Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Direkte Migration
Durch die direkte Migration müssen Sie nicht mehr all Ihre Datendateien neu schreiben. Stattdessen werden Iceberg-Metadatendateien generiert und mit Ihren vorhandenen Datendateien verknüpft. Diese Methode ist in der Regel schneller und kostengünstiger, insbesondere bei großen Datensätzen oder Tabellen mit kompatiblen Dateiformaten wie Parquet, Avro und ORC.
Anmerkung
Die direkte Migration kann bei der Migration zu Amazon S3-Tabellen nicht verwendet werden.
Iceberg bietet zwei Hauptoptionen für die Implementierung der In-Place-Migration:
-
Verwenden des Snapshot-Verfahrens
, um eine neue Iceberg-Tabelle zu erstellen und dabei die Quelltabelle unverändert zu lassen. Weitere Informationen finden Sie unter Snapshot-Tabelle in der Iceberg-Dokumentation. -
Verwenden des Migrationsverfahrens
, um eine neue Iceberg-Tabelle als Ersatz für die Quelltabelle zu erstellen. Weitere Informationen finden Sie unter Tabelle migrieren in der Iceberg-Dokumentation. Dieses Verfahren funktioniert zwar mit Hive Metastore (HMS), ist aber derzeit nicht kompatibel mit dem. AWS Glue Data Catalog Das Verfahren zur Replikation der Tabellenmigration im AWS Glue Data Catalog Abschnitt weiter unten in diesem Handbuch bietet eine Problemumgehung, um mit dem Datenkatalog ein ähnliches Ergebnis zu erzielen.
Nachdem Sie die direkte Migration mit einer der Optionen snapshot oder durchgeführt habenmigrate, bleiben einige Datendateien möglicherweise nicht migriert. Dies ist in der Regel der Fall, wenn Autoren während oder nach der Migration weiterhin in die Quelltabelle schreiben. Um diese verbleibenden Dateien in Ihre Iceberg-Tabelle zu integrieren, können Sie die add_files-Prozedur
Nehmen wir an, Sie haben eine Parquet-basierte products Tabelle, die in Athena wie folgt erstellt und gefüllt wurde:
CREATE EXTERNAL TABLE mydb.products ( product_id INT, product_name STRING ) PARTITIONED BY (category STRING) STORED AS PARQUET LOCATION 's3://amzn-s3-demo-bucket/products/'; INSERT INTO mydb.products VALUES (1001, 'Smartphone', 'electronics'), (1002, 'Laptop', 'electronics'), (2001, 'T-Shirt', 'clothing'), (2002, 'Jeans', 'clothing');
In den folgenden Abschnitten wird erklärt, wie Sie die migrate Verfahren snapshot und für diese Tabelle verwenden können.
Option 1: Snapshot-Verfahren
Das snapshot Verfahren erstellt eine neue Iceberg-Tabelle, die einen anderen Namen hat, aber das Schema und die Partitionierung der Quelltabelle repliziert. Bei diesem Vorgang bleibt die Quelltabelle sowohl während als auch nach der Aktion vollständig unverändert. Dabei wird effektiv eine einfache Kopie der Tabelle erstellt, was besonders nützlich ist, um Szenarien zu testen oder Daten zu untersuchen, ohne das Risiko einzugehen, Änderungen an der ursprünglichen Datenquelle zu riskieren. Dieser Ansatz ermöglicht eine Übergangsphase, in der sowohl die Originaltabelle als auch die Iceberg-Tabelle verfügbar bleiben (siehe die Hinweise am Ende dieses Abschnitts). Wenn die Tests abgeschlossen sind, können Sie Ihre neue Iceberg-Tabelle in die Produktionsumgebung überführen, indem Sie alle Autoren und Leser auf die neue Tabelle umstellen.
Sie können das snapshot Verfahren ausführen, indem Sie Spark in jedem Amazon EMR-Bereitstellungsmodell verwenden (z. B. Amazon EMR auf EC2, Amazon EMR auf EKS, EMR Serverless) und. AWS Glue
Gehen Sie wie folgt vor, um die direkte Migration mit dem Spark-Verfahren zu testen: snapshot
-
Starten Sie eine Spark-Anwendung und konfigurieren Sie die Spark-Sitzung mit den folgenden Einstellungen:
-
"spark.sql.extensions":"org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" -
"spark.sql.catalog.spark_catalog":"org.apache.iceberg.spark.SparkSessionCatalog" -
"spark.sql.catalog.spark_catalog.type":"glue" -
"spark.hadoop.hive.metastore.client.factory.class":"com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory"
-
-
Führen Sie das
snapshotVerfahren aus, um eine neue Iceberg-Tabelle zu erstellen, die auf die ursprünglichen Tabellendatendateien verweist:spark.sql(f""" CALL system.snapshot( source_table => 'mydb.products', table => 'mydb.products_iceberg', location => 's3://amzn-s3-demo-bucket/products_iceberg/' ) """ ).show(truncate=False)Der Ausgabedatenrahmen enthält die
imported_files_count(die Anzahl der hinzugefügten Dateien). -
Überprüfen Sie die neue Tabelle, indem Sie sie abfragen:
spark.sql(f""" SELECT * FROM mydb.products_iceberg LIMIT 10 """ ).show(truncate=False)
Hinweise
-
Nachdem Sie die Prozedur ausgeführt haben, führt jede Änderung der Datendatei an der Quelltabelle dazu, dass die generierte Tabelle nicht mehr synchron ist. Neue Dateien, die Sie hinzufügen, sind in der Eisberg-Tabelle nicht sichtbar, und Dateien, die Sie entfernt haben, wirken sich auf die Abfragefunktionen in der Eisberg-Tabelle aus. Gehen Sie wie folgt vor, um Synchronisationsprobleme zu vermeiden:
-
Wenn die neue Iceberg-Tabelle für den Produktionseinsatz vorgesehen ist, beenden Sie alle Prozesse, die in die Originaltabelle schreiben, und leiten Sie sie in die neue Tabelle um.
-
Wenn Sie eine Übergangszeit benötigen oder wenn die neue Iceberg-Tabelle zu Testzwecken verwendet wird, finden Sie weiter unten in diesem Abschnitt Anleitungen zur Aufrechterhaltung der Tabellensynchronisierung unter Synchronisieren von Iceberg-Tabellen nach der In-Place-Migration.
-
-
Wenn Sie das
snapshotVerfahren verwenden, wird diegc.enabledEigenschaftfalsein den Tabelleneigenschaften der erstellten Iceberg-Tabelle auf festgelegt. Diese Einstellung verbietet Aktionen wieexpire_snapshotsremove_orphan_files, oderDROP TABLEmit derPURGEOption, durch die Datendateien physisch gelöscht würden. Lösch- oder Zusammenführungsvorgänge von Iceberg, die sich nicht direkt auf Quelldateien auswirken, sind weiterhin zulässig. -
Um Ihre neue Iceberg-Tabelle voll funktionsfähig zu machen, ohne Einschränkungen bei Aktionen, die Datendateien physisch löschen, können Sie die
gc.enabledTabelleneigenschaft auf ändern.trueDiese Einstellung ermöglicht jedoch Aktionen, die sich auf Quelldatendateien auswirken, wodurch der Zugriff auf die Originaltabelle beeinträchtigt werden könnte. Ändern Sie diegc.enabledEigenschaft daher nur, wenn Sie die Funktionalität der Originaltabelle nicht mehr beibehalten müssen. Beispiel:spark.sql(f""" ALTER TABLE mydb.products_iceberg SET TBLPROPERTIES ('gc.enabled' = 'true'); """)
Option 2: Migrationsverfahren
Das migrate Verfahren erstellt eine neue Iceberg-Tabelle, die denselben Namen, dasselbe Schema und dieselbe Partitionierung wie die Quelltabelle hat. Wenn diese Prozedur ausgeführt wird, sperrt sie die Quelltabelle und benennt sie um in <table_name>_BACKUP_ (oder in einen benutzerdefinierten Namen, der durch den backup_table_name Parameter procedure angegeben wird).
Anmerkung
Wenn Sie den drop_backup Prozedurparameter auf setzentrue, wird die Originaltabelle nicht als Backup aufbewahrt.
Folglich erfordert die migrate Tabellenprozedur, dass alle Änderungen, die sich auf die Quelltabelle auswirken, gestoppt werden, bevor die Aktion ausgeführt wird. Bevor Sie die migrate Prozedur ausführen:
-
Stoppen Sie alle Writer, die mit der Quelltabelle interagieren.
-
Ändern Sie Leser und Autoren, die Iceberg nicht nativ unterstützen, um die Iceberg-Unterstützung zu aktivieren.
Beispiel:
-
Athena arbeitet weiterhin ohne Änderung.
-
Spark benötigt:
-
Iceberg Java Archive (JAR) -Dateien, die in den Klassenpfad aufgenommen werden sollen (siehe die Abschnitte Arbeiten mit Iceberg in Amazon EMR und Arbeiten mit Iceberg in den Abschnitten weiter oben in AWS Glue diesem Handbuch).
-
Die folgenden Konfigurationen des Spark-Sitzungskatalogs (werden verwendet,
SparkSessionCatalogum Iceberg-Unterstützung hinzuzufügen und gleichzeitig die integrierten Katalogfunktionen für Tabellen beizubehalten, die nicht zu Iceberg gehören):-
"spark.sql.extensions":"org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" -
"spark.sql.catalog.spark_catalog":"org.apache.iceberg.spark.SparkSessionCatalog" -
"spark.sql.catalog.spark_catalog.type":"glue" -
"spark.hadoop.hive.metastore.client.factory.class":"com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory"
-
-
Nachdem Sie das Verfahren ausgeführt haben, können Sie Ihre Writer mit ihrer neuen Iceberg-Konfiguration neu starten.
Derzeit ist das migrate Verfahren nicht mit dem kompatibel AWS Glue Data Catalog, da der Datenkatalog den RENAME Vorgang nicht unterstützt. Daher empfehlen wir, dieses Verfahren nur zu verwenden, wenn Sie mit Hive Metastore arbeiten. Wenn Sie den Datenkatalog verwenden, finden Sie im nächsten Abschnitt einen alternativen Ansatz.
Sie können das migrate Verfahren für alle Amazon EMR-Bereitstellungsmodelle (Amazon EMR auf EC2, Amazon EMR auf EKS, EMR Serverless) und ausführen, erfordert jedoch eine konfigurierte Verbindung zu AWS Glue Hive Metastore. Amazon EMR on EC2 ist die empfohlene Wahl, da es eine integrierte Hive Metastore-Konfiguration bietet, die die Komplexität der Einrichtung minimiert.
Gehen Sie wie folgt vor, um die In-Place-Migration mit dem migrate Spark-Verfahren von einem Amazon EMR auf EC2-Cluster zu testen, der mit Hive Metastore konfiguriert ist:
-
Starten Sie eine Spark-Anwendung und konfigurieren Sie die Spark-Sitzung so, dass sie die Iceberg Hive-Katalogimplementierung verwendet. Wenn Sie beispielsweise die
pysparkCLI verwenden:pyspark --conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions --conf spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog --conf spark.sql.catalog.spark_catalog.type=hive -
Erstellen Sie eine
productsTabelle in Hive Metastore. Dies ist die Quelltabelle, die bei einer typischen Migration bereits vorhanden ist.-
Erstellen Sie die
productsexterne Hive-Tabelle in Hive Metastore, um auf die vorhandenen Daten in Amazon S3 zu verweisen:spark.sql(f""" CREATE EXTERNAL TABLE products ( product_id INT, product_name STRING ) PARTITIONED BY (category STRING) STORED AS PARQUET LOCATION 's3://amzn-s3-demo-bucket/products/'; """ ) -
Fügen Sie die vorhandenen Partitionen mit dem folgenden Befehl hinzu:
MSCK REPAIR TABLEspark.sql(f""" MSCK REPAIR TABLE products """ ) -
Stellen Sie sicher, dass die Tabelle Daten enthält, indem Sie eine
SELECTAbfrage ausführen:spark.sql(f""" SELECT * FROM products """ ).show(truncate=False)Beispielausgabe:

-
-
Verwenden Sie das Iceberg-Verfahren
migrate:df_res=spark.sql(f""" CALL system.migrate( table => 'default.products' ) """ ) df_res.show()Der Ausgabedatenrahmen enthält
migrated_files_count(die Anzahl der Dateien, die der Iceberg-Tabelle hinzugefügt wurden):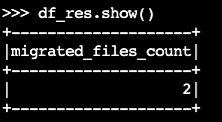
-
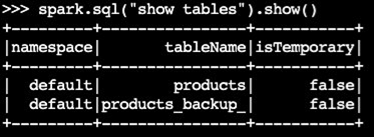
Vergewissern Sie sich, dass die Backup-Tabelle erstellt wurde:
spark.sql("show tables").show()Beispielausgabe:
-
Überprüfen Sie den Vorgang, indem Sie die Iceberg-Tabelle abfragen:
spark.sql(f""" SELECT * FROM products """ ).show(truncate=False)
Hinweise
-
Nachdem Sie die Prozedur ausgeführt haben, sind alle aktuellen Prozesse, die die Quelltabelle abfragen oder in sie schreiben, betroffen, wenn sie nicht ordnungsgemäß mit Iceberg-Unterstützung konfiguriert sind. Daher empfehlen wir, dass Sie die folgenden Schritte ausführen:
-
Stoppen Sie vor der Migration alle Prozesse mithilfe der Quelltabelle.
-
Führen Sie die Migration durch.
-
Reaktivieren Sie die Prozesse, indem Sie die richtigen Iceberg-Einstellungen verwenden.
-
-
Wenn Datendateien während des Migrationsprozesses geändert werden (neue Dateien werden hinzugefügt oder Dateien entfernt), gerät die generierte Tabelle nicht mehr synchron. Informationen zu Synchronisierungsoptionen finden Sie unter Synchronisieren von Iceberg-Tabellen nach der In-Place-Migration weiter unten in diesem Abschnitt.
Das Verfahren zur Tabellenmigration replizieren in AWS Glue Data Catalog
Sie können das Ergebnis des Migrationsvorgangs replizieren AWS Glue Data Catalog (Sicherung der Originaltabelle und Ersetzen durch eine Iceberg-Tabelle), indem Sie die folgenden Schritte ausführen:
-
Verwenden Sie das Snapshot-Verfahren, um eine neue Iceberg-Tabelle zu erstellen, die auf die Datendateien der Originaltabelle verweist.
-
Sichern Sie die Metadaten der ursprünglichen Tabelle im Datenkatalog:
-
Verwenden Sie die GetTableAPI, um die Quelltabellendefinition abzurufen.
-
Verwenden Sie die GetPartitionsAPI, um die Partitionsdefinition der Quelltabelle abzurufen.
-
Verwenden Sie die CreateTableAPI, um eine Backup-Tabelle im Datenkatalog zu erstellen.
-
Verwenden Sie die BatchCreatePartitionAPI CreatePartitionoder, um Partitionen in der Backup-Tabelle im Datenkatalog zu registrieren.
-
-
Ändern Sie die
gc.enabledIceberg-Tabelleneigenschaft auffalse, um vollständige Tabellenoperationen zu aktivieren. -
Entfernen Sie die ursprüngliche Tabelle.
-
Suchen Sie die Iceberg-Tabellenmetadaten-JSON-Datei im Metadatenordner des Stammverzeichnisses der Tabelle.
-
Registrieren Sie die neue Tabelle im Datenkatalog, indem Sie die Prozedur register_table
mit dem ursprünglichen Tabellennamen und dem Speicherort der metadata.jsonDatei verwenden, die von der Prozedur erstellt wurde:snapshotspark.sql(f""" CALL system.register_table( table => 'mydb.products', metadata_file => '{iceberg_metadata_file}' ) """ ).show(truncate=False)
Synchronisieren von Iceberg-Tabellen nach der In-Place-Migration
Das add_files Verfahren bietet eine flexible Möglichkeit, vorhandene Daten in Iceberg-Tabellen zu integrieren. Insbesondere werden vorhandene Datendateien (wie Parquet-Dateien) registriert, indem auf ihre absoluten Pfade in der Metadatenebene von Iceberg verwiesen wird. Standardmäßig fügt das Verfahren Dateien aus allen Tabellenpartitionen zu einer Iceberg-Tabelle hinzu, Sie können jedoch selektiv Dateien aus bestimmten Partitionen hinzufügen. Dieser selektive Ansatz ist in mehreren Szenarien besonders nützlich:
-
Wenn der Quelltabelle nach der ersten Migration neue Partitionen hinzugefügt werden.
-
Wenn nach der ersten Migration Datendateien zu vorhandenen Partitionen hinzugefügt oder aus vorhandenen Partitionen entfernt werden. Um geänderte Partitionen erneut hinzuzufügen, muss die Partition jedoch zuerst gelöscht werden. Weitere Informationen dazu finden Sie weiter unten in diesem Abschnitt.
Im Folgenden finden Sie einige Überlegungen zur Verwendung des add_file Verfahrens, nachdem die direkte Migration (snapshotodermigrate) durchgeführt wurde, um die neue Iceberg-Tabelle mit den Quelldatendateien synchron zu halten:
-
Wenn neue Daten zu neuen Partitionen in der Quelltabelle hinzugefügt werden, verwenden Sie das
add_filesVerfahren mit derpartition_filterOption, diese Ergänzungen selektiv in die Iceberg-Tabelle zu integrieren:spark.sql(f""" CALL system.add_files( source_table => 'mydb.products', table => 'mydb.products_iceberg', partition_filter => map('category', 'electronics') ).show(truncate=False)oder:
spark.sql(f""" CALL system.add_files( source_table => '`parquet`.`s3://amzn-s3-demo-bucket/products/`', table => 'mydb.products_iceberg', partition_filter => map('category', 'electronics') ).show(truncate=False) -
Die
add_filesProzedur sucht entweder in der gesamten Quelltabelle oder in bestimmten Partitionen nach Dateien, wenn Sie diepartition_filterOption angeben, und versucht, alle gefundenen Dateien zur Iceberg-Tabelle hinzuzufügen. Standardmäßig ist diecheck_duplicate_filesProzedureigenschaft auf gesetzttrue, wodurch verhindert wird, dass die Prozedur ausgeführt wird, wenn in der Iceberg-Tabelle bereits Dateien vorhanden sind. Dies ist wichtig, da es keine integrierte Option zum Überspringen zuvor hinzugefügter Dateien gibt und eine Deaktivierungcheck_duplicate_filesdazu führt, dass Dateien zweimal hinzugefügt werden, wodurch Duplikate entstehen. Gehen Sie folgendermaßen vor, wenn der Quelltabelle neue Dateien hinzugefügt werden:-
Verwenden Sie für neue Partitionen
add_fileswith a,partition_filterum nur Dateien aus der neuen Partition zu importieren. -
Löschen Sie bei vorhandenen Partitionen zuerst die Partition aus der Iceberg-Tabelle und führen Sie den Vorgang dann erneut
add_filesfür diese Partition aus, wobei Sie den angeben.partition_filterBeispiel:# We initially perform in-place migration with snapshot spark.sql(f""" CALL system.snapshot( source_table => 'mydb.products', table => 'mydb.products_iceberg', location => 's3://amzn-s3-demo-bucket/products_iceberg/' ) """ ).show(truncate=False) # Then on the source table, some new files were generated under the category='electronics' partition. Example: spark.sql(""" INSERT INTO mydb.products VALUES (1003, 'Tablet', 'electronics') """) # We delete the modified partition from the Iceberg table. Note this is a metadata operation only spark.sql(""" DELETE FROM mydb.products_iceberg WHERE category = 'electronics' """) # We add_files from the modified partition spark.sql(""" CALL system.add_files( source_table => 'mydb.products', table => 'mydb.products_iceberg', partition_filter => map('category', 'electronics') ) """).show(truncate=False)
-
Anmerkung
Jeder add_files Vorgang generiert einen neuen Iceberg-Tabellen-Snapshot mit angehängten Daten.
Auswahl der richtigen Strategie für die direkte Migration
Beachten Sie die Fragen in der folgenden Tabelle, um die beste Strategie für die direkte Migration auszuwählen.
Frage |
Empfehlung |
Erklärung |
|---|---|---|
Möchten Sie schnell migrieren, ohne Daten neu zu schreiben, und gleichzeitig die Hive- und Iceberg-Tabellen für Tests oder schrittweise Umstellung zugänglich halten? |
|
Gehen Sie |
Verwenden Sie Hive Metastore und möchten Sie Ihre Hive-Tabelle sofort durch eine Iceberg-Tabelle ersetzen, ohne die Daten neu zu schreiben? |
|
Gehen Sie Hinweis: Diese Option ist mit Hive Metastore kompatibel, aber nicht mit. AWS Glue Data Catalog Gehen Sie |
Verwenden Sie Ihre Hive-Tabelle AWS Glue Data Catalog und möchten Sie diese sofort durch eine Iceberg-Tabelle ersetzen, ohne die Daten neu zu schreiben? |
Anpassung des |
Verhalten der
Hinweis: Diese Option erfordert die manuelle Bearbeitung von AWS Glue API-Aufrufen für die Metadatensicherung. Verwenden Sie das |
