointin der Amazon SageMaker AI-Dokumentation. | Entwickler, Sicherheitsarchitekt |
Senden Sie die Benutzerdaten an ein neues Modell. | Um das zugrunde liegende ML-Modell in dieser Anwendung zu ändern, müssen Sie die folgenden Dateien ändern:
| Datenwissenschaftler |
Aktualisieren Sie die Dashboard-Visualisierungen. | In der Regel bedeutet die Integration eines neuen ML-Modells, dass die Visualisierungen aktualisiert werden müssen, um die neuen Ergebnisse widerzuspiegeln. Diese Änderungen werden in den folgenden Dateien vorgenommen:
| Web-Entwickler |
| Aufgabe | Description | Erforderliche Fähigkeiten |
|---|---|---|
Aktualisieren Sie die Anforderungsdatei Ihrer Bewerbung. | Bevor Sie Änderungen an Elastic Beanstalk senden, aktualisieren Sie die
| Python-Entwickler |
Stellen Sie die Elastic Beanstalk Beanstalk-Umgebung erneut bereit. | Um sicherzustellen, dass Ihre Anwendungsänderungen in Ihrem Elastic Beanstalk-Deployment berücksichtigt werden, navigieren Sie zum Stammverzeichnis Ihrer Anwendung und führen Sie den folgenden Befehl aus:
Dadurch wird die neueste Version des Anwendungscodes an Ihr vorhandenes Elastic Beanstalk-Deployment gesendet. | Systemadministrator, Architekt |
Fehlerbehebung
| Problem | Lösung |
|---|---|
| Wenn dieser Fehler bei der Ausführung auftritt |
| Dieser Fehler tritt in Bereitstellungsprotokollen auf, weil Elastic Beanstalk erwartet, dass der Flask-Code benannt wird.
Stellen Sie sicher, dass Sie es Sie können auch Gunicorn und ein Profil nutzen. Weitere Informationen zu diesem Ansatz finden Sie in der Dokumentation unter Konfiguration des WSGI-Servers mit einer Profildatei. AWS Elastic Beanstalk |
| Elastic Beanstalk erwartet, dass die Variable, die Ihre Flask-Anwendung repräsentiert, benannt wird.
|
| Verwenden Sie die EB-CLI, um anzugeben, welches key pair verwendet werden soll, oder um ein key pair für die Amazon EC2 EC2-Instances Ihrer Bereitstellung zu erstellen. Um den Fehler zu beheben, führen Sie den
Antworten Sie mit |
Ich habe meinen Code aktualisiert und erneut bereitgestellt, aber meine Bereitstellung spiegelt meine Änderungen nicht wider. | Wenn du ein Git-Repository mit deiner Bereitstellung verwendest, stelle sicher, dass du deine Änderungen hinzufügst und festschreibst, bevor du sie erneut bereitstellst. |
Sie sehen sich die Flask-Anwendung von einer AWS Cloud9 IDE aus in der Vorschau an und stoßen auf Fehler. | Weitere Informationen dazu finden Sie in der Dokumentation unter Vorschau laufender Anwendungen in der AWS Cloud9 IDE. AWS Cloud9 |
Zugehörige Ressourcen
Zusätzliche Informationen
Verarbeitung natürlicher Sprache mit Amazon Comprehend
Wenn Sie sich für Amazon Comprehend entscheiden, können Sie benutzerdefinierte Entitäten in einzelnen Textdokumenten erkennen, indem Sie Echtzeitanalysen oder asynchrone Batch-Jobs ausführen. Mit Amazon Comprehend können Sie auch benutzerdefinierte Modelle zur Erkennung von Entitäten und zur Textklassifizierung trainieren, die in Echtzeit verwendet werden können, indem Sie einen Endpunkt erstellen.
Dieses Muster verwendet asynchrone Batch-Jobs, um Stimmungen und Entitäten aus einer Eingabedatei zu erkennen, die mehrere Dokumente enthält. Die in diesem Muster bereitgestellte Beispielanwendung ist so konzipiert, dass Benutzer eine CSV-Datei hochladen können, die eine einzelne Spalte mit einem Textdokument pro Zeile enthält. Die comprehend_helper.py Datei im GitHub Visualize AI/ML Model Results using Flask and AWS Elastic Beanstalk
BatchDetectEntities
Amazon Comprehend untersucht den Text eines Stapels von Dokumenten auf benannte Entitäten und gibt die erkannte Entität, den Standort, den Entitätstyp und eine Bewertung zurück, die das Vertrauensniveau von Amazon Comprehend angibt. In einem API-Aufruf können maximal 25 Dokumente gesendet werden, wobei jedes Dokument kleiner als 5.000 Byte ist. Sie können die Ergebnisse filtern, sodass nur bestimmte Entitäten angezeigt werden, die auf dem Anwendungsfall basieren. Sie könnten beispielsweise den ‘quantity’ Entitätstyp überspringen und einen Schwellenwert für die erkannte Entität festlegen (z. B. 0,75). Wir empfehlen Ihnen, die Ergebnisse für Ihren speziellen Anwendungsfall zu untersuchen, bevor Sie einen Schwellenwert auswählen. Weitere Informationen dazu finden Sie BatchDetectEntitiesin der Amazon Comprehend Comprehend-Dokumentation.
BatchDetectSentiment
Amazon Comprehend prüft einen Stapel eingehender Dokumente und gibt die vorherrschende Stimmung für jedes Dokument zurück (POSITIVE,NEUTRAL, MIXED oder). NEGATIVE In einem API-Aufruf können maximal 25 Dokumente gesendet werden, wobei jedes Dokument kleiner als 5.000 Byte ist. Die Stimmungsanalyse ist unkompliziert, und Sie wählen die Stimmung mit der höchsten Punktzahl aus, die in den Endergebnissen angezeigt werden soll. Weitere Informationen dazu finden Sie BatchDetectSentimentin der Amazon Comprehend Comprehend-Dokumentation.
Handhabung der Flask-Konfiguration
Flask-Server verwenden eine Reihe von Konfigurationsvariablen
In diesem Muster wird die Konfiguration definiert config.py und darin vererbtapplication.py.
config.pyenthält die Konfigurationsvariablen, die beim Start der Anwendung eingerichtet werden. In dieser Anwendung ist eineDEBUGVariable definiert, die der Anwendung mitteilt, den Server im Debug-Modusauszuführen. Anmerkung
Der Debug-Modus sollte nicht verwendet werden, wenn eine Anwendung in einer Produktionsumgebung ausgeführt wird.
UPLOAD_FOLDERist eine benutzerdefinierte Variable, die so definiert ist, dass sie später in der Anwendung referenziert wird und sie darüber informiert, wo hochgeladene Benutzerdaten gespeichert werden sollen.application.pyinitiiert die Flask-Anwendung und erbt die in definierten Konfigurationseinstellungen.config.pyDies wird durch den folgenden Code ausgeführt:
application = Flask(__name__) application.config.from_pyfile('config.py')
