Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Optimieren Sie mithilfe von SageMaker KI und Hydra Workflows für maschinelles Lernen — von der lokalen Entwicklung bis hin zu skalierbaren Experimenten
David Sauerwein, Marco Geiger und Julian Ferdinand Grueber, Amazon Web Services
Zusammenfassung
Dieses Muster bietet einen einheitlichen Ansatz für die Konfiguration und Ausführung von Algorithmen für maschinelles Lernen (ML) von lokalen Tests bis hin zur Produktion auf Amazon SageMaker AI. ML-Algorithmen stehen im Mittelpunkt dieses Musters, aber sein Ansatz erstreckt sich auch auf Feature-Engineering, Inferenz und ganze ML-Pipelines. Dieses Muster veranschaulicht anhand eines Beispielanwendungsfalls den Übergang von der lokalen Skriptentwicklung zu SageMaker KI-Schulungsaufgaben.
Ein typischer ML-Workflow besteht darin, Lösungen auf einem lokalen Computer zu entwickeln und zu testen, groß angelegte Experimente (z. B. mit unterschiedlichen Parametern) in der Cloud durchzuführen und die genehmigte Lösung in der Cloud bereitzustellen. Anschließend muss die bereitgestellte Lösung überwacht und gewartet werden. Ohne einen einheitlichen Ansatz für diesen Workflow müssen Entwickler ihren Code häufig in jeder Phase neu gestalten. Wenn die Lösung von einer Vielzahl von Parametern abhängt, die sich in jeder Phase dieses Workflows ändern können, kann es immer schwieriger werden, organisiert und konsistent zu bleiben.
Dieses Muster adressiert diese Herausforderungen. Erstens macht es Code-Refactoring zwischen Umgebungen überflüssig, indem ein einheitlicher Workflow bereitgestellt wird, der konsistent bleibt, unabhängig davon, ob er auf lokalen Computern, in Containern oder auf SageMaker KI ausgeführt wird. Zweitens vereinfacht es die Parameterverwaltung durch das Konfigurationssystem von Hydra, bei dem Parameter in separaten Konfigurationsdateien definiert werden, die einfach geändert und kombiniert werden können, wobei die Konfiguration jedes Laufs automatisch protokolliert wird. Weitere Informationen darüber, wie dieses Muster diese Herausforderungen bewältigt, finden Sie unter Zusätzliche Informationen.
Voraussetzungen und Einschränkungen
Voraussetzungen
Ein aktiver AWS-Konto
Eine AWS Identity and Access Management (IAM-) Benutzerrolle für die Bereitstellung und den Start der SageMaker KI-Schulungsjobs
AWS Command Line Interface (AWS CLI) Version 2.0 oder höher installiert und konfiguriert
Poetry
Version 1.8 oder höher, aber früher als 2.0, installiert Docker
ist installiert
Einschränkungen
Der Code zielt derzeit nur auf SageMaker KI-Schulungsjobs ab. Es ist einfach, ihn auf die Verarbeitung von Jobs und ganzen SageMaker KI-Pipelines auszudehnen.
Für ein vollständig produktionsfähiges SageMaker KI-Setup müssen zusätzliche Details vorhanden sein. Beispiele könnten benutzerdefinierte AWS Key Management Service (AWS KMS) Schlüssel für Rechen- und Speicheranwendungen oder Netzwerkkonfigurationen sein. Sie können diese zusätzlichen Optionen auch konfigurieren, indem Sie Hydra in einem speziellen Unterordner des
configOrdners verwenden.Einige AWS-Services sind nicht in allen verfügbar. AWS-Regionen Informationen zur Verfügbarkeit in den einzelnen Regionen finden Sie unter AWS Dienste nach Regionen
. Informationen zu bestimmten Endpunkten finden Sie unter Dienstendpunkte und Kontingente. Wählen Sie dort den Link für den Dienst aus.
Architektur
Das folgende Diagramm zeigt die Architektur der Lösung.
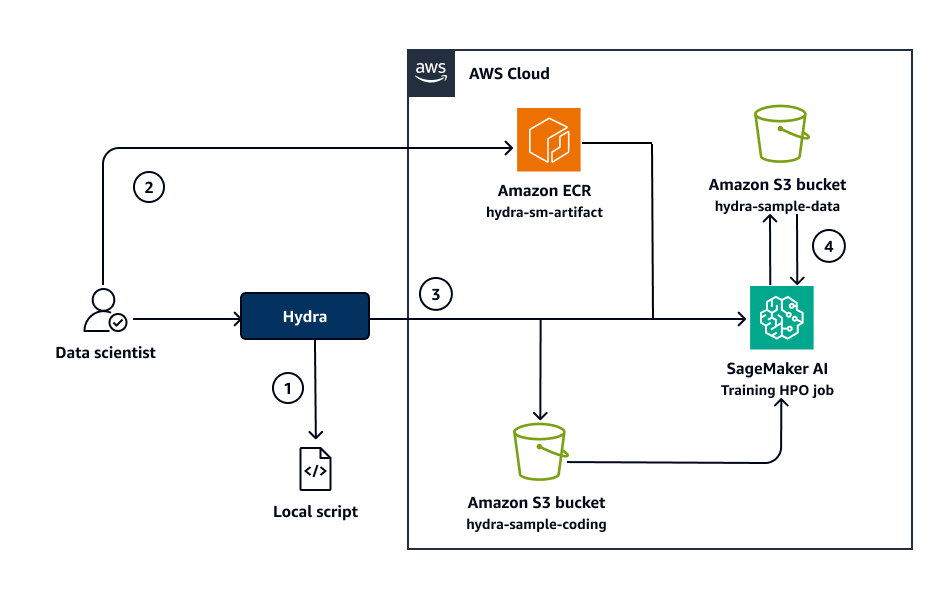
Das Diagramm zeigt den folgenden Workflow:
Der Datenwissenschaftler kann den Algorithmus in kleinem Maßstab in einer lokalen Umgebung wiederholen, Parameter anpassen und das Trainingsskript schnell testen, ohne dass Docker oder KI erforderlich sind. SageMaker (Weitere Informationen finden Sie unter der Aufgabe „Lokal für schnelle Tests ausführen“ in Epics.)
Sobald der Datenwissenschaftler mit dem Algorithmus zufrieden ist, erstellt er das Docker-Image und überträgt es in das angegebene Amazon Elastic Container Registry (Amazon ECR) -Repository.
hydra-sm-artifact(Weitere Informationen finden Sie unter „Workflows auf SageMaker KI ausführen“ in Epics.)Der Datenwissenschaftler initiiert entweder SageMaker KI-Trainingsjobs oder Hyperparameter-Optimierungsjobs (HPO) mithilfe von Python-Skripten. Für reguläre Trainingsjobs wird die angepasste Konfiguration in den Amazon Simple Storage Service (Amazon S3) Bucket mit dem Namen geschrieben
hydra-sample-config. Für HPO-Jobs wird der Standardkonfigurationssatz angewendet, der sich imconfigOrdner befindet.Der SageMaker KI-Trainingsjob ruft das Docker-Image ab, liest die Eingabedaten aus dem Amazon S3 S3-Bucket
hydra-sample-dataund ruft entweder die Konfiguration aus dem Amazon S3 S3-Bucket abhydra-sample-configoder verwendet die Standardkonfiguration. Nach dem Training speichert der Job die Ausgabedaten im Amazon S3 S3-Buckethydra-sample-data.
Automatisierung und Skalierung
Für automatisierte Schulungen, Umschulungen oder Inferenzen können Sie den AWS CLI Code in Dienste wie AWS LambdaAWS CodePipeline, oder Amazon integrieren. EventBridge
Die Skalierung kann erreicht werden, indem Konfigurationen für die Instance-Größen geändert oder Konfigurationen für verteilte Schulungen hinzugefügt werden.
Tools
AWS-Services
AWS CloudFormationhilft Ihnen dabei, AWS Ressourcen einzurichten, sie schnell und konsistent bereitzustellen und sie während ihres gesamten Lebenszyklus über AWS-Konten und zu verwalten AWS-Regionen.
AWS Command Line Interface (AWS CLI) ist ein Open-Source-Tool, mit dem Sie AWS-Services über Befehle in Ihrer Befehlszeilen-Shell interagieren können. Für dieses Muster AWS CLI ist das sowohl für die anfängliche Konfiguration als auch für das Testen von Ressourcen nützlich.
Amazon Elastic Container Registry (Amazon ECR) ist ein verwalteter Container-Image-Registry-Service, der sicher, skalierbar und zuverlässig ist.
Amazon SageMaker AI ist ein verwalteter Service für maschinelles Lernen (ML), mit dem Sie ML-Modelle erstellen und trainieren und diese dann in einer produktionsbereiten, gehosteten Umgebung bereitstellen können. SageMaker AI Training ist ein vollständig verwalteter ML-Service innerhalb von SageMaker KI, der das Training von ML-Modellen in großem Maßstab ermöglicht. Das Tool kann die Rechenanforderungen von Trainingsmodellen effizient bewältigen und nutzt dabei die integrierte Skalierbarkeit und Integration mit anderen AWS-Services Modellen. SageMaker AI Training unterstützt auch benutzerdefinierte Algorithmen und Container und ist somit flexibel für eine Vielzahl von ML-Workflows.
Amazon Simple Storage Service (Amazon S3) ist ein cloudbasierter Objektspeicherservice, der Sie beim Speichern, Schützen und Abrufen beliebiger Datenmengen unterstützt.
Andere Tools
Docker
ist eine Reihe von Platform-as-a-Service (PaaS) -Produkten, die Virtualisierung auf Betriebssystemebene nutzen, um Software in Containern bereitzustellen. Es wurde in diesem Muster verwendet, um konsistente Umgebungen in verschiedenen Phasen sicherzustellen, von der Entwicklung bis zur Bereitstellung, und um Abhängigkeiten und Code zuverlässig zu verpacken. Die Containerisierung von Docker ermöglichte eine einfache Skalierung und Versionskontrolle im gesamten Workflow. Hydra ist ein
Konfigurationsmanagement-Tool, das Flexibilität bei der Handhabung mehrerer Konfigurationen und dynamisches Ressourcenmanagement bietet. Es ist entscheidend für die Verwaltung von Umgebungskonfigurationen und ermöglicht eine nahtlose Bereitstellung in verschiedenen Umgebungen. Weitere Informationen zu Hydra finden Sie unter Zusätzliche Informationen. Python
ist eine Allzweck-Computerprogrammiersprache. Python wurde verwendet, um den ML-Code und den Deployment-Workflow zu schreiben. Poetry
ist ein Tool für Abhängigkeitsmanagement und Paketierung in Python.
Code-Repository
Der Code für dieses Muster ist im Repository GitHub configuring-sagemaker-training-jobs-with-hydra
Best Practices
Wählen Sie eine IAM-Rolle für die Bereitstellung und den Start der SageMaker KI-Schulungsjobs, die dem Prinzip der geringsten Rechte folgt, und gewähren Sie die Mindestberechtigungen, die zur Ausführung einer Aufgabe erforderlich sind. Weitere Informationen finden Sie in der IAM-Dokumentation unter Gewährung der geringsten Rechte und bewährte Methoden zur Sicherheit.
Verwenden Sie temporäre Anmeldeinformationen, um auf die IAM-Rolle im Terminal zuzugreifen.
Epen
| Aufgabe | Description | Erforderliche Fähigkeiten |
|---|---|---|
Erstellen und aktivieren Sie die virtuelle Umgebung. | Um die virtuelle Umgebung zu erstellen und zu aktivieren, führen Sie die folgenden Befehle im Stammverzeichnis des Repositorys aus:
| Allgemeines AWS |
Stellen Sie die Infrastruktur bereit. | Führen Sie den folgenden Befehl aus CloudFormation, um die Infrastruktur mithilfe von bereitzustellen:
| General AWS, DevOps Ingenieur |
Laden Sie die Beispieldaten herunter. | Führen Sie den folgenden Befehl aus, um die Eingabedaten von openml
| Allgemeines AWS |
Für schnelle Tests lokal ausführen. | Führen Sie den folgenden Befehl aus, um den Trainingscode lokal zum Testen auszuführen:
Die Protokolle aller Ausführungen werden nach Ausführungszeit sortiert in einem Ordner mit dem Namen Mithilfe der | Datenwissenschaftler |
| Aufgabe | Description | Erforderliche Fähigkeiten |
|---|---|---|
Legen Sie die Umgebungsvariablen fest. | Um Ihren Job auf SageMaker KI auszuführen, legen Sie die folgenden Umgebungsvariablen fest und geben Sie dabei Ihre ID AWS-Region und Ihre AWS-Konto ID an:
| Allgemeines AWS |
Erstellen Sie ein Docker-Image und übertragen Sie es. | Führen Sie den folgenden Befehl aus, um das Docker-Image zu erstellen und in das Amazon ECR-Repository zu übertragen:
Bei dieser Aufgabe wird davon ausgegangen, dass Sie in Ihrer Umgebung über gültige Anmeldeinformationen verfügen. Das Docker-Image wird in das Amazon ECR-Repository übertragen, das in der vorherigen Aufgabe in der Umgebungsvariablen angegeben wurde, und wird verwendet, um den SageMaker AI-Container zu aktivieren, in dem der Trainingsjob ausgeführt wird. | ML-Ingenieur, General AWS |
Kopieren Sie die Eingabedaten nach Amazon S3. | Der SageMaker KI-Trainingsjob muss die Eingabedaten aufnehmen. Führen Sie den folgenden Befehl aus, um die Eingabedaten in den Amazon S3 S3-Bucket für Daten zu kopieren:
| Dateningenieur, General AWS |
Reichen Sie SageMaker KI-Schulungsjobs ein. | Um die Ausführung Ihrer Skripts zu vereinfachen, geben Sie in der
| Allgemeiner AWS, ML-Ingenieur, Datenwissenschaftler |
Führen Sie das SageMaker KI-Hyperparameter-Tuning durch. | Das Ausführen des SageMaker KI-Hyperparameter-Tunings ähnelt dem Einreichen eines SageMaker AII-Trainingsjobs. Das Ausführungsskript unterscheidet sich jedoch in einigen wichtigen Punkten, wie Sie in der Datei start_sagemaker_hpo_job.py Führen Sie die folgenden Befehle aus, um den Job zur Hyperparameter-Optimierung (HPO) zu starten:
| Datenwissenschaftler |
Fehlerbehebung
| Problem | Lösung |
|---|---|
Abgelaufenes Token | Exportieren Sie neue Anmeldeinformationen AWS . |
Fehlende IAM-Berechtigungen | Stellen Sie sicher, dass Sie die Anmeldeinformationen einer IAM-Rolle exportieren, die über alle erforderlichen IAM-Berechtigungen verfügt, um die CloudFormation Vorlage bereitzustellen und die SageMaker KI-Schulungsjobs zu starten. |
Zugehörige Ressourcen
Trainieren Sie ein Modell mit Amazon SageMaker AI (AWS Dokumentation)
Zusätzliche Informationen
Dieses Muster befasst sich mit den folgenden Herausforderungen:
Konsistenz von der lokalen Entwicklung bis zur Bereitstellung im großen Maßstab — Mit diesem Muster können Entwickler denselben Workflow verwenden, unabhängig davon, ob sie lokale Python-Skripte verwenden, lokale Docker-Container ausführen, große SageMaker KI-Experimente durchführen oder in der Produktion auf SageMaker KI bereitstellen. Diese Konsistenz ist aus den folgenden Gründen wichtig:
Schnellere Iteration — Sie ermöglicht schnelles, lokales Experimentieren, ohne dass größere Anpassungen bei der Skalierung erforderlich sind.
Kein Refactoring — Der Übergang zu größeren Experimenten mit SageMaker KI ist nahtlos und erfordert keine Überarbeitung des bestehenden Setups.
Kontinuierliche Verbesserung — Die Entwicklung neuer Funktionen und die kontinuierliche Verbesserung des Algorithmus sind unkompliziert, da der Code in allen Umgebungen gleich bleibt.
Konfigurationsmanagement — Dieses Muster nutzt Hydra, ein
Parameter werden getrennt vom Code in Konfigurationsdateien definiert.
Verschiedene Parametersätze können einfach ausgetauscht oder kombiniert werden.
Die Nachverfolgung von Experimenten wird vereinfacht, da die Konfiguration jedes Durchlaufs automatisch protokolliert wird.
Cloud-Experimente können dieselbe Konfigurationsstruktur wie lokale Läufe verwenden, wodurch Konsistenz gewährleistet wird.
Mit Hydra können Sie die Konfiguration effektiv verwalten und die folgenden Funktionen aktivieren:
Konfigurationen aufteilen — Teilen Sie Ihre Projektkonfigurationen in kleinere, überschaubare Teile auf, die unabhängig voneinander geändert werden können. Dieser Ansatz erleichtert die Bearbeitung komplexer Projekte.
Einfache Anpassung der Standardeinstellungen — Ändern Sie Ihre Basiskonfigurationen schnell, sodass Sie neue Ideen leichter testen können.
CLI-Eingaben und Konfigurationsdateien aufeinander abstimmen — Kombinieren Sie Befehlszeileneingaben problemlos mit Ihren Konfigurationsdateien. Dieser Ansatz reduziert Unordnung und Verwirrung und macht Ihr Projekt im Laufe der Zeit überschaubarer.
