Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Deterministische Selbstüberschätzung
Gal und Ghahramani (2016) warnten davor, Softmax-Wahrscheinlichkeiten als Konfidenzwerte zu interpretieren. Sie zeigten empirisch, dass die Weitergabe einer Punktschätzung durch die Softmax-Aktivierungsfunktion zu hohen Wahrscheinlichkeiten führt, wohingegen die Weitergabe einer Verteilung von Schätzungen über die Softmax-Methode zu vernünftigeren, niedrigeren Konfidenzwerten führt. Diese deterministische Selbstüberschätzung ist zum Teil darauf zurückzuführen, dass das Erlernen einer prädiktiven Verteilung und nicht einer einzelnen Vorhersage motiviert ist.
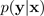
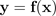
Formal lässt sich die deterministische Vermutung der Selbstüberschätzung anhand der folgenden Ungleichheit detailliert beschreiben:
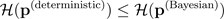
Der
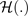 Operator steht für Shannons Entropie, die größer ist, wenn sich Elemente des Eingabevektors ähnlicher sind, und daher bei gleichförmigen Vektoren am größten ist. Somit besagt die vorherige Gleichung, dass die Unsicherheit, ausgedrückt als Shannon-Entropie
, des erwarteten Softmax-Wahrscheinlichkeitsvektors aus einem Bayes-Modell
Operator steht für Shannons Entropie, die größer ist, wenn sich Elemente des Eingabevektors ähnlicher sind, und daher bei gleichförmigen Vektoren am größten ist. Somit besagt die vorherige Gleichung, dass die Unsicherheit, ausgedrückt als Shannon-Entropie
, des erwarteten Softmax-Wahrscheinlichkeitsvektors aus einem Bayes-Modell
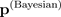 (der Durchschnitt einer Verteilung) größer oder gleich dem Softmax-Wahrscheinlichkeitsvektor aus einem deterministischen Modell
(der Durchschnitt einer Verteilung) größer oder gleich dem Softmax-Wahrscheinlichkeitsvektor aus einem deterministischen Modell
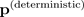 (aus einem Modell, das eine Einzelpunktschätzung erzeugt) sein wird. Einen Beweis und eine Demonstration der Ungleichheit in der vorherigen Gleichung finden Sie in Anhang A.
(aus einem Modell, das eine Einzelpunktschätzung erzeugt) sein wird. Einen Beweis und eine Demonstration der Ungleichheit in der vorherigen Gleichung finden Sie in Anhang A.
Deterministische Selbstüberschätzung beeinträchtigt die Zuverlässigkeit und Sicherheit unserer Deep-Learning-Modelle. Stellen Sie sich den Fall vor, dass ein Modell zuverlässig voraussagt, dass ein Artikel an einer Montagelinie nicht defekt ist, obwohl dies tatsächlich der Fall ist, was dazu führt, dass der Artikel die Qualitätsprüfung überspringt. Dieser fehlerhafte Artikel könnte dann in ein größeres Produkt eingebettet werden, wodurch dessen Integrität beeinträchtigt wird. Das Endergebnis ist bestenfalls eine Ineffizienz, wenn der Fehler im Laufe der Zeit erkannt wird, oder schlimmer noch, ein Totalausfall des Produkts, wenn der Fehler nicht gefunden wird. Daher ist es für den Erfolg unserer Projekte und für die future von Deep Learning von entscheidender Bedeutung, deterministische Selbstüberschätzung zu verstehen und zu überwinden.
Es gibt drei Möglichkeiten, die Qualität von Unsicherheitsmessungen zu verbessern und Selbstüberschätzung zu überwinden:
-
Post-hoc-Kalibrierung von Softmax-Wahrscheinlichkeiten mit Temperaturskalierung (Guo et al. 2017)
Deterministische Selbstüberschätzung ist eine Theorie, die sowohl für die Verteilung als auch für Daten gilt. out-of-distribution 1 In den nächsten Abschnitten wird erklärt, wie die gesamte quantifizierbare Unsicherheit 2 in ihre beiden Bestandteile aufgeteilt werden kann: epistemische (Modell-) Unsicherheit und aleatorische Unsicherheit (Daten) (Kendall und Gal 2017).
Hinweise
1 Insbesondere wurde kürzlich festgestellt, dass die Vertrauensüberschätzung mit rektifizierten linearen Einheiten (ReLU) erheblich zur Selbstüberschätzung beiträgt, wenn Daten weit von der Entscheidungsgrenze entfernt sind, insbesondere wenn Daten nicht mehr verbreitet sind (Hein, Andriushchenko und Bitterwolf 2019). Ein Vorschlag, um widerstandsfähig gegen die Selbstüberschätzung der ReLU zu werden, besteht darin, den informationstheoretischen Begriff der aleatorischen Unsicherheit zu modellieren (Gal und Ghahramani 2016, Hein, Andriushchenko und Bitterwolf 2019, van Amersfoort et al. 2020), der später in diesem Leitfaden erläutert wird.
2 In einigen Bereichen wird die totale Unsicherheit in Unsicherheit, die quantifizierbar ist, und Unsicherheit, die nicht quantifizierbar ist, zerlegt. Die Diskussion in diesem Leitfaden beschränkt sich auf quantifizierbare Unsicherheit; daher werden die Begriffe „totale Unsicherheit“ und „gesamte quantifizierbare Unsicherheit“ synonym verwendet.
