Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verwendung von Amazon Aurora Machine Learning mit Aurora MySQL
Wenn Sie Amazon Aurora Machine Learning mit Ihrem Aurora MySQL-DB-Cluster verwenden, können Sie je nach Bedarf Amazon Bedrock, Amazon Comprehend oder Amazon SageMaker AI verwenden. Sie unterstützen jeweils unterschiedliche Anwendungsfälle für Machine Learning.
Inhalt
Voraussetzungen für die Verwendung von Aurora Machine Learning mit Aurora MySQL
Unterstützte Funktionen und Einschränkungen von Aurora Machine Learning mit Aurora MySQL
Einrichten Ihres DB-Clusters von Aurora MySQL zur Verwendung von Aurora Machine Learning
Einrichten Ihres DB-Clusters von Aurora MySQL zur Verwendung von Amazon Bedrock
Einrichten Ihres DB-Clusters von Aurora MySQL zur Verwendung von Amazon Comprehend
Einrichtung Ihres Aurora MySQL-DB-Clusters für die Verwendung von SageMaker KI
Erteilen des Zugriffs auf Aurora Machine Learning für Datenbankbenutzer
Verwenden von Amazon Bedrock mit Ihrem DB-Cluster von Aurora MySQL
Verwenden von Amazon Comprehend mit Ihrem DB-Cluster von Aurora MySQL
Leistungsaspekte zur Verwendung von Aurora Machine Learning mit Aurora MySQL
Voraussetzungen für die Verwendung von Aurora Machine Learning mit Aurora MySQL
AWS Dienste für maschinelles Lernen sind verwaltete Dienste, die in ihren eigenen Produktionsumgebungen eingerichtet und ausgeführt werden. Aurora Machine Learning unterstützt die Integration mit Amazon Bedrock, Amazon Comprehend und KI. SageMaker Bevor Sie versuchen, Ihren DB-Cluster von Aurora MySQL für die Verwendung von Aurora Machine Learning einzurichten, stellen Sie sicher, dass Sie die folgenden Anforderungen und Voraussetzungen verstehen.
-
Die Machine-Learning-Dienste müssen im selben System AWS-Region wie Ihr Aurora MySQL-DB-Cluster laufen. Sie können keine Machine-Learning-Services aus einem DB-Cluster von Aurora MySQL in einer anderen Region verwenden.
-
Wenn sich Ihr Aurora MySQL-DB-Cluster in einer anderen Virtual Public Cloud (VPC) als Ihr Amazon Bedrock-, Amazon Comprehend- oder SageMaker AI-Service befindet, muss die Sicherheitsgruppe der VPC ausgehende Verbindungen zum Aurora-Zielservice für maschinelles Lernen zulassen. Weitere Informationen finden Sie unter Steuern des Datenverkehrs zu den AWS -Ressourcen mithilfe von Sicherheitsgruppen im Amazon-VPC-Benutzerhandbuch.
-
Sie können einen Aurora-Cluster, auf dem eine niedrigere Version von Aurora MySQL ausgeführt wird, auf eine unterstützte höhere Version aktualisieren, wenn Sie Aurora Machine Learning mit diesem Cluster verwenden möchten. Weitere Informationen finden Sie unter Datenbank-Engine-Updates für Amazon Aurora MySQL.
-
Ihr DB-Cluster von Aurora MySQL muss eine benutzerdefinierte DB-Cluster-Parametergruppe verwenden. Am Ende des Einrichtungsvorgangs für jeden Aurora-Service für Machine Learning, den Sie verwenden möchten, fügen Sie den Amazon-Ressourcennamen (ARN) der zugehörigen IAM-Rolle hinzu, die für den Service erstellt wurde. Wir empfehlen Ihnen, vorab eine benutzerdefinierte DB-Cluster-Parametergruppe für Aurora MySQL zu erstellen und Ihren DB-Cluster von Aurora MySQL für ihre Verwendung zu konfigurieren, damit sie am Ende des Einrichtungsvorgangs von Ihnen geändert werden kann.
-
Für SageMaker KI:
-
Die Machine-Learning-Komponenten, die Sie für Inferenzen verwenden möchten, müssen eingerichtet werden und einsatzbereit sein. Stellen Sie während des Konfigurationsprozesses für Ihren Aurora MySQL-DB-Cluster sicher, dass der ARN des SageMaker KI-Endpunkts verfügbar ist. Die Datenwissenschaftler in Ihrem Team sind wahrscheinlich am besten in der Lage, mit SageMaker KI zu arbeiten, um die Modelle vorzubereiten und die anderen derartigen Aufgaben zu erledigen. Informationen zu den ersten Schritten mit Amazon SageMaker AI finden Sie unter Erste Schritte mit Amazon SageMaker AI. Weitere Informationen zu Inferenzen und Endpunkten finden Sie unter Real-time Inferenz.
-
Um SageMaker KI mit Ihren eigenen Trainingsdaten zu verwenden, müssen Sie einen Amazon S3 S3-Bucket als Teil Ihrer Aurora MySQL-Konfiguration für Aurora Machine Learning einrichten. Dazu folgen Sie demselben allgemeinen Prozess wie bei der Einrichtung der SageMaker KI-Integration. Eine Zusammenfassung dieses optionalen Einrichtungsprozesses finden Sie unter Einrichtung Ihres Aurora MySQL-DB-Clusters für die Verwendung von Amazon S3 for SageMaker AI (optional).
-
-
Für globale Aurora-Datenbanken richten Sie die Aurora-Dienste für maschinelles Lernen ein, die Sie in allen Bereichen AWS-Regionen Ihrer globalen Aurora-Datenbank verwenden möchten. Wenn Sie beispielsweise Aurora Machine Learning mit SageMaker KI für Ihre globale Aurora-Datenbank verwenden möchten, gehen Sie für jeden Aurora MySQL-DB-Cluster in jedem wie folgt vor AWS-Region:
-
Richten Sie die Amazon SageMaker AI-Services mit denselben SageMaker KI-Schulungsmodellen und Endpunkten ein. Diese müssen auch dieselben Namen tragen.
-
Erstellen Sie die IAM-Rollen wie unter Einrichten Ihres DB-Clusters von Aurora MySQL zur Verwendung von Aurora Machine Learning beschrieben.
-
Fügen Sie den ARN der IAM-Rolle der benutzerdefinierten DB-Cluster-Parametergruppe für jeden DB-Cluster von Aurora MySQL in jeder AWS-Region hinzu.
Diese Aufgaben setzen voraus, dass Aurora Machine Learning für Ihre Version von Aurora MySQL in allen Bereichen AWS-Regionen Ihrer globalen Aurora-Datenbank verfügbar ist.
-
Verfügbarkeit von Regionen und Versionen
Die Verfügbarkeit von Funktionen und der Support variieren zwischen bestimmten Versionen der einzelnen Aurora-Datenbank-Engines und in allen AWS-Regionen.
-
Informationen zur Version und regionalen Verfügbarkeit für Amazon Comprehend und Amazon SageMaker AI mit Aurora MySQL finden Sie unter. Aurora Machine Learning mit Aurora MySQL
-
Amazon Bedrock wird nur auf Aurora MySQL Version 3.06 und höher unterstützt.
Informationen zur Verfügbarkeit von Regionen für Amazon Bedrock finden Sie unter Modell-Support nach AWS-Region im Amazon-Bedrock-Benutzerhandbuch.
Unterstützte Funktionen und Einschränkungen von Aurora Machine Learning mit Aurora MySQL
Bei der Verwendung von Aurora MySQL mit Aurora Machine Learning gelten die folgenden Einschränkungen:
-
Die Aurora-Erweiterung für Machine Learning unterstützt keine Vektorschnittstellen.
-
Integrationen von Aurora Machine Learning werden nicht unterstützt, wenn sie in einem Auslöser verwendet werden.
Funktionen für Aurora Machine Learning sind mit der Binärprotokollreplikation (Binlog) nicht kompatibel.
-
Die Einstellung
--binlog-format=STATEMENTführt beim Aufrufen von Aurora Machine Learning-Funktionen zu einer Ausnahme. -
Aurora-Funktionen für Machine Learning sind nichtdeterministisch und nichtdeterministische gespeicherte Funktionen sind mit diesem Binlog-Format nicht kompatibel.
Weitere Informationen finden Sie unter Gemischte Binärprotokollformate
in der MySQL-Dokumentation. -
-
Gespeicherte Funktionen, die Tabellen mit „Generated-always“-Spalten aufrufen, werden nicht unterstützt. Dies gilt für jede gespeicherte Aurora-MySQL-Funktion. Weitere Informationen zu diesem Spaltentyp finden Sie unter CREATE TABLE und „Generated“-Spalten
in der MySQL-Dokumentation. -
Amazon Bedrock-Funktionen unterstützen
RETURNS JSONnicht. Sie könnenCONVERToderCASTverwenden, um bei Bedarf vonTEXTzuJSONzu konvertieren. -
Amazon Bedrock unterstützt keine Batch-Anforderungen.
-
Aurora MySQL unterstützt jeden SageMaker KI-Endpunkt, der das CSV-Format (Comma-Separated Value) liest und schreibt, und zwar über ein
ContentTypeof.text/csvDieses Format wird von den folgenden integrierten SageMaker KI-Algorithmen akzeptiert:-
Lineares Lernen
-
Random Cut Forest
-
XGBoost
Weitere Informationen zu diesen Algorithmen finden Sie unter Choose an Algorithm im Amazon SageMaker AI Developer Guide.
-
Einrichten Ihres DB-Clusters von Aurora MySQL zur Verwendung von Aurora Machine Learning
In den folgenden Themen finden Sie separate Einrichtungsverfahren für jeden dieser Aurora-Dienste für Machine Learning.
Topics
Einrichten Ihres DB-Clusters von Aurora MySQL zur Verwendung von Amazon Bedrock
Einrichten Ihres DB-Clusters von Aurora MySQL zur Verwendung von Amazon Comprehend
Einrichtung Ihres Aurora MySQL-DB-Clusters für die Verwendung von SageMaker KI
Erteilen des Zugriffs auf Aurora Machine Learning für Datenbankbenutzer
Einrichten Ihres DB-Clusters von Aurora MySQL zur Verwendung von Amazon Bedrock
Aurora Machine Learning stützt sich auf AWS Identity and Access Management (IAM-) Rollen und Richtlinien, damit Ihr Aurora MySQL-DB-Cluster auf die Amazon Bedrock-Services zugreifen und diese nutzen kann. Die folgenden Verfahren erstellen eine IAM-Berechtigungsrichtlinie und -rolle, sodass Ihr DB-Cluster in Amazon Bedrock integriert werden kann.
So erstellen Sie die -IAM-Richtlinie
Melden Sie sich bei der an AWS-Managementkonsole und öffnen Sie die IAM-Konsole unter. https://console.aws.amazon.com/iam/
-
Wählen Sie im Navigationsbereich Richtlinien aus.
-
Klicken Sie auf Create a policy (Richtlinie erstellen).
-
Wählen Sie auf der Seite Berechtigungen festlegen für Service auswählen die Option Bedrock aus.
Die Amazon-Bedrock-Berechtigungen werden angezeigt.
-
Erweitern Sie Lesen und wählen Sie dann aus InvokeModel.
-
Wählen Sie für Ressourcen die Option Alle aus.
Die Seite Berechtigungen angeben sollte wie die folgende Abbildung aussehen.
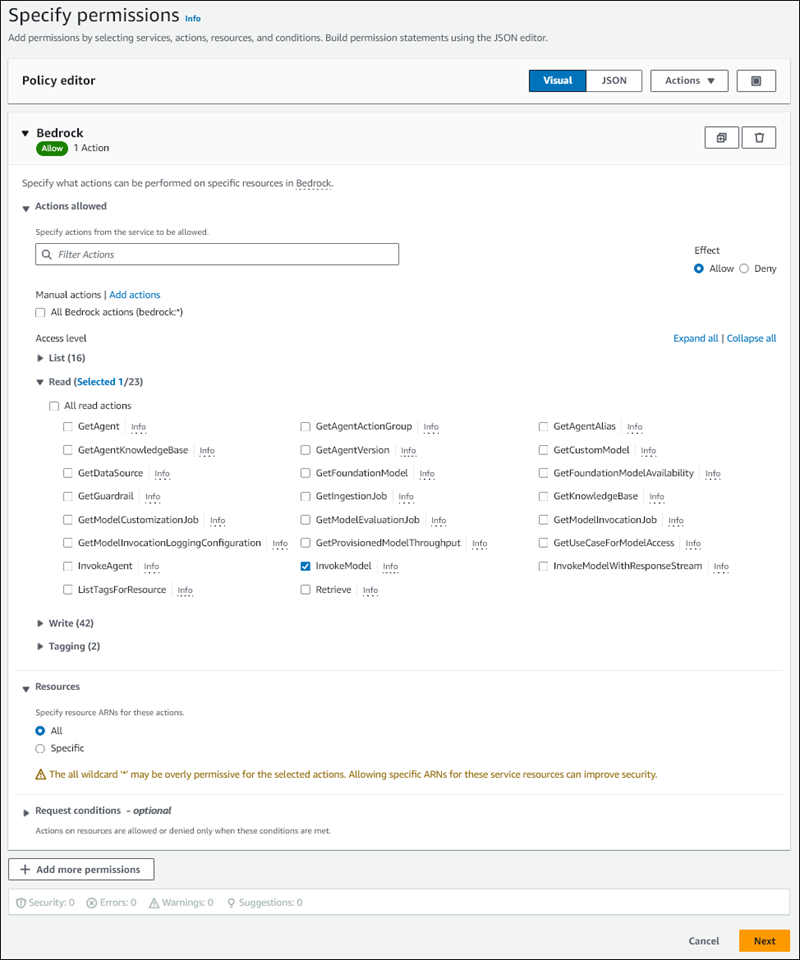
-
Wählen Sie Weiter aus.
-
Geben Sie auf der Seite Überprüfen und erstellen einen Namen für Ihre Richtlinie ein, zum Beispiel
BedrockInvokeModel. -
Überprüfen Sie Ihre Richtlinie und klicken Sie dann auf Richtlinie erstellen.
Als Nächstes erstellen Sie die IAM-Rolle, die die Amazon-Bedrock-Berechtigungsrichtlinie verwendet.
So erstellen Sie die IAM-Rolle
Melden Sie sich bei der an AWS-Managementkonsole und öffnen Sie die IAM-Konsole unter. https://console.aws.amazon.com/iam/
-
Wählen Sie im Navigationsbereich Roles (Rollen) aus.
-
Wählen Sie Rolle erstellen aus.
-
Wählen Sie auf der Seite Vertrauenswürdige Entitäten auswählen für Anwendungsfall die Option RDS aus.
-
Wählen Sie RDS – Rolle zur Datenbank hinzufügen und dann Weiter aus.
-
Wählen Sie auf der Seite Berechtigungen hinzufügen für Berechtigungsrichtlinien die von Ihnen erstellte IAM-Richtlinie und dann Weiter aus.
-
Geben Sie auf der Seite Benennen, überprüfen und erstellen einen Namen für Ihre Rolle ein, zum Beispiel
ams-bedrock-invoke-model-role.Die Rolle sollte in etwa wie die folgende Abbildung aussehen.
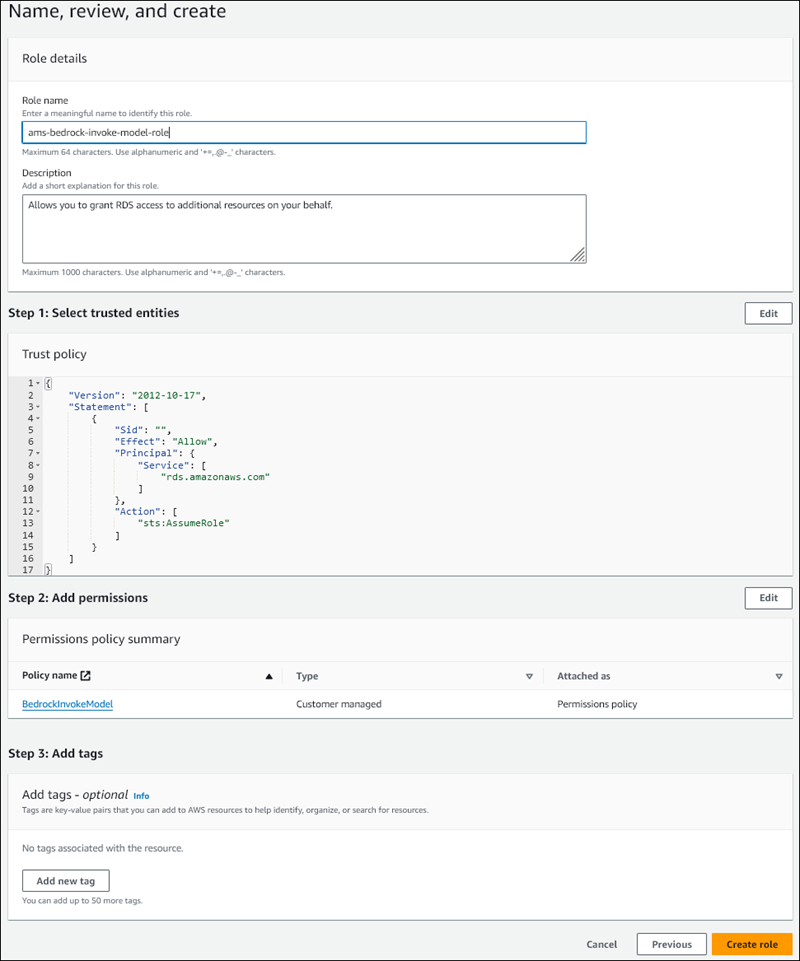
-
Überprüfen Sie die Rolle und wählen Sie dann Rolle erstellen aus.
Als Nächstes ordnen Sie Ihrem DB-Cluster die Amazon-Bedrock-IAM-Rolle zu.
So weisen Sie Ihrem Cluster die IAM-Rolle zu
Melden Sie sich bei der an AWS-Managementkonsole und öffnen Sie die Amazon RDS-Konsole unter https://console.aws.amazon.com/rds/
. -
Wählen Sie aus dem Navigationsbereich Datenbanken aus.
-
Wählen Sie den DB-Cluster von Aurora MySQL aus, den Sie mit Amazon-Bedrock-Services verbinden möchten.
-
Wählen Sie die Registerkarte Connectivity & security (Konnektivität und Sicherheit).
-
Wählen Sie im Abschnitt IAM-Rollen verwalten die Option IAM-Rollen auswählen, die diesem Cluster hinzugefügt werden sollen aus.
-
Wählen Sie die von Ihnen erstellte IAM-Rolle und dann Rolle hinzufügen aus.
Die IAM-Rolle ist Ihrem DB-Cluster zugeordnet, zunächst mit dem Status Ausstehend, dann mit dem Status Aktiv. Wenn der Vorgang abgeschlossen ist, wird die Rolle in der Liste Current IAM roles for this cluster (Aktuelle IAM-Rollen für diesen Cluster) angezeigt.
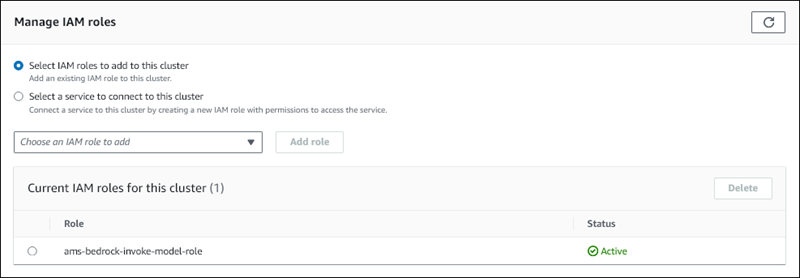
Sie müssen die ARN dieser IAM-Rolle dem Parameter aws_default_bedrock_role der benutzerdefinierten DB-Cluster-Parametergruppe hinzufügen, die mit dem DB-Cluster von Aurora MySQL verknüpft ist. Wenn Ihr DB-Cluster von Aurora MySQL keine benutzerdefinierte DB-Cluster-Parametergruppe verwendet, müssen Sie eine erstellen, die Sie mit Ihrem DB-Cluster von Aurora MySQL nutzen können, um die Integration abzuschließen. Weitere Informationen finden Sie unter DB-Cluster-Parametergruppen für Amazon-Aurora-DB-Cluster.
So konfigurieren Sie den DB-Cluster-Parameter
-
Öffnen Sie in der Amazon-RDS-Konsole die Registerkarte Configuration (Konfiguration) Ihres DB-Clusters von Aurora MySQL.
-
Suchen Sie die DB-Cluster-Parametergruppe, die für Ihren Cluster konfiguriert ist. Wählen Sie den Link zum Öffnen Ihrer benutzerdefinierten DB-Cluster-Parametergruppe und dann Bearbeiten aus.
-
Suchen Sie den
aws_default_bedrock_role-Parameter in Ihrer benutzerdefinierten DB-Cluster-Parametergruppe. -
Geben Sie im Feld Wert den ARN der IAM-Rolle ein.
-
Wählen Sie zum Speichern der Einstellung Save Changes (Änderungen speichern) aus.
-
Starten Sie die primäre Instance Ihres DB-Clusters von Aurora MySQL neu, damit diese Parametereinstellung wirksam wird.
Die IAM-Integration für Amazon Bedrock ist abgeschlossen. Fahren Sie mit der Einrichtung Ihres DB-Clusters von Aurora MySQL für den Einsatz von Amazon Bedrock durch Erteilen des Zugriffs auf Aurora Machine Learning für Datenbankbenutzer fort.
Einrichten Ihres DB-Clusters von Aurora MySQL zur Verwendung von Amazon Comprehend
Aurora Machine Learning stützt sich auf AWS Identity and Access Management Rollen und Richtlinien, damit Ihr Aurora MySQL-DB-Cluster auf die Amazon Comprehend-Services zugreifen und diese nutzen kann. Mit dem folgenden Verfahren werden automatisch eine IAM-Rolle und -Richtlinie für Ihren Cluster erstellt, sodass dieser Amazon Comprehend verwenden kann.
So richten Sie Ihren DB-Cluster von Aurora MySQL zur Verwendung von Amazon Comprehend ein
Melden Sie sich bei der an AWS-Managementkonsole und öffnen Sie die Amazon RDS-Konsole unter https://console.aws.amazon.com/rds/
. -
Wählen Sie aus dem Navigationsbereich Datenbanken aus.
-
Wählen Sie den DB-Cluster von Aurora MySQL aus, den Sie mit Amazon-Comprehend-Services verbinden möchten.
-
Wählen Sie die Registerkarte Connectivity & security (Konnektivität und Sicherheit).
-
Wählen im Abschnitt IAM-Rollen verwalten die Option Einen Service zum Herstellen einer Verbindung mit diesem Cluster auswählen aus.
-
Wählen Sie Amazon Comprehend aus dem Menü und dann Service verbinden aus.
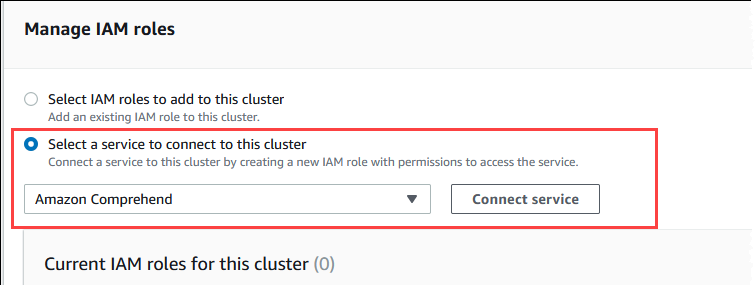
Für das Dialogfeld Connect cluster to Amazon Comprehend (Cluster mit Amazon Comprehend verbinden) sind keine zusätzlichen Informationen erforderlich. Möglicherweise wird jedoch eine Meldung mit dem Hinweis angezeigt, dass sich die Integration von Aurora und Amazon Comprehend derzeit in der Vorschau befindet. Lesen Sie die Nachricht unbedingt, bevor Sie fortfahren. Sie können Abbrechen auswählen, wenn Sie nicht fortfahren möchten.
Wählen Sie Connect service (Service verbinden) aus, um den Integrationsvorgang abzuschließen.
Aurora erstellt die IAM-Rolle. Außerdem wird die Richtlinie erstellt, die dem Aurora-MySQL-DB-Cluster die Nutzung der Amazon-Comprehend-Services ermöglicht, und die Richtlinie der Rolle angefügt. Wenn der Vorgang abgeschlossen ist, wird die Rolle in der Liste Current IAM roles for this cluster (Aktuelle IAM-Rollen für diesen Cluster) angezeigt, wie in der folgenden Abbildung dargestellt.
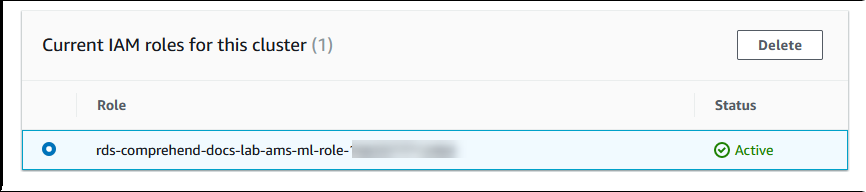
Sie müssen die ARN dieser IAM-Rolle dem Parameter
aws_default_comprehend_roleder benutzerdefinierten DB-Cluster-Parametergruppe hinzufügen, die mit dem DB-Cluster von Aurora MySQL verknüpft ist. Wenn Ihr DB-Cluster von Aurora MySQL keine benutzerdefinierte DB-Cluster-Parametergruppe verwendet, müssen Sie eine erstellen, die Sie mit Ihrem DB-Cluster von Aurora MySQL nutzen können, um die Integration abzuschließen. Weitere Informationen finden Sie unter DB-Cluster-Parametergruppen für Amazon-Aurora-DB-Cluster.Nachdem Sie Ihre benutzerdefinierte DB-Cluster-Parametergruppe erstellt und mit Ihrem DB-Cluster von Aurora MySQL verknüpft haben, können Sie mit den folgenden Schritten fortfahren.
Wenn Ihr Cluster eine benutzerdefinierte DB-Cluster-Parametergruppe verwendet, gehen Sie wie folgt vor.
Öffnen Sie in der Amazon-RDS-Konsole die Registerkarte Configuration (Konfiguration) Ihres DB-Clusters von Aurora MySQL.
-
Suchen Sie die DB-Cluster-Parametergruppe, die für Ihren Cluster konfiguriert ist. Wählen Sie den Link zum Öffnen Ihrer benutzerdefinierten DB-Cluster-Parametergruppe und dann Bearbeiten aus.
Suchen Sie den
aws_default_comprehend_role-Parameter in Ihrer benutzerdefinierten DB-Cluster-Parametergruppe.Geben Sie im Feld Wert den ARN der IAM-Rolle ein.
Wählen Sie zum Speichern der Einstellung Save Changes (Änderungen speichern) aus. Die folgende Abbildung zeigt ein Beispiel.
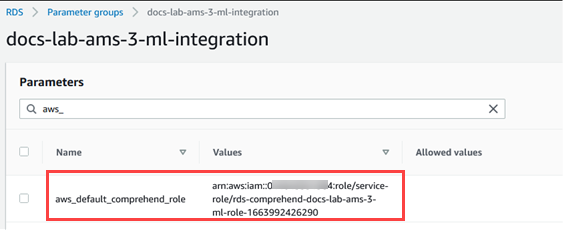
Starten Sie die primäre Instance Ihres DB-Clusters von Aurora MySQL neu, damit diese Parametereinstellung wirksam wird.
Die IAM-Integration für Amazon Comprehend ist abgeschlossen. Fahren Sie mit der Einrichtung Ihres DB-Clusters von Aurora MySQL zur Zusammenarbeit mit Amazon Comprehend fort, indem Sie den entsprechenden Datenbankbenutzern Zugriff gewähren.
Einrichtung Ihres Aurora MySQL-DB-Clusters für die Verwendung von SageMaker KI
Das folgende Verfahren erstellt automatisch die IAM-Rolle und -Richtlinie für Ihren Aurora MySQL-DB-Cluster, sodass dieser SageMaker KI verwenden kann. Bevor Sie versuchen, dieses Verfahren zu befolgen, stellen Sie sicher, dass Sie den SageMaker KI-Endpunkt verfügbar haben, damit Sie ihn bei Bedarf eingeben können. In der Regel ist es Aufgabe der Datenwissenschaftler in Ihrem Team, einen Endpunkt zu erstellen, den Sie von Ihrem DB-Cluster von Aurora MySQL aus verwenden können. Sie finden solche Endpunkte in der SageMaker AI-Konsole
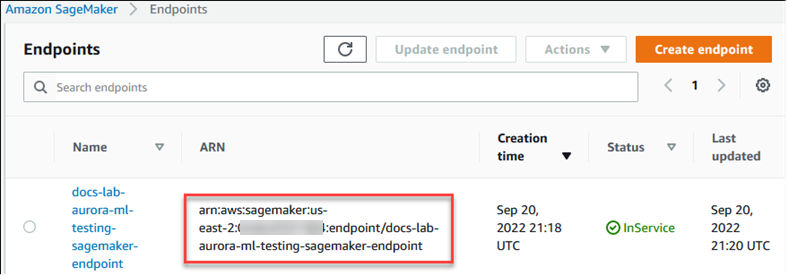
So richten Sie Ihren Aurora MySQL-DB-Cluster für die Verwendung von SageMaker KI ein
Melden Sie sich bei der an AWS-Managementkonsole und öffnen Sie die Amazon RDS-Konsole unter https://console.aws.amazon.com/rds/
. -
Wählen Sie im Amazon RDS-Navigationsmenü Datenbanken und dann den Aurora MySQL-DB-Cluster aus, den Sie mit SageMaker AI-Services verbinden möchten.
-
Wählen Sie die Registerkarte Connectivity & security (Konnektivität und Sicherheit).
-
Wählen Sie Select a service to connect to this cluster (Auswahl eines Services zur Verbindung mit diesem Cluster) im Abschnitt Manage IAM roles (IAM-Rollen verwalten) aus. Wählen Sie SageMaker AI aus der Auswahl aus.
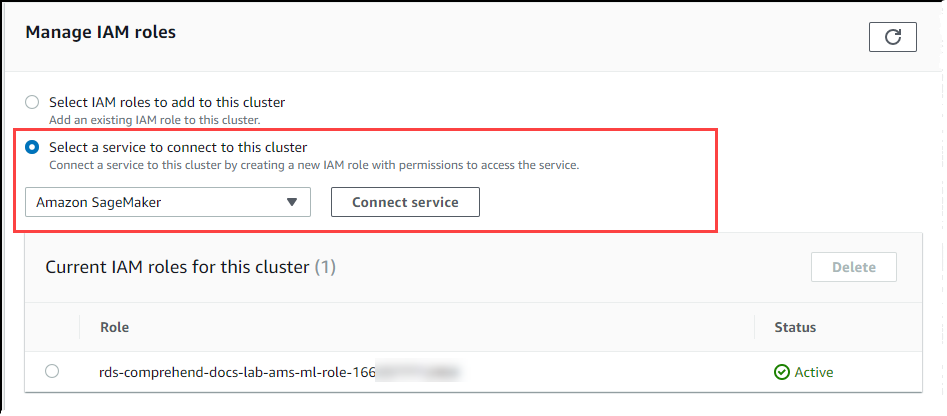
Wählen Sie Connect Service (Service verbinden).
Geben Sie im Dialogfeld Cluster mit SageMaker KI verbinden den ARN des SageMaker AI-Endpunkts ein.
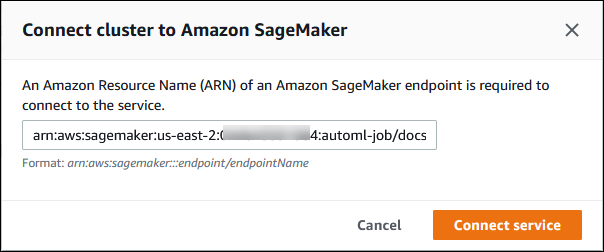
-
Aurora erstellt die IAM-Rolle. Es erstellt auch die Richtlinie, die es dem Aurora MySQL-DB-Cluster ermöglicht, SageMaker KI-Dienste zu nutzen, und fügt die Richtlinie der Rolle hinzu. Wenn der Vorgang abgeschlossen ist, wird die Rolle in der Liste Current IAM roles for this cluster (Aktuelle IAM-Rollen für diesen Cluster) angezeigt.
Öffnen Sie unter https://console.aws.amazon.com/iam/
die IAM-Konsole. Wählen Sie Roles (Rollen) aus dem Abschnitt „Access management“ (Zugriffsverwaltung) des Navigationsmenüs von AWS Identity and Access Management aus.
Suchen Sie die Rolle in der Liste. Der Name verwendet das folgende Format.
rds-sagemaker-your-cluster-name-role-auto-generated-digitsÖffnen Sie die Seite „Summary“ (Zusammenfassung) der Rolle und suchen Sie den ARN. Notieren Sie sich den ARN oder kopieren Sie ihn mit dem Widget „Copy“ (Kopieren).
Öffnen Sie die Amazon RDS-Konsole unter https://console.aws.amazon.com/rds/
. Wählen Sie Ihren DB-Cluster von Aurora MySQL und dann die Registerkarte Configuration (Konfiguration) aus.
Suchen Sie die DB-Cluster-Parametergruppe und wählen Sie den Link zum Öffnen Ihrer benutzerdefinierten DB-Cluster-Parametergruppe aus. Suchen Sie den
aws_default_sagemaker_role-Parameter und geben Sie den ARN der IAM-Rolle in das Feld „Value“ (Wert) ein. Speichern Sie die Einstellung mit „Save“ (Speichern).Starten Sie die primäre Instance Ihres DB-Clusters von Aurora MySQL neu, damit diese Parametereinstellung wirksam wird.
Die IAM-Einrichtung ist damit abgeschlossen. Setzen Sie die Einrichtung Ihres Aurora MySQL-DB-Clusters für die Zusammenarbeit mit SageMaker KI fort, indem Sie den entsprechenden Datenbankbenutzern Zugriff gewähren.
Wenn Sie Ihre SageMaker KI-Modelle für Schulungen verwenden möchten, anstatt vorgefertigte SageMaker KI-Komponenten zu verwenden, müssen Sie auch den Amazon S3 S3-Bucket zu Ihrem Aurora MySQL-DB-Cluster hinzufügen, wie im Einrichtung Ihres Aurora MySQL-DB-Clusters für die Verwendung von Amazon S3 for SageMaker AI (optional) Folgenden beschrieben.
Einrichtung Ihres Aurora MySQL-DB-Clusters für die Verwendung von Amazon S3 for SageMaker AI (optional)
Um SageMaker KI mit Ihren eigenen Modellen zu verwenden, anstatt die von SageMaker AI bereitgestellten vorgefertigten Komponenten zu verwenden, müssen Sie einen Amazon S3 S3-Bucket einrichten, den der Aurora MySQL-DB-Cluster verwenden kann. Weitere Informationen zum Erstellen eines Amazon-S3-Buckets finden Sie unter Erstellen von Buckets im Handbuch für Amazon Simple Storage Service.
So richten Sie Ihren Aurora MySQL-DB-Cluster für die Verwendung eines Amazon S3 S3-Buckets für SageMaker KI ein
Melden Sie sich bei der an AWS-Managementkonsole und öffnen Sie die Amazon RDS-Konsole unter https://console.aws.amazon.com/rds/
. -
Wählen Sie im Amazon RDS-Navigationsmenü Datenbanken und dann den Aurora MySQL-DB-Cluster aus, den Sie mit SageMaker AI-Services verbinden möchten.
-
Wählen Sie die Registerkarte Connectivity & security (Konnektivität und Sicherheit).
-
Wählen Sie Select a service to connect to this cluster (Auswahl eines Services zur Verbindung mit diesem Cluster) im Abschnitt Manage IAM roles (IAM-Rollen verwalten) aus. Wählen Sie Amazon S3 in der Auswahl aus.
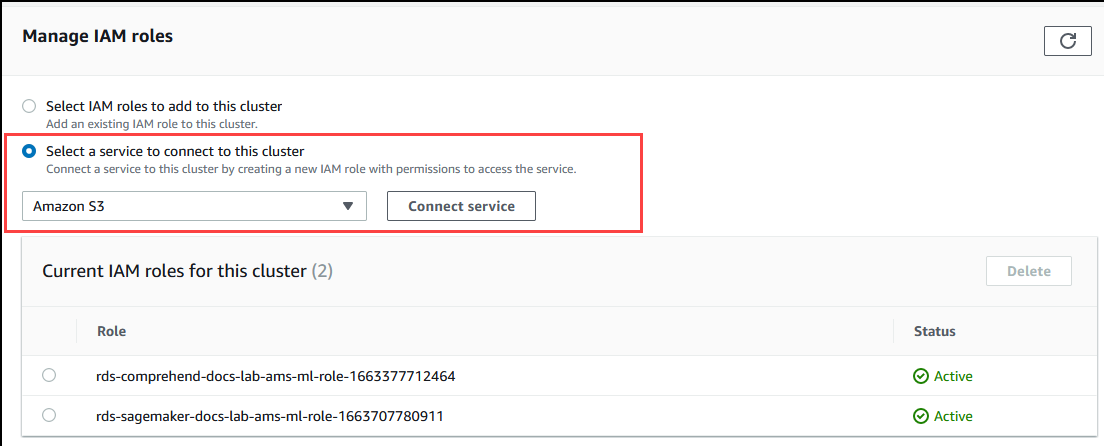
Wählen Sie Connect Service (Service verbinden).
Geben Sie im Dialogfeld Cluster mit Amazon S3 verbinden den ARN des Amazon-S3-Buckets ein, wie in der folgenden Abbildung dargestellt.
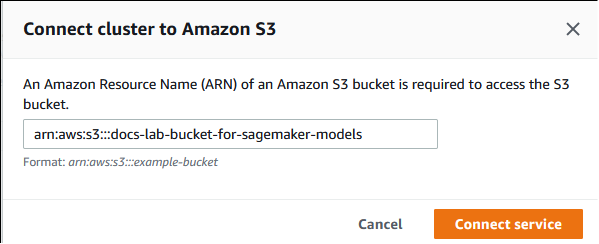
Wählen Sie Connect service (Service verbinden) aus, um den Integrationsvorgang abzuschließen.
Weitere Informationen zur Verwendung von Amazon S3 S3-Buckets mit SageMaker KI finden Sie unter Spezifizieren eines Amazon S3 S3-Buckets zum Hochladen von Trainingsdatensätzen und Speichern von Ausgabedaten im Amazon SageMaker AI Developer Guide. Weitere Informationen zur Arbeit mit SageMaker KI finden Sie unter Erste Schritte mit Amazon SageMaker AI Notebook Instances im Amazon SageMaker AI Developer Guide.
Erteilen des Zugriffs auf Aurora Machine Learning für Datenbankbenutzer
Datenbankbenutzern muss die Berechtigung zum Aufrufen von Aurora-Machine-Learning-Funktionen erteilt werden. Wie Sie Berechtigungen erteilen, hängt von der MySQL-Version ab, die Sie für Ihren DB-Cluster von Aurora MySQL verwenden, wie im Folgenden beschrieben. Wie Sie diesen Vorgang ausführen, hängt von der MySQL-Version ab, die Ihr DB-Cluster von Aurora MySQL verwendet.
Für Aurora-MySQL-Version 3 (mit MySQL 8.0 kompatibel) muss Datenbankbenutzern die entsprechende Datenbankrolle zugewiesen werden. Weitere Informationen finden Sie unter Verwenden von Rollen
im MySQL 8.0-Referenzhandbuch. Für Aurora-MySQL-Version 2 (mit MySQL 5.7 kompatibel) werden Datenbankbenutzern Berechtigungen erteilt. Weitere Informationen finden Sie unter Access Control and Account Management
im MySQL-5.7-Referenzhandbuch.
Die folgende Tabelle zeigt die Rollen und Berechtigungen, die Datenbankbenutzer benötigen, um mit Funktionen für Machine Learning zu arbeiten.
| Aurora-MySQL-Version 3 (Rolle) | Aurora MySQL Version 2 (Berechtigung) |
|---|---|
|
AWS_BEDROCK_ACCESS |
– |
|
AWS_COMPREHEND_ACCESS |
INVOKE COMPREHEND |
|
AWS_SAGEMAKER_ACCESS |
INVOKE SAGEMAKER |
Erteilen des Zugriffs auf Amazon-Bedrock-Funktionen
Wenn Sie Datenbankbenutzern Zugriff auf Amazon-Bedrock-Funktionen erteilen möchten, verwenden Sie die folgende SQL-Anweisung:
GRANT AWS_BEDROCK_ACCESS TOuser@domain-or-ip-address;
Datenbankbenutzern müssen außerdem EXECUTE-Berechtigungen für die Funktionen erteilt werden, die Sie für die Arbeit mit Amazon Bedrock erstellen.
GRANT EXECUTE ON FUNCTIONdatabase_name.function_nameTOuser@domain-or-ip-address;
Schließlich müssen die Rollen der Datenbankbenutzer auf AWS_BEDROCK_ACCESS festgelegt sein:
SET ROLE AWS_BEDROCK_ACCESS;
Die Amazon-Bedrock-Funktionen sind jetzt verfügbar.
Erteilen des Zugriffs auf Amazon-Comprehend-Funktionen
Wenn Sie Datenbankbenutzern Zugriff auf Amazon-Comprehend-Funktionen erteilen möchten, verwenden Sie die entsprechende Anweisung für Ihre Aurora-MySQL-Version.
Aurora-MySQL-Version 3 (mit MySQL 8.0 kompatibel)
GRANT AWS_COMPREHEND_ACCESS TOuser@domain-or-ip-address;Aurora-MySQL-Version 2 (mit MySQL 5.7 kompatibel)
GRANT INVOKE COMPREHEND ON *.* TOuser@domain-or-ip-address;
Die Amazon-Comprehend-Funktionen sind jetzt verfügbar. Anwendungsbeispiele finden Sie unter Verwenden von Amazon Comprehend mit Ihrem DB-Cluster von Aurora MySQL.
Zugriff auf SageMaker KI-Funktionen gewähren
Um Datenbankbenutzern Zugriff auf SageMaker KI-Funktionen zu gewähren, verwenden Sie die entsprechende Anweisung für Ihre Aurora MySQL-Version.
Aurora-MySQL-Version 3 (mit MySQL 8.0 kompatibel)
GRANT AWS_SAGEMAKER_ACCESS TOuser@domain-or-ip-address;Aurora-MySQL-Version 2 (mit MySQL 5.7 kompatibel)
GRANT INVOKE SAGEMAKER ON *.* TOuser@domain-or-ip-address;
Datenbankbenutzern müssen außerdem EXECUTE Berechtigungen für die Funktionen erteilt werden, die Sie für die Arbeit mit SageMaker KI erstellen. Angenommen, Sie haben zwei Funktionen erstellt, db1.anomoly_score unddb2.company_forecasts, um die Dienste Ihres SageMaker KI-Endpunkts aufzurufen. Sie gewähren Ausführungsberechtigungen wie im folgenden Beispiel dargestellt.
GRANT EXECUTE ON FUNCTION db1.anomaly_score TOuser1@domain-or-ip-address1; GRANT EXECUTE ON FUNCTION db2.company_forecasts TOuser2@domain-or-ip-address2;
Die SageMaker KI-Funktionen können jetzt verwendet werden. Anwendungsbeispiele finden Sie unter SageMaker KI mit Ihrem Aurora MySQL-DB-Cluster verwenden.
Verwenden von Amazon Bedrock mit Ihrem DB-Cluster von Aurora MySQL
Um Amazon Bedrock zu verwenden, erstellen Sie eine benutzerdefinierte Funktion (UDF) in Ihrer Aurora-MySQL-Datenbank, die ein Modell aufruft. Weitere Informationen finden Sie unter Was ist Amazon Bedrock? im Amazon Bedrock-Benutzerhandbuch.
Eine UDF verwendet die folgende Syntax:
CREATE FUNCTIONfunction_name(argumenttype) [DEFINER = user] RETURNSmysql_data_type[SQL SECURITY {DEFINER | INVOKER}] ALIAS AWS_BEDROCK_INVOKE_MODEL MODEL ID 'model_id' [CONTENT_TYPE 'content_type'] [ACCEPT 'content_type'] [TIMEOUT_MStimeout_in_milliseconds];
-
Amazon Bedrock-Funktionen unterstützen
RETURNS JSONnicht. Sie könnenCONVERToderCASTverwenden, um bei Bedarf vonTEXTzuJSONzu konvertieren. -
Wenn Sie weder
CONTENT_TYPEnochACCEPTangeben, wird standardmäßigapplication/jsonverwendet. -
Wenn Sie kein
TIMEOUT_MSangeben, wird der Standardwertaurora_ml_inference_timeoutverwendet.
Die folgende UDF ruft beispielsweise das Modell „Amazon Titan Text Express“ auf:
CREATE FUNCTION invoke_titan (request_body TEXT) RETURNS TEXT ALIAS AWS_BEDROCK_INVOKE_MODEL MODEL ID 'amazon.titan-text-express-v1' CONTENT_TYPE 'application/json' ACCEPT 'application/json';
Verwenden Sie den folgenden SQL-Befehl, um einem DB-Benutzer die Verwendung dieser Funktion zu ermöglichen:
GRANT EXECUTE ON FUNCTIONdatabase_name.invoke_titan TOuser@domain-or-ip-address;
Dann kann der Benutzer invoke_titan wie jede andere Funktion aufrufen, wie im folgenden Beispiel gezeigt. Achten Sie darauf, den Text der Anforderung gemäß den Textmodellen von Amazon Titan zu formatieren.
CREATE TABLE prompts (request varchar(1024)); INSERT INTO prompts VALUES ( '{ "inputText": "Generate synthetic data for daily product sales in various categories - include row number, product name, category, date of sale and price. Produce output in JSON format. Count records and ensure there are no more than 5.", "textGenerationConfig": { "maxTokenCount": 1024, "stopSequences": [], "temperature":0, "topP":1 } }'); SELECT invoke_titan(request) FROM prompts; {"inputTextTokenCount":44,"results":[{"tokenCount":296,"outputText":" ```tabular-data-json { "rows": [ { "Row Number": "1", "Product Name": "T-Shirt", "Category": "Clothing", "Date of Sale": "2024-01-01", "Price": "$20" }, { "Row Number": "2", "Product Name": "Jeans", "Category": "Clothing", "Date of Sale": "2024-01-02", "Price": "$30" }, { "Row Number": "3", "Product Name": "Hat", "Category": "Accessories", "Date of Sale": "2024-01-03", "Price": "$15" }, { "Row Number": "4", "Product Name": "Watch", "Category": "Accessories", "Date of Sale": "2024-01-04", "Price": "$40" }, { "Row Number": "5", "Product Name": "Phone Case", "Category": "Accessories", "Date of Sale": "2024-01-05", "Price": "$25" } ] } ```","completionReason":"FINISH"}]}
Achten Sie bei anderen Modellen, die Sie verwenden, darauf, den Anforderungstext entsprechend zu formatieren. Weitere Informationen finden Sie unter Inferenzparameter für Fundamentmodelle im Amazon Bedrock-Benutzerhandbuch.
Verwenden von Amazon Comprehend mit Ihrem DB-Cluster von Aurora MySQL
Für Aurora MySQL bietet Aurora Machine Learning die folgenden zwei integrierten Funktionen für die Arbeit mit Amazon Comprehend und Ihren Textdaten. Sie geben den zu analysierenden Text (input_data) und die Sprache (language_code) an.
- aws_comprehend_detect_sentiment
-
Diese Funktion erkennt, dass der Text eine positive, negative, neutrale oder gemischte emotionale Haltung hat. Die Referenzdokumentation dieser Funktion lautet wie folgt.
aws_comprehend_detect_sentiment( input_text, language_code [,max_batch_size] )Weitere Informationen finden Sie unter Stimmung im Entwicklerhandbuch für Amazon Comprehend.
- aws_comprehend_detect_sentiment_confidence
-
Diese Funktion misst den Wahrscheinlichkeitsgrad der für einen bestimmten Text erkannten Stimmung. Sie gibt einen Wert (Typ,
double) zurück, der die Wahrscheinlichkeit der Stimmung angibt, die dem Text von der aws_comprehend_detect_sentiment-Funktion zugewiesen wurde. Die Wahrscheinlichkeit ist eine statistische Metrik zwischen 0 und 1. Je höher der Wahrscheinlichkeitsgrad ist, desto stärker können Sie das Ergebnis gewichten. Eine Zusammenfassung der Dokumentation der Funktion lautet wie folgt.aws_comprehend_detect_sentiment_confidence( input_text, language_code [,max_batch_size] )
In beiden Funktionen (aws_comprehend_detect_sentiment_confidence, aws_comprehend_detect_sentiment) verwendet max_batch_size den Standardwert 25, wenn kein Wert angegeben ist. Die Batch-Größe sollte immer größer als 0 sein. Sie können max_batch_size zur Optimierung der Leistung der Amazon-Comprehend-Funktionsaufrufe verwenden. Große Stapel bieten schnellere Leistung bei gleichzeitig höherer Speichernutzung auf dem DB-Cluster von Aurora MySQL. Weitere Informationen finden Sie unter Leistungsaspekte zur Verwendung von Aurora Machine Learning mit Aurora MySQL.
Weitere Informationen zu Parametern und Rückgabetypen für die Stimmungserkennungsfunktionen in Amazon Comprehend finden Sie unter DetectSentiment
Beispiel Beispiel: Eine einfache Abfrage mit Amazon-Comprehend-Funktionen
Hier ist ein Beispiel für eine einfache Abfrage, die diese beiden Funktionen aufruft, um festzustellen, wie zufrieden Ihre Kunden mit Ihrem Support-Team sind. Angenommen, Sie haben eine Datenbanktabelle (support), in der Kundenfeedback nach jeder Supportanfrage gespeichert wird. Diese Beispielabfrage wendet beide integrierten Funktionen auf den Text in der feedback-Spalte der Tabelle an und gibt die Ergebnisse aus. Die von der Funktion zurückgegebenen Wahrscheinlichkeitswerte sind Doppelwerte zwischen 0,0 und 1,0. Für eine besser lesbare Ausgabe rundet diese Abfrage die Ergebnisse auf 6 Dezimalstellen auf. Diese Abfrage sortiert außerdem die Ergebnisse in absteigender Reihenfolge, angefangen mit dem Ergebnis mit dem höchsten Wahrscheinlichkeitsgrad, um Vergleiche einfacher zu gestalten.
SELECT feedback AS 'Customer feedback', aws_comprehend_detect_sentiment(feedback, 'en') AS Sentiment, ROUND(aws_comprehend_detect_sentiment_confidence(feedback, 'en'), 6) AS Confidence FROM support ORDER BY Confidence DESC;+----------------------------------------------------------+-----------+------------+ | Customer feedback | Sentiment | Confidence | +----------------------------------------------------------+-----------+------------+ | Thank you for the excellent customer support! | POSITIVE | 0.999771 | | The latest version of this product stinks! | NEGATIVE | 0.999184 | | Your support team is just awesome! I am blown away. | POSITIVE | 0.997774 | | Your product is too complex, but your support is great. | MIXED | 0.957958 | | Your support tech helped me in fifteen minutes. | POSITIVE | 0.949491 | | My problem was never resolved! | NEGATIVE | 0.920644 | | When will the new version of this product be released? | NEUTRAL | 0.902706 | | I cannot stand that chatbot. | NEGATIVE | 0.895219 | | Your support tech talked down to me. | NEGATIVE | 0.868598 | | It took me way too long to get a real person. | NEGATIVE | 0.481805 | +----------------------------------------------------------+-----------+------------+ 10 rows in set (0.1898 sec)
Beispiel Beispiel: Ermitteln der durchschnittlichen Stimmung für Text oberhalb eines bestimmten Wahrscheinlichkeitsgrads
Eine typische Amazon Comprehend-Abfrage sucht nach Zeilen, auf denen die Stimmung einen bestimmten Wert hat, mit einem Zuverlässigkeitsniveau, das über einem bestimmten numerischen Wert liegt. Beispielsweise zeigt die folgende Abfrage, wie Sie die durchschnittliche Stimmung in Dokumenten in Ihrer Datenbank feststellen können. Die Abfrage berücksichtigt nur Dokumente mit einer Feststellungszuverlässigkeit von mindestens 80 %.
SELECT AVG(CASE aws_comprehend_detect_sentiment(productTable.document, 'en') WHEN 'POSITIVE' THEN 1.0 WHEN 'NEGATIVE' THEN -1.0 ELSE 0.0 END) AS avg_sentiment, COUNT(*) AS total FROM productTable WHERE productTable.productCode = 1302 AND aws_comprehend_detect_sentiment_confidence(productTable.document, 'en') >= 0.80;
SageMaker KI mit Ihrem Aurora MySQL-DB-Cluster verwenden
Um SageMaker KI-Funktionen aus Ihrem Aurora MySQL-DB-Cluster zu nutzen, müssen Sie gespeicherte Funktionen erstellen, die Ihre Aufrufe in den SageMaker KI-Endpunkt und seine Inferenzfunktionen einbetten. Verwenden Sie dazu CREATE FUNCTION von MySQL im Prinzip auf die gleiche Weise wie für andere Verarbeitungsaufgaben auf Ihrem DB-Cluster von Aurora MySQL.
Um in SageMaker KI bereitgestellte Modelle für Inferenz zu verwenden, erstellen Sie benutzerdefinierte Funktionen mithilfe von MySQL Data Definition Language (DDL) -Anweisungen für gespeicherte Funktionen. Jede gespeicherte Funktion stellt den SageMaker KI-Endpunkt dar, der das Modell hostet. Wenn Sie eine solche Funktion definieren, geben Sie die Eingabeparameter für das Modell, den spezifischen SageMaker AI-Endpunkt, der aufgerufen werden soll, und den Rückgabetyp an. Die Funktion gibt die vom SageMaker KI-Endpunkt berechnete Inferenz zurück, nachdem das Modell auf die Eingabeparameter angewendet wurde.
Alle gespeicherten Aurora Machine Learning-Funktionen geben numerische Typen oder zurüc VARCHAR. Sie können alle numerischen Typen außer verwende BIT. Andere Typen wie etwa JSON, BLOB, TEXT oder DATE sind nicht zulässig.
Das folgende Beispiel zeigt die CREATE FUNCTION Syntax für die Arbeit mit SageMaker KI.
CREATE FUNCTION function_name (
arg1 type1,
arg2 type2, ...)
[DEFINER = user]
RETURNS mysql_type
[SQL SECURITY { DEFINER | INVOKER } ]
ALIAS AWS_SAGEMAKER_INVOKE_ENDPOINT
ENDPOINT NAME 'endpoint_name'
[MAX_BATCH_SIZE max_batch_size];
Dies ist eine Erweiterung der regulären CREATE FUNCTION-DDL-Anweisung. In der CREATE FUNCTION Anweisung, die die SageMaker AI-Funktion definiert, geben Sie keinen Funktionskörper an. Stattdessen geben Sie das Schlüsselwort ALIAS dort an, wo normalerweise der Funktionstext steht. Derzeit unterstützt Aurora Machine Learning nur aws_sagemaker_invoke_endpoint für diese erweiterte Syntax. Sie müssen den Parameter endpoint_name angeben. Ein SageMaker KI-Endpunkt kann für jedes Modell unterschiedliche Eigenschaften aufweisen.
Anmerkung
Weitere Informationen zu CREATE FUNCTION finden Sie unter CREATE PROCEDURE- und CREATE FUNCTION-Anweisungen
Der Parameter max_batch_size ist optional. Standardmäßig beträgt die maximale Stapelgröße 10 000. Sie können diesen Parameter in Ihrer Funktion verwenden, um die maximale Anzahl von Eingaben zu beschränken, die in einer Batch-Anfrage an SageMaker KI verarbeitet werden. Der max_batch_size Parameter kann dazu beitragen, Fehler zu vermeiden, die durch zu große Eingaben verursacht werden, oder SageMaker KI dazu zu bringen, schneller eine Antwort zurückzugeben. Dieser Parameter wirkt sich auf die Größe eines internen Puffers aus, der für die Verarbeitung von SageMaker KI-Anfragen verwendet wird. Die Angabe eines zu großen Werts für max_batch_size kann zu erheblicher Speicherüberlastung auf Ihrer DB-Instance führen.
Wir empfehlen Ihnen, für die Einstellung MANIFEST den Standardwert OFF zu belassen. Sie können die MANIFEST ON Option zwar verwenden, aber einige SageMaker KI-Funktionen können die mit dieser Option exportierte CSV nicht direkt verwenden. Das Manifestformat ist nicht mit dem erwarteten Manifestformat von SageMaker AI kompatibel.
Sie erstellen für jedes Ihrer SageMaker KI-Modelle eine separate gespeicherte Funktion. Dieses Mapping von Funktionen zu Modellen ist erforderlich, da ein Endpunkt mit einem spezifischen Modell verbunden ist und jedes Modell unterschiedliche Parameter akzeptiert. Die Verwendung von SQL-Typen für die Modelleingaben und den Modellausgabetyp trägt dazu bei, Typkonvertierungsfehler zu vermeiden, bei der Daten zwischen den AWS Diensten hin- und hergeschickt werden. Sie können steuern, wer das Modell anwenden kann. Sie können auch die Laufzeiteigenschaften steuern, indem Sie einen Parameter angeben, der für die maximale Stapelgröße steht.
Derzeit haben alle Aurora Machine Learning-Funktionen die NOT DETERMINISTIC-Eigenschaft. Wenn Sie diese Eigenschaft nicht explizit angeben, richtet Aurora NOT DETERMINISTIC automatisch ein. Diese Anforderung ist darauf zurückzuführen, dass das SageMaker KI-Modell ohne Benachrichtigung an die Datenbank geändert werden kann. Wenn dies geschieht, führen Aufrufe an eine Aurora Machine Learning-Funktion möglicherweise zu unterschiedlichen Ergebnissen für gleiche Eingaben innerhalb einer einzigen Transaktion.
Sie können die Merkmale CONTAINS SQL, NO SQL, READS SQL DATA oder MODIFIES SQL DATA in Ihrer CREATE
FUNCTION-Anweisung nicht verwenden.
Im Folgenden finden Sie ein Beispiel für die Verwendung des Aufrufs eines SageMaker KI-Endpunkts zur Erkennung von Anomalien. Es gibt einen KI-Endpunkt SageMaker . random-cut-forest-model Das entsprechende Modell wurde bereits durch den random-cut-forest-Algorithmus trainiert. Für jede Eingabe gibt das Modell einen Anomaliewert aus. Dieses Beispiel zeigt die Datenpunkte, deren Wert über 3 Standardabweichungen (etwa das 99,9-te Perzentil) vom Durchschnittsergebnis liegt.
CREATE FUNCTION anomaly_score(value real) returns real
alias aws_sagemaker_invoke_endpoint endpoint name 'random-cut-forest-model-demo';
set @score_cutoff = (select avg(anomaly_score(value)) + 3 * std(anomaly_score(value)) from nyc_taxi);
select *, anomaly_detection(value) score from nyc_taxi
where anomaly_detection(value) > @score_cutoff;
Zeichensatzanforderung für SageMaker KI-Funktionen, die Zeichenketten zurückgeben
Wir empfehlen, einen Zeichensatz von utf8mb4 als Rückgabetyp für Ihre SageMaker KI-Funktionen anzugeben, die Zeichenkettenwerte zurückgeben. Wenn dies nicht sinnvoll ist, verwenden Sie eine ausreichende Zeichenfolgenlänge, damit der Rückgabetyp einen im utf8mb4-Zeichensatz ausgedrückten Wert aufnehmen kann. Das folgende Beispiel illustriert die Angabe des utf8mb4-Zeichensatzes für Ihre Funktion.
CREATE FUNCTION my_ml_func(...) RETURNS VARCHAR(5) CHARSET utf8mb4 ALIAS ...Derzeit verwendet jede SageMaker AI-Funktion, die eine Zeichenfolge zurückgibt, den Zeichensatz utf8mb4 als Rückgabewert. Der Rückgabewert verwendet diesen Zeichensatz, auch wenn Ihre SageMaker AI-Funktion implizit oder explizit einen anderen Zeichensatz für ihren Rückgabetyp deklariert. Wenn Ihre SageMaker AI-Funktion einen anderen Zeichensatz für den Rückgabewert deklariert, werden die zurückgegebenen Daten möglicherweise stillschweigend gekürzt, wenn Sie sie in einer Tabellenspalte speichern, die nicht lang genug ist. Beispielsweise erstellt eine Abfrage mit einer DISTINCT-Klausel eine temporäre Tabelle. Daher kann das Ergebnis der SageMaker AI-Funktion aufgrund der Art und Weise, wie Zeichenketten während einer Abfrage intern behandelt werden, gekürzt werden.
Exportieren von Daten nach Amazon S3 für das SageMaker KI-Modelltraining (Fortgeschritten)
Wir empfehlen Ihnen, mit Aurora Machine Learning und SageMaker KI zu beginnen, indem Sie einige der bereitgestellten Algorithmen verwenden und dass die Datenwissenschaftler in Ihrem Team Ihnen die SageMaker KI-Endpunkte zur Verfügung stellen, die Sie mit Ihrem SQL-Code verwenden können. Im Folgenden finden Sie minimale Informationen zur Verwendung Ihres eigenen Amazon S3 S3-Buckets mit Ihren eigenen SageMaker KI-Modellen und Ihrem Aurora MySQL-DB-Cluster.
Machine Learning besteht aus zwei Hauptschritten: Training und Inferenz. Um SageMaker KI-Modelle zu trainieren, exportieren Sie Daten in einen Amazon S3 S3-Bucket. Der Amazon S3 S3-Bucket wird von einer Jupyter SageMaker AI-Notebook-Instance verwendet, um Ihr Modell vor der Bereitstellung zu trainieren. Sie können die Anweisung SELECT INTO OUTFILE S3 verwenden, um Daten aus einem Aurora MySQL-DB-Cluster abzufragen und sie direkt in Textdateien in einem Amazon S3-Bucket zu speichern. Anschließend verwendet die Notebook-Instance die Daten aus dem Amazon S3-Bucket für das Training.
Aurora Machine Learning erweitert die bestehende SELECT INTO OUTFILE-Syntax in Aurora MySQL zum Export von Daten im CSV-Format. Die generierte CSV-Datei kann direkt von Modellen verwendet werden, die dieses Format für Trainingszwecke benötigen.
SELECT * INTO OUTFILE S3 's3_uri' [FORMAT {CSV|TEXT} [HEADER]] FROM table_name;Die Erweiterung unterstützt das Standard-CSV-Format.
-
Format
TEXTist identisch mit dem bestehenden MySQL-Exportformat. Dies ist das Standardformat. -
Format
CSVist ein neu eingeführtes Format, das der Spezifikation in folgt. RFC-4180 -
Wenn Sie das optionale Schlüsselwort
HEADERangeben, enthält die Ausgabedatei eine Kopfzeile. Die Beschriftungen in der Kopfzeile entsprechen den Spaltennamen aus derSELECT-Anweisung. -
Sie können die Schlüsselwörter
CSVundHEADERweiterhin als Kennungen verwenden.
Die erweiterte Syntax und Grammatik von SELECT INTO sind jetzt wie folgt.
INTO OUTFILE S3 's3_uri'
[CHARACTER SET charset_name]
[FORMAT {CSV|TEXT} [HEADER]]
[{FIELDS | COLUMNS}
[TERMINATED BY 'string']
[[OPTIONALLY] ENCLOSED BY 'char']
[ESCAPED BY 'char']
]
[LINES
[STARTING BY 'string']
[TERMINATED BY 'string']
]
Leistungsaspekte zur Verwendung von Aurora Machine Learning mit Aurora MySQL
Die Dienste Amazon Bedrock, Amazon Comprehend und SageMaker KI erledigen den Großteil der Arbeit, wenn sie von einer Aurora-Funktion für maschinelles Lernen aufgerufen werden. Das bedeutet, dass Sie diese Ressourcen nach Bedarf unabhängig voneinander skalieren können. Für Ihren DB-Cluster von Aurora MySQL können Sie Ihre Funktionsaufrufe so effizient wie möglich gestalten. Im Folgenden finden Sie einige Leistungsaspekte, die Sie bei der Arbeit mit Aurora Machine Learning beachten sollten.
Modell und Prompt
Die Leistung bei der Verwendung von Amazon Bedrock hängt stark vom Modell und vom verwendeten Prompt ab. Wählen Sie ein Modell und einen Prompt aus, die für Ihren Anwendungsfall optimal geeignet sind.
Abfrage-Cache
Der Abfrage-Cache von Aurora MySQL funktioniert nicht für Aurora-Funktionen für Machine Learning. Aurora MySQL speichert keine Abfrageergebnisse im Abfrage-Cache für SQL-Anweisungen, die Aurora-Funktionen für Machine Learning aufrufen.
Batch-Optimierung für Aurora-Machine-Learning-Funktionsaufrufe
Der wichtigste Aurora Machine Learning-Performanceaspekt, den Sie von Ihrem Aurora-Cluster aus beeinflussen können, ist die Batch-Moduseinstellung für Aufrufe der gespeicherten Aurora-Machine-Learning-Funktion. Machine-Learning-Funktionen erfordern in der Regel einen erheblichen Overhead, was es unpraktisch macht, einen externen Service für jede Zeile separat aufzurufen. Aurora Machine Learning kann diesen Overhead minimieren, indem die Aufrufe des externen Aurora-Machine-Learning-Services für viele Zeilen in einem einzigen Batch zusammengefasst werden. Aurora Machine Learning empfängt die Antworten für alle Eingabezeilen und liefert die Antworten Zeile für Zeile an die Abfrage, während sie ausgeführt wird. Diese Optimierung verbessert den Durchsatz und die Latenz für Ihre Aurora-Abfragen ohne Änderungen bei den Ergebnissen.
Wenn Sie eine gespeicherte Aurora-Funktion erstellen, die mit einem SageMaker KI-Endpunkt verbunden ist, definieren Sie den Batchgröße-Parameter. Dieser Parameter beeinflusst, wie viele Zeilen für jeden zugrunde liegenden Aufruf an SageMaker AI übertragen werden. Bei Abfragen, die eine große Anzahl von Zeilen verarbeiten, kann der Aufwand, für jede Zeile einen separaten SageMaker KI-Aufruf zu tätigen, erheblich sein. Je größer der von der gespeicherten Prozedur verarbeitete Datensatz ist, umso größer kann die Stapelgröße gewählt werden.
Ob die Optimierung im Batchmodus auf eine SageMaker AI-Funktion angewendet werden kann, können Sie anhand des durch die EXPLAIN PLAN Anweisung erstellten Abfrageplans feststellen. In diesem Fall enthält die extra-Spalte in dem Ausführungsplan Batched machine learning. Das folgende Beispiel zeigt einen Aufruf einer SageMaker AI-Funktion, die den Batch-Modus verwendet.
mysql> CREATE FUNCTION anomaly_score(val real) returns real alias aws_sagemaker_invoke_endpoint endpoint name 'my-rcf-model-20191126';
Query OK, 0 rows affected (0.01 sec)
mysql> explain select timestamp, value, anomaly_score(value) from nyc_taxi;
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | nyc_taxi | NULL | ALL | NULL | NULL | NULL | NULL | 48 | 100.00 | Batched machine learning |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+--------------------------+
1 row in set, 1 warning (0.01 sec)
Wenn Sie eine der integrierten Amazon Comprehend-Funktionen aufrufen, können Sie die Stapelgröße steuern, indem Sie den optionalen max_batch_size-Parameter angeben. Dieser Parameter schränkt die maximale Anzahl der in jedem Stapel verarbeiteten input_text-Werte ein. Wenn mehrere Elemente gleichzeitig gesendet werden, reduziert dies die Anzahl der Wiederholungen zwischen Aurora und Amazon Comprehend. Die Begrenzung der Stapelgröße ist in verschiedenen Situationen sinnvoll, etwa bei einer Abfrage mit einer LIMIT-Klausel. Durch die Verwendung eines kleineren Wertes für max_batch_size vermeiden Sie, dass Amazon Comprehend häufiger aufgerufen wird als Eingabetexte vorhanden sind.
Die Batchoptimierung für die Evaluierung von Aurora-Machine-Learning-Funktionen gilt in den folgenden Fällen:
-
Funktionsaufrufe innerhalb der ausgewählten Liste oder der
WHERE-Klausel vonSELECT-Anweisungen. -
Funktionsaufrufe in der
VALUES-Liste vonINSERT- undREPLACE-Anweisungen. -
SageMaker KI-Funktionen in
SETWerten inUPDATEAnweisungen:INSERT INTO MY_TABLE (col1, col2, col3) VALUES (ML_FUNC(1), ML_FUNC(2), ML_FUNC(3)), (ML_FUNC(4), ML_FUNC(5), ML_FUNC(6)); UPDATE MY_TABLE SET col1 = ML_FUNC(col2), SET col3 = ML_FUNC(col4) WHERE ...;
Überwachung von Aurora Machine Learning
Sie können Batchoperationen von Aurora Machine Learning überwachen, indem Sie mehrere globale Variablen abfragen, wie im folgenden Beispiel gezeigt.
show status like 'Aurora_ml%';
Sie können die Statusvariablen mit einer FLUSH STATUS-Anweisung zurücksetzen. So stehen alle Zahlen für Gesamtwerte, Durchschnittswerte usw. seit der letzten Zurücksetzung der Variablen.
Aurora_ml_logical_request_cnt-
Die Anzahl der logischen Anfragen, die die DB-Instance seit dem letzten Status-Reset zum Senden an die Aurora-Machine-Learning-Services ausgewertet hat. Je nachdem, ob Stapelverarbeitung verwendet wurde, kann dieser Wert höher sein als
Aurora_ml_actual_request_cnt. Aurora_ml_logical_response_cnt-
Die aggregierte Zahl der Antworten, die Aurora MySQL von den Machine-Learning-Services von Aurora über alle von Benutzern der DB-Instance durchgeführten Abfragen hinweg erhält.
Aurora_ml_actual_request_cnt-
Die aggregierte Zahl der Anfragen, die Aurora MySQL an die Machine-Learning-Services von Aurora über alle von Benutzern der DB-Instance durchgeführten Abfragen hinweg stellt.
Aurora_ml_actual_response_cnt-
Die aggregierte Zahl der Antworten, die Aurora MySQL von den Machine-Learning-Services von Aurora über alle von Benutzern der DB-Instance durchgeführten Abfragen hinweg erhält.
Aurora_ml_cache_hit_cnt-
Die aggregierte Zahl der internen Cache-Treffer, die Aurora MySQL von den Machine-Learning-Services von Aurora über alle von Benutzern der DB-Instance durchgeführten Abfragen hinweg erhält.
Aurora_ml_retry_request_cnt-
Die Anzahl der wiederholten Anfragen, die die DB-Instance seit dem letzten Status-Reset an die Aurora-Machine-Learning-Services gesendet hat.
Aurora_ml_single_request_cnt-
Die aggregierte Zahl der Machine-Learning-Funktionen von Aurora, die im Nicht-Batch-Modus über alle von Benutzern der DB-Instance durchgeführten Abfragen hinweg evaluiert werden.
Informationen zur Überwachung der Leistung der SageMaker KI-Operationen, die von Aurora-Funktionen für maschinelles Lernen aufgerufen werden, finden Sie unter Amazon SageMaker AI überwachen.
