Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Amazon-Aurora-DB-Cluster
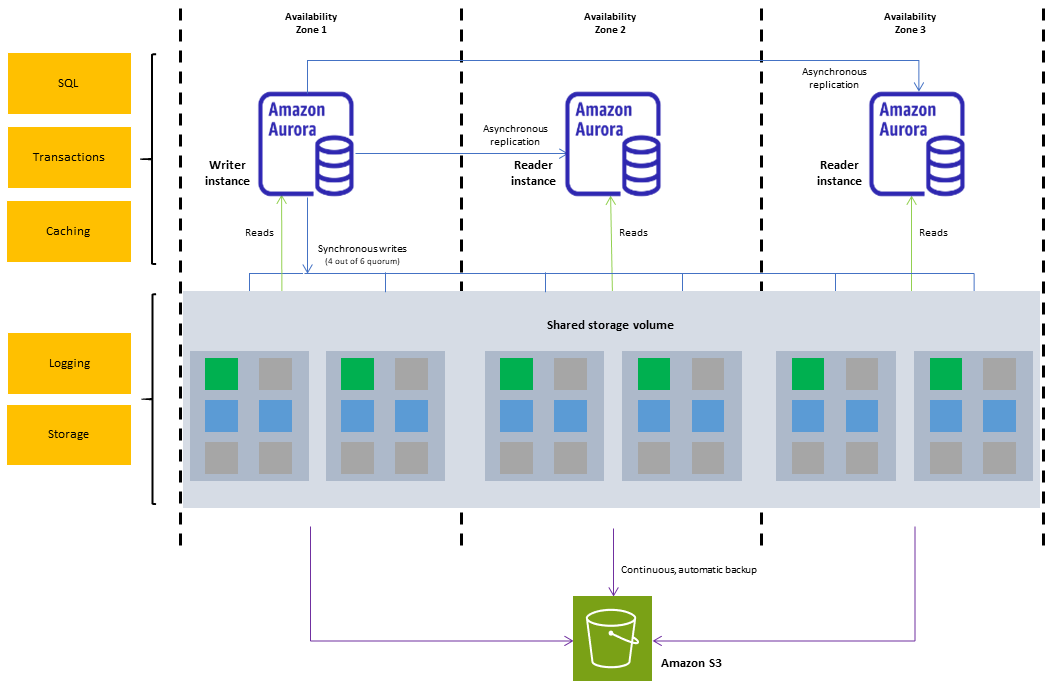
Ein Amazon Aurora-DB-Cluster besteht aus einer oder mehreren DB-Instances und einem Cluster-Volume, das die Daten für diese DB-Instances verwaltet. Ein Aurora-Cluster-Volume ist ein virtuelles Datenbankspeicher-Volume, das sich über mehrere Availability Zones erstreckt, wobei jede Availability Zone über eine Kopie der DB-Cluster-Daten verfügt. Zwei Typen von DB-Instances bilden einen Aurora-DB-Cluster:
-
Primäre (Schreiber-)DB-Instance – Unterstützt Lese- und Schreiboperationen und führt alle Datenänderungen im Cluster-Volume durch. Jeder Aurora-DB-Cluster verfügt über eine primäre DB-Instance.
-
Aurora-Replikat (Leser-DB-Instance) – Stellt eine Verbindung zu demselben Speichervolume wie die primäre DB-Instance her und unterstützt nur Lesevorgänge. Jeder Aurora-DB-Cluster kann zusätzlich zur primären DB-Instance bis zu 15 Aurora-Replicas besitzen. Sorgen Sie für eine hohe Verfügbarkeit, indem Sie die Aurora-Replikate in separaten Availability Zones platzieren. Aurora führt ein automatisches Failover auf ein Aurora-Replikat durch, falls die primäre DB-Instance nicht mehr verfügbar ist. Sie können die Failover-Priorität für Aurora-Replicas festlegen. Aurora-Replicas können auch schreibgeschützte Workloads von der primären DB-Instance auslagern.
Das folgende Diagramm veranschaulicht die Beziehung zwischen dem Cluster-Volume, der Schreiber-DB-Instance und Leser-DB-Instances in einem Aurora-DB-Cluster.
Anmerkung
Die obigen Informationen gelten für alle Aurora-DB-Cluster — bereitgestellte, parallel Abfragen, Aurora Global DatabaseAurora Serverless, Aurora und Aurora MySQL-Compatible. PostgreSQL-Compatible
Der Aurora-DB-Cluster veranschaulicht die Trennung von Rechenkapazität und Speicher. Beispielsweise ist eine Aurora-Konfiguration mit nur einer einzigen DB-Instance immer noch ein Cluster, da das zugrunde liegende Speichervolumen mehrere Speicherknoten umfasst, die auf mehrere Availability Zones (AZs) verteilt sind.
Input/output (I/O) Operationen in Aurora-DB-Clustern werden auf die gleiche Weise gezählt, unabhängig davon, ob sie sich auf einer Writer- oder Reader-DB-Instance befinden. Weitere Informationen finden Sie unter Speicherkonfigurationen für DB-Cluster von Amazon Aurora.
