Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Optimieren Sie die Leistung Ihrer modernisierten AWS Blu Age-Anwendung
Vishal Jaswani, Manish Roy und Himanshu Sah, Amazon Web Services
Zusammenfassung
Mainframe-Anwendungen, die mit AWS Blu Age modernisiert wurden, erfordern Funktions- und Leistungsgleichwertigkeitstests, bevor sie in der Produktion eingesetzt werden. Bei Leistungstests können modernisierte Anwendungen langsamer ausgeführt werden als ältere Systeme, insbesondere bei komplexen Batch-Jobs. Dieser Unterschied besteht darin, dass Mainframe-Anwendungen monolithisch sind, wohingegen moderne Anwendungen mehrstufige Architekturen verwenden. Dieses Muster stellt Optimierungstechniken zur Behebung dieser Leistungslücken für Anwendungen vor, die mithilfe von automatisiertem Refactoring mit Blu Age modernisiert wurden. AWS
Das Muster verwendet das AWS Blu Age-Modernisierungsframework mit systemeigenen Java- und Datenbankoptimierungsfunktionen, um Leistungsengpässe zu identifizieren und zu beheben. Das Muster beschreibt, wie Sie mithilfe von Profilerstellung und Überwachung Leistungsprobleme anhand von Kennzahlen wie SQL-Ausführungszeiten, Speicherauslastung und Mustern identifizieren können. I/O Anschließend wird erklärt, wie Sie gezielte Optimierungen anwenden können, darunter die Umstrukturierung von Datenbankabfragen, das Zwischenspeichern und die Verfeinerung der Geschäftslogik.
Die Verbesserungen der Batch-Verarbeitungszeiten und der Auslastung der Systemressourcen tragen dazu bei, dass Sie das Mainframe-Leistungsniveau Ihrer modernisierten Systeme erreichen. Dieser Ansatz gewährleistet die funktionale Gleichwertigkeit beim Übergang zu modernen Cloud-basierten Architekturen.
Voraussetzungen und Einschränkungen
Voraussetzungen
Eine modernisierte AWS Anwendung von Blue Age
Administratorrechte zur Installation des Datenbankclients und der Profilerstellungstools
AWS Blu Age Level 3-Zertifizierung
Kenntnisse des AWS Blu Age-Frameworks, der generierten Codestruktur und der Java-Programmierung auf mittlerem Niveau
Einschränkungen
Die folgenden Optimierungsmöglichkeiten und Merkmale fallen nicht in den Geltungsbereich dieses Musters:
Optimierung der Netzwerklatenz zwischen Anwendungsebenen
Optimierungen auf Infrastrukturebene durch Amazon Elastic Compute Cloud (Amazon EC2) Instance-Typen und Speicheroptimierung
Gleichzeitige Benutzerlasttests und Stresstests
Produktversionen
JProfiler Version 13.0 oder höher (wir empfehlen die neueste Version)
pgAdmin Version 8.14 oder höher
Architektur
Dieses Muster richtet mithilfe von Tools wie pgAdmin eine Profilierungsumgebung für eine AWS Blu Age-Anwendung ein. JProfiler Es unterstützt die Optimierung mit dem von AWS Blu SQLExecution Age APIs bereitgestellten DAOManager and Builder.
Der Rest dieses Abschnitts enthält detaillierte Informationen und Beispiele zur Identifizierung von Performance-Hotspots und Optimierungsstrategien für Ihre modernisierten Anwendungen. Die Schritte im Abschnitt Epics beziehen sich auf diese Informationen, um weitere Anleitungen zu erhalten.
Identifizierung von Leistungs-Hotspots in modernisierten Mainframe-Anwendungen
In modernisierten Mainframe-Anwendungen sind Performance-Hotspots bestimmte Bereiche im Code, die zu erheblichen Verlangsamungen oder Ineffizienzen führen. Diese Hotspots werden häufig durch die architektonischen Unterschiede zwischen Mainframe- und modernisierten Anwendungen verursacht. Um diese Leistungsengpässe zu identifizieren und die Leistung Ihrer modernisierten Anwendung zu optimieren, können Sie drei Techniken verwenden: SQL-Protokollierung, Abfrageplan und Analyse. EXPLAIN JProfiler
Technik zur Identifizierung von Hotspots: SQL-Protokollierung
Moderne Java-Anwendungen, einschließlich solcher, die mithilfe von AWS Blu Age modernisiert wurden, verfügen über integrierte Funktionen zum Protokollieren von SQL-Abfragen. Sie können spezielle Logger in AWS Blu Age-Projekten aktivieren, um die von Ihrer Anwendung ausgeführten SQL-Anweisungen zu verfolgen und zu analysieren. Diese Technik ist besonders nützlich, um ineffiziente Datenbankzugriffsmuster zu identifizieren, wie z. B. zu viele einzelne Abfragen oder schlecht strukturierte Datenbankaufrufe, die durch Batching oder Verfeinerung von Abfragen optimiert werden könnten.
Um die SQL-Protokollierung in Ihrer modernisierten AWS Blu Age-Anwendung zu implementieren, setzen Sie die Protokollebene auf DEBUG für SQL-Anweisungen in der application.properties Datei, um Details zur Abfrageausführung zu erfassen:
level.org.springframework.beans.factory.support.DefaultListableBeanFactory : WARN level.com.netfective.bluage.gapwalk.runtime.sort.internal: WARN level.org.springframework.jdbc.core.StatementCreatorUtils: DEBUG level.com.netfective.bluage.gapwalk.rt.blu4iv.dao: DEBUG level.com.fiserv.signature: DEBUG level.com.netfective.bluage.gapwalk.database.support.central: DEBUG level.com.netfective.bluage.gapwalk.rt.db.configuration.DatabaseConfiguration: DEBUG level.com.netfective.bluage.gapwalk.rt.db.DatabaseInteractionLoggerUtils: DEBUG level.com.netfective.bluage.gapwalk.database.support.AbstractDatabaseSupport: DEBUG level.com.netfective.bluage.gapwalk.rt: DEBUG
Überwachen Sie Abfragen mit hoher Frequenz und langsamer Leistung, indem Sie die protokollierten Daten verwenden, um Optimierungsziele zu identifizieren. Konzentrieren Sie sich auf Abfragen innerhalb von Batch-Prozessen, da diese in der Regel die größte Auswirkung auf die Leistung haben.
Technik zur Identifizierung von Hotspots: EXPLAIN-Plan abfragen
Diese Methode nutzt die Funktionen zur Abfrageplanung relationaler Datenbankmanagementsysteme. Sie können Befehle wie EXPLAIN in PostgreSQL oder MySQL oder EXPLAIN PLAN in Oracle verwenden, um zu untersuchen, wie Ihre Datenbank eine bestimmte Abfrage ausführen will. Die Ausgabe dieser Befehle bietet wertvolle Einblicke in die Strategie zur Abfrageausführung, einschließlich der Frage, ob Indizes verwendet oder vollständige Tabellenscans durchgeführt werden. Diese Informationen sind entscheidend für die Optimierung der Abfrageleistung, insbesondere in Fällen, in denen eine ordnungsgemäße Indizierung die Ausführungszeit erheblich reduzieren kann.
Extrahieren Sie die sich am häufigsten wiederholenden SQL-Abfragen aus den Anwendungsprotokollen und analysieren Sie den Ausführungspfad langsamer Abfragen mithilfe des für Ihre Datenbank spezifischen EXPLAIN Befehls. Hier ist ein Beispiel für eine PostgreSQL-Datenbank.
Abfrage:
SELECT * FROM tenk1 WHERE unique1 < 100;
EXPLAINBefehl:
EXPLAIN SELECT * FROM tenk1 where unique1 < 100;
Ausgabe:
Bitmap Heap Scan on tenk1 (cost=5.06..224.98 rows=100 width=244) Recheck Cond: (unique1 < 100) -> Bitmap Index Scan on tenk1_unique1 (cost=0.00..5.04 rows=100 width=0) Index Cond: (unique1 < 100)
Sie können die EXPLAIN Ausgabe wie folgt interpretieren:
Lesen Sie den
EXPLAINPlan von den innersten bis zu den äußersten Operationen (von unten nach oben).Suchen Sie nach Schlüsselbegriffen.
Seq ScanZeigt beispielsweise einen vollständigen Tabellenscan an undIndex Scanzeigt die Indexnutzung an.Überprüfen Sie die Kostenwerte: Die erste Zahl steht für die Startkosten und die zweite Zahl für die Gesamtkosten.
Sehen Sie sich den
rowsWert für die geschätzte Anzahl von Ausgabezeilen an.
In diesem Beispiel verwendet die Abfrage-Engine einen Indexscan, um die passenden Zeilen zu finden, und ruft dann nur diese Zeilen ab (Bitmap Heap Scan). Dies ist trotz der höheren Kosten für den Zugriff auf einzelne Zeilen effizienter als das Scannen der gesamten Tabelle.
Tabellenscanvorgänge in der Ausgabe eines EXPLAIN Plans deuten auf einen fehlenden Index hin. Die Optimierung erfordert die Erstellung eines geeigneten Indexes.
Technik zur Identifizierung von Hotspots: Analyse JProfiler
JProfiler ist ein umfassendes Java-Profiling-Tool, mit dem Sie Leistungsengpässe beheben können, indem es langsame Datenbankaufrufe und CPU-intensive Aufrufe identifiziert. Dieses Tool ist besonders effektiv bei der Identifizierung langsamer SQL-Abfragen und ineffizienter Speichernutzung.
Beispielanalyse für eine Abfrage:
select evt. com.netfective.bluage.gapwalk.rt.blu4iv.dao.Blu4ivTableManager.queryNonTrasactional
Die Ansicht „ JProfiler Hot Spots“ enthält die folgenden Informationen:
Spalte „Zeit“
Zeigt die gesamte Ausführungsdauer an (z. B. 329 Sekunden)
Zeigt den Prozentsatz der gesamten Anwendungszeit an (z. B. 58,7%)
Hilft bei der Identifizierung der zeitaufwändigsten Vorgänge
Spalte „Durchschnittliche Zeit“
Zeigt die Dauer pro Ausführung an (z. B. 2.692 Mikrosekunden)
Zeigt die Leistung des einzelnen Vorgangs an
Hilft dabei, langsame Einzelvorgänge zu erkennen
Spalte „Ereignisse“
Zeigt die Anzahl der Ausführungen an (z. B. 122.387 Mal)
Zeigt die Betriebsfrequenz an
Hilft bei der Identifizierung häufig aufgerufener Methoden
Für die Beispielergebnisse:
Hohe Frequenz: 122.387 Ausführungen weisen auf Optimierungspotenzial hin
Bedenken hinsichtlich der Leistung: 2.692 Mikrosekunden für die durchschnittliche Zeit deuten auf Ineffizienz hin
Kritische Auswirkung: 58,7% der Gesamtzeit deuten auf einen großen Engpass hin
JProfiler kann das Laufzeitverhalten Ihrer Anwendung analysieren, um Hotspots aufzudecken, die durch statische Codeanalyse oder SQL-Protokollierung möglicherweise nicht erkennbar sind. Diese Kennzahlen helfen Ihnen dabei, die Abläufe zu identifizieren, die optimiert werden müssen, und die Optimierungsstrategie zu bestimmen, die am effektivsten wäre. Weitere Informationen zu den JProfiler Funktionen finden Sie in der JProfiler Dokumentation
Wenn Sie diese drei Techniken (SQL-Protokollierung, EXPLAIN Abfrageplan und JProfiler) zusammen verwenden, können Sie sich einen ganzheitlichen Überblick über die Leistungsmerkmale Ihrer Anwendung verschaffen. Indem Sie die kritischsten Performance-Hotspots identifizieren und beheben, können Sie die Leistungslücke zwischen Ihrer ursprünglichen Mainframe-Anwendung und Ihrem modernisierten cloudbasierten System schließen.
Nachdem Sie die Performance-Hotspots Ihrer Anwendung identifiziert haben, können Sie Optimierungsstrategien anwenden, die im nächsten Abschnitt erläutert werden.
Optimierungsstrategien für die Mainframe-Modernisierung
In diesem Abschnitt werden die wichtigsten Strategien zur Optimierung von Anwendungen beschrieben, die von Mainframe-Systemen aus modernisiert wurden. Es konzentriert sich auf drei Strategien: Nutzung vorhandener Strategien APIs, Implementierung von effektivem Caching und Optimierung der Geschäftslogik.
Optimierungsstrategie: Nutzung vorhandener APIs
AWS Blu Age bietet mehrere leistungsstarke APIs In-DAO-Schnittstellen, mit denen Sie die Leistung optimieren können. Zwei Hauptschnittstellen — DAOManager und SQLExecution Builder — bieten Funktionen zur Verbesserung der Anwendungsleistung.
DAOManager
DAOManager dient als primäre Schnittstelle für Datenbankoperationen in modernisierten Anwendungen. Es bietet mehrere Methoden zur Verbesserung der Datenbankoperationen und zur Verbesserung der Anwendungsleistung, insbesondere für einfache Erstellungs-, Lese-, Aktualisierungs- und Löschvorgänge (CRUD) und die Stapelverarbeitung.
Verwenden SetMaxResults. In der DAOManager API können Sie die SetMaxResultsMethode verwenden, um die maximale Anzahl von Datensätzen anzugeben, die in einem einzigen Datenbankvorgang abgerufen werden sollen. DAOManager Ruft standardmäßig nur 10 Datensätze gleichzeitig ab, was bei der Verarbeitung großer Datenmengen zu mehreren Datenbankaufrufen führen kann. Verwenden Sie diese Optimierung, wenn Ihre Anwendung eine große Anzahl von Datensätzen verarbeiten muss und derzeit mehrere Datenbankaufrufe durchführt, um sie abzurufen. Dies ist besonders nützlich in Batchverarbeitungsszenarien, in denen Sie durch einen großen Datensatz iterieren. Im folgenden Beispiel verwendet der Code auf der linken Seite (vor der Optimierung) den Standardwert für den Datenabruf von 10 Datensätzen. Der Code auf der rechten Seite (nach der Optimierung) legt fest setMaxResults, dass 100.000 Datensätze gleichzeitig abgerufen werden.

Anmerkung
Wählen Sie größere Batchgrößen sorgfältig aus und überprüfen Sie die Objektgröße, da diese Optimierung den Speicherbedarf erhöht.
Ersetze SetOnGreatorOrEqual durch SetOnEqual. Diese Optimierung beinhaltet die Änderung der Methode, mit der Sie die Bedingungen für das Abrufen von Datensätzen festlegen. Die SetOnGreatorOrEqualMethode ruft Datensätze ab, die größer oder gleich einem angegebenen Wert sind, wohingegen nur Datensätze SetOnEqualabgerufen werden, die genau dem angegebenen Wert entsprechen.
Verwenden Sie, SetOnEqualwie im folgenden Codebeispiel dargestellt, wenn Sie wissen, dass Sie exakte Übereinstimmungen benötigen und Sie derzeit die SetOnGreatorOrEqualMethode verwenden, gefolgt von readNextEqual(). Diese Optimierung reduziert unnötiges Abrufen von Daten.

Verwenden Sie Batch-Schreib- und Aktualisierungsvorgänge. Sie können Batch-Operationen verwenden, um mehrere Schreib- oder Aktualisierungsvorgänge in einer einzigen Datenbanktransaktion zu gruppieren. Dies reduziert die Anzahl der Datenbankaufrufe und kann die Leistung von Vorgängen, die mehrere Datensätze umfassen, erheblich verbessern.
Im folgenden Beispiel führt der Code auf der linken Seite Schreiboperationen in einer Schleife aus, was die Leistung der Anwendung verlangsamt. Sie können diesen Code optimieren, indem Sie einen Batch-Schreibvorgang verwenden: Bei jeder Iteration der
WHILESchleife fügen Sie Datensätze zu einem Stapel hinzu, bis die Batchgröße eine vorgegebene Größe von 100 erreicht. Sie können den Stapel dann leeren, wenn er die vorgegebene Batchgröße erreicht hat, und anschließend alle verbleibenden Datensätze in die Datenbank übernehmen. Dies ist besonders nützlich in Szenarien, in denen Sie große Datenmengen verarbeiten, die aktualisiert werden müssen.
Fügen Sie Indizes hinzu. Das Hinzufügen von Indizes ist eine Optimierung auf Datenbankebene, die die Abfrageleistung erheblich verbessern kann. Ein Index ermöglicht es der Datenbank, schnell Zeilen mit einem bestimmten Spaltenwert zu finden, ohne die gesamte Tabelle zu scannen. Verwenden Sie die Indizierung für Spalten, die häufig in
WHEREKlauseln,JOINBedingungen oderORDER BYAnweisungen verwendet werden. Dies ist besonders wichtig bei großen Tabellen oder wenn ein schneller Datenabruf entscheidend ist.
SQLExecutionBaumeister
SQLExecutionBuilder ist eine flexible API, mit der Sie die Kontrolle über die auszuführenden SQL-Abfragen übernehmen und nur bestimmte Spalten abrufen können, INSERT indem Sie dynamische Tabellennamen verwenden und verwenden. SELECT Im folgenden Beispiel verwendet SQLExecutor Builder eine benutzerdefinierte Abfrage, die Sie definieren.

Wählen Sie zwischen DAOManager und SQLExecution Builder
Die Wahl zwischen diesen APIs hängt von Ihrem spezifischen Anwendungsfall ab:
Verwenden Sie diese Option DAOManager , wenn Sie möchten, dass AWS Blu Age Runtime die SQL-Abfragen generiert, anstatt sie selbst zu schreiben.
Wählen Sie SQLExecution Builder, wenn Sie SQL-Abfragen schreiben müssen, um datenbankspezifische Funktionen zu nutzen oder optimale SQL-Abfragen zu schreiben.
Optimierungsstrategie: Caching
In modernisierten Anwendungen kann die Implementierung effektiver Caching-Strategien die Anzahl der Datenbankaufrufe erheblich reduzieren und die Antwortzeiten verbessern. Dies trägt dazu bei, die Leistungslücke zwischen Mainframe- und Cloud-Umgebungen zu schließen.
In AWS Blu Age-Anwendungen verwenden einfache Caching-Implementierungen interne Datenstrukturen wie Hashmaps oder Array-Listen, sodass Sie keine externe Caching-Lösung einrichten müssen, die eine Kosten- und Code-Restrukturierung erfordert. Dieser Ansatz ist besonders effektiv für Daten, auf die häufig zugegriffen wird, die sich jedoch selten ändern. Wenn Sie das Caching implementieren, sollten Sie Speicherbeschränkungen und Aktualisierungsmuster berücksichtigen, um sicherzustellen, dass die zwischengespeicherten Daten konsistent bleiben und tatsächliche Leistungsvorteile bieten.
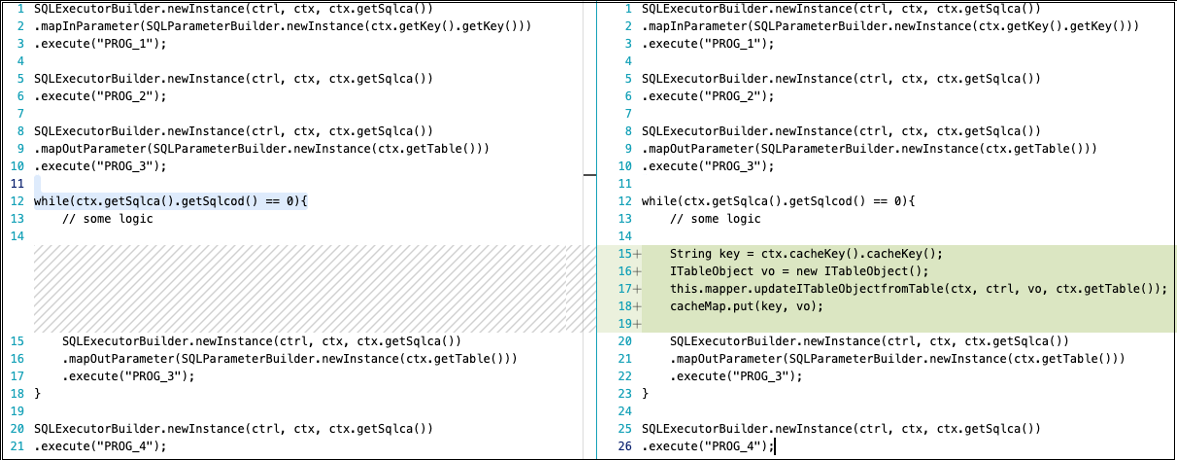
Der Schlüssel zu erfolgreichem Caching liegt in der Identifizierung der richtigen Daten für den Cache. Im folgenden Beispiel liest der Code auf der linken Seite immer Daten aus der Tabelle, wohingegen der Code auf der rechten Seite Daten aus der Tabelle liest, wenn die lokale Hashmap keinen Wert für einen bestimmten Schlüssel enthält. cacheMapist ein Hashmap-Objekt, das im Kontext des Programms erstellt und in der Cleanup-Methode des Programmkontextes gelöscht wird.
Zwischenspeichern mit: DAOManager

Caching mit Builder: SQLExecution
Optimierungsstrategie: Optimierung der Geschäftslogik
Die Optimierung der Geschäftslogik konzentriert sich auf die Umstrukturierung von automatisch generiertem Code aus AWS Blu Age, um ihn besser an die Funktionen moderner Architekturen anzupassen. Dies wird notwendig, wenn der generierte Code dieselbe Logikstruktur wie der ältere Mainframe-Code beibehält, was für moderne Systeme möglicherweise nicht optimal ist. Ziel ist es, die Leistung zu verbessern und gleichzeitig die funktionale Äquivalenz mit der ursprünglichen Anwendung aufrechtzuerhalten.
Dieser Optimierungsansatz geht über einfache API-Optimierungen und Caching-Strategien hinaus. Es beinhaltet Änderungen an der Art und Weise, wie die Anwendung Daten verarbeitet und mit der Datenbank interagiert. Zu den gängigen Optimierungen gehören die Vermeidung unnötiger Lesevorgänge für einfache Updates, das Entfernen redundanter Datenbankaufrufe und die Umstrukturierung der Datenzugriffsmuster, um sie besser an die moderne Anwendungsarchitektur anzupassen. Nachfolgend sind einige Beispiele aufgeführt:
Aktualisierung von Daten direkt in der Datenbank.Strukturieren Sie Ihre Geschäftslogik neu, indem Sie direkte SQL-Updates anstelle mehrerer DAOManager Operationen mit Schleifen verwenden. Der folgende Code (linke Seite) führt beispielsweise mehrere Datenbankaufrufe durch und belegt übermäßig viel Speicher. Insbesondere werden mehrere Datenbank-Lese- und Schreiboperationen innerhalb von Schleifen, einzelne Aktualisierungen statt Stapelverarbeitung und unnötige Objekterstellung für jede Iteration verwendet.
Der folgende optimierte Code (rechte Seite) verwendet einen einzigen Direct SQL-Aktualisierungsvorgang. Insbesondere verwendet er einen einzigen Datenbankaufruf anstelle mehrerer Aufrufe und benötigt keine Schleifen, da alle Aktualisierungen in einer einzigen Anweisung verarbeitet werden. Diese Optimierung sorgt für eine bessere Leistung und Ressourcennutzung und reduziert die Komplexität. Sie verhindert die SQL-Injection, ermöglicht eine bessere Zwischenspeicherung von Abfrageplänen und trägt zur Verbesserung der Sicherheit bei.

Anmerkung
Verwenden Sie immer parametrisierte Abfragen, um eine SQL-Injection zu verhindern und ein ordnungsgemäßes Transaktionsmanagement sicherzustellen.
Reduzierung redundanter Datenbankaufrufe. Redundante Datenbankaufrufe können die Anwendungsleistung erheblich beeinträchtigen, insbesondere wenn sie innerhalb von Schleifen erfolgen. Eine einfache, aber effektive Optimierungstechnik besteht darin, zu vermeiden, dass dieselbe Datenbankabfrage mehrmals wiederholt wird. Der folgende Codevergleich zeigt, wie durch das Verschieben des
retrieve()Datenbankaufrufs außerhalb der Schleife die redundante Ausführung identischer Abfragen verhindert wird, was die Effizienz verbessert.
Reduzierung von Datenbankaufrufen mithilfe der
JOINSQL-Klausel. Implementieren Sie SQLExecution Builder, um die Aufrufe der Datenbank zu minimieren. SQLExecutionBuilder bietet mehr Kontrolle über die SQL-Generierung und ist besonders nützlich für komplexe Abfragen, die DAOManager nicht effizient verarbeitet werden können. Der folgende Code verwendet beispielsweise mehrere DAOManager Aufrufe:List<Employee> employees = daoManager.readAll(); for(Employee emp : employees) { Department dept = deptManager.readById(emp.getDeptId()); // Additional call for each employee Project proj = projManager.readById(emp.getProjId()); // Another call for each employee processEmployeeData(emp, dept, proj); }Der optimierte Code verwendet einen einzigen Datenbankaufruf in SQLExecution Builder:
SQLExecutionBuilder builder = new SQLExecutionBuilder(); builder.append("SELECT e.*, d.name as dept_name, p.name as proj_name"); builder.append("FROM employee e"); builder.append("JOIN department d ON e.dept_id = d.id"); builder.append("JOIN project p ON e.proj_id = p.id"); builder.append("WHERE e.status = ?", "ACTIVE"); List<Map<String, Object>> results = builder.execute(); // Single database call for(Map<String, Object> result : results) { processComplexData(result); }
Optimierungsstrategien gemeinsam verwenden
Diese drei Strategien wirken synergistisch: APIs Bereitstellung der Tools für einen effizienten Datenzugriff, Caching reduziert die Notwendigkeit wiederholter Datenabrufe, und die Optimierung der Geschäftslogik stellt sicher, dass diese so effektiv wie möglich genutzt APIs werden. Die regelmäßige Überwachung und Anpassung dieser Optimierungen gewährleistet kontinuierliche Leistungsverbesserungen bei gleichzeitiger Wahrung der Zuverlässigkeit und Funktionalität der modernisierten Anwendung. Der Schlüssel zum Erfolg liegt darin, zu verstehen, wann und wie die einzelnen Strategien auf der Grundlage der Merkmale und Leistungsziele Ihrer Anwendung angewendet werden müssen.
Tools
JProfiler
ist ein Java-Profiling-Tool, das für Entwickler und Performance-Ingenieure entwickelt wurde. Es analysiert Java-Anwendungen und hilft bei der Identifizierung von Leistungsengpässen, Speicherlecks und Threading-Problemen. JProfiler bietet CPU-, Speicher- und Thread-Profiling sowie Datenbank- und Java-Virtual-Machine-Überwachung (JVM), um Einblicke in das Anwendungsverhalten zu gewinnen. Anmerkung
Als Alternative dazu JProfiler können Sie Java
VisualVM verwenden. Dies ist ein kostenloses Open-Source-Tool zur Erstellung und Überwachung von Leistungsprofilen und zur Überwachung von Java-Anwendungen, das eine Echtzeitüberwachung der CPU-Auslastung, des Speicherverbrauchs, der Threadverwaltung und der Garbage-Collection-Statistiken ermöglicht. Da es sich bei Java VisualVM um ein integriertes JDK-Tool handelt, ist es kostengünstiger als JProfiler für grundlegende Profilerstellungsanforderungen. pgAdmin
ist ein Open-Source-Verwaltungs- und Entwicklungstool für PostgreSQL. Es bietet eine grafische Oberfläche, mit der Sie Datenbankobjekte erstellen, verwalten und verwenden können. Mit pgAdmin können Sie eine Vielzahl von Aufgaben ausführen, vom Schreiben einfacher SQL-Abfragen bis hin zur Entwicklung komplexer Datenbanken. Zu seinen Funktionen gehören ein SQL-Editor mit Syntaxhervorhebung, ein serverseitiger Code-Editor, ein Scheduling-Agent für SQL-, Shell- und Batch-Aufgaben sowie Unterstützung für alle PostgreSQL-Funktionen für Anfänger und erfahrene PostgreSQL-Benutzer.
Best Practices
Identifizierung von Leistungs-Hotspots:
Dokumentieren Sie grundlegende Leistungskennzahlen, bevor Sie mit Optimierungen beginnen.
Legen Sie klare Ziele zur Leistungsverbesserung fest, die auf den Geschäftsanforderungen basieren.
Deaktivieren Sie beim Benchmarking die ausführliche Protokollierung, da dies die Leistung beeinträchtigen kann.
Richten Sie eine Suite für Leistungstests ein und führen Sie sie regelmäßig aus.
Verwenden Sie die neueste Version von pgAdmin. (Ältere Versionen unterstützen den
EXPLAINAbfrageplan nicht.)Beim Benchmarking sollten Sie die Verbindung trennen, JProfiler nachdem Ihre Optimierungen abgeschlossen sind, da dies die Latenz erhöht.
Stellen Sie beim Benchmarking sicher, dass Sie den Server im Startmodus statt im Debug-Modus ausführen, da der Debug-Modus die Latenz erhöht.
Optimierungsstrategien:
Konfigurieren Sie SetMaxResultsWerte in der
application.yamlDatei, um Chargen mit der richtigen Größe gemäß Ihren Systemspezifikationen anzugeben.Konfigurieren Sie SetMaxResultsWerte auf der Grundlage von Datenvolumen und Speicherbeschränkungen.
Wechseln Sie SetOnGreatorOrEqualzu „SetOnEqualNur“, wenn nachfolgende Aufrufe erfolgen
.readNextEqual().Behandeln Sie bei Batch-Schreib- oder Aktualisierungsvorgängen den letzten Batch separat, da er möglicherweise kleiner als die konfigurierte Batchgröße ist und beim Schreib- oder Aktualisierungsvorgang übersehen werden könnte.
Zwischenspeichern:
Felder, die für das Caching eingeführt wurden
processImplund die bei jeder Ausführung mutieren, sollten immer im jeweiligen Kontext definiert werden.processImplDie Felder sollten auch mit der MethodedoReset()orcleanUp()gelöscht werden.Wenn Sie In-Memory-Caching implementieren, passen Sie die Größe des Caches an. Sehr große Caches, die im Arbeitsspeicher gespeichert sind, können alle Ressourcen beanspruchen, was sich auf die Gesamtleistung Ihrer Anwendung auswirken kann.
SQLExecutionBuilder:
Verwenden Sie für Abfragen, die Sie in SQLExecution Builder verwenden möchten, Schlüsselnamen wie
PROGRAMNAME_STATEMENTNUMBER.Wenn Sie SQLExecution Builder verwenden, suchen Sie immer nach dem
SqlcodFeld. Dieses Feld enthält einen Wert, der angibt, ob die Abfrage korrekt ausgeführt wurde oder ob Fehler aufgetreten sind.Verwenden Sie parametrisierte Abfragen, um eine SQL-Injection zu verhindern.
Optimierung der Geschäftslogik:
Achten Sie bei der Umstrukturierung von Code auf funktionale Äquivalenz und führen Sie Regressionstests und Datenbankvergleiche für die entsprechende Teilmenge von Programmen durch.
Pflegen Sie Schnappschüsse zur Profilerstellung zum Vergleich.
Epen
| Aufgabe | Description | Erforderliche Fähigkeiten |
|---|---|---|
Installieren und konfigurieren JProfiler. |
| App-Developer |
Installieren und konfigurieren Sie pgAdmin. | In diesem Schritt installieren und konfigurieren Sie einen DB-Client für die Abfrage Ihrer Datenbank. Dieses Muster verwendet eine PostgreSQL-Datenbank und pgAdmin als Datenbankclient. Wenn Sie eine andere Datenbank-Engine verwenden, folgen Sie der Dokumentation für den entsprechenden DB-Client.
| App-Developer |
| Aufgabe | Description | Erforderliche Fähigkeiten |
|---|---|---|
Aktivieren Sie die SQL-Abfrageprotokollierung in Ihrer AWS Blu Age-Anwendung. | Aktivieren Sie die Logger für die Protokollierung von SQL-Abfragen in der | App-Developer |
Generieren und analysieren Sie | Einzelheiten finden Sie im Abschnitt Architektur. | App-Developer |
Erstellen Sie einen JProfiler Snapshot, um einen Testfall mit langsamer Leistung zu analysieren. |
| App-Developer |
Analysieren Sie den JProfiler Snapshot, um Leistungsengpässe zu identifizieren. | Gehen Sie wie folgt vor, um den Snapshot zu analysieren. JProfiler
Weitere Informationen zur Verwendung JProfiler finden Sie im Abschnitt Architektur und in der JProfiler Dokumentation | App-Developer |
| Aufgabe | Description | Erforderliche Fähigkeiten |
|---|---|---|
Legen Sie eine Leistungsbasis fest, bevor Sie Optimierungen implementieren. |
| App-Developer |
| Aufgabe | Description | Erforderliche Fähigkeiten |
|---|---|---|
Optimieren Sie Leseanrufe. | Optimieren Sie den Datenabruf mithilfe der DAOManager SetMaxResultsMethode. Weitere Informationen zu diesem Ansatz finden Sie im Abschnitt Architektur. | App-Entwickler, DAOManager |
Refaktorieren Sie die Geschäftslogik, um mehrere Aufrufe der Datenbank zu vermeiden. | Reduzieren Sie Datenbankaufrufe mithilfe einer | App-Entwickler, SQLExecution Builder |
Refaktorieren Sie den Code so, dass er Caching verwendet, um die Latenz von Leseaufrufen zu reduzieren. | Informationen zu dieser Technik finden Sie unter Caching im Abschnitt Architektur. | App-Developer |
Schreiben Sie ineffizienten Code neu, der mehrere DAOManager Operationen für einfache Aktualisierungsvorgänge verwendet. | Weitere Informationen zum Aktualisieren von Daten direkt in der Datenbank finden Sie unter Optimierung der Geschäftslogik im Abschnitt Architektur. | App-Developer |
| Aufgabe | Description | Erforderliche Fähigkeiten |
|---|---|---|
Validieren Sie jede Optimierungsänderung iterativ unter Beibehaltung der funktionalen Äquivalenz. |
AnmerkungDie Verwendung von Basiskennzahlen als Referenz gewährleistet eine genaue Messung der Auswirkungen jeder Optimierung bei gleichzeitiger Wahrung der Systemzuverlässigkeit. | App-Developer |
Fehlerbehebung
| Problem | Lösung |
|---|---|
Wenn Sie die moderne Anwendung ausführen, wird eine Ausnahme mit dem Fehler angezeigt | So beheben Sie dieses Problem
|
Sie haben Indizes hinzugefügt, sehen aber keine Leistungsverbesserungen. | Gehen Sie wie folgt vor, um sicherzustellen, dass die Abfrage-Engine den Index verwendet:
|
Sie stoßen auf eine out-of-memory Ausnahme. | Stellen Sie sicher, dass der Code den in der Datenstruktur enthaltenen Speicher freigibt. |
Batch-Schreibvorgänge führen zu fehlenden Datensätzen in der Tabelle | Überprüfen Sie den Code, um sicherzustellen, dass ein zusätzlicher Schreibvorgang ausgeführt wird, wenn die Batchanzahl nicht Null ist. |
Die SQL-Protokollierung erscheint nicht in den Anwendungsprotokollen. |
|
Zugehörige Ressourcen
Automatisches Refactoring von Anwendungen mit AWS Blu Age (AWS Mainframe Modernization Benutzerhandbuch)
