Integrieren Sie mithilfe von OAuth2 in Google Drive
Dieses Tutorial für die ersten Schritte führt Sie durch die wichtigsten Schritte, um mit der Nutzung von Amazon Bedrock AgentCore Identity für Ihre KI-Agenten zu beginnen. Sie erfahren, wie Sie Ihre Entwicklungsumgebung einrichten, die erforderlichen SDKs installieren, Ihre erste Agentenidentität erstellen und Ihrem Agenten den sicheren Zugriff auf externe Ressourcen ermöglichen.
Am Ende dieses Tutorials verfügen Sie über einen funktionierenden Agenten, der mit AgentCore Identity OAuth2 Credential Provider Zugriffstoken von Google abrufen und mithilfe von Zugriffstoken Dateien von Google Drive lesen kann. Ausführliche Informationen zu OAuth2-Flows finden Sie unter Anmeldeinformationsanbieter mit Identity verwalten. AgentCore
Themen
Voraussetzungen
Bevor Sie beginnen, benötigen Sie:
-
Ein AWS Konto mit entsprechenden Berechtigungen
BedrockAgentCoreFullAccess(z. B. -
Python 3.10 oder höher
-
Die neueste AWS CLI und
jqinstalliert -
AWS Anmeldeinformationen und Region konfiguriert (
aws configure) -
Grundlegendes Verständnis der Python-Programmierung
Wichtig
Die BedrockAgentCoreFullAccess verwaltete Richtlinie gewährt umfassende BerechtigungenGetWorkloadAccessTokenForUserId, die es Aufrufern unter anderem ermöglichen, Workload-Zugriffstoken unter Verwendung einer beliebigen Benutzer-Identifikationszeichenfolge ohne IdP-Tokenverifizierung auszugeben. Dies eignet sich für Entwicklung und Tests. Erstellen Sie für Produktionsbereitstellungen benutzerdefinierte IAM-Richtlinien, die dem Prinzip der geringsten Rechte folgen und die Berechtigungen nur auf die spezifischen Aktionen beschränken, die erforderlich sind. Wenn Ihre Anwendung eine JWT-based Authentifizierung verwendet (empfohlen für die Produktion), können Sie dies ausdrücklich ablehnen, GetWorkloadAccessTokenForUserId um sicherzustellen, dass die gesamte Benutzeridentifikation den verifizierten JWT-Pfad durchläuft. Weitere Informationen finden Sie unter Workload-Zugriffstoken abrufen.
Das SDK installieren
Um zu beginnen, installieren Sie das bedrock-agentcore Paket:
pip install bedrock-agentcore
Besorgen Sie sich die Google Client ID und den Client Secret
Damit Ihr Agent auf Google Drive zugreifen kann, benötigen Sie eine Google-Client-ID und einen geheimen Clientschlüssel für Ihren Agenten. Gehen Sie zur Google Developer Console
-
Erstellen Sie ein Projekt in der Google Developer Console
-
Aktivieren Sie die Google Drive-API
-
Konfigurieren Sie den OAuth-Zustimmungsbildschirm
-
Erstellen Sie eine neue Webanwendung für den Agenten, zum Beispiel „My Agent 1"
-
Fügen Sie Ihrer Agentenanwendung den folgenden OAuth 2.0-Bereich hinzu:
https://www.googleapis.com/auth/drive.metadata.readonly -
Erstellen Sie OAuth 2.0-Anmeldeinformationen für die neue Webanwendung und speichern Sie die generierte Google-Client-ID und das Client-Geheimnis
Schritt 1: Richten Sie einen OAuth 2.0-Anmeldeinformationsanbieter ein
Erstellen Sie einen neuen OAuth 2.0-Anmeldeinformationsanbieter mit der Google-Client-ID und dem Client-Schlüssel, die Sie zuvor mit dem folgenden AWS CLI-Befehl abgerufen haben:
OAUTH2_CREDENTIAL_PROVIDER_RESPONSE=$(aws bedrock-agentcore-control create-oauth2-credential-provider \ --region us-east-1 \ --name "google-provider" \ --credential-provider-vendor "GoogleOauth2" \ --oauth2-provider-config-input '{ "googleOauth2ProviderConfig": { "clientId": "<your-google-client-id>", "clientSecret": "<your-google-client-secret>" } }' \ --output json) OAUTH2_CALLBACK_URL=$(echo $OAUTH2_CREDENTIAL_PROVIDER_RESPONSE | jq -r '.callbackUrl') echo "OAuth2 Callback URL: $OAUTH2_CALLBACK_URL"
Anmerkung
Rufen Sie das callbackUrl aus der obigen CreateOauth2CredentialProviderAntwort ab und fügen Sie den URI zur Liste der Weiterleitungs-URIs Ihrer Google-Anwendung hinzu. Die Callback-URL sollte wie folgt aussehen: https://bedrock-agentcore.us-east-1.amazonaws.com/identities/oauth2/callback/ ********-****-****-************
Schritt 2: Identity- und Auth-Module importieren
Fügen Sie diese Importanweisung zu Ihrer Python-Datei hinzu:
from bedrock_agentcore.services.identity import IdentityClient from bedrock_agentcore.identity.auth import requires_access_token, requires_api_key
Schritt 3: Besorgen Sie sich ein OAuth 2.0-Zugriffstoken
Nachdem Sie den Google Credential Provider im vorherigen Schritt erstellt haben, fügen Sie Ihrem Agentencode den @requires_access_token Decorator hinzu, für den ein Google-Zugriffstoken erforderlich ist. Kopieren Sie die Autorisierungs-URL aus Ihrer Konsolenausgabe, fügen Sie sie dann in Ihren Browser ein und schließen Sie den Zustimmungsvorgang mit Google Drive ab.
Das folgende Codebeispiel soll in Ihren Agentencode integriert werden, um einen Autorisierungsworkflow aufzurufen. Dies ist kein eigenständiger Code, der kopiert und unabhängig ausgeführt werden kann.
import asyncio # Injects Google Access Token @requires_access_token( # Uses the same credential provider name created above provider_name="google-provider", # Requires Google OAuth2 scope to access Google Drive scopes=["https://www.googleapis.com/auth/drive.metadata.readonly"], # Sets to OAuth 2.0 Authorization Code flow auth_flow="USER_FEDERATION", # Prints authorization URL to console on_auth_url=lambda x: print("\nPlease copy and paste this URL in your browser:\n" + x), # If false, caches obtained access token force_authentication=False, # The callback URL to redirect to after the OAuth 2.0 token retrieval is complete callback_url='oauth2_callback_url_for_session_binding', ) async def write_to_google_drive(*, access_token: str): # Prints the access token obtained from Google print(access_token) asyncio.run(write_to_google_drive(access_token=""))
Hinter den Kulissen durchläuft der @requires_access_token Dekorateur die folgende Sequenz:
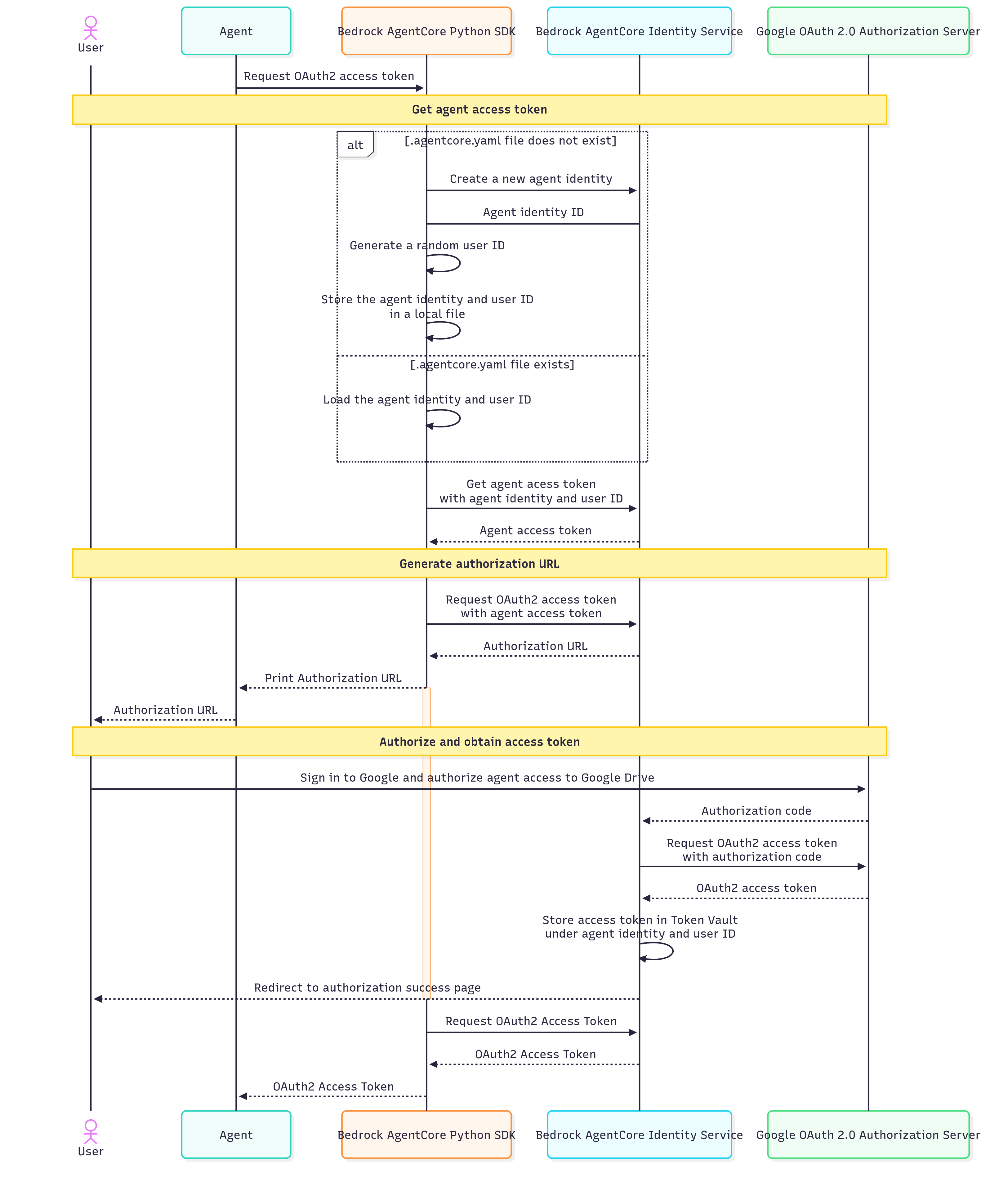
-
Das SDK führt API-Aufrufe an
CreateWorkloadIdentityGetWorkloadAccessToken, undGetResourceOauth2Tokendurch. -
Wenn der Agentencode lokal ausgeführt wird, generiert das SDK automatisch eine Agenten-Identitäts-ID und eine zufällige Benutzer-ID für lokale Tests und speichert sie in einer lokalen Datei namens
.bedrock_agentcore.yaml. -
Wenn der Agentencode mit AgentCore Runtime ausgeführt wird, generiert das SDK weder eine Agenten-Identitäts-ID noch eine zufällige Benutzer-ID. Stattdessen verwendet es die zugewiesene Agenten-Identitäts-ID und die Benutzer-ID oder das JWT-Token, das vom Agentenaufrufer übergeben wurde.
-
Das Agenten-Zugriffstoken ist ein verschlüsseltes (undurchsichtiges) Token, das die Agenten-Identitäts-ID und die Benutzer-ID enthält.
-
AgentCore Der Identitätsdienst speichert das Google-Zugriffstoken im Token-Tresor unter der Identitäts-ID und der Benutzer-ID des Agenten. Dadurch wird eine Bindung zwischen der Agentenidentität, der Benutzeridentität und dem Google-Zugriffstoken hergestellt.
-
Der Ablauf der Sitzungsbindung muss abgeschlossen sein, bevor das Google-Zugriffstoken von AgentCore Identity an den Anrufer zurückgegeben wird.
Schritt 4: Verwenden Sie das OAuth2-Zugriffstoken, um die externe Ressource aufzurufen
Sobald der Agent mit den obigen Schritten ein Google-Zugriffstoken erhalten hat, kann er das Zugriffstoken für den Zugriff auf Google Drive verwenden. Hier ist ein vollständiges Beispiel, das die Namen und IDs der ersten 10 Dateien auflistet, auf die der Nutzer Zugriff hat.
Installieren Sie zunächst die Google-Clientbibliothek für Python:
pip install --upgrade google-api-python-client google-auth-httplib2 google-auth-oauthlib
Kopieren Sie dann den folgenden Code:
import asyncio from bedrock_agentcore.identity.auth import requires_access_token, requires_api_key from google.auth.transport.requests import Request from google.oauth2.credentials import Credentials from google_auth_oauthlib.flow import InstalledAppFlow from googleapiclient.discovery import build from googleapiclient.errors import HttpError SCOPES = ["https://www.googleapis.com/auth/drive.metadata.readonly"] def main(access_token): """Shows basic usage of the Drive v3 API. Prints the names and ids of the first 10 files the user has access to. """ creds = Credentials(token=access_token, scopes=SCOPES) try: service = build("drive", "v3", credentials=creds) # Call the Drive v3 API results = ( service.files() .list(pageSize=10, fields="nextPageToken, files(id, name)") .execute() ) items = results.get("files", []) if not items: print("No files found.") return print("Files:") for item in items: print(f"{item['name']} ({item['id']})") except HttpError as error: # TODO(developer) - Handle errors from drive API. print(f"An error occurred: {error}") if __name__ == "__main__": # This annotation helps agent developer to obtain access tokens from external applications @requires_access_token( provider_name="google-provider", # Google OAuth2 scopes scopes=["https://www.googleapis.com/auth/drive.metadata.readonly"], # 3LO flow auth_flow="USER_FEDERATION", # prints authorization URL to console on_auth_url=lambda x: print("Copy and paste this authorization url to your browser", x), force_authentication=True, callback_url='oauth2_callback_url_for_session_binding', ) async def read_from_google_drive(*, access_token: str): print(access_token) # You can see the access_token # Make API calls... main(access_token) asyncio.run(read_from_google_drive(access_token=""))
Anmerkung
Ein Beispiel für eine Implementierung eines lokalen Callback-Servers zur Verarbeitung der Sitzungsbindung finden Sie unter https://github.com/awslabs/amazon-bedrock-agentcore-samples/blob/main/01-tutorials/03-AgentCore-identity/05-Outbound_Auth_3lo/oauth2_callback_server.py
Die nächsten Themen
Das Beispiel in diesem Abschnitt konzentriert sich auf praktische Implementierungsmuster, die Sie an Ihre spezifischen Anwendungsfälle anpassen können. Sie können den Code als Teil eines Agenten oder eines Model Context Protocol (MCP) -Tools einbetten. Wenn Sie Ihren Agent-Code oder Ihr MCP-Tool mit AgentCore Runtime hosten möchten, folgen Sie Host Agent oder Tools with Amazon Bedrock AgentCore Runtime, um den obigen Code in Runtime zu AgentCore kopieren.
