Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Importieren von Daten in eine Datenbank von Amazon RDS für MySQL mit reduzierter Ausfallzeit
In einigen Fällen müssen Sie möglicherweise Daten aus einer externen MySQL-Datenbank, die eine Live-Anwendung unterstützt, in eine RDS for MySQL-DB-Instance oder einen RDS for Multi-AZ MySQL-DB-Cluster importieren. Nutzen Sie das folgende Verfahren, um die Auswirkungen auf die Verfügbarkeit der Anwendung zu minimieren. Dieses Verfahren kann außerdem hilfreich sein, wenn Sie mit einer sehr großen Datenbank arbeiten. Mit diesem Verfahren können Sie die Kosten des Imports durch Reduzierung der Menge an Daten senken, die über das Netzwerk an AWS weitergeleitet werden.
Im Rahmen dieses Verfahrens übertragen Sie eine Kopie Ihrer Datenbankdaten an eine Amazon-EC2-Instance und importieren die Daten in eine neue Amazon-RDS-Datenbank. Anschließend verwenden Sie die Replikation, um die Amazon-RDS-Datenbank auf den aktuellen Stand Ihrer externen Live-Instance zu bringen, bevor Sie Ihre Anwendung an die Amazon-RDS-Datenbank weiterleiten. Konfigurieren Sie die Replikation basierend auf den Binärprotokollkoordinaten.
Anmerkung
Wenn Sie Daten in eine DB-Instance von RDS für MySQL importieren möchten und Ihr Szenario dies unterstützt, empfehlen wir, Daten mithilfe von Backup-Dateien und Amazon S3 in und aus Amazon RDS zu verschieben. Weitere Informationen finden Sie unter Wiederherstellen eines Backups in eine DB-Instance von Amazon RDS für MySQL.
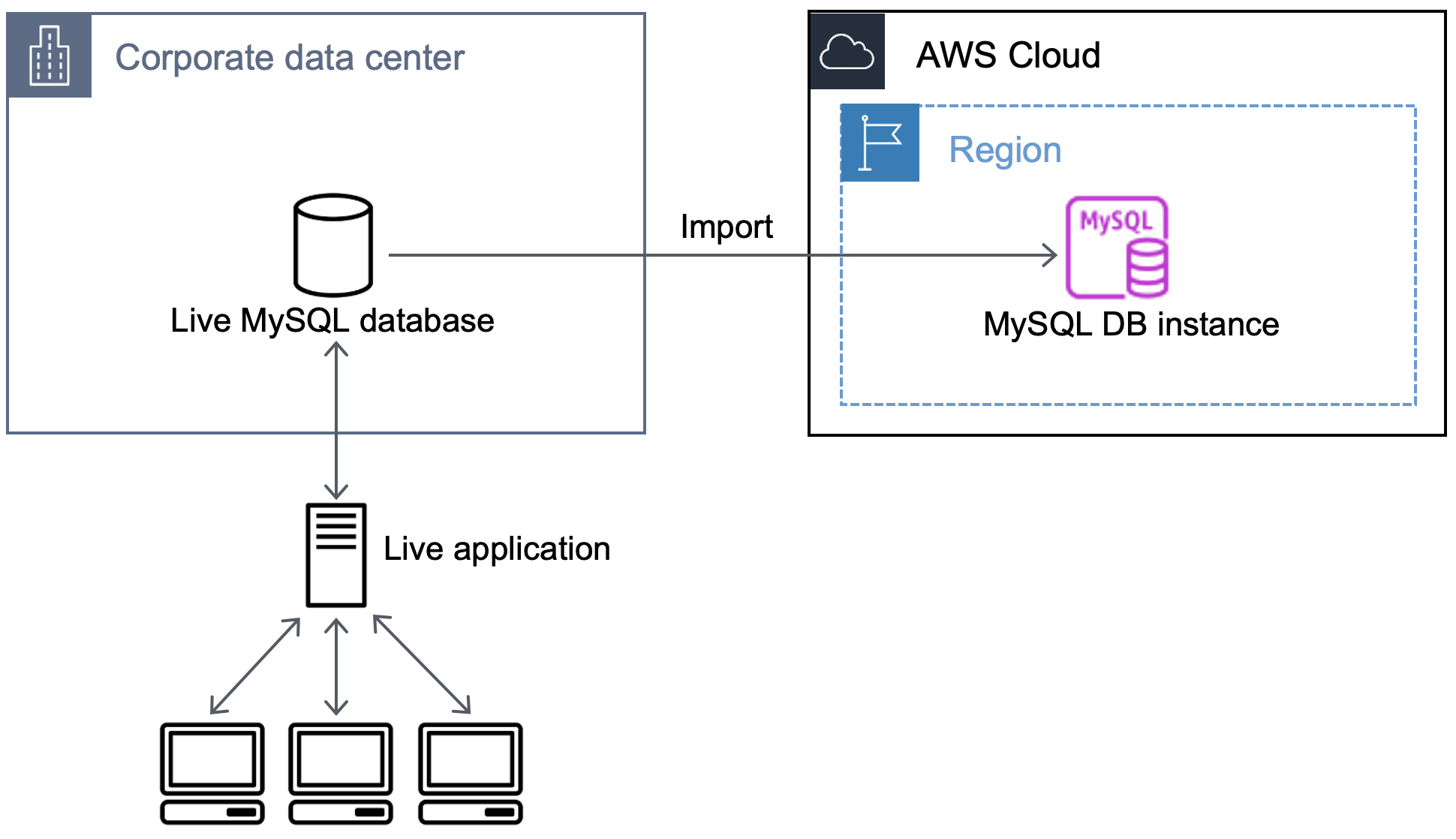
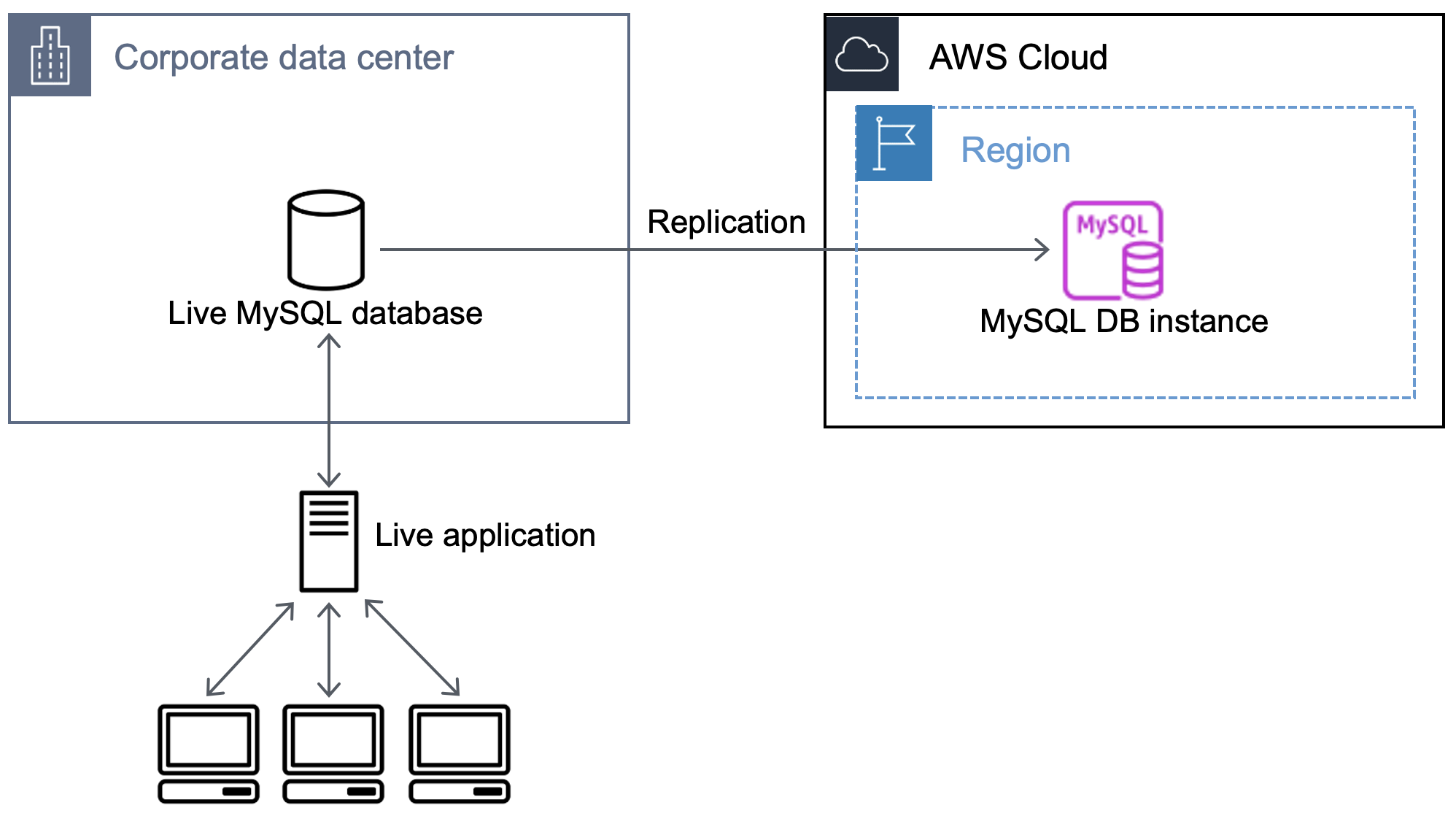
Im folgenden Diagramm ist der Import einer externen MySQL-Datenbank in eine MySQL-Datenbank auf Amazon RDS veranschaulicht.
Aufgabe 1: Erstellen einer Kopie Ihrer bestehenden Datenbank
Der erste Schritt bei der Migration von großen Datenmengen in eine Datenbank von RDS für MySQL mit minimaler Ausfallzeit besteht darin, eine Kopie der Quelldaten zu erstellen.
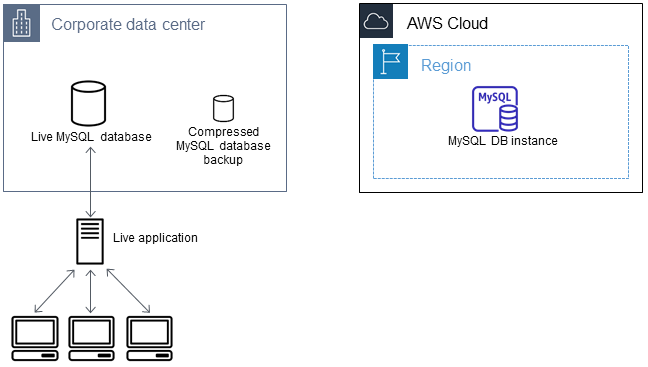
Das folgende Diagramm veranschaulicht die Erstellung eines Backups der MySQL-Datenbank.
Sie können das Hilfsprogramm mysqldump verwenden, um ein Datenbank-Backup im SQL-Format oder im separierten Textformat zu erstellen. Es wird empfohlen, mit jedem Format in einer Nichtproduktionsumgebung einen Testlauf durchzuführen, um festzustellen, welche Methode die Ausführungsdauer von mysqldump minimiert.
Wir empfehlen auch, dass Sie die Leistung von mysqldump gegenüber den Vorteilen einer Verwendung von separiertem Textformat beim Laden abwägen. Ein Backup, das ein separiertes Textformat verwendet, erstellt eine tabulatorseparierte Textdatei für jede verworfene Tabelle. Um den Zeitaufwand für den Import Ihrer Datenbank zu reduzieren, können Sie diese Dateien mit dem Befehl LOAD DATA LOCAL INFILE parallel laden. Weitere Informationen finden Sie unter Schritt 5: Laden der Daten im Verfahren zum Importieren von Daten aus einer beliebigen Quelle.
Bevor Sie mit dem Backup-Vorgang beginnen, müssen Sie die Optionen für die Replikation in der nach Amazon RDS zu kopierenden MySQL-Datenbank festlegen. Die Optionen für die Replikation schließen die Aktivierung der Binärprotokollierung und das Einstellen einer eindeutigen Server-ID mit ein. Das Einstellen dieser Optionen veranlasst den Server, mit der Protokollierung Ihrer Datenbanktransaktionen zu beginnen, und bereitet ihn darauf vor, später im Vorgang als Quellreplikationsinstance zu agieren.
Stellen Sie sicher, dass Sie die folgenden Empfehlungen und Überlegungen kennen:
-
Verwenden Sie die Option
--single-transactionmitmysqldump, da sie einen einheitlichen Zustand der Datenbank speichert. Um eine gültige Dump-Datei sicherzustellen, führen Sie beim Ausführen vonmysqldumpkeine DDL-Anweisungen (Data Definition Language) aus. Sie können ein Wartungsfenster für diese Abläufe planen. -
Schließen Sie die folgenden Schemas aus der Dump-Datei aus:
-
sys -
performance_schema -
information_schema
Das Dienstprogramm
mysqldumpschließt diese Schemas standardmäßig aus. -
-
Wenn Sie Benutzer und Berechtigungen migrieren müssen, sollten Sie ein Tool verwenden, das die Datenkontrollsprache (DCL, Data Control Language) für ihre Neuerstellung generiert, z. B. das Dienstprogramm pt-show-grants
.
So stellen Sie Optionen für die Replikation ein:
-
Bearbeiten Sie die
my.cnf-Datei. Diese Datei befindet sich normalerweise in/etc.sudo vi /etc/my.cnfFügen Sie die Optionen
log_binundserver_idzum Abschnitt[mysqld]hinzu. Die Optionlog_binbietet eine Dateinamenkennung für Binärprotokolldateien. Die Optionserver_idstellt eine eindeutige Kennung für den Server für Quelle-Replica-Beziehungen bereit.Im folgenden Beispiel ist der aktualisierte
[mysqld]-Abschnitt einermy.cnf-Datei angegeben:[mysqld] log-bin=mysql-bin server-id=1Weitere Informationen finden Sie unter Setting the Replication Master Configuration
in der MySQL-Dokumentation. -
Für die Replikation mit einem Multi-AZ DB-Cluster setzen Sie den
GTID_MODEParameterENFORCE_GTID_CONSISTENCYund aufON.mysql> SET @@GLOBAL.ENFORCE_GTID_CONSISTENCY = ON;mysql> SET @@GLOBAL.GTID_MODE = ON;Diese Einstellungen sind für die Replikation mit einer DB-Instance nicht erforderlich.
-
Den Service
mysqlneu starten.sudo service mysqld restart
So erstellen Sie eine Sicherungskopie für Ihre bestehende Datenbank:
-
Erstellen Sie ein Backup für Ihre Daten mithilfe des Hilfsprogramms
mysqldump, indem Sie entweder das SQL- oder separierte Textformat festlegen.Geben Sie bei MySQL 8.0.25 und älteren Versionen
--master-data=2an, um eine Backup-Datei zu erstellen, die für das Starten einer Replikation zwischen Servern verwendet werden kann. Geben Sie bei MySQL 8.0.26 und neueren Versionen--source-data=2an, um eine Backup-Datei zu erstellen, die für das Starten einer Replikation zwischen Servern verwendet werden kann. Weitere Informationen finden Sie unter mysqldump – A Database Backup Programin der MySQL-Dokumentation. Verwenden Sie die Optionen
--order-by-primaryund--single-transactionfürmysqldump., um die Leistung zu verbessern und die Datenintegrität sicherzustellen.Verwenden Sie die Option
--all-databasesnicht mitmysqldump, um die Einbindung der MySQL-Systemdatenbank im Backup zu vermeiden. Weitere Informationen finden Sie unter Creating a Data Snapshot Using mysqldumpin der MySQL-Dokumentation. Verwenden Sie bei Bedarf
chmod, um sicherzustellen, dass das Verzeichnis beschreibbar ist, in dem die Backup-Datei erstellt wird.Wichtig
Führen Sie unter Windows die Eingabeaufforderung als Administrator aus.
-
Verwenden Sie den folgenden Befehl, um eine SQL-Ausgabe zu erstellen:
Für Linux, macOS oder Unix:
sudo mysqldump \ --databasesdatabase_name\ --master-data=2 \ --single-transaction \ --order-by-primary \ -r backup.sql \ -ulocal_user\ -ppasswordAnmerkung
Geben Sie als bewährte Sicherheitsmethode andere Anmeldeinformationen als die in diesem Beispiel angegebenen Prompts an.
Für Windows:
mysqldump ^ --databasesdatabase_name^ --master-data=2 ^ --single-transaction ^ --order-by-primary ^ -r backup.sql ^ -ulocal_user^ -ppasswordAnmerkung
Geben Sie als bewährte Sicherheitsmethode andere Anmeldeinformationen als die in diesem Beispiel angegebenen Prompts an.
-
Verwenden Sie den folgenden Befehl, um eine separierte Textausgabe zu erstellen:
Für Linux, macOS oder Unix:
sudo mysqldump \ --tab=target_directory\ --fields-terminated-by ',' \ --fields-enclosed-by '"' \ --lines-terminated-by 0x0d0a \database_name\ --master-data=2 \ --single-transaction \ --order-by-primary \ -ppasswordFür Windows:
mysqldump ^ --tab=target_directory^ --fields-terminated-by "," ^ --fields-enclosed-by """ ^ --lines-terminated-by 0x0d0a ^database_name^ --master-data=2 ^ --single-transaction ^ --order-by-primary ^ -ppasswordAnmerkung
Geben Sie als bewährte Sicherheitsmethode andere Anmeldeinformationen als die in diesem Beispiel angegebenen Prompts an.
Stellen Sie sicher, dass Sie alle gespeicherten Prozeduren, Auslöser, Funktionen oder Ereignisse manuell in Ihrer Amazon-RDS-Datenbank erstellen. Falls Sie eines dieser Objekte in der Datenbank haben, die Sie kopieren, schließen Sie sie aus, wenn Sie
mysqldumpausführen. Fügen Sie dazu die folgenden Argumente in den Befehlmysqldumpein:-
--routines=0 -
--triggers=0 -
--events=0
Bei MySQL 8.0.22 und früheren Versionen wird der Kommentar
CHANGE MASTER TOzurückgegeben, wenn Siemysqldumpausführen und das separierte Textformat festlegen. Dieser Kommentar beinhaltet den Namen und die Position der Hauptprotokolldatei. Bei MySQL 8.0.23 und neueren Versionen wird der KommentarCHANGE REPLICATION SOURCE TOzurückgegeben, wenn Siemysqldumpmithilfe des separierten Textformats ausführen. Dieser Kommentar beinhaltet den Namen und die Position der Quellprotokolldatei. Wenn es sich bei der externen Instance um MySQL 8.0.23 oder eine neuere Version handelt, notieren Sie die Werte fürMASTER_LOG_FILEundMASTER_LOG_POS. Sie benötigen diese Werte beim Einrichten der Replikation.Die folgende Ausgabe wird für MySQL 8.0.22 und frühere Versionen zurückgegeben:
-- Position to start replication or point-in-time recovery from -- -- CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin-changelog.000031', MASTER_LOG_POS=107;Die folgende Ausgabe wird für MySQL 8.0.23 und neuere Versionen zurückgegeben:
-- Position to start replication or point-in-time recovery from -- -- CHANGE SOURCE TO SOURCE_LOG_FILE='mysql-bin-changelog.000031', SOURCE_LOG_POS=107;Wenn Sie bei MySQL 8.0.22 und früheren Versionen das SQL-Format verwenden, können Sie den Namen und die Position der Hauptprotokolldatei im Kommentar
CHANGE MASTER TOin der Backup-Datei abrufen. Wenn Sie bei MySQL 8.0.23 und neueren Versionen das SQL-Format verwenden, können Sie den Namen und die Position der Quellprotokolldatei im KommentarCHANGE REPLICATION SOURCE TOin der Backup-Datei abrufen. -
-
-
Komprimieren Sie die kopierten Daten, um die Menge der Netzwerkressourcen zu reduzieren, die benötigt werden, um Ihre Daten in eine Amazon-RDS-Datenbank zu kopieren. Notieren Sie sich die Größe der Backup-Datei. Diese Informationen benötigen Sie, um die Größe der zu erstellenden Amazon-EC2-Instance zu bestimmen. Wenn Sie fertig sind, komprimieren Sie die Sicherungsdatei mithilfe von GZIP oder Ihrem bevorzugten Komprimierungsprogramm.
-
Verwenden Sie den folgenden Befehl, um eine SQL-Ausgabe zu komprimieren:
gzip backup.sql -
Verwenden Sie den folgenden Befehl, um eine separierte Textausgabe zu komprimieren:
tar -zcvf backup.tar.gztarget_directory
-
Aufgabe 2: Erstellen einer Amazon EC2-Instance und Kopieren der komprimierten Datenbank
Das Kopieren Ihrer komprimierten Datenbank-Sicherungsdatei in eine Amazon EC2-Instance verbraucht weniger Netzwerkressourcen als eine direkte Kopie von unkomprimierten Daten zwischen Datenbank-Instances. Wenn sich die Daten in Amazon EC2 befinden, können Sie diese von dort direkt in die MySQL-Datenbank kopieren. Damit Sie Kosten für Netzwerkressourcen sparen können, muss sich Ihre Amazon EC2 EC2-Instance in derselben Konfiguration AWS-Region wie Ihre Amazon RDS-DB-Instance befinden. Wenn sich die Amazon EC2-Instance in derselben AWS-Region wie die Amazon-RDS-Datenbank befindet, wird auch die Netzwerklatenz während des Importvorgangs reduziert.
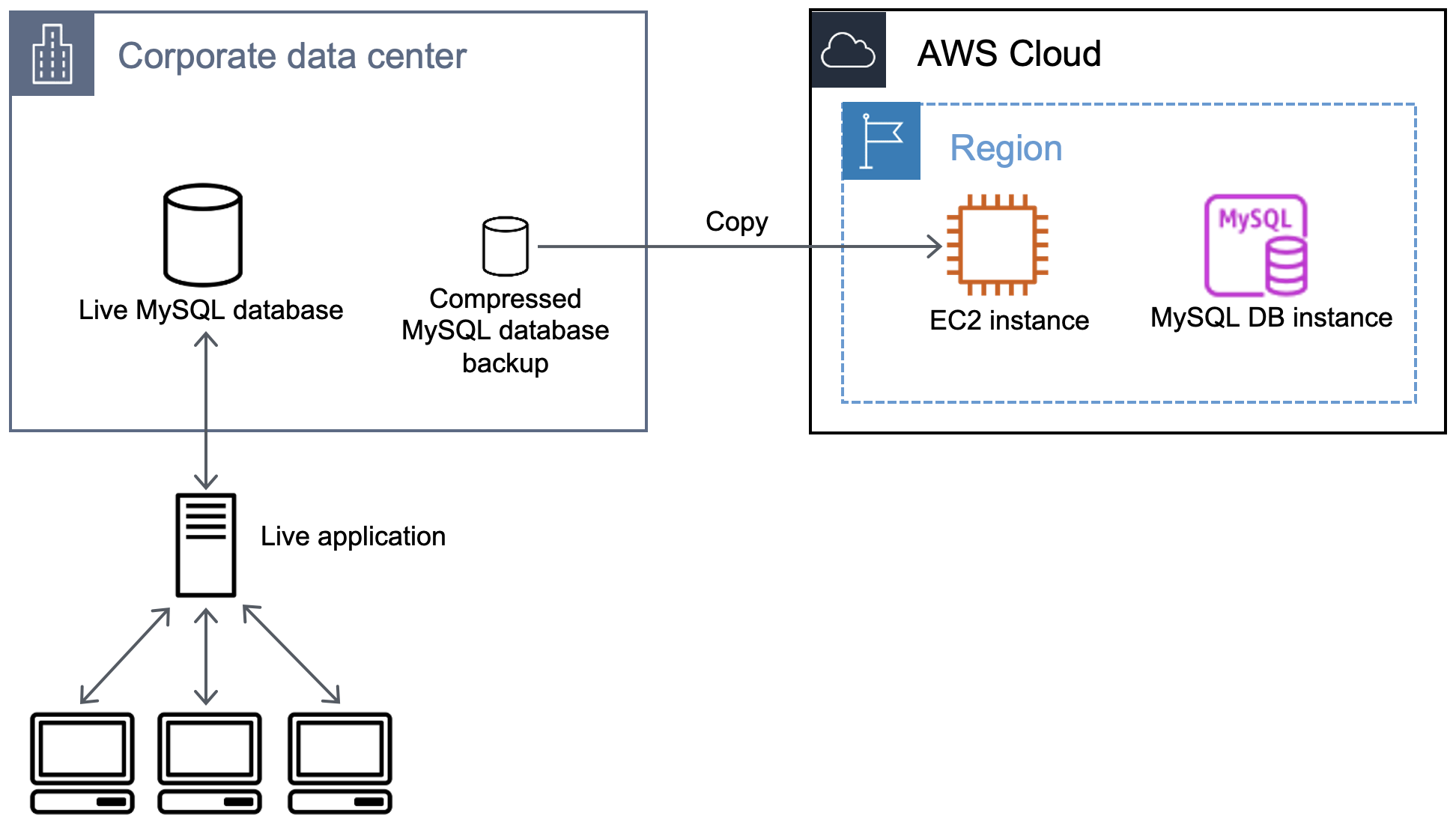
Das folgende Diagramm veranschaulicht den Kopiervorgang des Datenbank-Backups in eine Amazon EC2-Instance.
So erstellen Sie eine Amazon EC2-Instance und kopieren Ihre Daten:
-
Erstellen Sie in AWS-Region dem Bereich, in dem Sie die Amazon RDS-Datenbank erstellen möchten, eine Virtual Private Cloud (VPC), eine VPC-Sicherheitsgruppe und ein VPC-Subnetz. Stellen Sie sicher, dass die eingehenden Regeln für Ihre VPC-Sicherheitsgruppe IP-Adressen zulassen, die für eine Verbindung Ihrer Anwendung mit erforderlich sin AWS. Sie können einen IP-Adressbereich (z. B.
203.0.113.0/24) oder eine andere VPC-Sicherheitsgruppe festlegen. Sie können die Amazon VPC-Konsoleverwenden, um VPCs, Subnetze und Sicherheitsgruppen zu erstellen und zu verwalten. Weitere Informationen finden Sie unter Erste Schritte mit Amazon VPC im Amazon Virtual Private Cloud-Benutzerhandbuch. -
Öffnen Sie die Amazon EC2 EC2-Konsole
und wählen Sie die aus AWS-Region , die sowohl Ihre Amazon EC2 EC2-Instance als auch Ihre Amazon RDS-Datenbank enthalten soll. Starten Sie eine Amazon EC2-Instance unter Verwendung der VPC, dem Subnetz und der Sicherheitsgruppe, die Sie in Schritt 1 erstellt haben. Stellen Sie sicher, dass Sie einen Instance-Typ mit genügend Speicherplatz für Ihre unkomprimierte Datenbank-Sicherungsdatei ausgewählt haben. Weitere Informationen zu Amazon EC2-Instances finden Sie unter Erste Schritte mit Amazon EC2 im Amazon Elastic Compute Cloud-Benutzerhandbuch. -
Wenn Sie sich von Ihrer Amazon-EC2-Instance mit Ihrer Amazon-RDS-Datenbank verbinden möchten, bearbeiten Sie Ihre VPC-Sicherheitsgruppe. Fügen Sie eine Regel für eingehenden Datenverkehr hinzu, in der die private IP-Adresse Ihrer EC2-Instance angegeben ist. Die private IP-Adresse finden Sie auf der Registerkarte Details im Bereich Instance des EC2-Konsolenfensters. Wählen Sie zuerst Sicherheitsgruppen im Navigationsbereich der EC2-Konsole und dann Ihre Sicherheitsgruppe aus und fügen Sie anschließend eine Regel für eingehenden Datenverkehr für MySQL oder Aurora hinzu, die die private IP-Adresse Ihrer EC2-Instance angibt, um Ihre VPC-Sicherheitsgruppe zu bearbeiten und eine Regel für eingehenden Datenverkehr hinzuzufügen. Weitere Informationen zum Hinzufügen einer Regel für eingehenden Datenverkehr zu einer VPC-Sicherheitsgruppe finden Sie unter Sicherheitsgruppenregeln im Amazon Virtual Private Cloud-Benutzerhandbuch.
-
Kopieren Sie Ihre komprimierte Datenbank-Sicherungsdatei aus Ihrem lokalen System in Ihre Amazon EC2-Instance. Verwenden Sie bei Bedarf
chmod, um sicherzustellen, dass Sie Schreibrechte für das Zielverzeichnis der Amazon EC2-Instance besitzen. Sie könnenscpoder einen Secure-Shell(SSH)-Client verwenden, um die Datei zu kopieren. Nachfolgend finden Sie ein Beispiel für einenscp-Befehl:scp -r -ikey pair.pem backup.sql.gz ec2-user@EC2 DNS:/target_directory/backup.sql.gzWichtig
Vergewissern Sie sich beim Kopieren von sensiblen Daten, dass Sie ein sicheres Netzwerk-Übertragungsprotokoll verwenden.
-
Verbinden Sie sich mit Ihrer Amazon EC2-Instance und installieren Sie die neusten Updates und MySQL-Client-Tools mithilfe der folgenden Befehle:
sudo yum update -y sudo yum install mysql -yWeitere Informationen finden Sie unter Herstellen einer Verbindung mit Ihrer Instance für Linux-Instances im Amazon Elastic Compute Cloud-Benutzerhandbuch.
Wichtig
In diesem Beispiel wird der MySQL-Client auf einem Amazon Machine Image (AMI) für eine Amazon-Linux-Verteilung installiert. Mit diesem Beispiel kann der MySQL-Client nicht auf einer anderen Verteilung wie Ubuntu oder Red Hat Enterprise Linux installiert werden. Informationen zum Installieren von MySQL finden Sie unter Installation von MySQL
in der MySQL-Dokumentation. -
Solange Sie mit Ihrer Amazon EC2-Instance verbunden sind, dekomprimieren Sie Ihre Datenbank-Sicherungsdatei. Die folgenden Befehle sind Beispiele.
-
Verwenden Sie den folgenden Befehl, um eine SQL-Ausgabe zu extrahieren:
gzip backup.sql.gz -d -
Verwenden Sie den folgenden Befehl, um eine separierte Textausgabe zu extrahieren:
tar xzvf backup.tar.gz
-
Aufgabe 3: Erstellen einer MySQL-Datenbank und Importieren von Daten aus der Amazon EC2-Instance
Indem Sie eine RDS for MySQL-DB-Instance oder einen RDS for Multi-AZ MySQL-DB-Cluster in derselben Umgebung AWS-Region wie Ihre Amazon EC2-Instance erstellen, können Sie die Datenbank-Backup-Datei schneller als über das Internet aus Amazon EC2 importieren.
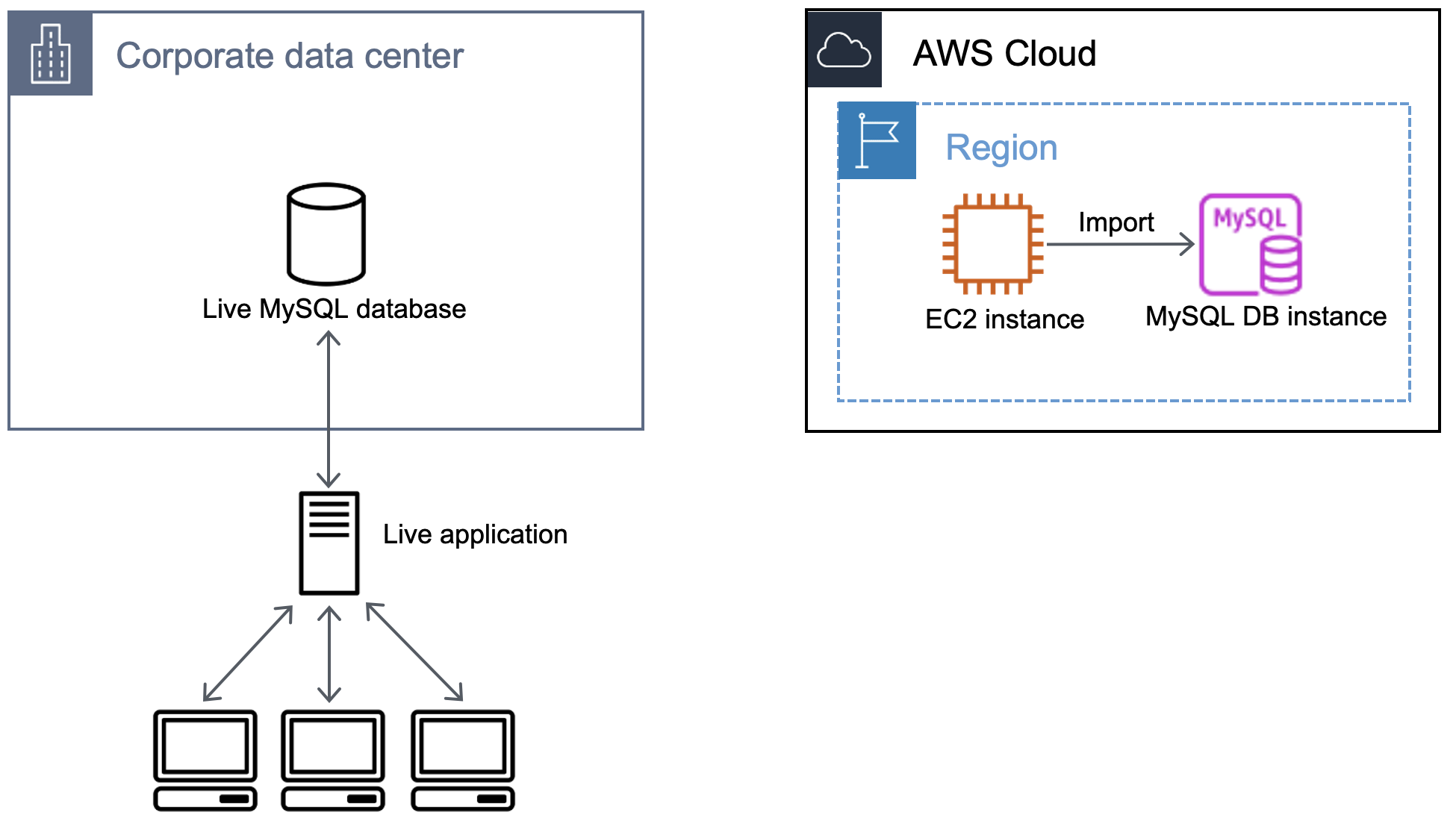
Das folgende Diagramm veranschaulicht den Importvorgang der Backup-Datei von einer Amazon EC2-Instance in eine MySQL-Datenbank.
So erstellen Sie eine MySQL-Datenbank und importieren Ihre Daten
-
Bestimmen Sie, welche DB-Instance-Klasse und wie viel Speicherplatz erforderlich sind, um den erwarteten Workload für diese Amazon-RDS-Datenbank unterstützen zu können. Bei diesem Vorgang sollten Sie auch entscheiden, wie viel Speicherplatz und Verarbeitungskapazität für Ihre Datenladevorgänge ausreichen. Entscheiden Sie auch, was für den Umgang mit dem Produktions-Workload erforderlich ist. Sie können diese Faktoren anhand der Größe und der Ressourcen der MySQL-Quelldatenbank einschätzen. Weitere Informationen finden Sie unter DB-Instance-Klassen.
-
Erstellen Sie eine DB-Instance oder einen Multi-AZ DB-Cluster in dem AWS-Region , der Ihre Amazon EC2 EC2-Instance enthält.
Folgen Sie den Anweisungen unter, um einen RDS for Multi-AZ MySQL-DB-Cluster zu erstellenEinen Multi-AZ DB-Cluster für Amazon RDS erstellen.
Wenn Sie eine DB-Instance von RDS für MySQL erstellen möchten, befolgen Sie die Anweisungen unter Erstellen einer Amazon-RDS-DB-Instance und verwenden Sie die folgenden Richtlinien:
-
Geben Sie eine DB-Engine-Version an, die mit Ihrer Quell-DB-Instance kompatibel ist.
-
Geben Sie dieselbe Virtual Private Cloud (VPC) und VPC-Sicherheitsgruppe an, die Sie auch für die Amazon-EC2-Instance ausgewählt haben. Durch diesen Ansatz wird sichergestellt, dass Ihre Amazon EC2-Instance und Ihre Amazon-RDS-Instance im Netzwerk gegenseitig füreinander sichtbar sind. Stellen Sie sicher, dass Ihre DB-Instance öffentlich zugänglich ist. Ihre DB-Instance muss öffentlich zugänglich sein, um eine Replikation für Ihre Quelldatenbank einzurichten, wie in einem späteren Abschnitt beschrieben wird.
-
Konfigurieren Sie nicht mehrere Availability Zones, Backup-Aufbewahrungen oder Lesereplikate, nachdem Sie das Datenbank-Backup importiert haben. Wenn dieser Import abgeschlossen ist, können Sie die Aufbewahrung für die Produktionsinstanz konfigurieren Multi-AZ und sichern.
-
-
Überprüfen Sie die Optionen der Standardkonfiguration für die Amazon-RDS-Datenbank. Wenn in der Standardparametergruppe für die Datenbank die von Ihnen gewünschten Optionen nicht konfiguriert sind, wählen Sie eine andere aus, die die entsprechenden Konfigurationsoptionen enthält, oder erstellen Sie eine neue Parametergruppe. Weitere Informationen zum Erstellen einer Parametergruppe finden Sie unter Parametergruppen für Amazon RDS.
-
Stellen Sie als Hauptbenutzer eine Verbindung mit der neuen Amazon-RDS-Datenbank her. Erstellen Sie die Benutzer, die erforderlich sind, um die Administratoren, Anwendungen und Services zu unterstützen, die auf die DB-Instance zugreifen müssen. Der Hostname für die Amazon-RDS-Datenbank ist ihr Endpunktwert für diese DB-Instance ohne die Portnummer, z. B.
mysampledb.123456789012.us-west-2.rds.amazonaws.com. Sie finden den Endpunktwert in den Datenbankdetails der Amazon-RDS-Konsole. -
Stellen Sie eine Verbindung zu Ihrer Amazon-EC2-Instance her. Weitere Informationen finden Sie unter Herstellen einer Verbindung mit Ihrer Instance für Linux-Instances im Amazon Elastic Compute Cloud-Benutzerhandbuch.
-
Stellen Sie als Remote-Host eine Verbindung mit Ihrer Amazon-RDS-Datenbank von Ihrer Amazon-EC2-Instance aus mithilfe des Befehls
mysqlher. Der folgende Befehl ist ein Beispiel:mysql -hhost_name-P 3306 -udb_master_user-pDas
host_nameist der Amazon RDS-Datenbank-Endpunkt. -
Führen Sie an der Eingabeaufforderung
mysqlden Befehlsourceaus und tragen Sie den Namen der Datenbank-Dumpdatei ein. Mit diesem Befehl werden die Daten in die Amazon-RDS-DB-Instance geladen.-
Verwenden Sie für das SQL-Format den folgenden Befehl:
mysql> source backup.sql; -
Für das separierte Textformat erstellen Sie zuerst die Datenbank, wenn es sich nicht um die Standarddatenbank handelt, die Sie bei der Einrichtung der Amazon-RDS-Datenbank erstellt haben.
mysql> create databasedatabase_name; mysql> usedatabase_name;Erstellen Sie anschließend die Tabellen.
mysql> sourcetable1.sql mysql> sourcetable2.sql etc...Importieren Sie dann die Daten.
mysql> LOAD DATA LOCAL INFILE 'table1.txt' INTO TABLE table1 FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '0x0d0a'; mysql> LOAD DATA LOCAL INFILE 'table2.txt' INTO TABLE table2 FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '0x0d0a'; etc...Zur Verbesserung der Leistung können Sie diese Operationen parallel aus mehreren Verbindungen ausführen, damit alle Ihre Tabellen erstellt und die Daten anschließend gleichzeitig geladen werden.
Anmerkung
Wenn Sie Optionen für eine Datenformatierung mit
mysqldumpbeim ersten Verwerfen der Tabelle verwendet haben, müssen Sie nun dieselben Optionen mitLOAD DATA LOCAL INFILEverwenden, um eine richtige Interpretation der Datendateiinhalte sicherzustellen.
-
-
Führen Sie eine einfache
SELECT-Abfrage anhand einer oder zwei der Tabellen in der importierten Datenbank durch, um zu prüfen, ob der Importvorgang erfolgreich abgeschlossen wurde.
Wenn Sie die in diesem Verfahren verwendete Amazon EC2 EC2-Instance nicht mehr benötigen, beenden Sie die EC2-Instance, um Ihren AWS Ressourcenverbrauch zu reduzieren. Weitere Informationen zum Beenden einer EC2-Instance finden Sie unter Beenden einer Instance im Amazon Elastic Compute Cloud-Benutzerhandbuch.
Aufgabe 4: Replizieren von Daten aus der externen Datenbank in die neue Amazon-RDS-Datenbank
Die Quelldatenbank wurde in der Zeit, in der die Daten in die MySQL-Datenbank kopiert und übertragen wurden, wahrscheinlich aktualisiert. In diesem Fall können Sie die kopierte Datenbank mithilfe der Replikation auf den Stand der Quelldatenbank bringen.
Die erforderlichen Berechtigungen für das Starten einer Replikation in einer Amazon-RDS-Datenbank sind beschränkt und für den Amazon-RDS-Hauptbenutzer nicht verfügbar. Verwenden Sie daher die entsprechende gespeicherte Amazon-RDS-Prozedur für die Engine-Hauptversion:
-
mysql_rds_set_external_master (Hauptversionen von RDS für MySQL 8.0 und frühere Versionen)
-
mysql.rds_set_external_source (RDS-für-MySQL-Hauptversionen 8.4 und höher)
-
mysql.rds_set_external_master_gtid zum Konfigurieren der Replikation und mysql.rds_start_replication zum Starten der Replikation
So starten Sie eine Replikation:
In Aufgabe 1 haben Sie bei der Festlegung der Replikationsoptionen die Binärprotokollierung aktiviert und eine eindeutige Server-ID für die Quelldatenbank festgelegt. Jetzt können Sie Ihre Amazon-RDS-Datenbank als Replikat mit Ihrer Live-Datenbank als Quellreplikations-Instance einrichten.
-
Fügen Sie in der Amazon-RDS-Konsole die IP-Adresse des Servers, der die Quelldatenbank hostet, zur VPC-Sicherheitsgruppe dieser Amazon-RDS-Datenbank hinzu. Weitere Informationen zum Konfigurieren einer VPC-Sicherheitsgruppe finden Sie unter Konfigurieren von Sicherheitsgruppenregeln im Amazon Virtual Private Cloud-Benutzerhandbuch.
Möglicherweise müssen Sie Ihr lokales Netzwerk so konfigurieren, dass es Verbindungen von der IP-Adresse Ihrer Amazon-RDS-Datenbank zulässt, damit es mit Ihrer Quell-Instance kommunizieren kann. Verwenden Sie den Befehl
host, um die IP-Adresse der Amazon-RDS-Datenbank zu ermitteln.hosthost_nameDas
host_nameist zum Beispiel der DNS-Name vom Amazon RDS-Datenbank-Endpunktmyinstance.123456789012.us-east-1.rds.amazonaws.com. Sie finden den Endpunktwert in den DB-Instance-Details in der Amazon-RDS-Konsole. -
Verbinden Sie sich mithilfe eines Clients Ihrer Wahl mit der Quell-Instance und erstellen Sie einen Benutzer, der für die Replikation verwendet werden soll. Dieses Konto wird ausschließlich für die Replikation verwendet und muss auf Ihre Domäne beschränkt sein, um die Sicherheit zu erhöhen. Der folgende Befehl ist ein Beispiel:
CREATE USER 'repl_user'@'mydomain.com' IDENTIFIED BY 'password';Anmerkung
Geben Sie aus Sicherheitsgründen andere Anmeldeinformationen als hier angegeben an.
-
Erteilen Sie für die Quell-Instance die Sonderrechte
REPLICATION CLIENTundREPLICATION SLAVEfür Ihren Replikationsbenutzer. Erteilen Sie beispielsweise die SonderrechteREPLICATION CLIENTundREPLICATION SLAVEin allen Datenbanken für denrepl_user-Benutzer für Ihre Domäne, mit dem folgenden Befehl:GRANT REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'repl_user'@'mydomain.com'; -
Konfigurieren Sie die Amazon-RDS-Datenbank als Replikat. Stellen Sie eine Verbindung mit der Amazon-RDS-Datenbank als Masterbenutzer her und identifizieren Sie die Quelldatenbank mithilfe der entsprechenden gespeicherten Amazon-RDS-Prozedur als Quellreplikations-Instance.
Wenn Sie über eine Backup-Datei im SQL-Format verfügen, verwenden Sie den Namen der Hauptprotokolldatei und die Position des Hauptprotokolls, die Sie beide in Schritt 4 ermittelt haben. Wenn Sie das separierte Textformat genutzt haben, verwenden Sie den Namen und die Position, die Sie beide beim Erstellen der Backup-Dateien ermittelt haben. Die folgenden Befehle sind Beispiele.
MySQL 8.4 und neuere Versionen
CALL mysql.rds_set_external_source ('myserver.mydomain.com', 3306, 'repl_user', 'password', 'mysql-bin-changelog.000031', 107, 1);MySQL 8.0 und frühere Versionen
CALL mysql.rds_set_external_master ('myserver.mydomain.com', 3306, 'repl_user', 'password', 'mysql-bin-changelog.000031', 107, 1);Anmerkung
Geben Sie aus Sicherheitsgründen andere Anmeldeinformationen als hier angegeben an.
-
Um die Replikation in der Amazon-RDS-Datenbank zu starten, führen Sie den folgenden Befehl aus, der die gespeicherte Prozedur mysql.rds_start_replication verwendet:
CALL mysql.rds_start_replication; -
Führen Sie in der Amazon-RDS-Datenbank den Befehl SHOW REPLICA STATUS
aus, um festzustellen, wann das Replikat auf dem aktuellen Stand der Quellreplikations-Instance ist. Zu den Ergebnissen des SHOW REPLICA STATUS-Befehls gehört das FeldSeconds_Behind_Master. Wenn das FeldSeconds_Behind_Master0 zurückgibt, ist das Replikat auf dem aktuellen Stand der Quellreplikations-Instance.Anmerkung
Frühere Versionen von MySQL verwenden
SHOW SLAVE STATUSanstelle vonSHOW REPLICA STATUS. Wenn Sie vor 8.0.23 eine MySQL-Version verwenden, verwenden SiSHOW SLAVE STATUS. -
Nachdem die Amazon-RDS-Datenbank auf den aktuellen Stand gebracht wurde, aktivieren Sie die automatischen Backups, damit Sie diese Datenbank bei Bedarf wiederherstellen können. Sie können automatische Backups für die Amazon-RDS-Datenbank mithilfe der Amazon-RDS-Konsole
aktivieren oder ändern. Weitere Informationen finden Sie unter Einführung in Backups.
Aufgabe 5: Weiterleiten der Live-Anwendung an die Amazon-RDS-Instance
Wenn die MySQL-Datenbank auf den aktuellen Stand der Quellreplikations-Instance gebracht wurde, können Sie nun die Live-Anwendung aktualisieren, damit sie die Amazon-RDS-Instance nutzt.

So leiten Sie die Live-Anwendung an die MySQL-Datenbank weiter und halten die Replikation an
-
Fügen Sie die IP-Adresse des Host-Servers der Anwendung hinzu, um die VPC-Sicherheitsgruppe für Ihre Amazon-RDS-Datenbank hinzuzufügen. Weitere Informationen zum Ändern einer VPC-Sicherheitsgruppe finden Sie unter Konfigurieren von Sicherheitsgruppenregeln im Amazon Virtual Private Cloud-Benutzerhandbuch.
-
Vergewissern Sie sich, dass das Feld
Seconds_Behind_Masterim Ergebnis des Befehls SHOW REPLICA STATUS0 ist, was darauf hinweist, dass das Replikat auf dem neuesten Stand mit der Quellreplikations-Instance ist. SHOW REPLICA STATUS;Anmerkung
Frühere Versionen von MySQL verwenden
SHOW SLAVE STATUSanstelle vonSHOW REPLICA STATUS. Wenn Sie vor 8.0.23 eine MySQL-Version verwenden, verwenden SiSHOW SLAVE STATUS. -
Schließen Sie alle Verbindungen zur Quelle, nachdem ihre Transaktionen abgeschlossen sind.
-
Aktualisieren Sie Ihre Anwendung, um die Amazon-RDS-Datenbank zu nutzen. Dieses Update ändert die Verbindungseinstellungen, um den Hostnamen und den Port der Amazon-RDS-Datenbank, das Benutzerkonto und Passwort für die Verbindung und die zu verwendende Datenbank zu bestimmen.
-
Stellen Sie eine Verbindung mit der DB-Instance her.
Stellen Sie für einen Multi-AZ DB-Cluster eine Verbindung zur Writer-DB-Instance her.
-
Halten Sie die Replikation für die Amazon-RDS-Instance an, indem Sie den folgenden Befehl ausführen, der die gespeicherte Prozedur mysql.rds_stop_replication verwendet:
CALL mysql.rds_stop_replication; -
Setzen Sie die Replikationskonfiguration zurück, damit diese Instance nicht mehr als Replikat identifiziert wird, indem Sie die entsprechende gespeicherte Amazon-RDS-Prozedur in der Amazon-RDS-Datenbank verwenden:
MySQL 8.4 und neuere Versionen
CALL mysql.rds_reset_external_source;MySQL 8.0 und frühere Versionen
CALL mysql.rds_reset_external_master; -
Aktivieren Sie zusätzliche Amazon RDS-Funktionen wie Multi-AZ Support und Read Replicas. Weitere Informationen erhalten Sie unter Konfiguration und Verwaltung einer Multi-AZ Bereitstellung für Amazon RDS und Arbeiten mit DB-Instance-Lesereplikaten.
