Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
AWS CLI Beispiele für Performance Insights
In den folgenden Abschnitten erfahren Sie mehr über das AWS Command Line Interface (AWS CLI) für Performance Insights und AWS CLI Anwendungsbeispiele.
Themen
Built-in Hilfe für AWS CLI für Performance Insights
Sie können Performance-Insights-Daten über die anzeige AWS CLI. Sie können die Hilfe zu den AWS CLI Befehlen für Performance Insights anzeigen, indem Sie in der Befehlszeile Folgendes eingeben.
aws pi help
Falls Sie das nicht AWS CLI installiert haben, finden Sie unter Installation von AWS CLI im AWS CLI Benutzerhandbuch weitere Informationen zur Installation.
Abrufen von Zählermetriken
Der folgende Screenshot zeigt zwei Zählermetriken-Diagramme in der AWS-Managementkonsole.
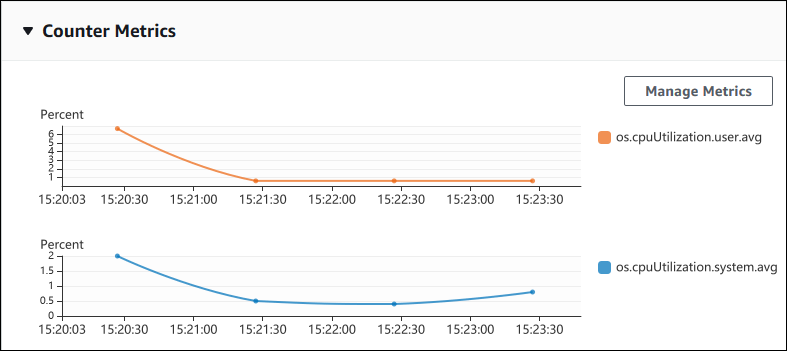
Das folgende Beispiel zeigt, wie dieselben Daten erfasst werden, die er zur Generierung der beiden Zählermetrikdiagramme AWS-Managementkonsole verwendet.
Für Linux, macOS oder Unix:
aws pi get-resource-metrics \ --service-type RDS \ --identifier db-ID\ --start-time2018-10-30T00:00:00Z\ --end-time2018-10-30T01:00:00Z\ --period-in-seconds60\ --metric-queries '[{"Metric": "os.cpuUtilization.user.avg" }, {"Metric": "os.cpuUtilization.idle.avg"}]'
Für Windows:
aws pi get-resource-metrics ^ --service-type RDS ^ --identifier db-ID^ --start-time2018-10-30T00:00:00Z^ --end-time2018-10-30T01:00:00Z^ --period-in-seconds60^ --metric-queries '[{"Metric": "os.cpuUtilization.user.avg" }, {"Metric": "os.cpuUtilization.idle.avg"}]'
Sie können einen Befehl besser lesbar gestalten, indem Sie eine Datei für die Option --metrics-query angeben. Im folgenden Beispiel wird eine Datei namens query.json für die Option verwendet. Die Datei enthält Folgendes.
[ { "Metric": "os.cpuUtilization.user.avg" }, { "Metric": "os.cpuUtilization.idle.avg" } ]
Führen Sie den folgenden Befehl aus, um die Datei zu verwenden.
Für Linux, macOS oder Unix:
aws pi get-resource-metrics \ --service-type RDS \ --identifier db-ID\ --start-time2018-10-30T00:00:00Z\ --end-time2018-10-30T01:00:00Z\ --period-in-seconds60\ --metric-queries file://query.json
Für Windows:
aws pi get-resource-metrics ^ --service-type RDS ^ --identifier db-ID^ --start-time2018-10-30T00:00:00Z^ --end-time2018-10-30T01:00:00Z^ --period-in-seconds60^ --metric-queries file://query.json
Das vorige Beispiel gibt die folgenden Werte für die Optionen an:
-
--service-type–RDSfür Amazon RDS -
--identifier– Die Ressource-ID für die DB-Instance -
--start-timeund--end-time– Die ISO 8601-WerteDateTimefür den abzufragenden Zeitraum mit mehreren unterstützten Formaten
Der Abfragezeitraum beträgt eine Stunde:
-
--period-in-seconds–60für eine Abfrage pro Minute -
--metric-queries– Ein Array mit zwei Abfragen, jeweils für nur eine Metrik.Der Metrikname verwendet Punkte, um die Metrik in eine sinnvolle Kategorie einzustufen, wobei das letzte Element eine Funktion ist. Im Beispiel lautet die Funktion
avgfür jede Abfrage. Wie bei Amazon CloudWatch sind die unterstützten Funktionenminmax,total, undavg.
Die Antwort sieht in etwa so aus:
{ "Identifier": "db-XXX", "AlignedStartTime": 1540857600.0, "AlignedEndTime": 1540861200.0, "MetricList": [ { //A list of key/datapoints "Key": { "Metric": "os.cpuUtilization.user.avg" //Metric1 }, "DataPoints": [ //Each list of datapoints has the same timestamps and same number of items { "Timestamp": 1540857660.0, //Minute1 "Value": 4.0 }, { "Timestamp": 1540857720.0, //Minute2 "Value": 4.0 }, { "Timestamp": 1540857780.0, //Minute 3 "Value": 10.0 } //... 60 datapoints for the os.cpuUtilization.user.avg metric ] }, { "Key": { "Metric": "os.cpuUtilization.idle.avg" //Metric2 }, "DataPoints": [ { "Timestamp": 1540857660.0, //Minute1 "Value": 12.0 }, { "Timestamp": 1540857720.0, //Minute2 "Value": 13.5 }, //... 60 datapoints for the os.cpuUtilization.idle.avg metric ] } ] //end of MetricList } //end of response
Die Antwort enthält Werte für Identifier, AlignedStartTime und AlignedEndTime. Bei einem --period-in-seconds-Wert von 60 wurden Start- und Endzeiten auf die Minute ausgerichtet. Wenn der --period-in-seconds-Wert 3600 lautet, werden Start- und Endzeiten auf die Stunde ausgerichtet.
Die MetricList in der Antwort enthält eine Reihe von Einträgen, und zwar jeweils mit einem Key- und einem DataPoints-Eintrag. Jeder DataPoint verfügt über einen Timestamp und einen Value. Jede Datapoints-Liste enthält 60 Datenpunkte, da die Abfragen eine Stunde lang jede Minute Daten abfragen, und zwar mit den Werten Timestamp1/Minute1, Timestamp2/Minute2 usw. bis Timestamp60/Minute60.
Da sich die Abfrage auf zwei verschiedene Zählermetriken bezieht, enthält die -Antwort zwei Element MetricList.
Abrufen des DB-Lastdurchschnitts für Top-Warteereignisse
Das folgende Beispiel ist dieselbe Abfrage, die AWS-Managementkonsole verwendet wird, um ein gestapeltes Flächenliniendiagramm zu generieren. Mit diesem Beispiel wird der db.load.avg-Wert für die letzte Stunde abgerufen, wobei die Last auf die sieben Top-Warteereignisse aufgeteilt ist. Der Befehl ist mit dem Befehl unter identisc Abrufen von Zählermetriken. Die Datei query.json enthält hingegen Folgendes.
[ { "Metric": "db.load.avg", "GroupBy": { "Group": "db.wait_event", "Limit": 7 } } ]
Führen Sie den folgenden Befehl aus.
Für Linux, macOS oder Unix:
aws pi get-resource-metrics \ --service-type RDS \ --identifier db-ID\ --start-time2018-10-30T00:00:00Z\ --end-time2018-10-30T01:00:00Z\ --period-in-seconds60\ --metric-queries file://query.json
Für Windows:
aws pi get-resource-metrics ^ --service-type RDS ^ --identifier db-ID^ --start-time2018-10-30T00:00:00Z^ --end-time2018-10-30T01:00:00Z^ --period-in-seconds60^ --metric-queries file://query.json
Das Beispiel gibt die Metrik db.load.avg und eine GroupBy-Sortierung der sieben Top-Warteereignisse an. Einzelheiten zu gültigen Werten für dieses Beispiel finden Sie DimensionGroupin der Performance Insights API-Referenz.
Die Antwort sieht in etwa so aus:
{ "Identifier": "db-XXX", "AlignedStartTime": 1540857600.0, "AlignedEndTime": 1540861200.0, "MetricList": [ { //A list of key/datapoints "Key": { //A Metric with no dimensions. This is the total db.load.avg "Metric": "db.load.avg" }, "DataPoints": [ //Each list of datapoints has the same timestamps and same number of items { "Timestamp": 1540857660.0, //Minute1 "Value": 0.5166666666666667 }, { "Timestamp": 1540857720.0, //Minute2 "Value": 0.38333333333333336 }, { "Timestamp": 1540857780.0, //Minute 3 "Value": 0.26666666666666666 } //... 60 datapoints for the total db.load.avg key ] }, { "Key": { //Another key. This is db.load.avg broken down by CPU "Metric": "db.load.avg", "Dimensions": { "db.wait_event.name": "CPU", "db.wait_event.type": "CPU" } }, "DataPoints": [ { "Timestamp": 1540857660.0, //Minute1 "Value": 0.35 }, { "Timestamp": 1540857720.0, //Minute2 "Value": 0.15 }, //... 60 datapoints for the CPU key ] }, //... In total we have 8 key/datapoints entries, 1) total, 2-8) Top Wait Events ] //end of MetricList } //end of response
In dieser Antwort gibt es acht Einträge in der MetricList. Davon bezieht sich ein Eintrag auf den db.load.avg-Gesamtwert und sieben Einträge jeweils auf den db.load.avg-Wert, der auf eines der sieben Top-Warteereignisse aufgeteilt ist. Im Gegensatz zum ersten Beispiel, bei dem eine Gruppierungsdimension vorlag, muss für jede Gruppierung der Metrik ein Schlüssel vorliegen. Für jede Metrik kann nicht nur ein Schlüssel vorhanden sein, wie im Anwendungsfall der Basiszählermetrik.
Abrufen des DB-Lastdurchschnitts für Top-SQL-Anweisungen
Im folgenden Beispiel werden db.wait_events entsprechend der 10 Top-SQL-Anweisungen gruppiert. Es gibt zwei verschiedene Gruppen für SQL-Anweisungen.
-
db.sql– Die vollständige SQL-Anweisung, wieselect * from customers where customer_id = 123 -
db.sql_tokenized– Die SQL-Anweisung mit Token, wieselect * from customers where customer_id = ?
Beim Analysieren der Datenbank-Performance kann es nützlich sein, SQL-Anweisungen, die sich nur durch ihre Parameter unterscheiden, als ein logisches Element zu betrachten. In diesem Fall können Sie db.sql_tokenized beim Abfragen verwenden. In manchen Fällen, insbesondere wenn Sie an Explain-Plänen interessiert sind, ist es jedoch sinnvoller, die vollständigen SQL-Anweisungen mit Parametern zu untersuchen und die Abfrage nach db.sql zu gruppieren. Zwischen SQL-Anweisungen mit Token und vollständigen SQL-Anweisungen besteht eine Beziehung der Über-/Unterordnung. Mehrere vollständige (untergeordnete) SQL-Anweisungen befinden sich unter derselben (übergeordneten) SQL-Anweisung mit Token.
Der Befehl in diesem Beispiel ähnelt dem Befehl unter Abrufen des DB-Lastdurchschnitts für Top-Warteereignisse. Die Datei query.json enthält hingegen Folgendes.
[ { "Metric": "db.load.avg", "GroupBy": { "Group": "db.sql_tokenized", "Limit": 10 } } ]
Im folgenden Beispiel wird verwende db.sql_tokenized.
Für Linux, macOS oder Unix:
aws pi get-resource-metrics \ --service-type RDS \ --identifier db-ID\ --start-time2018-10-29T00:00:00Z\ --end-time2018-10-30T00:00:00Z\ --period-in-seconds3600\ --metric-queries file://query.json
Für Windows:
aws pi get-resource-metrics ^ --service-type RDS ^ --identifier db-ID^ --start-time2018-10-29T00:00:00Z^ --end-time2018-10-30T00:00:00Z^ --period-in-seconds3600^ --metric-queries file://query.json
In diesem Beispiel läuft die Abfrage über 24 Stunden, mit einem einstündigen Zeitraum in Sekunden.
Das Beispiel gibt die Metrik db.load.avg und eine GroupBy-Sortierung der sieben Top-Warteereignisse an. Einzelheiten zu gültigen Werten für dieses Beispiel finden Sie DimensionGroupin der Performance Insights API-Referenz.
Die Antwort sieht in etwa so aus:
{ "AlignedStartTime": 1540771200.0, "AlignedEndTime": 1540857600.0, "Identifier": "db-XXX", "MetricList": [ //11 entries in the MetricList { "Key": { //First key is total "Metric": "db.load.avg" } "DataPoints": [ //Each DataPoints list has 24 per-hour Timestamps and a value { "Value": 1.6964980544747081, "Timestamp": 1540774800.0 }, //... 24 datapoints ] }, { "Key": { //Next key is the top tokenized SQL "Dimensions": { "db.sql_tokenized.statement": "INSERT INTO authors (id,name,email) VALUES\n( nextval(?) ,?,?)", "db.sql_tokenized.db_id": "pi-2372568224", "db.sql_tokenized.id": "AKIAIOSFODNN7EXAMPLE" }, "Metric": "db.load.avg" }, "DataPoints": [ //... 24 datapoints ] }, // In total 11 entries, 10 Keys of top tokenized SQL, 1 total key ] //End of MetricList } //End of response
Diese Antwort umfasst 11 Einträge in der MetricList (1 gesamt, 10 Top-SQL mit Token), wobei jeder Eintrage 24 DataPoints pro Stunde aufweist.
Für SQL-Anweisungen mit Token gibt es in jeder Dimensionsliste drei Einträge:
-
db.sql_tokenized.statement– Die SQL-Anweisung mit Token. -
db.sql_tokenized.db_id– Entweder die native Datenbank-ID zum Verweisen auf die SQL-Anweisung oder eine synthetische ID, die von Performance Insights generiert wird, wenn keine native Datenbank-ID verfügbar ist. In diesem Beispiel wird die synthetische IDpi-2372568224zurückgegeben. -
db.sql_tokenized.id– Die ID der Abfrage innerhalb von Performance-Insights.In der AWS-Managementkonsole wird diese ID als Support-ID bezeichnet. Es trägt diesen Namen, weil es sich bei der ID um Daten handelt, die der AWS Support untersuchen kann, um Ihnen bei der Behebung eines Problems mit Ihrer Datenbank zu helfen. AWS nimmt die Sicherheit und den Datenschutz Ihrer Daten sehr ernst und fast alle Daten werden mit Ihrem AWS KMS Schlüssel verschlüsselt gespeichert. Daher AWS kann niemand im Inneren diese Daten einsehen. Im vorherigen Beispiel wird sowohl
tokenized.statementals auchtokenized.db_idverschlüsselt gespeichert. Wenn Sie ein Problem mit Ihrer Datenbank haben, kann Ihnen der AWS Support unter Angabe der Support-ID weiterhelfen.
Beim Abfragen empfiehlt es sich ggf., eine Group in GroupBy anzugeben. Für eine präzisere Kontrolle der Daten, die zurückgegeben werden, sollten Sie allerdings die Dimensionsliste angeben. Wenn z. B. lediglich eine db.sql_tokenized.statement erforderlich ist, kann der query.json-Datei ein Dimensions-Attribut hinzugefügt werden.
[ { "Metric": "db.load.avg", "GroupBy": { "Group": "db.sql_tokenized", "Dimensions":["db.sql_tokenized.statement"], "Limit": 10 } } ]
Abrufen des nach SQL gefilterten DB-Lastdurchschnitts
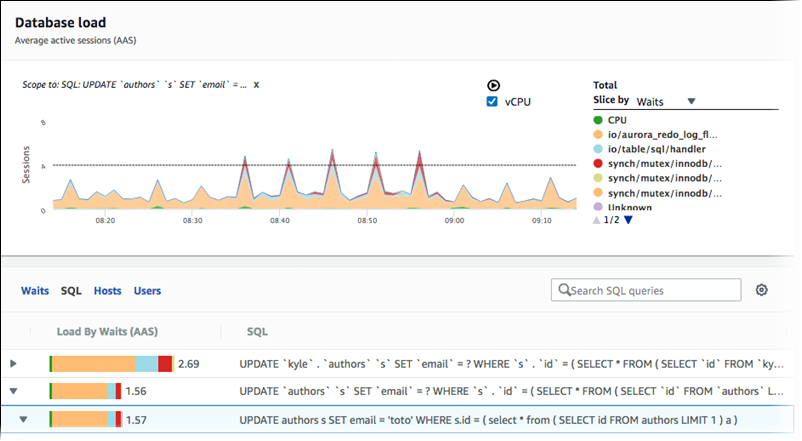
Die vorherige Abbildung zeigt, dass eine bestimmte Abfrage ausgewählt ist, und das Stapelflächendiagramm der durchschnittlichen aktiven Top-Sitzungen ist auf diese Abfrage beschränkt. Obwohl sich die Abfrage nach wie vor auf die sieben Top-Gesamtwarteereignisse bezieht, wird der Wert der Antwort gefiltert. Durch das Filtern werden nur die Sitzungen berücksichtigt, die mit dem entsprechenden Filter übereinstimmen.
Die entsprechende API-Abfrage in diesem Beispiel ähnelt dem Befehl unter Abrufen des DB-Lastdurchschnitts für Top-SQL-Anweisungen. Die Datei query.json enthält hingegen Folgendes.
[ { "Metric": "db.load.avg", "GroupBy": { "Group": "db.wait_event", "Limit": 5 }, "Filter": { "db.sql_tokenized.id": "AKIAIOSFODNN7EXAMPLE" } } ]
Für Linux, macOS oder Unix:
aws pi get-resource-metrics \ --service-type RDS \ --identifier db-ID\ --start-time2018-10-30T00:00:00Z\ --end-time2018-10-30T01:00:00Z\ --period-in-seconds60\ --metric-queries file://query.json
Für Windows:
aws pi get-resource-metrics ^ --service-type RDS ^ --identifier db-ID^ --start-time2018-10-30T00:00:00Z^ --end-time2018-10-30T01:00:00Z^ --period-in-seconds60^ --metric-queries file://query.json
Die Antwort sieht in etwa so aus:
{ "Identifier": "db-XXX", "AlignedStartTime": 1556215200.0, "MetricList": [ { "Key": { "Metric": "db.load.avg" }, "DataPoints": [ { "Timestamp": 1556218800.0, "Value": 1.4878117913832196 }, { "Timestamp": 1556222400.0, "Value": 1.192823803967328 } ] }, { "Key": { "Metric": "db.load.avg", "Dimensions": { "db.wait_event.type": "io", "db.wait_event.name": "wait/io/aurora_redo_log_flush" } }, "DataPoints": [ { "Timestamp": 1556218800.0, "Value": 1.1360544217687074 }, { "Timestamp": 1556222400.0, "Value": 1.058051341890315 } ] }, { "Key": { "Metric": "db.load.avg", "Dimensions": { "db.wait_event.type": "io", "db.wait_event.name": "wait/io/table/sql/handler" } }, "DataPoints": [ { "Timestamp": 1556218800.0, "Value": 0.16241496598639457 }, { "Timestamp": 1556222400.0, "Value": 0.05163360560093349 } ] }, { "Key": { "Metric": "db.load.avg", "Dimensions": { "db.wait_event.type": "synch", "db.wait_event.name": "wait/synch/mutex/innodb/aurora_lock_thread_slot_futex" } }, "DataPoints": [ { "Timestamp": 1556218800.0, "Value": 0.11479591836734694 }, { "Timestamp": 1556222400.0, "Value": 0.013127187864644107 } ] }, { "Key": { "Metric": "db.load.avg", "Dimensions": { "db.wait_event.type": "CPU", "db.wait_event.name": "CPU" } }, "DataPoints": [ { "Timestamp": 1556218800.0, "Value": 0.05215419501133787 }, { "Timestamp": 1556222400.0, "Value": 0.05805134189031505 } ] }, { "Key": { "Metric": "db.load.avg", "Dimensions": { "db.wait_event.type": "synch", "db.wait_event.name": "wait/synch/mutex/innodb/lock_wait_mutex" } }, "DataPoints": [ { "Timestamp": 1556218800.0, "Value": 0.017573696145124718 }, { "Timestamp": 1556222400.0, "Value": 0.002333722287047841 } ] } ], "AlignedEndTime": 1556222400.0 } //end of response
In dieser Antwort werden alle Werte gemäß des Beitrags der SQL-Anweisung mit Token AKIAIOSFODNN7EXAMPLE gefiltert, die in der query.json-Datei angegeben ist. Die Schlüssel sind möglicherweise in einer anderen Reihenfolge angeordnet als bei einer Abfrage ohne Filter, da die gefilterte SQL-Anweisung von den fünf Top-Warteereignisse beeinflusst wurde.
Abrufen des Volltextes einer SQL-Anweisung
Im folgenden Beispiel wird der Volltext einer SQL-Anweisung für die DB-Instance db-10BCD2EFGHIJ3KL4M5NO6PQRS5 abgerufen. --group ist db.sql und --group-identifier ist db.sql.id. In diesem Beispiel my-sql-id steht sie für eine SQL-ID, die durch Aufrufen pi
get-resource-metrics von oder abgerufen wurde. pi describe-dimension-keys
Führen Sie den folgenden Befehl aus.
Für Linux, macOS oder Unix:
aws pi get-dimension-key-details \ --service-type RDS \ --identifier db-10BCD2EFGHIJ3KL4M5NO6PQRS5 \ --group db.sql \ --group-identifiermy-sql-id\ --requested-dimensions statement
Für Windows:
aws pi get-dimension-key-details ^ --service-type RDS ^ --identifier db-10BCD2EFGHIJ3KL4M5NO6PQRS5 ^ --group db.sql ^ --group-identifiermy-sql-id^ --requested-dimensions statement
In diesem Beispiel sind die Dimensionsdetails verfügbar. Performance Insights ruft also den vollständigen Text der SQL-Anweisung ab, ohne ihn abzuschneiden.
{ "Dimensions":[ { "Value": "SELECT e.last_name, d.department_name FROM employees e, departments d WHERE e.department_id=d.department_id", "Dimension": "db.sql.statement", "Status": "AVAILABLE" }, ... ] }
Erstellen eines Leistungsanalyseberichts für einen bestimmten Zeitraum
Im folgenden Beispiel wird ein Leistungsanalysebericht mit der Startzeit 1682969503 und der Endzeit 1682979503 für diedb-loadtest-0-Datenbank erstellt.
aws pi create-performance-analysis-report \ --service-type RDS \ --identifier db-loadtest-0 \ --start-time 1682969503 \ --end-time 1682979503 \ --region us-west-2
Die Antwort ist der eindeutige Bezeichner report-0234d3ed98e28fb17 für den Bericht.
{ "AnalysisReportId": "report-0234d3ed98e28fb17" }
Abrufen eines Leistungsanalyseberichts
Im folgenden Beispiel werden die Details des Analyseberichts für den Bericht report-0d99cc91c4422ee61 abgerufen.
aws pi get-performance-analysis-report \ --service-type RDS \ --identifier db-loadtest-0 \ --analysis-report-id report-0d99cc91c4422ee61 \ --region us-west-2
Die Antwort enthält den Berichtsstatus, die ID, Zeitdetails und Einblicke.
{ "AnalysisReport": { "Status": "Succeeded", "ServiceType": "RDS", "Identifier": "db-loadtest-0", "StartTime": 1680583486.584, "AnalysisReportId": "report-0d99cc91c4422ee61", "EndTime": 1680587086.584, "CreateTime": 1680587087.139, "Insights": [ ... (Condensed for space) ] } }
Auflisten aller Leistungsanalyseberichte für die DB-Instance
Das folgende Beispiel listet alle verfügbaren Leistungsanalyseberichte für die db-loadtest-0-Datenbank auf.
aws pi list-performance-analysis-reports \ --service-type RDS \ --identifier db-loadtest-0 \ --region us-west-2
In der Antwort werden alle Berichte mit der Berichts-ID, dem Status und den Details zum Zeitraum aufgeführt.
{ "AnalysisReports": [ { "Status": "Succeeded", "EndTime": 1680587086.584, "CreationTime": 1680587087.139, "StartTime": 1680583486.584, "AnalysisReportId": "report-0d99cc91c4422ee61" }, { "Status": "Succeeded", "EndTime": 1681491137.914, "CreationTime": 1681491145.973, "StartTime": 1681487537.914, "AnalysisReportId": "report-002633115cc002233" }, { "Status": "Succeeded", "EndTime": 1681493499.849, "CreationTime": 1681493507.762, "StartTime": 1681489899.849, "AnalysisReportId": "report-043b1e006b47246f9" }, { "Status": "InProgress", "EndTime": 1682979503.0, "CreationTime": 1682979618.994, "StartTime": 1682969503.0, "AnalysisReportId": "report-01ad15f9b88bcbd56" } ] }
Löschen eines Leistungsanalyseberichts
Im folgenden Beispiel wird der Analysebericht für die db-loadtest-0-Datenbank gelöscht.
aws pi delete-performance-analysis-report \ --service-type RDS \ --identifier db-loadtest-0 \ --analysis-report-id report-0d99cc91c4422ee61 \ --region us-west-2
Hinzufügen eines Tags zu einem Leistungsanalysebericht
Im folgenden Beispiel wird ein Tag mit dem Schlüssel name und dem Wert test-tag zum Bericht report-01ad15f9b88bcbd56 hinzugefügt.
aws pi tag-resource \ --service-type RDS \ --resource-arn arn:aws:pi:us-west-2:356798100956:perf-reports/RDS/db-loadtest-0/report-01ad15f9b88bcbd56 \ --tags Key=name,Value=test-tag \ --region us-west-2
Auflisten aller Tags für einen Leistungsanalysebericht
Das folgende Beispiel listet alle Tags für den Bericht report-01ad15f9b88bcbd56 auf.
aws pi list-tags-for-resource \ --service-type RDS \ --resource-arn arn:aws:pi:us-west-2:356798100956:perf-reports/RDS/db-loadtest-0/report-01ad15f9b88bcbd56 \ --region us-west-2
In der Antwort werden der Wert und der Schlüssel für alle dem Bericht hinzugefügten Tags aufgeführt:
{ "Tags": [ { "Value": "test-tag", "Key": "name" } ] }
Löschen der Tags eines Leistungsanalyseberichts
Im folgenden Beispiel wird das Tag name aus dem Bericht report-01ad15f9b88bcbd56 gelöscht.
aws pi untag-resource \ --service-type RDS \ --resource-arn arn:aws:pi:us-west-2:356798100956:perf-reports/RDS/db-loadtest-0/report-01ad15f9b88bcbd56 \ --tag-keys name \ --region us-west-2
Nachdem das Tag gelöscht wurde, wird beim Abrufen der API list-tags-for-resource dieses Tag nicht mehr aufgelistet.
