Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Datenfilterung für Null-ETL-Integrationen für Aurora
Null-ETL-Integrationen von Aurora unterstützen die Datenfilterung, mit der Sie steuern können, welche Daten aus Ihrer Quelle, also der dem Aurora-DB-Cluster, in Ihr Ziel-Data-Warehouse repliziert werden. Anstatt die gesamte Datenbank zu replizieren, können Sie einen oder mehrere Filter anwenden, um bestimmte Tabellen ein- oder auszuschließen. Auf diese Weise können Sie die Speicher- und Abfrageleistung optimieren, da nur relevante Daten übertragen werden. Derzeit ist die Filterung auf Datenbank- und Tabellenebene beschränkt. Das Filtern auf Spalten- und Zeilenebene wird nicht unterstützt.
Die Datenfilterung kann nützlich sein, wenn Sie:
-
bestimmte Tabellen aus zwei oder mehr verschiedenen Quell-Clustern verknüpfen möchten und nicht alle Daten aus den jeweiligen Clustern benötigen;
-
Kosten sparen möchten, indem Sie Analysen nur mit einer Teilmenge von Tabellen und nicht mit einer ganzen Flotte von Datenbanken durchführen;
-
vertrauliche Informationen wie Telefonnummern, Adressen oder Kreditkarteninformationen aus bestimmten Tabellen herausfiltern möchten.
Sie können Datenfilter zu einer Zero-ETL-Integration hinzufügen AWS-Managementkonsole, indem Sie die AWS Command Line Interface (AWS CLI) oder die Amazon RDS-API verwenden.
Wenn die Integration einen bereitgestellten Cluster als Ziel hat, muss sich der Cluster auf Patch 180 oder höher befinden, um die Datenfilterung verwenden zu können.
Themen
Format eines Datenfilters
Sie können mehrere Filter für eine einzelne Integration definieren. Jeder Filter schließt alle vorhandenen und künftigen Datenbanktabellen, die einem der Muster im Filterausdruck entsprechen, entweder ein oder aus. Null-ETL-Integrationen von Aurora verwenden die Maxwell-Filtersyntax
Jeder Filter enthält die folgenden Elemente:
| Element | Description |
|---|---|
| Filtertyp |
Der Filtertyp |
| Filterausdruck |
Eine kommagetrennte Liste von Mustern. Ausdrücke müssen die Maxwell-Filtersyntax |
| Muster |
Ein Filtermuster im Format AnmerkungFür Aurora MySQL werden reguläre Ausdrücke sowohl im Datenbank- als auch im Tabellennamen unterstützt. Für Aurora PostgreSQL werden reguläre Ausdrücke nur im Schema- und Tabellennamen unterstützt, nicht im Datenbanknamen. Sie können keine Filter oder Zugriffsverweigerungslisten auf Spaltenebene einbeziehen. Eine einzelne Integration kann insgesamt maximal 99 Muster haben. In der Konsole können Sie Muster innerhalb eines einzelnen Filterausdrucks eingeben oder sie auf mehrere Ausdrücke verteilen. Ein einzelnes Muster darf maximal 256 Zeichen lang sein. |
Wichtig
Wenn Sie ein Quell-DB-Cluster von Aurora PostgreSQL auswählen, müssen Sie mindestens ein Datenfiltermuster angeben. Das Muster muss mindestens eine einzelne Datenbank (database-name.*.*
Die folgende Abbildung zeigt die Struktur der Datenfilter für Aurora MySQL in der Konsole:
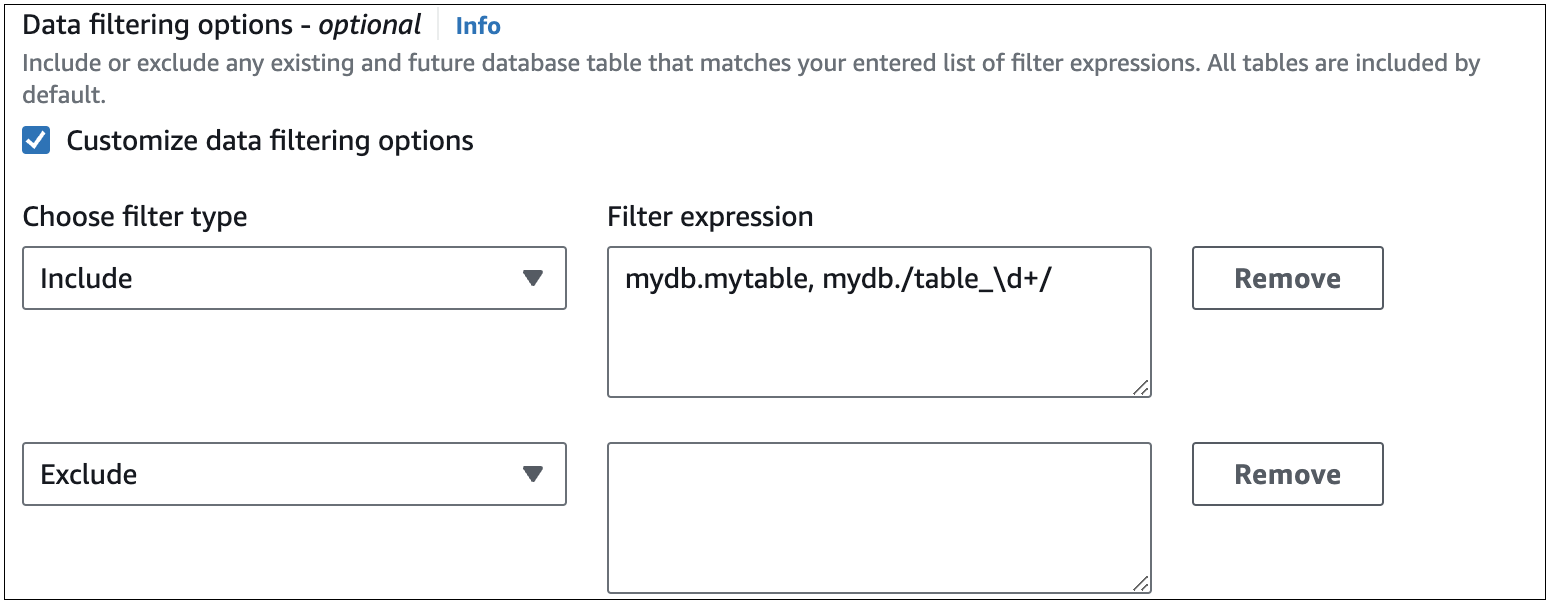
Wichtig
Geben Sie in Ihren Filtermustern keine persönlich identifizierenden, vertraulichen oder sensiblen Informationen an.
Datenfilter im AWS CLI
Wenn Sie den verwenden AWS CLI , um einen Datenfilter hinzuzufügen, unterscheidet sich die Syntax geringfügig von der der Konsole. Sie müssen jedem Muster einzeln einen Filtertyp (Include oder Exclude) zuweisen, sodass Sie nicht mehrere Muster unter einem Filtertyp gruppieren können.
In der Konsole können Sie beispielsweise die folgenden durch Kommas getrennten Muster unter einer einzigen Include-Anweisung gruppieren:
Aurora MySQL
mydb.mytable,mydb./table_\d+/
Aurora PostgreSQL
mydb.myschema.mytable,mydb.myschema./table_\d+/
Wenn Sie den verwenden AWS CLI, muss derselbe Datenfilter jedoch das folgende Format haben:
Aurora MySQL
'include:mydb.mytable, include:mydb./table_\d+/'
Aurora PostgreSQL
'include:mydb.myschema.mytable, include:mydb.myschema./table_\d+/'
Filterlogik
Wenn Sie in Ihrer Integration keine Datenfilter angeben, geht Aurora vom Standardfilter include:*.* aus, der alle Tabellen in das Ziel-Data-Warehouse repliziert. Wenn Sie jedoch mindestens einen Filter hinzufügen, wechselt die Standardlogik zu exclude:*.*, wodurch standardmäßig alle Tabellen ausgeschlossen werden. Auf diese Weise können Sie explizit definieren, welche Datenbanken und Tabellen in die Replikation einbezogen werden sollen.
Sie definieren beispielsweise folgenden Filter:
'include: db.table1, include: db.table2'
Aurora bewertet den Filter wie folgt:
'exclude:*.*, include: db.table1, include: db.table2'
Daher repliziert Aurora nur table1 und table2 von der angegebenen Datenbank db in das Ziel-Data-Warehouse.
Rangfolge der Filter
Aurora wertet Datenfilter in der von Ihnen angegebenen Reihenfolge aus. In der AWS-Managementkonsole verarbeitet er Filterausdrücke von links nach rechts und von oben nach unten. Ein zweiter Filter oder ein individuelles Muster, das dem ersten folgt, kann ihn/es überschreiben.
Wenn der erste Filter beispielsweise Include books.stephenking lautet, schließt er nur die Tabelle stephenkingaus der Datenbank books ein. Wenn Sie jedoch einen zweiten Filter Exclude books.* hinzufügen, überschreibt dieser den ersten Filter. Dadurch wird verhindert, dass Tabellen aus dem Index books in das Ziel-Data-Warehouse repliziert werden.
Wenn Sie mindestens einen Filter angeben, geht die Logik standardmäßig zunächst von exclude:*.* aus, wodurch automatisch alle Tabellen von der Replikation ausgeschlossen werden. Als bewährte Methode empfiehlt es sich, Filter von allgemein nach spezifisch zu definieren. Beginnen Sie mit einer oder mehreren Include-Anweisungen, um die zu replizierenden Daten anzugeben, und fügen Sie dann Exclude-Filter hinzu, um bestimmte Tabellen selektiv zu entfernen.
Das gleiche Prinzip gilt für Filter, die Sie mit der AWS CLI definieren. Aurora wertet diese Filtermuster in der Reihenfolge aus, in der Sie sie angeben, sodass ein Muster möglicherweise ein Muster überschreibt, das Sie zuvor angegeben haben.
Beispiele für Aurora MySQL
Die folgenden Beispiele zeigen, wie die Datenfilterung für Null-ETL-Integrationen in Beispielen für Aurora MySQL funktioniert:
-
Alle Datenbanken und alle Tabellen einschließen:
'include: *.*' -
Alle Tabellen in der Datenbank
bookseinschließen:'include: books.*' -
Alle Tabellen mit dem Namen
mysteryausschließen:'include: *.*, exclude: *.mystery' -
Zwei bestimmte Tabellen in der Datenbank
bookseinschließen:'include: books.stephen_king, include: books.carolyn_keene' -
Alle Tabellen in der Datenbank
bookseinschließen, außer denen, die die Teilzeichenfolgemysteryenthalten:'include: books.*, exclude: books./.*mystery.*/' -
Alle Tabellen in der Datenbank
bookseinschließen, außer denen, die mitmysterybeginnen:'include: books.*, exclude: books./mystery.*/' -
Alle Tabellen in der Datenbank
bookseinschließen, außer denen, die mitmysteryenden:'include: books.*, exclude: books./.*mystery/' -
Alle Tabellen in der Datenbank
bookseinschließen, die mittable_beginnen, außer der, die den Namentable_stephen_kingträgt. Zum Beispiel würdetable_moviesodertable_booksrepliziert werden,table_stephen_kingaber nicht.'include: books./table_.*/, exclude: books.table_stephen_king'
Beispiele für Aurora PostgreSQL
Die folgenden Beispiele zeigen, wie die Datenfilterung für Null-ETL-Integrationen für Aurora PostgreSQL funktioniert:
-
Alle Tabellen in der Datenbank
bookseinschließen:'include: books.*.*' -
Alle Tabellen mit dem Namen
mysteryin der Datenbankbooksausschließen:'include: books.*.*, exclude: books.*.mystery' -
Eine Tabelle in der Datenbank
booksim Schemamysteryund eine Tabelle in der Datenbankemployeeim Schemafinanceeinschließen:'include: books.mystery.stephen_king, include: employee.finance.benefits' -
Alle Tabellen in der Datenbank
booksund im Schemascience_fictioneinschließen, außer denen, die die Teilzeichenfolgekingenthalten:'include: books.science_fiction.*, exclude: books.*./.*king.*/ -
Alle Tabellen in der Datenbank
bookseinschließen, außer denen, deren Schemaname mitscibeginnt:'include: books.*.*, exclude: books./sci.*/.*' -
Alle Tabellen in der Datenbank
bookseinschließen, außer denen im Schemamystery, die mitkingenden:'include: books.*.*, exclude: books.mystery./.*king/' -
Alle Tabellen in der Datenbank
bookseinschließen, die mittable_beginnen, außer der, die den Namentable_stephen_kingträgt. Zum Beispiel werdentable_moviesim Schemafictionundtable_booksim Schemamysteryrepliziert,table_stephen_kingjedoch in keinem Schema:'include: books.*./table_.*/, exclude: books.*.table_stephen_king'
Hinzufügen von Datenfiltern zu einer Integration
Sie können die Datenfilterung mithilfe der AWS-Managementkonsole AWS CLI, der oder der Amazon RDS-API konfigurieren.
Wichtig
Wenn Sie einen Filter hinzufügen, nachdem Sie eine Integration erstellt haben, behandelt Aurora ihn so, als ob er schon immer existiert hätte. Alle Daten im Ziel-Data-Warehouse, die nicht den neuen Filterkriterien entsprechen, werden entfernt und alle betroffenen Tabellen erneut synchronisiert.
So fügen Sie Datenfilter zur einer Null-ETL-Integration hinzu
Melden Sie sich bei der an AWS-Managementkonsole und öffnen Sie die Amazon RDS-Konsole unter https://console.aws.amazon.com/rds/
. -
Wählen Sie im Navigationsbereich Zero-ETL Integrationen aus. Wählen Sie die Integration aus, zu der Sie Datenfilter hinzufügen möchten, und klicken Sie dann auf Ändern.
-
Fügen Sie unter Quelle eine oder mehrere
Include- undExclude-Anweisungen hinzu.Die folgende Abbildung zeigt ein Beispiel für Datenfilter für eine MySQL-Integration:

-
Wenn Sie mit den Änderungen zufrieden sind, wählen Sie Weiter und Änderungen speichern.
Rufen Sie den Befehl modify-integration auf, um einer Zero-ETL-Integration mithilfe von Datenfilter hinzuzufügen. AWS CLI--data-filter zusätzlich zur Integrations-ID mit einer kommagetrennten Liste von Include- und Exclude-Maxwell-Filtern an.
Beispiel
Im folgenden Beispiel werden Filtermuster zu my-integration hinzugefügt.
Für Linux, macOS oder Unix:
aws rds modify-integration \ --integration-identifiermy-integration\ --data-filter'include: foodb.*, exclude: foodb.tbl, exclude: foodb./table_\d+/'
Für Windows:
aws rds modify-integration ^ --integration-identifiermy-integration^ --data-filter'include: foodb.*, exclude: foodb.tbl, exclude: foodb./table_\d+/'
Rufen Sie den Vorgang auf, um eine Zero-ETL-Integration mithilfe der RDS-API zu ändern. ModifyIntegration Geben Sie die Integrations-ID an und stellen Sie eine kommagetrennte Liste der Filtermuster bereit.
Entfernen von Datenfiltern aus einer Integration
Wenn Sie einen Datenfilter aus einer Integration entfernen, wertet Aurora die verbleibenden Filter neu aus, als ob der entfernte Filter nie existiert hätte. Anschließend repliziert es alle zuvor ausgeschlossenen Daten, die jetzt die Kriterien erfüllen, in das Ziel-Data-Warehouse. Dadurch wird eine erneute Synchronisierung aller betroffenen Tabellen ausgelöst.
