Unterstützung für die Verbesserung dieser Seite beitragen
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Um zu diesem Benutzerhandbuch beizutragen, wählen Sie den GitHub Link Diese Seite bearbeiten auf, der sich im rechten Bereich jeder Seite befindet.
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Amazon EKS-Cluster für AI/ML Workloads mithilfe von CLIs einrichten
Tipp
Melden Sie sich
Dieser Abschnitt führt Sie durch die Schritte zum Erstellen der Infrastruktur, die für die Ausführung von Trainings- oder Inferenz-Workloads auf Amazon EKS über CLI-Befehle erforderlich ist. Die Schritte umfassen die Erstellung eines EKS-Clusters, von GPU-enabled Knoten mit EKS Auto Mode oder Karpenter, eines Monitoring-Stacks mit Prometheus und Grafana sowie Amazon S3 S3-Speicher für Modellgewichte.
Weitere Informationen darüber, wie diese Funktionen EC2-Instances in EKS-Clustern bereitstellen und automatisch skalieren, finden Sie in der Dokumentation für EKS Auto Mode und Karpenter
High-level Architektur und Arbeitsablauf
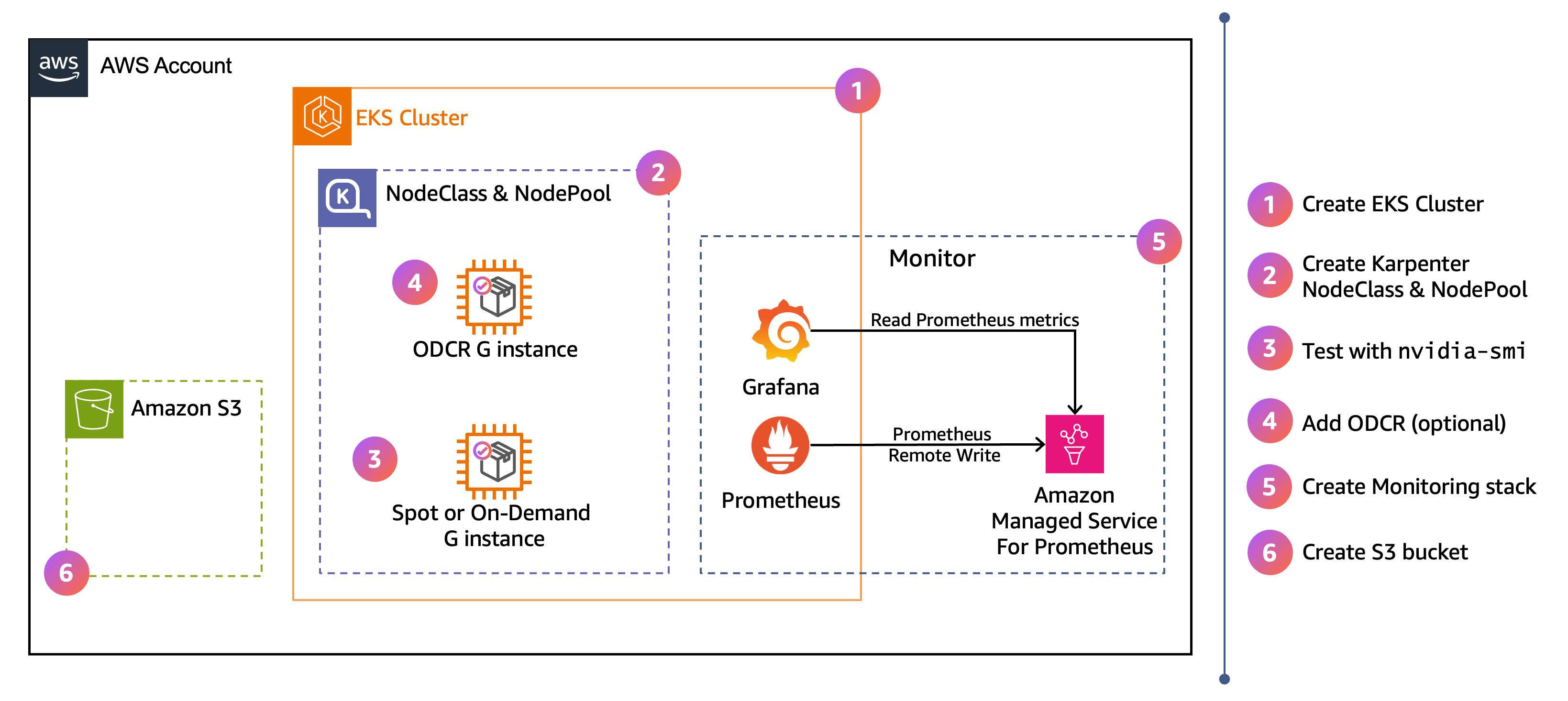
Das Diagramm zeigt die allgemeine Architektur für die Einrichtung dieses AWS Abschnitts. Die nummerierten Schritte auf der rechten Seite geben die Reihenfolge an, in der Sie die Konfiguration in den folgenden Schritten abschließen.
Voraussetzungen
-
kubectl>= 1,35. Anweisungen zur Einrichtung finden Sie unter. Kubectl und eksctl einrichten -
AWS CLI >= 2,27. Anweisungen zur Einrichtung finden Sie unter Installation.
-
Helm >= 3.14. Anweisungen zur Einrichtung finden Sie unter Setup Helm.
-
jq. Anweisungen zur Einrichtung finden Sie unter Laden Sie jqherunter. -
eksctl>= 0.227.0. Anweisungen zur Einrichtung finden Sie in der Dokumentation unter Installation. eksctl
Überprüfen Sie Ihre eksctl Version:
eksctl version
Wenn Sie eine ältere Version als 0.227.0 verwenden, folgen Sie der eksctl-Installationsanleitung
Festlegen von Umgebungsvariablen
Halten Sie den folgenden Clusternamen und die AWS Region während dieser Schritte einheitlich. Eine Änderung kann dazu führen, dass nachfolgende Befehle auf den falschen EKS-Cluster abzielen.
export CLUSTER_NAME=ai-eks-docs export AWS_REGION=us-east-2
Die Verwendung aller verfügbaren AZs verbessert die Fehlertoleranz und erhöht die Wahrscheinlichkeit, GPU-Kapazität zu erhalten:
export AZS=$(aws ec2 describe-availability-zones \ --region ${AWS_REGION} \ --query "AvailabilityZones[?ZoneId!='use1-az3' && ZoneId!='usw1-az2' && ZoneId!='cac1-az3'].ZoneName" \ --output text | tr '\t' ',') echo $AZS
Wichtig
Die Availability Zones use1-az3usw1-az2, und cac1-az3 sind ausgeschlossen, da Amazon EKS die Platzierung von Kontrollebenen in diesen Zonen nicht unterstütztUnsupportedAvailabilityZoneException.
Erwartete Ausgabe:
us-east-2a,us-east-2b,us-east-2c
Die AZs in der Ausgabe variieren je nach Region. Dieses Beispiel zeigt die verfügbaren AZs für die us-east-2 Region.
Cluster und GPU erstellen NodePool
Dieser Abschnitt enthält zwei Pfade zum Erstellen Ihres EKS-Clusters und Ihrer GPU-enabled EKS-Knoten, die in der folgenden Abbildung dargestellt sind. Wählen Sie im gesamten Handbuch nur eine Option aus.
-
EKS-Automatikmodus — Zusätzlich zu den Kern-Add-Ons für Netzwerke, Speicher und Lastausgleich umfasst und verwaltet der EKS Auto Mode die folgenden Funktionen für Trainings- und Inferenz-Workloads: EKS-Node-Monitoring-Agent, automatische Knotenreparatur, SOCI-Snapshotter
für schnelle Container-Pulls und GPU-Bereitschaft für die Standardeinstellung. NodeClass Das NVIDIA-Geräte-Plugin ist im Bottlerocket-beschleunigten AMI enthalten, das EKS Auto Mode für Knoten verwendet. GPU-enabled -
Self-managed Karpenter — Auf einem EKS-Cluster ohne EKS-Automatikmodus sind Sie für die Installation und Konfiguration der Komponenten verantwortlich, die für Trainings- und Inferenz-Workloads erforderlich sind. Dazu gehören Netzwerk-Add-Ons (VPC CNI, CoreDNS, Kube-Proxy), Karpenter, der EKS-Node-Monitoring-Agent, das NVIDIA-Geräte-Plugin und SOCI-Snapshotter für schnelle Container-Pulls.
EKS-Cluster-Optionen: EKS-Automatikmodus und selbstverwaltetes Karpenter
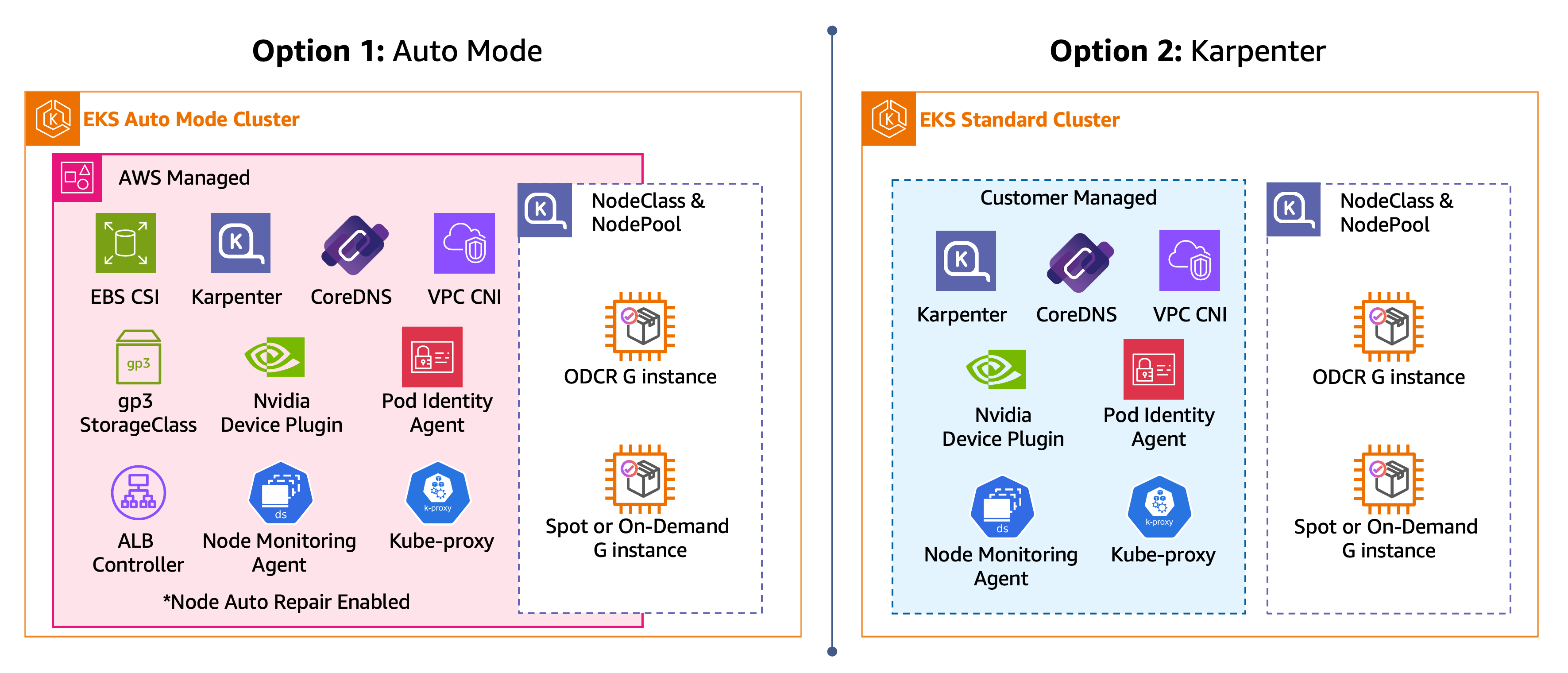
Wählen Sie in jedem der folgenden Schritte einen Pfad (EKS Auto Mode, Karpenter) und folgen Sie ihm durchgehend. Nachdem Sie die Schritte für den von Ihnen ausgewählten Pfad abgeschlossen haben, verfügen Sie über einen EKS-Cluster mit einer GPU, die NodePool bereit ist, GPU-Workloads zu planen.
Schritt 1: Cluster erstellen
Erstellen Sie zunächst Ihren EKS-Cluster und installieren Sie die Cluster-Komponenten, die für GPU-Workloads benötigt werden.
Im EKS-Automatikmodus stellt ein einziger eksctl create cluster --enable-auto-mode Befehl einen EKS-Cluster bereit, der für GPU-Workloads bereit ist.
Bei selbstverwaltetem Karpenter stellt der eksctl create cluster Befehl die wichtigsten Netzwerk-Add-Ons bereit. Anschließend sind weitere Schritte erforderlich, um die automatische Knotenreparatur über ein Karpenter Feature Gate zu aktivieren, den EKS-Node-Monitoring-Agenten zu installieren und das NVIDIA-Geräte-Plugin zu installieren.
Warnung
Sowohl für den automatischen EKS-Modus als auch für die selbstverwalteten Karpenter-Pfade verhält sich die automatische Knotenreparatur für Knoten, die von bereitgestellt wurden, genauso. NodePools Die automatische Knotenreparatur im EKS-Automodus und in Karpenter ist eine Methode, bei der die Notation und umgangen wird. PodDisruptionBudgets karpenter.sh/do-not-disrupt terminationGracePeriod Die automatische Knotenreparatur wartet 10 Minuten, bevor ein Knoten ersetzt wird, für den die AcceleratedHardwareReady Bedingung auf eingestellt ist, False und 30 Minuten für andere Reparaturbedingungen.
Schritt 2: Dynamische GPU erstellen NodePool
Definieren Sie eine NodePool , die G-family GPU-Instances mit einer Generation von mehr als 4 dynamisch bereitstellt und Spot-Kapazität On-Demand als Fallback verwendet. Der EKS-Automodus und der Karpenter-Pfad verwenden beide dieselbe NodePool API, mit dem einzigen Unterschied, dass NodeClass sie darauf verweist. Im EKS-Automodus wählt das Paket default NodeClass bereits das richtige AMI aus und konfiguriert den SOCI-Parallel-Pull, sodass es das einzige Objekt NodePool ist, das Sie erstellen. In selbstverwaltetem Karpenter benötigen Sie außerdem ein benutzerdefiniertes System, EC2NodeClass das das AMI anheftet und SOCI optimiert.
Bestätigen Sie, NodePool dass das erstellt wurde:
kubectl get nodepool gpu-inf
Erwartete Ausgabe:
NAME NODECLASS NODES READY AGE gpu-inf default 0 True 8s
Auf dem selbstverwalteten Karpenter-Pfad wird in der Spalte NODECLASS anstelle von angezeigt. gpu-inf default
Schritt 3: Testen Sie mit einem Beispiel-Pod
Testen Sie Ihr NodePool GPU-Setup mit einem nvidia-smi Pod.
cat << EOF | kubectl apply -f - apiVersion: v1 kind: Pod metadata: name: nvidia-smi labels: guide: ai-eks-docs spec: tolerations: - key: "nvidia.com/gpu" operator: "Exists" effect: "NoSchedule" containers: - name: nvidia-smi image: public.ecr.aws/amazonlinux/amazonlinux:2023-minimal command: ["nvidia-smi"] resources: limits: nvidia.com/gpu: 1 restartPolicy: OnFailure EOF
Stellen Sie sicher, dass der Pod geplant und erfolgreich abgeschlossen wurde.
kubectl get pods
Erwartete Ausgabe:
NAME READY STATUS RESTARTS AGE nvidia-smi 0/1 Completed 0 67s
STATUS: Abgeschlossen bedeutet, dass der Befehl nvidia-smi ausgeführt und beendet wurde. Sehen Sie in den Pod-Protokollen nach, welche GPU vom Knoten erkannt wurde.
kubectl logs nvidia-smi
Erwartete Ausgabe:
+-----------------------------------------------------------------------------------------+ | NVIDIA-SMI 580.126.09 Driver Version: 580.126.09 CUDA Version: 13.0 | +-----------------------------------------+------------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+========================+======================| | 0 NVIDIA RTX PRO 6000 Blac... On | 00000000:2B:00.0 Off | 0 | | N/A 30C P0 81W / 600W | 0MiB / 97887MiB | 0% Default | | | | Disabled | +-----------------------------------------+------------------------+----------------------+
Die Ausgabe zeigt das GPU-Modell, die Treiberversion, die CUDA-Version und den verfügbaren Speicher. In diesem Beispiel hat Karpenter eine G7e-Instanz bereitgestellt, die über eine NVIDIA RTX PRO 6000 Blackwell-GPU mit 96 GB Arbeitsspeicher verfügt. 30C ist die aktuelle GPU-Temperatur und P0 bedeutet, dass sich die GPU im Zustand mit der höchsten Leistung befindet (inaktiv, aber bereit). 81 W/600 W zeigen die aktuelle Leistungsaufnahme im Vergleich zur maximalen Leistungskapazität, und 0 MiB /97887 MiB zeigt den aktuell genutzten GPU-Speicher im Vergleich zum verfügbaren Gesamtspeicher an. Da der Pod gerade nvidia-smi ausgeführt und beendet wurde, verwendet kein Workload die GPU, sodass der Arbeitsspeicher auf 0 und die Stromversorgung im Leerlauf ist. Die NVIDIA-GPU-Treiberversion (580.126.09) stammt aus dem Bottlerocket AMI, während die CUDA-Version (13.0) aus dem Container-Image stammt. Das GPU-Modell und der Arbeitsspeicher variieren je nach Instance-Typ, den Karpenter auswählt. G5-Instances verfügen über NVIDIA A10G-GPUs (24 GB), G6e-Instances über NVIDIA L40S-GPUs (48 GB) und G7e-Instances über NVIDIA RTX PRO 6000-GPUs (96 GB).
Um zu verstehen, wie Karpenter und der Kubernetes-Scheduler die Bereitstellung eines Knotens und die Platzierung des Pods koordiniert haben, überprüfen Sie die Lebenszyklusereignisse des Pods:
kubectl describe po nvidia-smi
Erwartete Ausgabe:
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedScheduling 60s default-scheduler 0/2 nodes are available: 2 node(s) had untolerated taint(s). no new claims to deallocate, preemption: 0/2 nodes are available: 2 Preemption is not helpful for scheduling. Normal Nominated 59s eks-auto-mode/compute Pod should schedule on: nodeclaim/gpu-inf-vxcnj Normal Scheduled 24s default-scheduler Successfully assigned default/nvidia-smi to i-0fb17a09bc4203164 Warning FailedCreatePodSandBox 21s kubelet Failed to create pod sandbox: rpc error: code = Unknown desc = failed to setup network for sandbox "7f85e25b220c8fb245187758dbbbc8efb3d40f3e49e13054404880daf4c3b2f0": plugin type="aws-cni" name="aws-cni" failed (add): add cmd: failed to setup network policy Normal Pulling 7s kubelet spec.containers{nvidia-smi}: Pulling image "public.ecr.aws/amazonlinux/amazonlinux:2023-minimal" Normal Pulled 5s kubelet spec.containers{nvidia-smi}: Successfully pulled image "public.ecr.aws/amazonlinux/amazonlinux:2023-minimal" in 1.237s (1.237s including waiting). Image size: 37442701 bytes. Normal Created 5s kubelet spec.containers{nvidia-smi}: Container created Normal Started 5s kubelet spec.containers{nvidia-smi}: Container started
Diese Ereignisse zeigen die Reihenfolge der Pod-Planung: Der Pod kann zunächst nicht geplant werden, weil keine GPU-Knoten vorhanden sind (FailedScheduling), Karpenter nominiert einen neuen Pod NodeClaim (Nominiert), der Scheduler weist den Pod zu, sobald der Knoten bereit ist (geplant), und dann wird das Container-Image abgerufen und gestartet. Im EKS-Automatikmodus ist der parallel SOCI (Seekable OCI) -Pull standardmäßig auf G-, P- und Trn-Instances installiert und konfiguriert. Beachten Sie, dass das Container-Image aufgrund des parallel SOCI-Pulls in weniger als 2 Sekunden (1,237 Sekunden) aus dem ECR abgerufen wurde.
A NodeClaim ist eine Anfrage, die Karpenter erstellt, um einen bestimmten Knoten bereitzustellen. Es zeigt den Instanztyp, den Kapazitätstyp, AZ und ob der Knoten bereit ist.
kubectl get nodeclaims
Erwartete NodeClaim Ausgabe:
NAME TYPE CAPACITY ZONE NODE READY AGE gpu-inf-xxxxx g7e.2xlarge spot us-east-2a i-0xxxxxxxxxxxx True 2m
Der Instanztyp und die AZ variieren. Jede G-family Instance mit Generation > 4 ist berechtigt.
Die FailedCreatePodSandBox eingegebene Warnung kubectl describe pod nvidia-smi ist vorübergehend und wird erwartet. Die VPC-CNI wird asynchron initialisiert, nachdem der Knoten beigetreten ist, und das Kubelet versucht es automatisch erneut. Wenn der Pod eingeschaltet bleibt, überprüfen Sie die Knotenereignisse mit. ContainerCreating kubectl describe node <node-name>
Tipp
Wenn kein Knoten angezeigt wird, suchen Sie nach Fehlern mit unzureichender Kapazität:
kubectl get events | grep InsufficientCapacityError
Karpenter speichert nicht verfügbare Angebote 3 Minuten lang im Cache. Wenn Sie die zulässigen Instance-Typen und AZs in Ihrem System erweitern, NodePool erhöhen Sie die Wahrscheinlichkeit, dass Sie Kapazität erhalten.
Anmerkung
Von Karpenter gestartete Spot-Instances werden nicht in der EC2 Spot Requests-Konsole angezeigt. Karpenter verwendet die EC2-API mit. CreateFleettype: instant Die Instances werden in der EC2-Instanzen-Konsole mit einem Lebenszyklus angezeigt. spot
Schritt 4: Reservierte Kapazität zur hinzufügen NodePool (optional)
Um reservierte Kapazität zunächst mit Spot/On-Demand Fallback zu verwenden, erstellen Sie eine On-Demand Kapazitätsreservierung (ODCR) und fügen Sie sie Ihrer hinzu. Aktualisieren Sie dann die Dynamik NodePool aus Schritt 2 NodeClass, um auch Kapazität zuzulassenreserved. Der Reservierungs-API-Aufruf ist für beide Pfade derselbe. Der NodeClass Anhang unterscheidet sich, da EKS Auto Mode und selbstverwaltetes Karpenter unterschiedliche Typen verwenden. NodeClass
Warnung
Der folgende Befehl führt zu einer Gebühr für den Reserved Instance-Typ, bis Sie ihn mit kündigen. aws ec2 cancel-capacity-reservation --capacity-reservation-id <id>
Erstellen Sie die Kapazitätsreservierung:
CR_AZ="us-east-2a" INSTANCE_TYPE="g6e.4xlarge" aws ec2 create-capacity-reservation \ --instance-type $INSTANCE_TYPE \ --instance-platform Linux/UNIX \ --availability-zone "$CR_AZ" \ --instance-count 1 \ --instance-match-criteria open \ --end-date-type unlimited
Wenn Sie eine InsufficientInstanceCapacity Fehlermeldung erhalten, wechseln Sie CR_AZ zu einer anderen AZ und versuchen Sie es erneut.
Suchen Sie die Kapazitätsreservierungs-ID und speichern Sie sie in einer Shell-Variablen für die folgenden Schritte:
CAPACITY_RESERVATION_ID=$(aws ec2 describe-capacity-reservations \ --filters "Name=state,Values=active" "Name=instance-type,Values=${INSTANCE_TYPE}" \ --query 'CapacityReservations[0].CapacityReservationId' \ --output text \ --region ${AWS_REGION}) echo "Capacity reservation ID: ${CAPACITY_RESERVATION_ID}"
Wenden Sie dann die NodePool Änderungen NodeClass und für Ihren Pfad an:
Karpenter betrachtet es reserved als die kostengünstigste Option und bringt sie zuerst auf den Markt. Sobald die Reservierung voll ist, fällt sie zurück an Spot oder. On-Demand
Nachdem Sie die Änderungen übernommen haben, überprüfen Sie, ob Karpenter der reservierten Kapazität Priorität einräumt und auf Spot oder zurückgreift. On-Demand Stellen Sie eine Bereitstellung mit zwei Replikaten bereit, für die 1 GPU pro Pod erforderlich ist. Das ODCR ist für eine Instanz vorgesehen, sodass der erste Pod Karpenter veranlasst, einen reservierten Knoten zu starten. Der zweite Pod passt nicht auf den reservierten Knoten und veranlasst Karpenter, einen anderen Knoten von Spot oder Kapazität aus zu starten. On-Demand
cat << 'EOF' | kubectl apply -f - apiVersion: apps/v1 kind: Deployment metadata: name: gpu-overflow-test labels: guide: ai-eks-docs spec: replicas: 2 selector: matchLabels: app: gpu-overflow-test template: metadata: labels: app: gpu-overflow-test guide: ai-eks-docs spec: tolerations: - key: nvidia.com/gpu operator: Exists effect: NoSchedule containers: - name: nvidia-smi image: public.ecr.aws/amazonlinux/amazonlinux:2023-minimal command: ["sh", "-c", "nvidia-smi && sleep infinity"] resources: limits: nvidia.com/gpu: 1 EOF
Im Gegensatz zum nvidia-smi Test-Pod aus Schritt 3, der ausgeführt und beendet wurde, laufen bei diesem Deployment die Pods weiter (sleep infinity), sodass sie die GPU aufnehmen und den Knoten nicht freigeben.
Überprüfen Sie, ob die Pods auf verschiedenen Knoten geplant sind:
kubectl get pods -l app=gpu-overflow-test -o wide
Erwartete Ausgabe:
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES gpu-overflow-test-59b97944fb-lq56c 1/1 Running 0 2m42s 192.168.186.240 i-057692590480155da <none> <none> gpu-overflow-test-59b97944fb-z4zcx 1/1 Running 0 2m42s 192.168.130.64 i-0521ecd1849fa0578 <none> <none>
Die beiden Pods werden ausgeführt, jeder auf einem anderen Knoten.
Überprüfen Sie NodeClaims , um die Kapazitätstypen zu sehen:
kubectl get nodeclaims
Erwartete Ausgabe:
NAME TYPE CAPACITY ZONE NODE READY AGE gpu-inf-shg5w g6e.xlarge reserved us-east-2a i-0ea91fdeef65b8cb6 True 2m2s gpu-inf-ssnqf g7e.2xlarge spot us-east-2b i-00ccf7ce65cf3f6ca True 112s
Der reservierte Knoten wurde zuerst gestartet, gefolgt von einem Spot oder On-Demand Knoten, sobald die Reservierung voll war.
Bereinigen Sie die Testbereitstellung:
kubectl delete deployment gpu-overflow-test
Überwachen
Installieren Sie einen Monitoring-Stack, der Cluster-, Knoten- und GPU-Metriken erfasst, in Amazon Managed Service for Prometheus (AMP) und visualisieren Sie sie mit Grafana. Das kube-prometheus-stack Helm-Diagramm verwendet Prometheus zum Scrapen und Remote-Schreiben von Metriken in AMP sowie ein selbstverwaltetes Grafana für Dashboards. Der NVIDIA DCGM Exporter fügt Metriken hinzu (Auslastung, Arbeitsspeicher, Temperatur, Leistung, NVLink, Tensoraktivität). GPU-specific
Prometheus, Grafana und der Operator landen standardmäßig auf Nicht-GPU-Knoten, weil GPU-Knoten den Makel tragen. nvidia.com/gpu:NoSchedule Node-exporter und der DCGM Exporter laufen beide auf GPU-Knoten, sodass wir Host- und GPU-Metriken flottenweit durchsuchen können.
Wenn Sie ein neues Terminal geöffnet haben, legen Sie den Clusternamen und die Region fest:
export CLUSTER_NAME=ai-eks-docs export AWS_REGION=us-east-2
Erstellen Sie den AMP-Workspace
Erstelle einen AMP-Workspace zum Speichern von Metriken:
aws amp create-workspace \ --alias "amp-ws-${CLUSTER_NAME}" \ --region ${AWS_REGION}
Hol dir die Workspace-ID:
AMP_WORKSPACE_ID=$(aws amp list-workspaces \ --alias "amp-ws-${CLUSTER_NAME}" \ --query 'workspaces[0].workspaceId' \ --output text \ --region ${AWS_REGION}) echo "AMP Workspace ID: ${AMP_WORKSPACE_ID}"
Holen Sie sich den Remote-Write-Endpunkt:
AMP_ENDPOINT=$(aws amp describe-workspace \ --workspace-id ${AMP_WORKSPACE_ID} \ --query 'workspace.prometheusEndpoint' \ --output text \ --region ${AWS_REGION}) echo "AMP Endpoint: ${AMP_ENDPOINT}"
Erstellen Sie IAM-Richtlinien- und EKS Pod Identity-Verknüpfungen
Erstellen Sie eine IAM-Richtlinie, die es Prometheus ermöglicht, Metriken per Fernzugriff zu schreiben und Grafana sie abzufragen:
ACCOUNT_ID=$(aws sts get-caller-identity --query Account --output text) AMP_POLICY_ARN=$(aws iam create-policy \ --policy-name "${CLUSTER_NAME}-amp-grafana-policy" \ --policy-document "{\"Version\": \"2012-10-17\", \"Statement\": [{\"Sid\": \"AllowAMPReadWrite\", \"Effect\": \"Allow\", \"Action\": [\"aps:ListWorkspaces\", \"aps:DescribeWorkspace\", \"aps:GetMetricMetadata\", \"aps:GetSeries\", \"aps:QueryMetrics\", \"aps:RemoteWrite\", \"aps:GetLabels\"], \"Resource\": \"arn:aws:aps:${AWS_REGION}:${ACCOUNT_ID}:workspace/*\"}, {\"Sid\": \"AllowCloudWatchMetrics\", \"Effect\": \"Allow\", \"Action\": [\"cloudwatch:DescribeAlarmsForMetric\", \"cloudwatch:ListMetrics\", \"cloudwatch:GetMetricData\", \"cloudwatch:GetMetricStatistics\"], \"Resource\": \"*\"}]}" \ --query 'Policy.Arn' \ --output text) echo "AMP Policy ARN: ${AMP_POLICY_ARN}"
Erstellen Sie den Monitoring-Namespace und die Dienstkonten für Prometheus und Grafana:
kubectl create namespace monitoring kubectl create serviceaccount amp-iamproxy-ingest-service-account -n monitoring kubectl create serviceaccount grafana-sa -n monitoring
Erstellen Sie EKS Pod Identity Associations, um die Dienstkonten mit der IAM-Richtlinie zu verknüpfen:
eksctl create podidentityassociation \ --cluster ${CLUSTER_NAME} \ --namespace monitoring \ --service-account-name amp-iamproxy-ingest-service-account \ --role-name "${CLUSTER_NAME}-amp-ingest-role" \ --permission-policy-arns ${AMP_POLICY_ARN} \ --region ${AWS_REGION} eksctl create podidentityassociation \ --cluster ${CLUSTER_NAME} \ --namespace monitoring \ --service-account-name grafana-sa \ --role-name "${CLUSTER_NAME}-grafana-role" \ --permission-policy-arns ${AMP_POLICY_ARN} \ --region ${AWS_REGION}
Stellen Sie sicher, dass beide EKS Pod Identity-Verknüpfungen erstellt wurden:
eksctl get podidentityassociation --cluster ${CLUSTER_NAME} --region ${AWS_REGION}
Die erwartete Ausgabe sollte amp-iamproxy-ingest-service-account sowohl als auch grafana-sa im monitoring Namespace enthalten.
Installieren Sie kube-prometheus-stack
Füge das Helm-Repo hinzu:
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts helm repo update
In dieser Wertedatei wird ein NodeSelector für Prometheus, Grafana und den Operator weggelassen: Der nvidia.com/gpu:NoSchedule Makel der GPU-Knoten hält sie von den GPU-Knoten fern, sodass sie standardmäßig auf dem System oder dem Allzweckpool landen. Node-exporter verwendet eine Platzhalter-Toleranz, sodass sie auf jedem Knoten — auch auf GPU-Knoten — ausgeführt wird, um Metriken flottenweit zu sammeln.
Erstellen Sie die Wertedatei:
Beispiel Kube-Prometheus-Stack-Wertedatei
cat << EOF > /tmp/kube-prometheus-values.yaml alertmanager: enabled: false prometheus-adapter: enabled: false prometheus: serviceAccount: create: false name: amp-iamproxy-ingest-service-account prometheusSpec: serviceAccountName: amp-iamproxy-ingest-service-account enableRemoteWriteReceiver: true retention: 2h scrapeInterval: 30s evaluationInterval: 30s podMonitorSelectorNilUsesHelmValues: false serviceMonitorSelectorNilUsesHelmValues: false resources: requests: cpu: 500m memory: 1Gi limits: memory: 8Gi remoteWrite: - url: "${AMP_ENDPOINT}api/v1/remote_write" sigv4: region: "${AWS_REGION}" queueConfig: maxSamplesPerSend: 1000 maxShards: 200 capacity: 2500 nodeSelector: node-role: system prometheusOperator: resources: requests: cpu: 100m memory: 128Mi limits: memory: 256Mi nodeSelector: node-role: system admissionWebhooks: patch: nodeSelector: node-role: system kube-state-metrics: resources: requests: cpu: 50m memory: 128Mi limits: memory: 512Mi nodeSelector: node-role: system grafana: enabled: true serviceAccount: create: false name: grafana-sa resources: requests: cpu: 100m memory: 256Mi limits: memory: 1Gi nodeSelector: node-role: system grafana.ini: auth.sigv4: enabled: true sidecar: datasources: defaultDatasourceEnabled: false plugins: - grafana-amazonprometheus-datasource additionalDataSources: - name: Amazon-Managed-Prometheus type: grafana-amazonprometheus-datasource access: proxy url: "${AMP_ENDPOINT}" isDefault: true jsonData: sigV4Auth: true defaultRegion: "${AWS_REGION}" sigV4Region: "${AWS_REGION}" editable: true dashboardProviders: dashboardproviders.yaml: apiVersion: 1 providers: - name: default orgId: 1 folder: 'GPU Monitoring' type: file disableDeletion: false editable: true options: path: /var/lib/grafana/dashboards/default dashboards: default: nvidia-dcgm: gnetId: 25261 revision: 1 datasource: - name: DS_PROMETHEUS value: Amazon-Managed-Prometheus vllm: gnetId: 25263 revision: 1 datasource: - name: DS_PROMETHEUS value: Amazon-Managed-Prometheus vllm-load-analysis: gnetId: 25494 revision: 1 datasource: - name: DS_PROMETHEUS value: Amazon-Managed-Prometheus prometheus-node-exporter: resources: requests: cpu: 50m memory: 64Mi limits: memory: 128Mi tolerations: - operator: Exists EOF
Überprüfen Sie, ob die Variablen korrekt gefüllt wurden:
grep -E "url:|region:" /tmp/kube-prometheus-values.yaml
Du solltest die vollständige AMP-Endpunkt-URL (beginnend mithttps://aps-workspaces…) und deine Region sehen. Wenn eine davon leer ist, exportiere die Variablen erneut und erstelle die Datei neu.
Installieren Sie das Diagramm:
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack \ --namespace monitoring \ -f /tmp/kube-prometheus-values.yaml
Stellen Sie sicher, dass die Pods laufen:
kubectl get pods -n monitoring
Erwartete Ausgabe:
NAME READY STATUS RESTARTS AGE kube-prometheus-stack-grafana-7c58f54f77-rftrj 3/3 Running 0 4m kube-prometheus-stack-kube-state-metrics-d68dcbc84-5smxq 1/1 Running 0 4m kube-prometheus-stack-operator-5895df479f-ttm47 1/1 Running 0 4m kube-prometheus-stack-prometheus-node-exporter-t9q7s 1/1 Running 0 4m kube-prometheus-stack-prometheus-node-exporter-x6vfb 1/1 Running 0 4m prometheus-kube-prometheus-stack-prometheus-0 2/2 Running 0 4m
Der Stack stellt die folgenden Komponenten bereit:
-
Prometheus (StatefulSet): scrapiert Metriken und schreibt sie per Fernzugriff in AMP
-
Grafana: Dashboards und Visualisierung, vorkonfiguriert mit der AMP-Datenquelle
-
kube-state-metrics: generiert Metriken zum Kubernetes-Objektstatus (Pod-Status, Ressource, Status) requests/limits NodeClaim
-
node-exporter (DaemonSet, einer pro Knoten): sammelt Metriken auf Host-Ebene (CPU, Arbeitsspeicher, Festplatte, Netzwerk)
-
operator: verwaltet die benutzerdefinierten Ressourcen von Prometheus und Alertmanager
Alertmanager ist in diesem Setup deaktiviert.
Zugang zu Grafana
Öffnen Sie ein separates Terminal und leiten Sie den Port weiter, um auf Grafana zuzugreifen:
kubectl port-forward svc/kube-prometheus-stack-grafana 3000:80 -n monitoring
Öffnen Sie http://localhost:3000admin und dem Passwort des folgenden Befehls an:
kubectl --namespace monitoring get secrets kube-prometheus-stack-grafana -o jsonpath="{.data.admin-password}" | base64 -d ; echo
Um zu überprüfen, ob die Metrik-Pipeline durchgehend funktioniert:
-
Navigieren Sie zu Verbindungen > Datenquellen und vergewissern Sie
Amazon-Managed-Prometheussich, dass sie als Standarddatenquelle aufgeführt ist.Validieren Sie die AMP-Datenquelle in Grafana
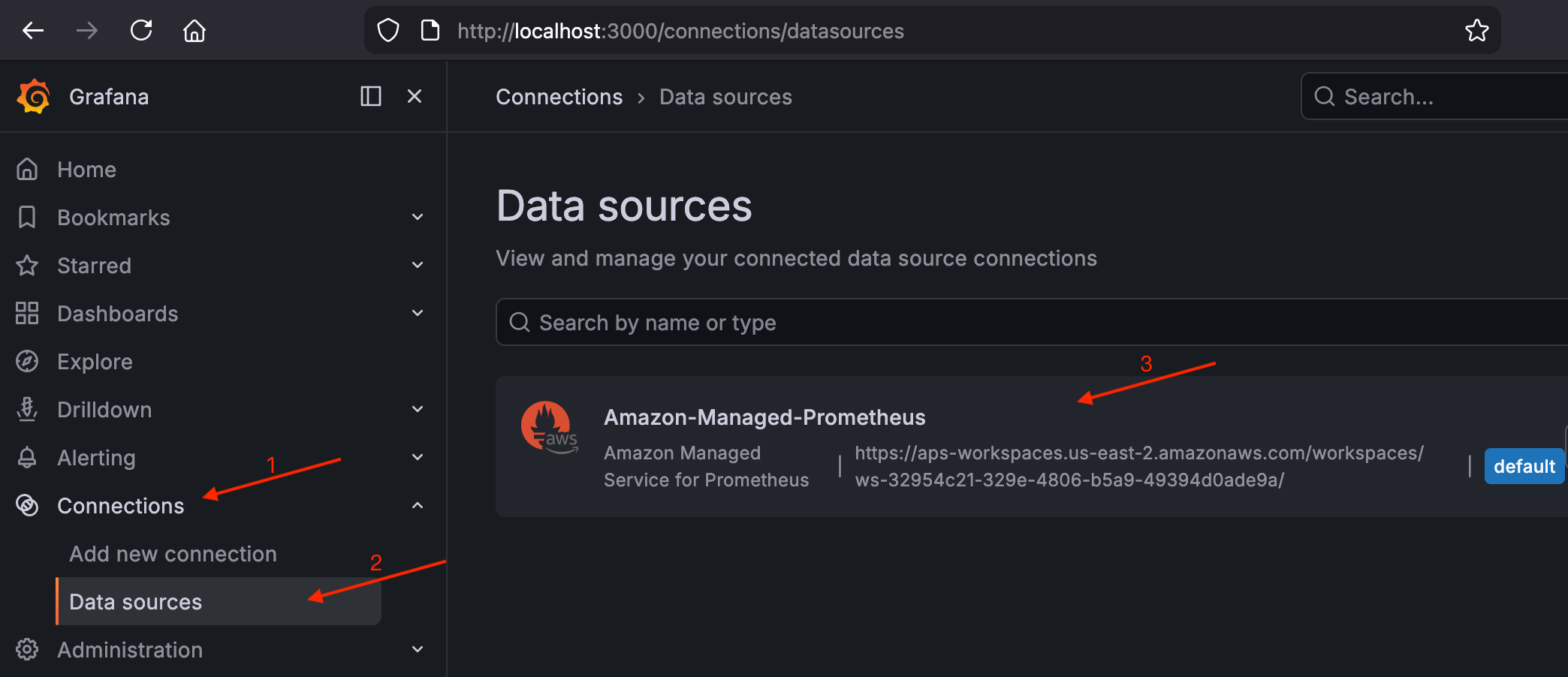
-
Navigieren Sie zu Drilldown > Metriken und suchen Sie nach der Metrik.
upSie sollten die Ergebnisse der Scrape-Ziele Ihres Clusters sehen.Validieren Sie die
upMetrik in Grafana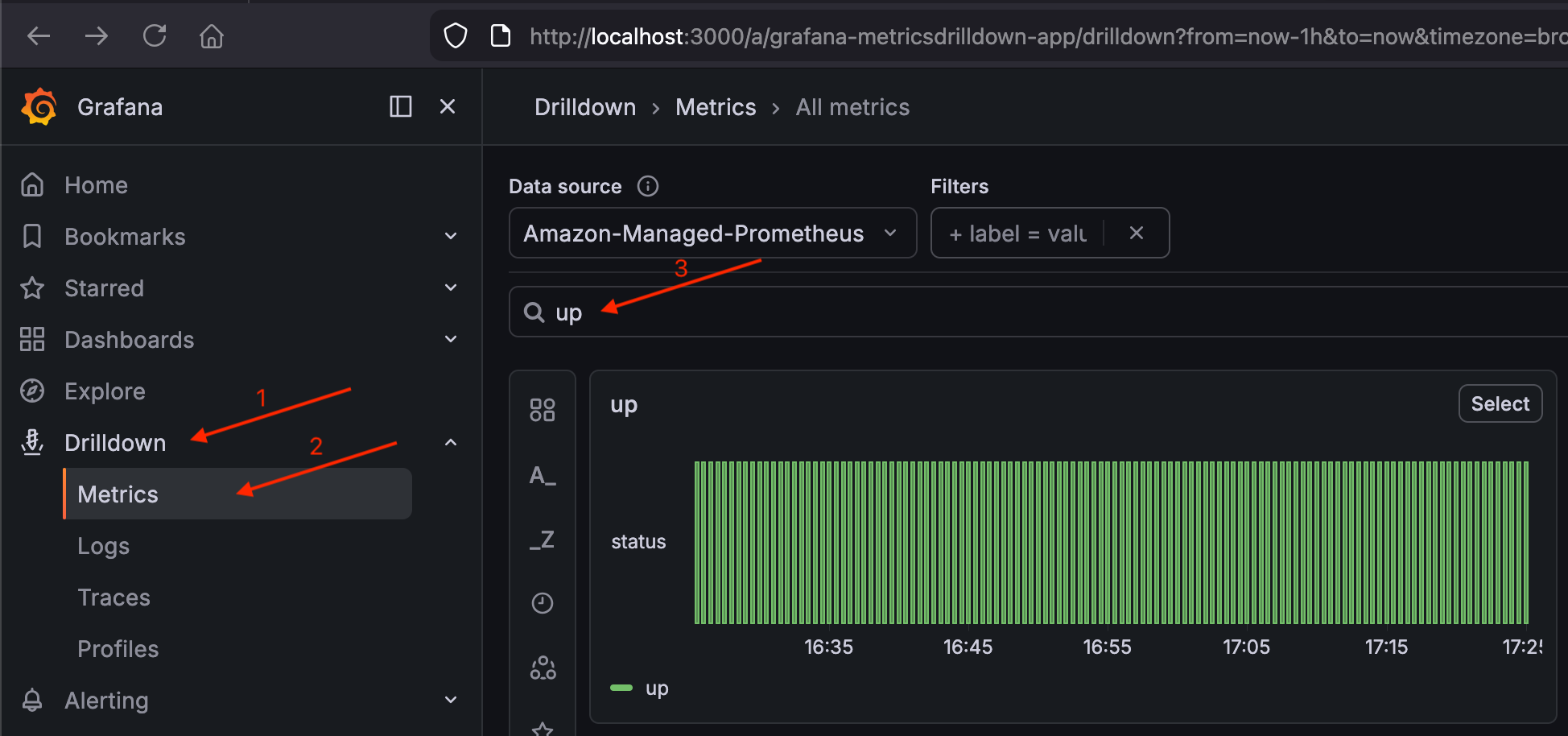
Wenn Ergebnisse up angezeigt werden, funktioniert die Pipeline (Cluster → Prometheus → AMP → Grafana).
Stellen Sie den DCGM-Exporter für GPU-Metriken bereit
Der Kube-Prometheus-Stack sammelt CPU- und Speichermetriken auf Knotenebene, aber keine GPU-Metriken. Der NVIDIA DCGM Exporter fügt GPU-Auslastung, Speichernutzung, Temperatur, Stromverbrauch, NVLink-Bandbreite und Tensoraktivität hinzu.
helm repo add gpu-helm-charts https://nvidia.github.io/dcgm-exporter/helm-charts helm repo update
Stellen Sie die GPU-Knotenauswahltaste für Ihren Pfad ein. Der automatische Modus von EKS und der selbstverwaltete Karpenter verwenden unterschiedliche Labelschlüssel für GPU-Hersteller.
Erstellen Sie die DCGM-Exportwertedatei:
Beispiel DCGM-Exporter-Wertedatei
cat << EOF > /tmp/dcgm-exporter-values.yaml resources: requests: memory: "512Mi" cpu: "100m" limits: memory: "1Gi" cpu: "500m" serviceMonitor: enabled: true additionalLabels: release: kube-prometheus-stack nodeSelector: ${GPU_NODE_SELECTOR_KEY}: nvidia tolerations: - key: "nvidia.com/gpu" operator: "Exists" effect: "NoSchedule" customMetrics: | # Clocks DCGM_FI_DEV_SM_CLOCK, gauge, SM clock frequency (in MHz). DCGM_FI_DEV_MEM_CLOCK, gauge, Memory clock frequency (in MHz). # Temperature DCGM_FI_DEV_MEMORY_TEMP, gauge, Memory temperature (in C). DCGM_FI_DEV_GPU_TEMP, gauge, GPU temperature (in C). # Power DCGM_FI_DEV_POWER_USAGE, gauge, Power draw (in W). DCGM_FI_DEV_TOTAL_ENERGY_CONSUMPTION, counter, Total energy consumption since boot (in mJ). # PCIe DCGM_FI_PROF_PCIE_TX_BYTES, counter, Number of bytes transmitted through PCIe TX (in KB) via NVML. DCGM_FI_PROF_PCIE_RX_BYTES, counter, Number of bytes received through PCIe RX (in KB) via NVML. DCGM_FI_DEV_PCIE_REPLAY_COUNTER, counter, Total number of PCIe retries. # Utilization (the sample period varies depending on the product) DCGM_FI_DEV_GPU_UTIL, gauge, GPU utilization (in %). DCGM_FI_DEV_MEM_COPY_UTIL, gauge, Memory utilization (in %). DCGM_FI_DEV_ENC_UTIL, gauge, Encoder utilization (in %). DCGM_FI_DEV_DEC_UTIL, gauge, Decoder utilization (in %). # Errors and violations DCGM_FI_DEV_XID_ERRORS, gauge, Value of the last XID error encountered. DCGM_EXP_XID_ERRORS_COUNT, gauge, Value of count of XID errors encountered. DCGM_FI_DEV_POWER_VIOLATION, counter, Throttling duration due to power constraints (in us). DCGM_FI_DEV_THERMAL_VIOLATION, counter, Throttling duration due to thermal constraints (in us). DCGM_FI_DEV_SYNC_BOOST_VIOLATION, counter, Throttling duration due to sync-boost constraints (in us). DCGM_FI_DEV_BOARD_LIMIT_VIOLATION, counter, Throttling duration due to board limit constraints (in us). DCGM_FI_DEV_LOW_UTIL_VIOLATION, counter, Throttling duration due to low utilization (in us). DCGM_FI_DEV_RELIABILITY_VIOLATION, counter, Throttling duration due to reliability constraints (in us). # Memory usage DCGM_FI_DEV_FB_FREE, gauge, Framebuffer memory free (in MiB). DCGM_FI_DEV_FB_USED, gauge, Framebuffer memory used (in MiB). # Retired pages DCGM_FI_DEV_RETIRED_SBE, counter, Total number of retired pages due to single-bit errors. DCGM_FI_DEV_RETIRED_DBE, counter, Total number of retired pages due to double-bit errors. DCGM_FI_DEV_RETIRED_PENDING, counter, Total number of pages pending retirement. # NVLink DCGM_FI_DEV_NVLINK_BANDWIDTH_TOTAL, counter, Total number of NVLink bandwidth counters for all lanes. DCGM_FI_PROF_NVLINK_TX_BYTES, counter, The rate of data transmitted over NVLink not including protocol headers in bytes per second. DCGM_FI_PROF_NVLINK_RX_BYTES, counter, The rate of data received over NVLink not including protocol headers in bytes per second. # DCP metrics DCGM_FI_PROF_GR_ENGINE_ACTIVE, gauge, Ratio of time the graphics engine is active (in %). DCGM_FI_PROF_SM_ACTIVE, gauge, The ratio of cycles an SM has at least 1 warp assigned (in %). DCGM_FI_PROF_SM_OCCUPANCY, gauge, The ratio of number of warps resident on an SM (in %). DCGM_FI_PROF_PIPE_TENSOR_ACTIVE, gauge, Ratio of cycles the tensor (HMMA) pipe is active (in %). DCGM_FI_PROF_DRAM_ACTIVE, gauge, Ratio of cycles the device memory interface is active sending or receiving data (in %). DCGM_FI_DEV_CLOCK_THROTTLE_REASONS, gauge, Current clock throttle reasons (bitmask of DCGM_CLOCKS_THROTTLE_REASON_*). DCGM_FI_DEV_GPU_NVLINK_ERRORS, gauge, Identifies a GPU NVLink error type returned by DCGM_FI_DEV_GPU_NVLINK_ERRORS. ## NVLink DCGM_FI_DEV_NVLINK_BANDWIDTH_L0, counter, The number of bytes of active NVLink rx or tx data including both header and payload. ## Remapped rows DCGM_FI_DEV_UNCORRECTABLE_REMAPPED_ROWS, counter, Number of remapped rows for uncorrectable errors. DCGM_FI_DEV_CORRECTABLE_REMAPPED_ROWS, counter, Number of remapped rows for correctable errors. DCGM_FI_DEV_ROW_REMAP_FAILURE, gauge, whether remapping of rows has failed. ## Profiling metrics DCGM_FI_PROF_PIPE_FP64_ACTIVE, gauge, Ratio of cycles the fp64 pipes are active (in %). DCGM_FI_PROF_PIPE_FP32_ACTIVE, gauge, Ratio of cycles the fp32 pipes are active (in %). DCGM_FI_PROF_PIPE_FP16_ACTIVE, gauge, Ratio of cycles the fp16 pipes are active (in %). # ECC DCGM_FI_DEV_ECC_SBE_VOL_TOTAL, counter, Total number of single-bit volatile ECC errors. DCGM_FI_DEV_ECC_DBE_VOL_TOTAL, counter, Total number of double-bit volatile ECC errors. EOF
Das customMetrics Feld überschreibt den Standard-Metriksatz des DCGM-Exporters mit einem erweiterten Metriksatz, der NVLink-Bandbreite, Tensoraktivität, PCIe-Durchsatz, ECC-Fehler und thermische Drosselung umfasst. Bei Inferenz-Workloads können Sie anhand dieser Informationen nachvollziehen, ob die GPU-Recheneinheiten voll ausgelastet sind, ob die GPU aufgrund niedriger Batchgrößen zwischen Anfragen inaktiv ist, ob die Datenübertragung zwischen CPU und GPU einen Engpass darstellt, ob thermische Drosselung Latenzspitzen verursacht und wie viel GPU-Speicherkapazität für größere Batches noch vorhanden ist.
Installieren Sie den DCGM-Exporter:
helm install dcgm-exporter gpu-helm-charts/dcgm-exporter \ --namespace monitoring \ -f /tmp/dcgm-exporter-values.yaml
tolerationsDadurch kann der Exporter auf den GPU-tainted Knoten ausgeführt werden, die Sie in Schritt 2 bereitgestellt haben. Das serviceMonitor mit dem release: kube-prometheus-stack Etikett sorgt dafür, dass Prometheus es automatisch entdeckt und abkratzt.
Überprüfen Sie den DCGM-Exporteur: DaemonSet
kubectl get daemonset dcgm-exporter -n monitoring
Sobald ein GPU-Knoten läuft, sollte ein bereiter Pod angezeigt werden. Um DCGM-Metriken zu validieren, navigieren Sie in Grafana zu Drilldown > Metrics und suchen Sie nach. DCGM_
Validieren Sie DCGM-Metriken in Grafana
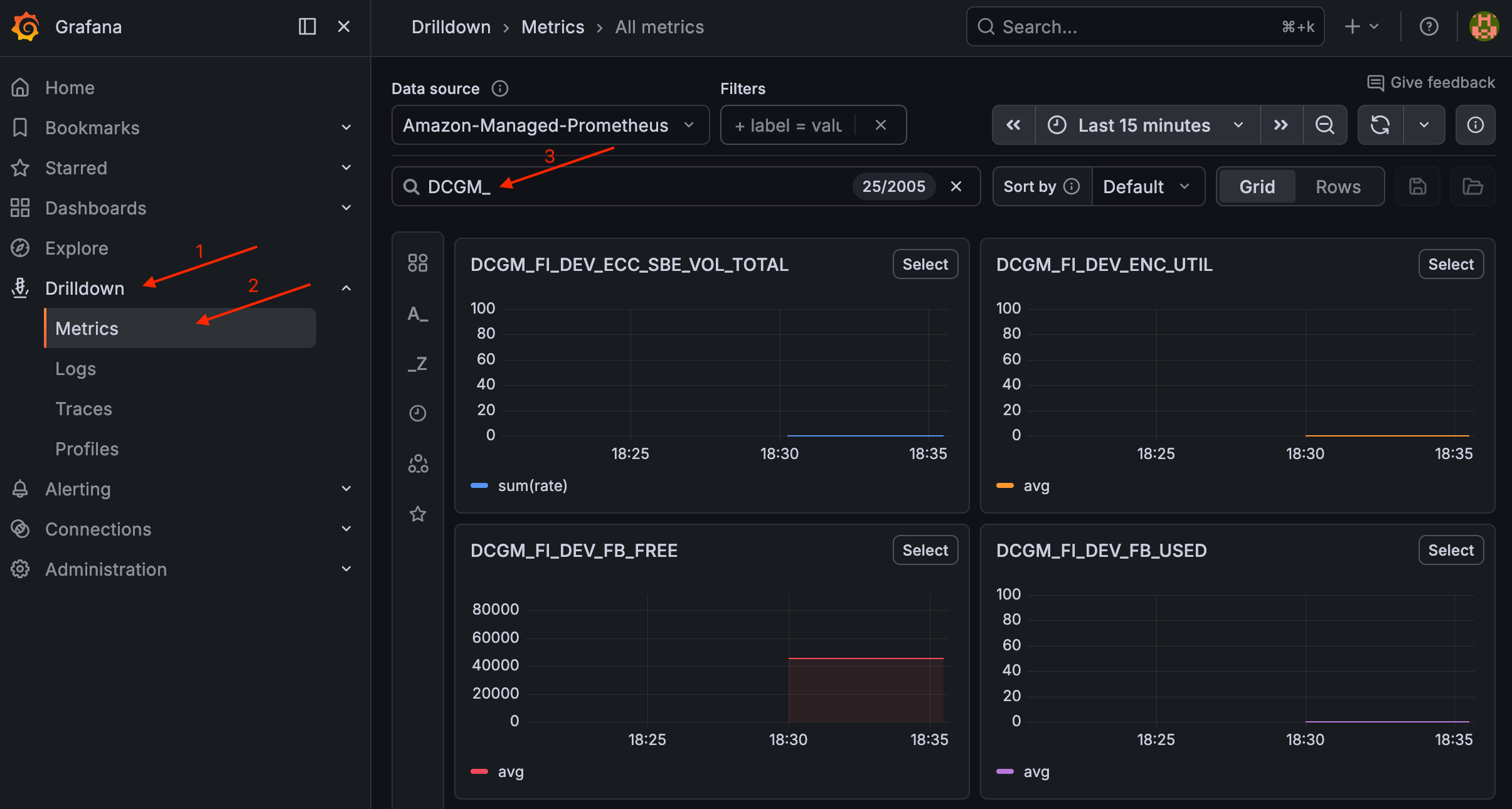
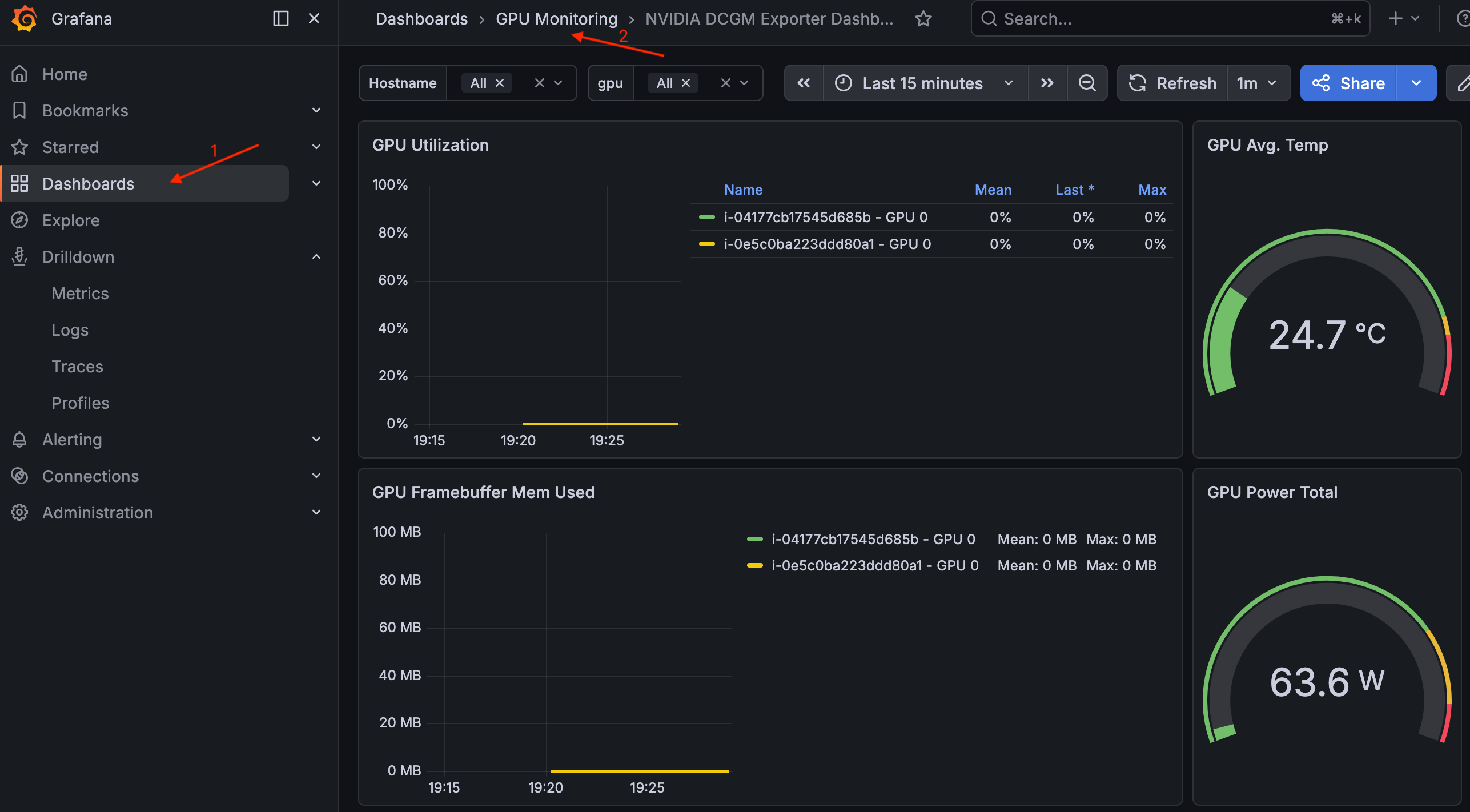
Um das Dashboard anzuzeigen, navigieren Sie zu Dashboards > GPU Monitoring > NVIDIA DCGM Exporter Dashboard.
NVIDIA DCGM Exporter-Dashboard in Grafana
Das Modell wiegt den S3-Bucket
Erstellen Sie einen Amazon S3 S3-Bucket zum Speichern von Modellgewichten und konfigurieren Sie eine EKS Pod Identity Association, sodass Workload-Pods darauf lesen und schreiben können.
Wenn Sie ein neues Terminal geöffnet haben, legen Sie den Clusternamen und die Region fest:
export CLUSTER_NAME=ai-eks-docs export AWS_REGION=us-east-2
Erstellen Sie den S3-Bucket
Erstellen Sie den Bucket mit einem zufälligen Suffix, um Namenskollisionen zu vermeiden:
BUCKET_SUFFIX=$(head -c 4 /dev/urandom | od -An -tx1 | tr -d ' \n') MODEL_BUCKET="${CLUSTER_NAME}-models-${BUCKET_SUFFIX}" aws s3 mb s3://${MODEL_BUCKET} --region ${AWS_REGION}
Bei S3-Buckets, die nach Januar 2023 erstellt wurden, sind serverseitige Verschlüsselung (AES256) und Sperrung des öffentlichen Zugriffs standardmäßig aktiviert.
Konfigurieren Sie EKS Pod Identity für den S3-Zugriff
Erstellen Sie model-storage-sa ServiceAccount im default Namespace eine IAM-Richtlinie, die auf den Modell-Bucket beschränkt ist, und eine EKS Pod Identity Association, die sie verknüpft. Diese Workload-Pods können serviceAccountName: model-storage-sa den Bucket lesen und in ihn schreiben.
kubectl create serviceaccount model-storage-sa
Erstellen Sie die IAM-Richtlinie:
POLICY_ARN=$(aws iam create-policy \ --policy-name "${CLUSTER_NAME}-model-storage-policy" \ --policy-document "{\"Version\": \"2012-10-17\", \"Statement\": [{\"Effect\": \"Allow\", \"Action\": [\"s3:GetObject\", \"s3:PutObject\", \"s3:ListBucket\", \"s3:DeleteObject\"], \"Resource\": [\"arn:aws:s3:::${MODEL_BUCKET}\", \"arn:aws:s3:::${MODEL_BUCKET}/*\"]}]}" \ --query 'Policy.Arn' \ --output text) echo "Policy ARN: ${POLICY_ARN}"
Anmerkung
Diese Richtlinie gewährt s3:DeleteObject und s3:PutObject für den Validierungsschritt. Für Inferenz-Pods in der Produktionsumgebung, die nur Modellgewichte auslesen, s3:DeleteObject müssen Sie die Option mit den geringsten Rechten entfernen s3:PutObject und befolgen.
Erstellen Sie die EKS Pod Identity Association. eksctlerstellt die IAM-Rolle mit der richtigen Vertrauensrichtlinie und verknüpft sie mit: ServiceAccount
eksctl create podidentityassociation \ --cluster ${CLUSTER_NAME} \ --namespace default \ --service-account-name model-storage-sa \ --role-name "${CLUSTER_NAME}-model-storage-role" \ --permission-policy-arns ${POLICY_ARN} \ --region ${AWS_REGION}
Überprüfen Sie die Zuordnung:
eksctl get podidentityassociation --cluster ${CLUSTER_NAME} --region ${AWS_REGION}
Die Ausgabe sollte die model-storage-sa Assoziation im default Namespace enthalten.
Führen Sie einen einmaligen Pod mit dem AWS CLI-Image aus, um zu bestätigen model-storage-sa ServiceAccount, dass EKS Pod Identity verkabelt ist und der S3-Zugriff funktioniert:
cat << EOF | kubectl apply -f - apiVersion: v1 kind: Pod metadata: name: s3-test labels: guide: ai-eks-docs spec: serviceAccountName: model-storage-sa containers: - name: aws-cli image: public.ecr.aws/aws-cli/aws-cli:2.27.0 command: - sh - -c - | echo "=== Caller Identity ===" aws sts get-caller-identity echo "" echo "=== S3 Write Test ===" echo "pod identity works" | aws s3 cp - s3://${MODEL_BUCKET}/test.txt echo "" echo "=== S3 List Test ===" aws s3 ls s3://${MODEL_BUCKET}/ echo "" echo "=== S3 Delete Test ===" aws s3 rm s3://${MODEL_BUCKET}/test.txt restartPolicy: Never EOF
Warten Sie, bis der Pod abgeschlossen ist, und überprüfen Sie die Protokolle:
kubectl wait --for=jsonpath='{.status.phase}'=Succeeded pod/s3-test --timeout=300s kubectl logs s3-test
Erwartete Ausgabe:
=== Caller Identity ===
{
"UserId": "AROA...:eks-ai-eks-docs-model-s-...",
"Account": "123456789012",
"Arn": "arn:aws:sts::123456789012:assumed-role/ai-eks-docs-model-storage-role/eks-ai-eks-docs-model-s-..."
}
=== S3 Write Test ===
upload: - to s3://ai-eks-docs-models-01234567/test.txt
=== S3 List Test ===
2026-05-04 12:00:00 19 test.txt
=== S3 Delete Test ===
delete: s3://ai-eks-docs-models-01234567/test.txtDie Identität des Anrufers bestätigt, dass der Pod die ${CLUSTER_NAME}-model-storage-role Rolle über EKS Pod Identity übernommen hat. Die S3-Befehle bestätigen den Lese- und Schreibzugriff.
Reinigen Sie den Test-Pod:
kubectl delete pod s3-test
Nächste Schritte
Wenn Ihr Cluster bereit ist, können Sie mit dem Load & Serve Model fortfahren, um ein umfangreiches Sprachmodell bereitzustellen und mit dem Inferenzendpunkt zu interagieren.
Bereinigen
Tipp
Wenn Sie mit den nächsten Abschnitten dieses Handbuchs fortfahren möchten, überspringen Sie die vollständige Bereinigung. Führen Sie es erst aus, wenn Sie fertig sind.
export CLUSTER_NAME=ai-eks-docs export AWS_REGION=us-east-2
kubectl delete pod nvidia-smi --ignore-not-found kubectl delete deployment gpu-overflow-test --ignore-not-found
Wenn Sie ein ODCR erstellt haben, stornieren Sie es zuerst. Suchen Sie nach der Reservierungs-ID:
INSTANCE_TYPE="g6e.4xlarge" CAPACITY_RESERVATION_ID=$(aws ec2 describe-capacity-reservations \ --filters "Name=state,Values=active" "Name=instance-type,Values=${INSTANCE_TYPE}" \ --query 'CapacityReservations[0].CapacityReservationId' \ --output text \ --region ${AWS_REGION}) echo "Capacity reservation ID: ${CAPACITY_RESERVATION_ID}"
Stornieren Sie die Reservierung:
aws ec2 cancel-capacity-reservation --capacity-reservation-id ${CAPACITY_RESERVATION_ID}
Wichtig
Durch das Stornieren einer Reservierung werden laufende Instances nicht beendet. Sie laufen zu On-Demand Standardtarifen weiter, bis sie gekündigt werden. Löschen Sie zuerst die Bereitstellung, um den reservierten Knoten zu entladen, bevor Sie den Vorgang abbrechen.
Suchen Sie nach dem ARN für die IAM-Richtlinie:
AMP_POLICY_ARN=$(aws iam list-policies \ --scope Local \ --query "Policies[?PolicyName=='${CLUSTER_NAME}-amp-grafana-policy'].Arn" \ --output text) echo "AMP Policy ARN: ${AMP_POLICY_ARN}"
Suchen Sie nach der AMP-Workspace-ID:
AMP_WORKSPACE_ID=$(aws amp list-workspaces \ --alias "amp-ws-${CLUSTER_NAME}" \ --query 'workspaces[0].workspaceId' \ --output text \ --region ${AWS_REGION}) echo "AMP Workspace ID: ${AMP_WORKSPACE_ID}"
Deinstalliere die Helm-Version des DCGM-Exporters:
helm uninstall dcgm-exporter -n monitoring
Deinstallieren Sie die Helm-Version von kube-prometheus-stack:
helm uninstall kube-prometheus-stack -n monitoring
Löschen Sie die EKS Pod Identity-Zuordnung für das Prometheus-Ingest-Servicekonto:
eksctl delete podidentityassociation \ --cluster ${CLUSTER_NAME} \ --namespace monitoring \ --service-account-name amp-iamproxy-ingest-service-account \ --region ${AWS_REGION}
Löschen Sie die EKS Pod Identity-Zuordnung für das Grafana-Dienstkonto:
eksctl delete podidentityassociation \ --cluster ${CLUSTER_NAME} \ --namespace monitoring \ --service-account-name grafana-sa \ --region ${AWS_REGION}
Löschen Sie die von Prometheus und Grafana verwendete IAM-Richtlinie:
aws iam delete-policy --policy-arn ${AMP_POLICY_ARN}
Löschen Sie den AMP-Workspace:
aws amp delete-workspace --workspace-id ${AMP_WORKSPACE_ID} --region ${AWS_REGION}
Löschen Sie den Monitoring-Namespace:
kubectl delete namespace monitoring
Suchen Sie nach dem Namen des Modell-Buckets:
MODEL_BUCKET=$(aws s3api list-buckets \ --query "Buckets[?starts_with(Name, '${CLUSTER_NAME}-models-')].Name | [0]" \ --output text) echo "Model bucket: ${MODEL_BUCKET}"
Suchen Sie nach dem ARN für die IAM-Richtlinie:
POLICY_ARN=$(aws iam list-policies \ --scope Local \ --query "Policies[?PolicyName=='${CLUSTER_NAME}-model-storage-policy'].Arn" \ --output text) echo "Policy ARN: ${POLICY_ARN}"
Löschen Sie den S3-Modell-Bucket und alle seine Objekte:
aws s3 rb s3://${MODEL_BUCKET} --force
Löschen Sie die EKS Pod Identity-Zuordnung:
eksctl delete podidentityassociation \ --cluster ${CLUSTER_NAME} \ --namespace default \ --service-account-name model-storage-sa \ --region ${AWS_REGION}
Löschen Sie die IAM-Richtlinie:
aws iam delete-policy --policy-arn ${POLICY_ARN}
Löschen Sie die Kubernetes ServiceAccount:
kubectl delete serviceaccount model-storage-sa
kubectl delete nodepool gpu-inf --ignore-not-found kubectl delete nodeclass gpu-inf --ignore-not-found kubectl delete ec2nodeclass gpu-inf --ignore-not-found eksctl delete cluster --name=$CLUSTER_NAME --region=$AWS_REGION
