Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Null-ETL-Integrationen von Aurora
Es handelt sich um eine vollständig verwaltete Lösung, die Transaktionsdaten in Ihrem Analyseziel verfügbar macht, nachdem diese in einen Aurora-DB-Cluster geschrieben wurden. Extract, Transform, Load (ETL) bezeichnet die Kombination von Daten aus mehreren Quellen in einem großen, zentralen Data Warehouse.
Eine Null-ETL-Integration macht die Daten in Ihrem Aurora-DB-Cluster in Amazon Redshift oder einem Amazon SageMaker AI -Lakehouse nahezu in Echtzeit verfügbar. Sobald sich diese Daten im Ziel-Data Warehouse oder Data Lake befinden, können Sie Ihre Analyse-, ML- und KI-Workloads mithilfe der integrierten Funktionen wie maschinelles Lernen, materialisierte Ansichten, gemeinsame Nutzung von Daten, Verbundzugriff auf mehrere Datenspeicher und Data Lakes sowie Integrationen mit Amazon SageMaker AI, Quick und anderen unterstützen. AWS-Services
Um eine Null-ETL-Integration zu erstellen, geben Sie einen Aurora-DB-Cluster als Quelle und ein unterstütztes Data Warehouse oder Lakehouse als Ziel an. Bei der Integration werden Daten aus der Quelldatenbank in das Ziel-Data-Warehouse oder -Lakehouse repliziert.
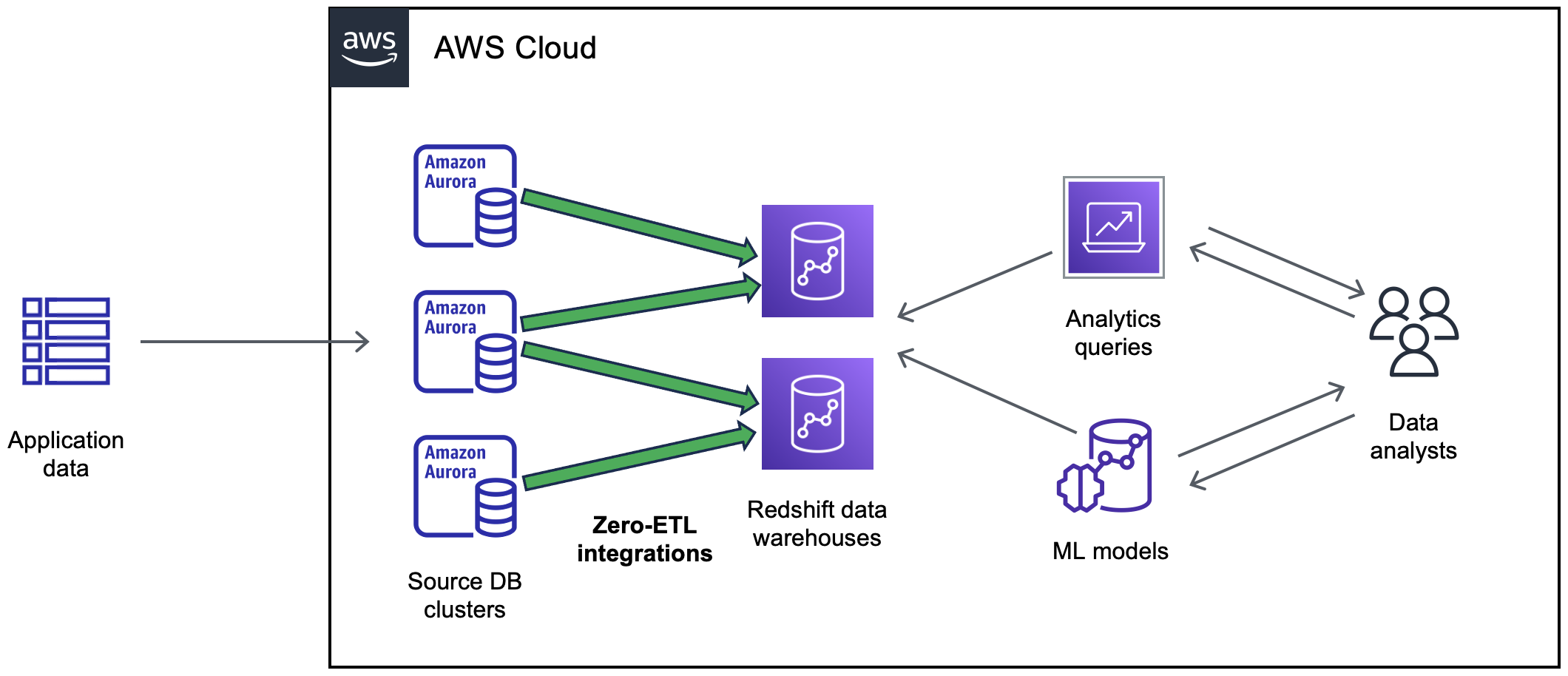
Das folgende Diagramm veranschaulicht diese Funktion für die Null-ETL-Integration mit Amazon Redshift:
Das folgende Diagramm veranschaulicht diese Funktion für die Null-ETL-Integration mit einem Amazon SageMaker AI -Lakehouse:
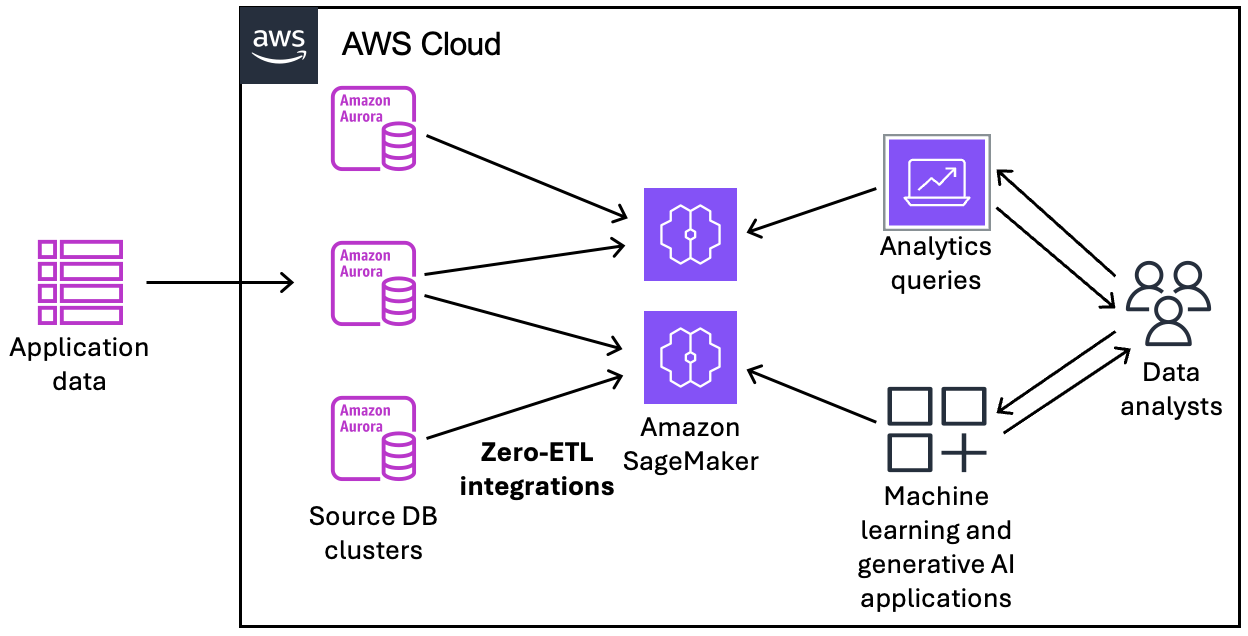
Die Integration überwacht den Zustand der Datenpipeline und behebt nach Möglichkeit Probleme. Sie können Integrationen aus mehreren Aurora-DB-Clustern in ein einziges Ziel-Data-Warehouse oder -Lakehouse erstellen und dadurch Erkenntnisse aus mehreren Anwendungen gewinnen.
Weitere Informationen zu den Preisen für Null-ETL-Integrationen finden Sie unter Amazon Aurora – Preise
Themen
Vorteile
Null-ETL-Integrationen von Aurora bieten die folgenden Vorteile:
-
Sie helfen Ihnen dabei, ganzheitliche Erkenntnisse aus mehreren Datenquellen zu gewinnen.
-
Eliminieren Sie die Notwendigkeit, komplexe Daten-Pipelines aufzubauen und zu verwalten, die Extraktions-, Transformations- und Ladevorgänge (ETL) durchführen. Zero-ETL Integrationen beseitigen die Herausforderungen, die mit dem Aufbau und der Verwaltung von Pipelines einhergehen, indem sie für Sie bereitgestellt und verwaltet werden.
-
Sie reduzieren den Betriebsaufwand und die Kosten, sodass Sie sich ganz auf die Verbesserung Ihrer Anwendungen konzentrieren können.
-
Sie ermöglichen die Nutzung der Analyse- und ML-Funktionen des Ziels zum Gewinnen von Erkenntnissen aus Transaktions- und anderen Daten, um effektiv auf (zeit-)kritische Ereignisse reagieren zu können.
Die wichtigsten Konzepte
Wenn Sie mit Null-ETL-Integrationen beginnen, sollten Sie die folgenden Konzepte berücksichtigen:
- Integration
-
Eine vollständig verwaltete Daten-Pipeline, die automatisch Transaktionsdaten und Schemata aus einem Aurora-DB-Cluster in ein Data Warehouse oder einen Katalog repliziert.
- Quell-DB-Cluster
-
Der Aurora-DB-Cluster, von wo aus die Daten repliziert werden. Sie können einen DB-Cluster angeben, der bereitgestellte DB-Instances oder Aurora serverless DB-Instances als Quelle verwendet.
- Target
-
Das Data Warehouse oder Lakehouse, in das die Daten repliziert werden. Es gibt zwei Arten von Data Warehouse: ein bereitgestelltes Cluster-Data-Warehouse und ein Serverless-Data-Warehouse. Ein bereitgestelltes Cluster-Data-Warehouse ist eine Sammlung von Datenverarbeitungsressourcen, den sogenannten Knoten, die zu einer Gruppe, einem sogenannten Cluster, zusammengefasst werden. Ein Serverless-Data-Warehouse besteht aus einer Arbeitsgruppe, die Datenverarbeitungsressourcen speichert, und einem Namespace, in dem die Datenbankobjekte und Benutzer gespeichert sind. In beiden Data Warehouses wird eine Analyse-Engine ausgeführt und beide enthalten eine oder mehrere Datenbanken.
Ein Ziel-Lakehouse besteht aus Katalogen, Datenbanken, Tabellen und Ansichten. Weitere Informationen zur Lakehouse-Architektur finden Sie unter SageMaker Lakehouse components im Amazon SageMaker AI Unified Studio-Benutzerhandbuch.
Mehrere Quell-DB-Cluster können in dasselbe Ziel schreiben.
Weitere Informationen finden Sie unter Architektur des Data-Warehouse-Systems im Entwicklerhandbuch zu Amazon Redshift.
Einschränkungen
Die folgenden Einschränkungen gelten für Null-ETL-Integrationen von Aurora.
Themen
Allgemeine Einschränkungen
-
Der Quell-DB-Cluster muss sich in derselben Region befinden wie das Ziel.
-
Sie können einen DB-Cluster oder die zugehörigen Instances nicht umbenennen, wenn das Element über bestehende Integrationen verfügt.
-
Sie können nicht mehrere Integrationen zwischen derselben Quell- und Zieldatenbank erstellen.
-
Sie können einen DB-Cluster mit bestehenden Integrationen nicht löschen. Sie müssen zuerst alle zugehörigen Integrationen löschen.
-
Wenn Sie den Quell-DB-Cluster anhalten, werden die letzten Transaktionen möglicherweise erst dann in das Ziel repliziert, wenn Sie den Cluster fortsetzen.
-
Wenn Ihr die Quelle einer blue/green Bereitstellung ist, dürfen die blauen und grünen Umgebungen während des Switchovers keine vorhandenen Zero-ETL-Integrationen aufweisen. Sie müssen zuerst die Integration löschen und umstellen. Anschließend erstellen Sie die Integration neu.
-
Ein DB-Cluster muss mindestens eine DB-Instance enthalten, um die Quelle einer Integration zu sein.
-
Sie können keine Integration für einen Quell-DB-Cluster erstellen, bei dem es sich um einen kontoübergreifenden Klon handelt, wie z. B. solche, die mit () gemeinsam genutzt werden. AWS Resource Access Manager AWS RAM
-
Wenn der DB-Quell-Cluster in einer globalen Aurora-Datenbank verwendet wird und ein Failover zu einem der sekundären Cluster erfolgt, wird die Integration inaktiv. Sie müssen die Integration löschen und erneut erstellen.
-
Sie können keine Integration für eine Quelldatenbank erstellen, für die aktiv eine andere Integration erstellt wird.
-
Wenn Sie zum ersten Mal eine Integration erstellen oder wenn eine Tabelle erneut synchronisiert wird, kann das Seeding von Daten von der Quelle zum Ziel je nach Größe der Quelldatenbank 20 bis 25 Minuten oder länger dauern. Diese Verzögerung kann zu einer erhöhten Replikatverzögerung führen.
-
Einige Datentypen werden nicht unterstützt. Weitere Informationen finden Sie unter Datentypunterschiede zwischen Aurora und Amazon Redshift-Datenbanken.
-
Systemtabellen, temporäre Tabellen und Ansichten werden nicht in Ziel-Warehouses repliziert.
-
Das Ausführen von DDL-Befehlen (z. B.
ALTER TABLE) für eine Quelltabelle kann eine erneute Synchronisierung der Tabelle auslösen, wobei die Tabelle während der erneuten Synchronisierung nicht mehr abgefragt werden kann. Weitere Informationen finden Sie unter Eine oder mehrere meiner Amazon-Redshift-Tabellen erfordern eine erneute Synchronisation.
Einschränkungen von Aurora MySQL
-
Auf Ihrem Quell-DB-Cluster muss eine unterstützte Version von Aurora MySQL ausgeführt werden. Eine Liste der unterstützten Versionen finden Sie unter Unterstützte Regionen und Aurora-DB-Engines für Null-ETL-Integrationen.
-
Zero-ETL Integrationen basieren auf der MySQL-Binärprotokollierung (Binlog), um laufende Datenänderungen zu erfassen. Verwenden Sie keine Binlog-basierte Datenfilterung, da dies zu Dateninkonsistenzen zwischen der Quell- und der Zieldatenbank führen kann.
-
Zero-ETL Integrationen werden nur für Datenbanken unterstützt, die für die Verwendung der InnoDB-Speicher-Engine konfiguriert sind.
-
Fremdschlüsselverweise mit vordefinierten Tabellenaktualisierungen werden nicht unterstützt. Insbesondere werden
ON DELETE- undON UPDATE-Regeln mitCASCADE-,SET NULL- undSET DEFAULT-Aktionen nicht unterstützt. Der Versuch, eine Tabelle mit solchen Verweisen in einer anderen Tabelle zu erstellen oder zu aktualisieren, führt zu einem Fehlschlag der Tabelle. -
XA-Transaktionen
, die auf dem Quell-DB-Cluster ausgeführt werden, führen dazu, dass die Integration in den Status Syncingwechselt.
Einschränkungen bei Aurora PostgreSQL
-
Auf Ihrem Quell-DB-Cluster muss eine unterstützte Version von Aurora PostgreSQL ausgeführt werden. Eine Liste der unterstützten Versionen finden Sie unter Unterstützte Regionen und Aurora-DB-Engines für Null-ETL-Integrationen.
-
Wenn Sie einen Quell-DB-Cluster von Aurora PostgreSQL auswählen, müssen Sie mindestens ein Datenfiltermuster angeben. Das Muster muss mindestens eine einzelne Datenbank (
database-name.*.* -
Alle Datenbanken, die im Aurora PostgreSQL-Quell-DB-Cluster erstellt wurden, müssen Kodierung verwenden UTF-8.
-
Bei Verwendung der deklarativen Partitionierung werden die Tabellenpartitionen in Amazon Redshift repliziert. Die partitionierte Tabelle selbst wird jedoch nicht in Amazon Redshift repliziert.
-
Two-phase Transaktionen
werden nicht unterstützt. -
Wenn Sie alle DB-Instances aus einem DB-Cluster löschen, der die Quelle einer Integration ist, und dann erneut eine DB-Instance hinzufügen, wird die Replikation zwischen dem Quell- und dem Ziel-Cluster unterbrochen.
-
Der Quell-DB-Cluster kann Aurora Limitless Database nicht verwenden.
-
Primärschlüssel sind für alle im Datenfilter vorhandenen Tabellen erforderlich. Alle Tabellen ohne Primärschlüssel werden in den Status „failed“ versetzt.
Einschränkungen für Amazon Redshift
Eine Liste der Einschränkungen von Amazon Redshift im Zusammenhang mit Null-ETL-Integrationen finden Sie unter Überlegungen bei der Verwendung von Null-ETL-Integrationen mit Amazon Redshift im Amazon-Redshift-Managementleitfaden.
Amazon SageMaker AI Lakehouse-Einschränkungen
Im Folgenden finden Sie eine Einschränkung für Amazon SageMaker AI Lakehouse Zero-ETL-Integrationen.
-
Katalognamen sind auf von 64 Zeichen beschränkt.
Kontingente
Für Ihr Konto gelten die folgenden Kontingente in Bezug auf Null-ETL-Integrationen von Aurora. Jedes Kontingent gilt pro Region, sofern nicht anders angegeben.
| Name | Standard | Description |
|---|---|---|
| Integrationen | 100 | Die Gesamtzahl der Integrationen innerhalb eines AWS-Konto. |
| Integrationen pro Ziel | 50 | Die Anzahl der Integrationen, die Daten an ein einzelnes Ziel-Data-Warehouse oder -Lakehouse senden. |
| Integrationen pro Quell-Cluster | 5 | Die Anzahl der Integrationen, die Daten von einem einzelnen DB-Cluster senden. |
Darüber hinaus legt das Ziel-Warehouse bestimmte Einschränkungen für die Anzahl der zulässigen Tabellen in jeder DB-Instance oder jedem Cluster-Knoten fest. Weitere Informationen finden Sie unter Kontingente und Limits in Amazon Redshift im Amazon-Redshift-Managementleitfaden.
Unterstützte Regionen
Aurora Zero-ETL-Integrationen sind in einer Teilmenge von verfügbar. AWS-Regionen Eine Liste der unterstützten -Regionen finden Sie unter Unterstützte Regionen und Aurora-DB-Engines für Null-ETL-Integrationen.
