Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Die Architektur von Aurora PostgreSQL Limitless Database
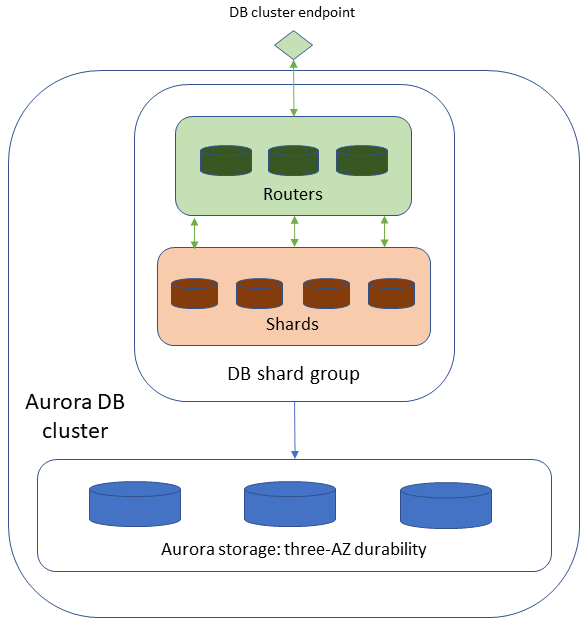
Limitless Database verdankt ihre Skalierbarkeit einer zweischichtigen Architektur, die aus mehreren Datenbankknoten besteht. Knoten sind entweder Router oder Shards.
-
Shards sind DB-Instances von Aurora PostgreSQL, die jeweils eine Teilmenge der Daten für Ihre Datenbank speichern und so eine gleichzeitige Verarbeitung ermöglichen, um einen höheren Schreibdurchsatz zu erzielen.
-
Router verwalten die verteilte Struktur der Datenbank und liefern Datenbank-Clients das Bild einer zentralen Datenbank. Router verwalten Metadaten darüber, wo Daten gespeichert sind, analysieren eingehende SQL-Befehle und senden diese Befehle an Shards. Anschließend aggregieren sie Daten aus Shards, um ein einziges Ergebnis an den Client zurückzugeben, und verwalten verteilte Transaktionen, um für Einheitlichkeit in der gesamten verteilten Datenbank zu sorgen.
Aurora PostgreSQL Limitless Database unterscheidet sich von Aurora-DB-Cluster (Standard) dadurch, dass sie anstelle einer Writer-DB-Instance und von Reader-DB-Instances über eine DB-Shard-Gruppe verfügt. Alle Knoten, aus denen Ihre Limitless-Database-Architektur besteht, sind in der DB-Shard-Gruppe enthalten. Die einzelnen Shards und Router in der DB-Shard-Gruppe sind in Ihrem nicht sichtbar. AWS-Konto Sie verwenden den DB-Cluster-Endpunkt, um auf Limitless Database zuzugreifen.
Die folgende Abbildung zeigt die High-Level-Architektur von Aurora PostgreSQL Limitless Database.
Weitere Informationen zur Architektur von Aurora PostgreSQL Limitless Database und zu deren Verwendung finden Sie in diesem Video auf dem AWS Event-Kanal unter: YouTube
Weitere Informationen zur Architektur eines standardmäßigen Aurora-DB-Clusters finden Sie unter Amazon-Aurora-DB-Cluster.
Wichtige Begriffe zu Aurora PostgreSQL Limitless Database
- DB-Shard-Gruppe
-
Ein Container für Limitless-Database-Knoten (Shards und Router).
- Router
-
Ein Knoten, der SQL-Verbindungen von Clients akzeptiert, SQL-Befehle an Shards sendet, für systemweite Einheitlichkeit sorgt und Ergebnisse an Clients zurückgibt.
- Shard
-
Ein Knoten, der eine Teilmenge von Sharded-Tabellen, vollständige Kopien von Referenztabellen und Standardtabellen speichert. Akzeptiert Abfragen von Routern, kann aber von den Clients nicht direkt kontaktiert werden.
- Sharded-Tabelle
-
Eine Tabelle, deren Daten auf Shards partitioniert sind.
- Shard-Schlüssel
-
Eine Spalte oder eine Gruppe von Spalten in einer Shard-Tabelle, die verwendet werden, um die Partitionierung zwischen Shards zu bestimmen.
- Zusammengefasste Tabellen
-
Zwei Sharded-Tabellen, die denselben Shard-Schlüssel verwenden und explizit als zusammengefasst deklariert sind. Alle Daten für denselben Shard-Schlüsselwert werden an denselben Shard gesendet.
- Referenztabelle
-
Eine Tabelle, deren Daten für jeden Shard vollständig kopiert wurden.
- Standardtabelle
-
Der Standard-Tabellentyp in Limitless Database. Sie können Standardtabellen in Sharded- und Referenztabellen konvertieren.
Alle Standardtabellen werden auf demselben vom System ausgewählten Shard gespeichert, sodass zwischen Standardtabellen innerhalb eines einzigen Shard Verknüpfungen stattfinden können. Standardtabellen sind jedoch durch die maximale Kapazität des Shards (128 TiB) begrenzt. Dieser Shard speichert auch Daten aus Sharded- und Referenztabellen, sodass der effektive Grenzwert für Standardtabellen unter 128 TiB liegt.
Tabellentypen für Aurora PostgreSQL Limitless Database
Aurora PostgreSQL Limitless Database unterstützt drei Tabellentypen: Sharded, Referenz und Standard.
Bei Sharded-Tabellen sind die Daten auf alle Shards in der DB-Shard-Gruppe verteilt. Limitless Database veranlasst dies automatisch mithilfe eines Shard-Schlüssels, bei dem es sich um eine Spalte oder eine Gruppe von Spalten handelt, die Sie bei der Partitionierung der Tabelle festlegen. Alle Daten mit demselben Wert für den Shard-Schlüssel werden an denselben Shard gesendet. Sharding basiert auf Hash, nicht auf Bereichen oder Listen.
Geeignete Anwendungsfälle für Sharded-Tabellen:
-
Die Anwendung arbeitet mit einer bestimmten Teilmenge von Daten.
-
Die Tabelle ist sehr groß.
-
Die Tabelle wächst möglicherweise schneller als andere Tabellen.
Sharded-Tabellen können zusammengefasst werden, was bedeutet, dass sie denselben Shard-Schlüssel verwenden und alle Daten aus beiden Tabellen mit demselben Shard-Schlüsselwert an denselben Shard gesendet werden. Wenn Sie Tabellen zusammenfassen und sie mithilfe des Shard-Schlüssels verknüpfen, kann die Verknüpfung auf einem einzigen Shard ausgeführt werden, da alle erforderlichen Daten auf diesem Shard vorhanden sind.
Für Referenztabellen gibt es eine vollständige Kopie all ihrer Daten auf jedem Shard in der DB-Shard-Gruppe. Referenztabellen werden in der Regel für kleinere Tabellen mit einem geringeren Schreibvolumen verwendet, die aber dennoch häufig verknüpft werden müssen und sich nicht für Sharding eignen. Beispiele für Referenztabellen sind Datumstabellen und Tabellen mit geographischen Daten wie Bundesland, Stadt und Postleitzahl.
Standardtabellen sind der Standardtabellentyp in Aurora PostgreSQL Limitless Database. Es handelt sich bei diesen Tabellen nicht um verteilte Tabellen. Aurora PostgreSQL Limitless Database unterstützt Verknüpfungen zwischen Standardtabellen und Standard-, Sharded- und Referenztabellen.
Fakturierung für Aurora PostgreSQL Limitless Database
Informationen zu den Gebühren für Aurora PostgreSQL Limitless Database finden Sie unter Abrechnung von DB-Instances für Aurora.
Informationen zur Preisgestaltung von Aurora finden Sie in der Aurora-Preisliste
