Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Neue Vokabeleinheiten hinzufügen
Mithilfe der InvokeDataAutomationLibraryIngestionJobAPI können Sie Ihrer Bibliothek Vokabeln hinzufügen. Sie können Vokabeln über eine S3-Manifestdatei oder eine Inline-Payload bereitstellen.
Wichtig
UPSERT-Operationen verwenden eine Ersetzung im Clobber-Stil auf Entitätsebene, was bedeutet, dass die gesamte Entität ersetzt wird, anstatt sie mit vorhandenem Inhalt zusammenzuführen.
Option 1: Verwenden der S3-Manifestdatei
Schritt 1: Erstellen Sie eine JSONL-Manifestdatei
Beispiel: vocabulary-manifest.json
{"entityId":"medical-en","description":"Medication terms in English language","phrases":[{"text":"paracetamol"},{"text":"ibuprofen"},{"text":"acetaminophen","displayAsText":"acetaminophen"}],"language":"EN"} {"entityId":"medical-es","description":"Medication terms in Spanish language","phrases":[{"text":"paracetamol"},{"text":"ibuprofen"},{"text":"acetaminophen","displayAsText":"acetaminophen"}],"language":"ES"}
Anforderungen an die Manifestdatei:
Dateiformat: JSONL (JSON-Zeilen)
-
Entität JSON:
entityId (erforderlich): Eindeutiger Bezeichner (max. 128 Zeichen)
Beschreibung (optional): Beschreibung der EntityID
Sprache (erforderlich): ISO-Sprachcode (Unterstützte Sprachen)
-
Phrasen (erforderlich): Array von Textobjekten. Jedes Objekt enthält:
Text (erforderlich): Einzelnes Wort oder Satz
displayAsText(optional): Verwenden Sie diese Option, um das tatsächliche Wort im Transkript zu ersetzen (HINWEIS: Groß- und Kleinschreibung beachten)
Schritt 2: Laden Sie das Manifest auf S3 hoch
aws s3 cp vocabulary-manifest.json s3://my-bucket/manifests/
Schritt 3: Starten Sie den Aufnahmejob
Verwenden Sie den InvokeDataAutomationLibraryIngestionJob, um einen Job zur Vokabelaufnahme zu starten.
AWS-CLI-Beispiel:
Anforderung
aws bedrock-data-automation-data-automation invoke-data-automation-library-ingestion-job \ --library-arn "arn:aws:bedrock:us-east-1:123456789012:data-automation-library/healthcare-vocabulary" \ --entity-type "VOCABULARY" \ --operation-type "UPSERT" \ --input-configuration '{"s3Object":{"s3Uri":"s3://my-bucket/manifests/vocabulary-manifest.json"}}' \ --output-configuration '{"s3Uri":"s3://my-bucket/outputs/"}'
Antwort:
{ "jobArn": "arn:aws:bedrock:us-east-1:123456789012:data-automation-library-ingestion-job/job-12345" }
Beispiel für eine AWS-Konsole:
Navigieren Sie zur Seite „Bibliotheksdetails“
Wählen Sie „Benutzerdefinierte Vokabelliste hinzufügen“
Wählen Sie „Manifest hochladen/auswählen“
Wählen Sie aus, ob Sie die Manifestdatei direkt oder von einem S3-Speicherort hochladen möchten

Option 2: Inline Payload verwenden
Diese Option kann für schnelle Updates mit bis zu 100 Phrasen verwendet werden.
Verwenden Sie den InvokeDataAutomationLibraryIngestionJob, um einen Job zum Erfassen von Vokabeln zu starten.
AWS-CLI-Beispiel:
Anforderung
aws bedrock-data-automation-data-automation invoke-data-automation-library-ingestion-job \ --library-arn "arn:aws:bedrock:us-east-1:123456789012:data-automation-library/healthcare-vocabulary" \ --entity-type "VOCABULARY" \ --operation-type "UPSERT" \ --input-configuration '{"inlinePayload":{"upsertEntitiesInfo":[{"vocabulary":{"entityId":"medical-en","language":"EN","phrases":[{"text":"paracetamol"},{"text":"ibuprofen"}]}}]}}' \ --output-configuration '{"s3Uri":"s3://bda-data-bucket/output/"}'
Antwort:
{ "jobArn": "arn:aws:bedrock:us-east-1:123456789012:data-automation-library-ingestion-job/job-12345" }
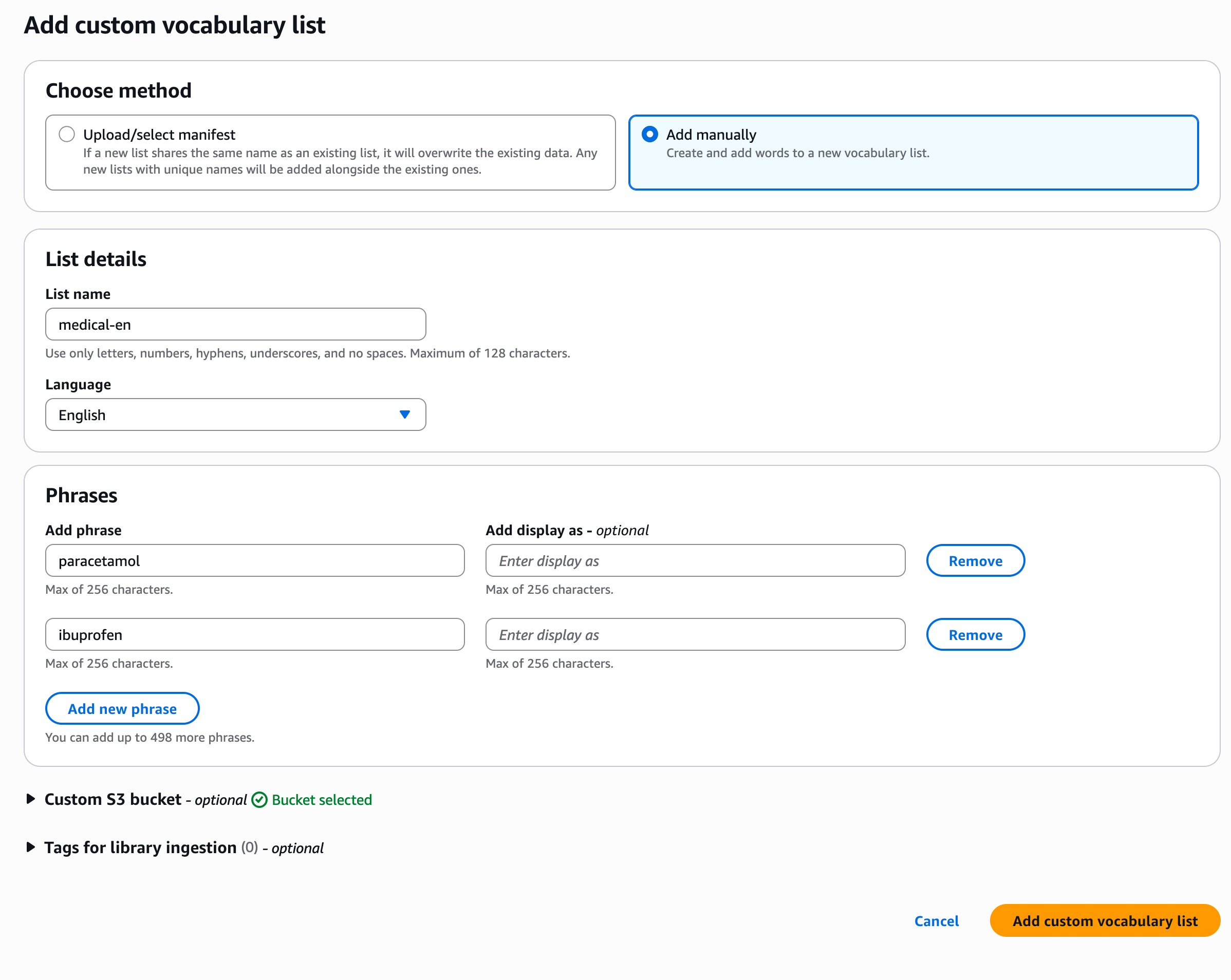
Beispiel für eine AWS-Konsole:
Navigieren Sie zur Seite „Bibliotheksdetails“
Wählen Sie „Benutzerdefinierte Vokabelliste hinzufügen“
Wähle „Manuell hinzufügen“