Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Optimierung der Leseleistung
In diesem Abschnitt werden Tabelleneigenschaften beschrieben, die Sie unabhängig von der Engine anpassen können, um die Leseleistung zu optimieren.
Partitionierung
Wie bei Hive-Tabellen verwendet Iceberg Partitionen als primäre Indizierungsebene, um das Lesen unnötiger Metadaten- und Datendateien zu vermeiden. Spaltenstatistiken werden auch als sekundäre Indizierungsebene berücksichtigt, um die Abfrageplanung weiter zu verbessern, was zu einer besseren Gesamtausführungszeit führt.
Ihre Daten partitionieren
Um die Datenmenge zu reduzieren, die bei der Abfrage von Iceberg-Tabellen gescannt wird, wählen Sie eine ausgewogene Partitionsstrategie, die Ihren erwarteten Lesemustern entspricht:
-
Identifizieren Sie Spalten, die häufig in Abfragen verwendet werden. Dies sind ideale Partitionierungskandidaten. Wenn Sie beispielsweise normalerweise Daten von einem bestimmten Tag abfragen, wäre ein natürliches Beispiel für eine Partitionsspalte eine Datumsspalte.
-
Wählen Sie eine Partitionsspalte mit niedriger Kardinalität, um zu vermeiden, dass zu viele Partitionen erstellt werden. Zu viele Partitionen können die Anzahl der Dateien in der Tabelle erhöhen, was sich negativ auf die Abfrageleistung auswirken kann. Als Faustregel gilt, dass „zu viele Partitionen“ als ein Szenario definiert werden können, in dem die Datengröße in den meisten Partitionen weniger als das Zwei- bis Fünffache des von
target-file-size-bytesfestgelegten Werts beträgt.
Anmerkung
Wenn Sie in der Regel Filter für eine Spalte mit hoher Kardinalität verwenden (z. B. eine id Spalte, die Tausende von Werten haben kann), verwenden Sie die Funktion für versteckte Partitionierung von Iceberg mit Bucket-Transformationen, wie im nächsten Abschnitt erklärt.
Verwenden Sie versteckte Partitionierung
Wenn Ihre Abfragen häufig nach einer Ableitung einer Tabellenspalte filtern, verwenden Sie versteckte Partitionen, anstatt explizit neue Spalten zu erstellen, die als Partitionen verwendet werden können. Weitere Informationen zu dieser Funktion finden Sie in der Iceberg-Dokumentation
Verwenden Sie beispielsweise in einem Datensatz mit einer Zeitstempelspalte (z. B.2023-01-01 09:00:00) Partitionstransformationen, um den Datumsanteil aus dem Zeitstempel zu extrahieren und diese Partitionen im Handumdrehen zu erstellen, anstatt eine neue Spalte mit dem analysierten Datum zu erstellen (z. B.2023-01-01).
Die häufigsten Anwendungsfälle für versteckte Partitionierung sind:
-
Partitionierung nach Datum oder Uhrzeit, wenn die Daten eine Zeitstempelspalte haben. Iceberg bietet mehrere Transformationen, um die Datums- oder Uhrzeitteile eines Zeitstempels zu extrahieren.
-
Partitionierung nach einer Hash-Funktion einer Spalte, wenn die partitionierende Spalte eine hohe Kardinalität aufweist und zu vielen Partitionen führen würde. Die Bucket-Transformation von Iceberg gruppiert mehrere Partitionswerte zu weniger versteckten (Bucket-) Partitionen, indem Hash-Funktionen für die Partitionierungsspalte verwendet werden.
Einen Überblick über alle verfügbaren Partitionstransformationen
Spalten, die für versteckte Partitionierung verwendet werden, können durch die Verwendung regulärer SQL-Funktionen wie und Teil von Abfrageprädikaten werden. year() month() Prädikate können auch mit Operatoren wie und kombiniert werden. BETWEEN AND
Anmerkung
Iceberg kann keine Partitionsbereinigung für Funktionen durchführen, die einen anderen Datentyp ergeben, z. B. substring(event_time, 1, 10) =
'2022-01-01'
Verwenden Sie Partition Evolution
Verwenden Sie die Partitionsentwicklung von Iceberg
Sie können diesen Ansatz verwenden, wenn die beste Partitionsstrategie für eine Tabelle zunächst unklar ist und Sie Ihre Partitionierungsstrategie verfeinern möchten, wenn Sie mehr Erkenntnisse gewinnen. Eine weitere effektive Anwendung der Partitionsentwicklung besteht darin, dass sich die Datenmengen ändern und die aktuelle Partitionierungsstrategie im Laufe der Zeit an Effektivität verliert.
Anweisungen zur Weiterentwicklung von Partitionen finden Sie unter ALTER TABLE SQL-Erweiterungen
Optimieren der Dateigrößen
Zur Optimierung der Abfrageleistung gehört die Minimierung der Anzahl kleiner Dateien in Ihren Tabellen. Für eine gute Abfrageleistung empfehlen wir generell, Parquet- und ORC-Dateien größer als 100 MB zu verwenden.
Die Dateigröße wirkt sich auch auf die Abfrageplanung für Iceberg-Tabellen aus. Mit zunehmender Anzahl von Dateien in einer Tabelle nimmt auch die Größe der Metadatendateien zu. Größere Metadatendateien können zu einer langsameren Abfrageplanung führen. Wenn die Tabellengröße zunimmt, sollten Sie daher die Dateigröße erhöhen, um die exponentielle Erweiterung der Metadaten zu verringern.
Verwenden Sie die folgenden bewährten Methoden, um Dateien mit der richtigen Größe in Iceberg-Tabellen zu erstellen.
Legen Sie die Größe der Zieldatei und der Zeilengruppe fest
Iceberg bietet die folgenden wichtigen Konfigurationsparameter zur Optimierung des Layouts der Datendatei. Wir empfehlen, dass Sie diese Parameter verwenden, um die Zieldateigröße und die Zeilengruppen- oder Strike-Größe festzulegen.
Parameter |
Standardwert |
Kommentar |
|---|---|---|
|
512 MB |
Dieser Parameter gibt die maximale Dateigröße an, die Iceberg erstellen wird. Bestimmte Dateien können jedoch mit einer kleineren Größe als diesem Limit geschrieben werden. |
|
128 MB |
Sowohl Parquet als auch ORC speichern Daten in Blöcken, sodass Engines bei einigen Vorgängen vermeiden können, die gesamte Datei zu lesen. |
|
64 MB |
|
|
Keine, für Iceberg Version 1.1 und niedriger Hash, beginnend mit Iceberg Version 1.2 |
Iceberg fordert Spark auf, Daten zwischen seinen Aufgaben zu sortieren, bevor sie in den Speicher geschrieben werden. |
-
Basierend auf Ihrer erwarteten Tabellengröße sollten Sie sich an diese allgemeinen Richtlinien halten:
-
Kleine Tabellen (bis zu einigen Gigabyte) — Reduzieren Sie die Zieldateigröße auf 128 MB. Reduzieren Sie auch die Zeilengruppen- oder Stripe-Größe (z. B. auf 8 oder 16 MB).
-
Mittlere bis große Tabellen (von einigen Gigabyte bis zu Hunderten von Gigabyte) — Die Standardwerte sind ein guter Ausgangspunkt für diese Tabellen. Wenn Ihre Abfragen sehr selektiv sind, passen Sie die Zeilengruppen- oder Stripe-Größe an (z. B. auf 16 MB).
-
Sehr große Tabellen (Hunderte von Gigabyte oder Terabyte) — Erhöhen Sie die Zieldateigröße auf 1024 MB oder mehr und erwägen Sie, die Zeilengruppen- oder Stripe-Größe zu erhöhen, wenn Ihre Abfragen normalerweise große Datenmengen abrufen.
-
-
Um sicherzustellen, dass Spark-Anwendungen, die in Iceberg-Tabellen schreiben, Dateien mit der entsprechenden Größe erstellen, setzen Sie die
write.distribution-modeEigenschaft entweder auf oder.hashrangeEine ausführliche Erklärung des Unterschieds zwischen diesen Modi finden Sie in der Iceberg-Dokumentation unter Writing Distribution Modes.
Dies sind allgemeine Richtlinien. Wir empfehlen Ihnen, Tests durchzuführen, um die am besten geeigneten Werte für Ihre spezifischen Tabellen und Workloads zu ermitteln.
Führen Sie eine regelmäßige Komprimierung durch
Die Konfigurationen in der vorherigen Tabelle legen eine maximale Dateigröße fest, die Schreibaufgaben erzeugen können, garantieren jedoch nicht, dass Dateien diese Größe haben. Führen Sie die Komprimierung regelmäßig durch, um kleine Dateien zu größeren Dateien zusammenzufassen, um die richtigen Dateigrößen sicherzustellen. Eine ausführliche Anleitung zum Ausführen der Komprimierung finden Sie weiter unten in diesem Handbuch unter Iceberg-Komprimierung.
Optimieren Sie die Spaltenstatistiken
Iceberg verwendet Spaltenstatistiken, um Dateien zu bereinigen. Dadurch wird die Abfrageleistung verbessert, da die Datenmenge, die durch Abfragen gescannt wird, reduziert wird. Um von Spaltenstatistiken zu profitieren, stellen Sie sicher, dass Iceberg Statistiken für alle Spalten sammelt, die häufig in Abfragefiltern verwendet werden.
Standardmäßig sammelt Iceberg Statistiken nur für die ersten 100 Spalten in jeder Tabellewrite.metadata.metrics.max-inferred-column-defaults Wenn Ihre Tabelle mehr als 100 Spalten hat und Ihre Abfragen häufig auf Spalten außerhalb der ersten 100 Spalten verweisen (z. B. wenn Sie Abfragen haben, die nach Spalte 132 filtern), stellen Sie sicher, dass Iceberg Statistiken zu diesen Spalten sammelt. Um dies zu erreichen, gibt es zwei Möglichkeiten:
-
Wenn Sie die Iceberg-Tabelle erstellen, ordnen Sie die Spalten neu an, sodass die Spalten, die Sie für Abfragen benötigen, in den angegebenen Spaltenbereich fallen
write.metadata.metrics.max-inferred-column-defaults(Standard ist 100).Hinweis: Wenn Sie keine Statistiken für 100 Spalten benötigen, können Sie die
write.metadata.metrics.max-inferred-column-defaultsKonfiguration auf einen gewünschten Wert (z. B. 20) anpassen und die Spalten neu anordnen, sodass die Spalten, die Sie zum Lesen und Schreiben von Abfragen benötigen, in die ersten 20 Spalten auf der linken Seite des Datensatzes fallen. -
Wenn Sie in Abfragefiltern nur wenige Spalten verwenden, können Sie die allgemeine Eigenschaft für die Erfassung von Metriken deaktivieren und selektiv einzelne Spalten auswählen, für die Statistiken erfasst werden sollen, wie in diesem Beispiel gezeigt:
.tableProperty("write.metadata.metrics.default", "none") .tableProperty("write.metadata.metrics.column.my_col_a", "full") .tableProperty("write.metadata.metrics.column.my_col_b", "full")
Hinweis: Spaltenstatistiken sind am effektivsten, wenn die Daten nach diesen Spalten sortiert sind. Weitere Informationen finden Sie im Abschnitt „Sortierreihenfolge festlegen“ weiter unten in diesem Handbuch.
Wählen Sie die richtige Aktualisierungsstrategie
Verwenden Sie eine copy-on-write Strategie zur Optimierung der Leseleistung, wenn langsamere Schreibvorgänge für Ihren Anwendungsfall akzeptabel sind. Dies ist die von Iceberg verwendete Standardstrategie.
Copy-on-write führt zu einer besseren Leseleistung, da Dateien leseoptimiert direkt in den Speicher geschrieben werden. Im Vergleich merge-on-read zu dauert jeder Schreibvorgang jedoch länger und verbraucht mehr Rechenressourcen. Dies stellt einen klassischen Kompromiss zwischen Lese- und Schreiblatenz dar. In der Regel copy-on-write ist dies ideal für Anwendungsfälle, in denen die meisten Aktualisierungen in denselben Tabellenpartitionen gespeichert sind (z. B. für tägliche Batchladevorgänge).
Copy-on-write Konfigurationen (write.update.modewrite.delete.mode, undwrite.merge.mode) können auf Tabellenebene oder unabhängig voneinander auf der Anwendungsseite festgelegt werden.
Verwenden Sie die STD-Komprimierung
Sie können den von Iceberg verwendeten Komprimierungscodec mithilfe der Tabelleneigenschaft ändern. write.<file_type>.compression-codec Wir empfehlen, den ZSTD-Komprimierungscodec zu verwenden, um die Gesamtleistung von Tabellen zu verbessern.
Standardmäßig verwenden die Iceberg-Versionen 1.3 und früher die GZIP-Komprimierung, die im Vergleich zu ZSTD eine langsamere read/write Leistung bietet.
Hinweis: Einige Engines verwenden möglicherweise andere Standardwerte. Dies ist bei Iceberg-Tabellen der Fall, die mit Athena oder Amazon EMR Version 7.x erstellt wurden.
Legen Sie die Sortierreihenfolge fest
Um die Leseleistung bei Iceberg-Tabellen zu verbessern, empfehlen wir, dass Sie Ihre Tabelle nach einer oder mehreren Spalten sortieren, die häufig in Abfragefiltern verwendet werden. Durch Sortierung in Kombination mit den Spaltenstatistiken von Iceberg kann das Bereinigen von Dateien erheblich effizienter gestaltet werden, was zu schnelleren Lesevorgängen führt. Durch die Sortierung wird auch die Anzahl der Amazon S3 S3-Anfragen für Abfragen reduziert, die die Sortierspalten in Abfragefiltern verwenden.
Sie können eine hierarchische Sortierreihenfolge auf Tabellenebene festlegen, indem Sie eine DDL-Anweisung (Data Definition Language) mit Spark ausführen. Die verfügbaren Optionen finden Sie in der Iceberg-Dokumentation
In Tabellen, die nach Datum (yyyy-mm-dd) partitioniert sind, nach denen die meisten Abfragen filternuuid, können Sie beispielsweise die DDL-Option verwenden, Write Distributed By Partition Locally Ordered um sicherzustellen, dass Spark Dateien mit nicht überlappenden Bereichen schreibt.
Das folgende Diagramm zeigt, wie sich die Effizienz von Spaltenstatistiken verbessert, wenn Tabellen sortiert werden. In diesem Beispiel muss die sortierte Tabelle nur eine einzige Datei öffnen und profitiert optimal von der Partition und Datei von Iceberg. In der unsortierten Tabelle uuid kann jede Datei potenziell in jeder beliebigen Datendatei vorkommen, sodass die Abfrage alle Datendateien öffnen muss.
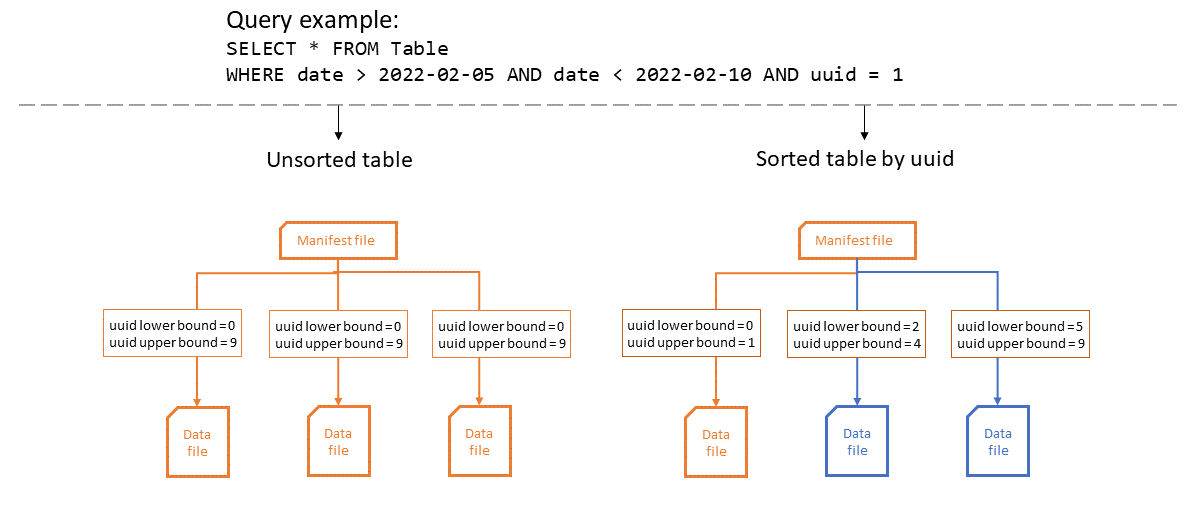
Das Ändern der Sortierreihenfolge hat keine Auswirkungen auf bestehende Datendateien. Sie können die Iceberg-Komprimierung verwenden, um die Sortierreihenfolge auf diese anzuwenden.
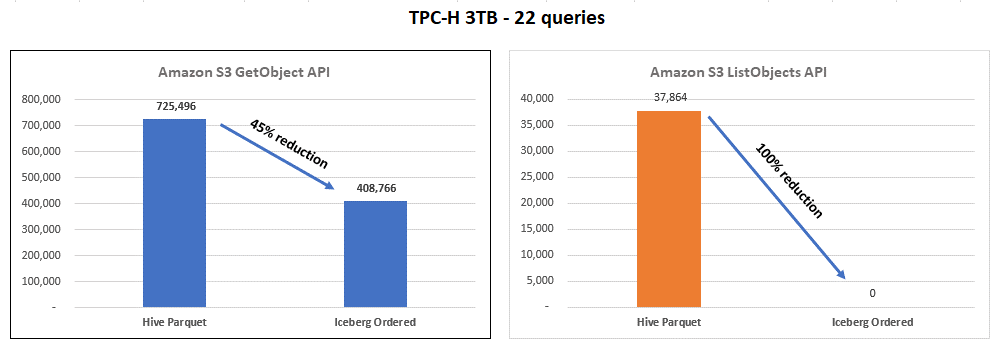
Die Verwendung von nach Iceberg sortierten Tabellen kann die Kosten für Ihre Arbeitslast senken, wie in der folgenden Grafik dargestellt.
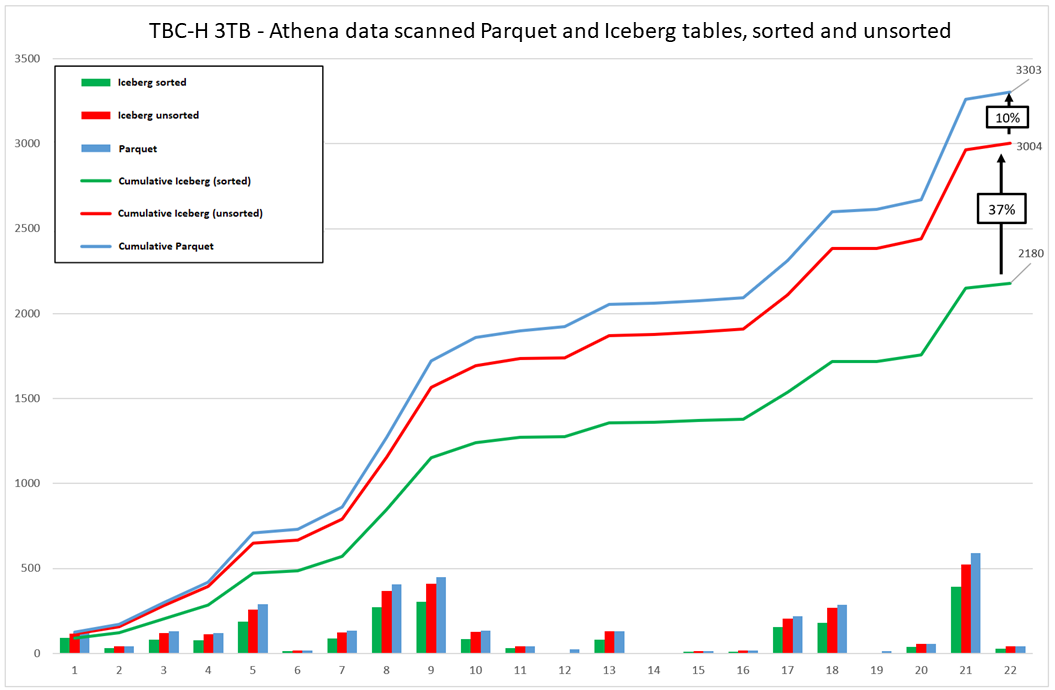
Diese Grafiken fassen die Ergebnisse der Durchführung des TPC-H-Benchmarks für Hive-Tabellen (Parquet) im Vergleich zu sortierten Iceberg-Tabellen zusammen. Bei anderen Datensätzen oder Workloads können die Ergebnisse jedoch anders ausfallen.