Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Erstellen eines DB-Clusters von Babelfish for Aurora PostgreSQL
Babelfish for Aurora PostgreSQL wird auf allen unterstützten Aurora PostgreSQL-Versionen 13 und höher unterstützt.
Sie können das AWS Management Console oder das verwenden, AWS CLI um einen Aurora PostgreSQL-Cluster mit Babelfish zu erstellen.
Anmerkung
In einem Aurora-PostgreSQL-Cluster ist der Datenbankname babelfish_db für Babelfish reserviert. Das Erstellen einer eigenen „babelfish_db“-Datenbank auf einem Babelfish für Aurora PostgreSQL verhindert, dass Aurora Babelfish erfolgreich bereitstellt.
Um einen Cluster zu erstellen, in dem Babelfish mit dem läuft AWS Management Console
-
Öffnen Sie die Amazon RDS-Konsole https://console.aws.amazon.com/rds/
unter und wählen Sie Datenbank erstellen. 
-
Für Wählen Sie eine Datenbankerstellungsmethode aus führen Sie einen der folgenden Schritte aus:
-
Um detaillierte Engine-Optionen festzulegen, wählen Sie Standard erstellen aus.
-
Um vorkonfigurierte Optionen zu verwenden, die Best Practices für einen Aurora-Cluster unterstützen, wählen Sie Einfache Erstellung aus.
-
-
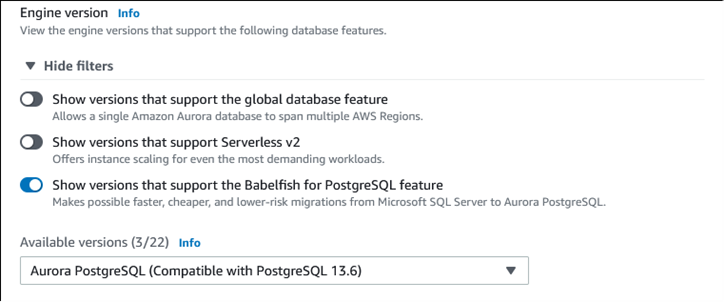
Wählen Sie als Engine-Typ Aurora (PostgreSQL-kompatibel).
-
Für Verfügbare Versionen, wählen Sie eine Aurora-PostgreSQL-Version. Die neuesten Babelfish-Funktionen erhalten Sie, wenn Sie die höchste Aurora-PostgreSQL-Hauptversion auswählen. Babelfish wird auf allen unterstützten Aurora PostgreSQL-Versionen 13 und höher unterstützt.
-
Wählen Sie unter Templates (Vorlagen) die Vorlage für Ihr Anwendungsszenario aus.
-
Für DB-Cluster-ID, geben Sie einen Namen ein, den Sie später in der DB-Clusterliste leicht finden können.
-
Für Master username (Masterbenutzername), geben Sie einen Administratorbenutzernamen ein. Der Standardwert für Aurora PostgreSQL ist
postgres. Sie können den Standardwert akzeptieren oder einen anderen Namen auswählen. Um beispielsweise der Benennungskonvention zu folgen, die in Ihren SQL-Server-Datenbanken verwendet wird, können Siesa(Systemadministrator) als Hauptbenutzername eingeben.Wenn Sie keinen Benutzer mit dem Namen
sazu diesem Zeitpunkt erstellen, können Sie später einen mit Ihrer Wahl des Kunden erstellen. Verwenden Sie nach dem Erstellen des Benutzers den BefehlALTER SERVER ROLE, um ihn dersysadmin-Gruppe (Rolle) für den Cluster hinzuzufügen.Warnung
Der Master-Benutzername muss immer Kleinbuchstaben verwenden, andernfalls kann der DB-Cluster keine Verbindung zu Babelfish über den TDS-Port herstellen.
-
Erstellen Sie für Master password (Hauptpasswort) ein sicheres Passwort und bestätigen Sie es.
-
Für die folgenden Optionen bis zum Abschnitt Babelfish Einstellungen, geben Sie Ihre DB-Cluster-Einstellungen an. Weitere Informationen zu den einzelnen Einstellungen finden Sie unter Einstellungen für Aurora-DB-Cluster.
-
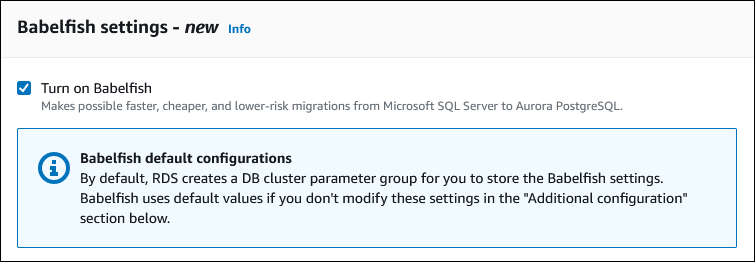
Um die Babelfish-Funktionalität verfügbar zu machen, wählen Sie Aktivieren Sie Babelfish aus.
-
Für DB-Cluster-Parametergruppe führen Sie einen der folgenden Schritte aus:
-
Klicken Sie auf Neue erstellen, um eine neue Parametergruppe zu erstellen, bei der Babelfish aktiviert ist.
-
Klicken Sie auf Wählen Sie existierende, um eine vorhandene Parametergruppe zu verwenden. Wenn Sie eine vorhandene Gruppe verwenden, müssen Sie die Gruppe ändern, bevor Sie den Cluster erstellen, und fügen Sie Werte für Babelfish-Parameter hinzu. Informationen zum Festlegen von Parametern finden Sie unter Einstellungen der DB-Cluster-Parametergruppe für Babelfish.
Wenn Sie eine vorhandene Gruppe verwenden, geben Sie den Gruppennamen in das folgende Feld ein.
-
-
Wählen Sie für Migration Mode eine der nachstehenden Optionen aus:
-
Einzelne Datenbank, um eine einzelne SQL Server-Datenbank zu migrieren.
In einigen Fällen können Sie mehrere Benutzerdatenbanken zusammen migrieren, wobei Ihr Endziel eine vollständige Migration zur nativen Aurora PostgreSQL ohne Babelfish ist. Wenn die endgültigen Anträge konsolidierte Schemas erfordern (ein einziges
dbo-Schema), stellen Sie sicher, dass Sie Ihre SQL Server-Datenbanken zuerst in einer einzigen SQL-Server-Datenbank konsolidieren. Migrieren Sie dann zu Babelfish mit dem Einzelne Datenbank-Modus. -
Mehrere Datenbanken, um mehrere SQL Server-Datenbanken zu migrieren (die aus einer einzigen SQL Server-Installation stammen). Der Mehrfachdatenbankmodus konsolidiert nicht mehrere Datenbanken, die nicht von einer einzigen SQL Server-Installation stammen. Weitere Informationen zum Migrieren mehrerer Datenbanken finden Sie unter Verwenden von Babelfish mit einer einzigen Datenbank oder mehreren Datenbanken.
Anmerkung
Ab Aurora-PostgreSQL-Version 16 ist die Option Mehrere Datenbanken standardmäßig als Datenbankmigrationsmodus ausgewählt.

-
-
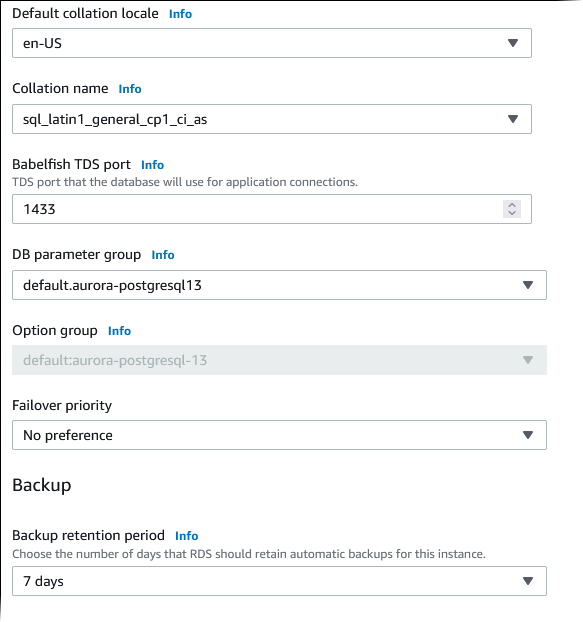
Für Standardmäßige Sortierreihenfolgen geben Sie das Gebietsschema des Servers ein. Der Standardwert ist
en-US. Ausführliche Informationen zu Aliassen finden Sie unter Verstehen der Kollationen in Babelfish für Aurora PostgreSQL. -
Für Name der Sortierung, geben Sie Ihre Standardsortierung ein. Der Standardwert ist
sql_latin1_general_cp1_ci_as. Weitere Informationen hierzu finden Sie unter Verstehen der Kollationen in Babelfish für Aurora PostgreSQL. -
Für DB-Parametergruppe wählen Sie eine Parametergruppe aus oder lassen Sie Aurora eine neue Gruppe mit Standardeinstellungen erstellen.
-
Für Failover priority (Failover-Priorität) wählen Sie eine Failover-Priorität für die Instance aus. Wenn Sie keinen Wert auswählen, wird als Standard
tier-1gesetzt. Diese Priorität bestimmt die Reihenfolge, in der -Replicas bei der Wiederherstellung nach einem Ausfall der primären Instance hochgestuft werden. Weitere Informationen finden Sie unter Fehlertoleranz für einen Aurora-DB-Cluster. -
Wählen Sie für Aufbewahrungszeitraum für Backups die Dauer (1–35 Tage) aus, die Aurora Backup-Kopien der Datenbank aufbewahrt. Sie können Sicherungskopien für sekundengenaue Point-in-Time-Wiederherstellungen (PITR) der Datenbank verwenden. Der Standardaufbewahrungszeitraum beträgt sieben Tage.
-
Wählen Sie Tags zu Snapshots kopieren, wenn beim Erstellen eines Snapshots DB-Instance-Tags in den DB-Snapshot kopiert werden sollen.
Anmerkung
Wenn Sie einen DB-Cluster aus einem Snapshot wiederherstellen, wird er nicht als DB-Cluster von Babelfish für Aurora PostgreSQL wiederhergestellt. Sie müssen die Parameter, die die Babelfish-Einstellungen steuern, in der DB-Cluster-Parametergruppe aktivieren, um Babelfish wieder zu aktivieren. Weitere Informationen zu diesen Babelfish-Parametern finden Sie unter Einstellungen der DB-Cluster-Parametergruppe für Babelfish.
-
Klicken Sie auf Enable encryption (Verschlüsselung aktivieren), um die Verschlüsselung im Ruhezustand (Aurora-Speicherverschlüsselung) für diesen DB-Cluster einzuschalten.
-
Klicken Sie auf Enable Performance Insights (Performance Insights aktivieren), um Amazon RDS Performance Insights zu aktivieren.
-
Wählen Sie Enable enhanced monitoring (Erweiterte Überwachung aktivieren) aus, um die Erfassung von Metriken in Echtzeit für das Betriebssystem zu aktivieren, in dem Ihr DB-Cluster ausgeführt wird.
-
Wählen Sie PostgreSQL-Protokoll, um die Protokolldateien in Amazon CloudWatch Logs zu veröffentlichen.
-
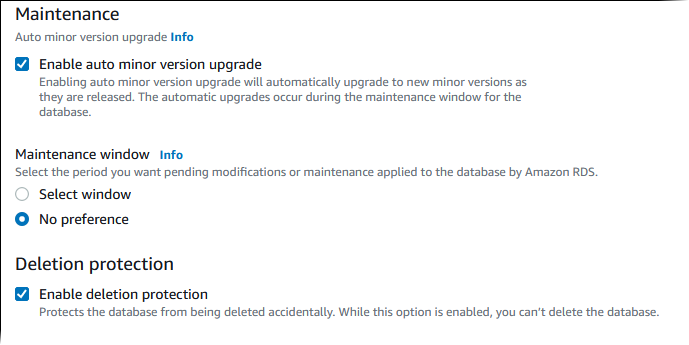
Klicken Sie auf Automatischer Unterversion-Upgrade aktivieren, um Ihren Aurora-DB-Cluster automatisch zu aktualisieren, wenn ein Minor-Versions-Upgrade verfügbar ist.
-
Für Maintenance window (Wartungsfenster) gehen Sie wie folgt vor:
-
Um einen Zeitpunkt auszuwählen, an dem Amazon RDS Änderungen vornehmen oder Wartungsarbeiten durchführen kann, wählen Sie Fenster wählen aus.
-
Um die Amazon-RDS-Wartung zu einem ungeplanten Zeitpunkt durchzuführen, wählen Sie Keine Präferenz aus.
-
-
Wählen Sie Enable deletion protection (Löschschutz aktivieren), um Ihre Datenbank vor versehentlichem Löschen zu schützen.
Wenn Sie diese Funktion aktivieren, können Sie die Datenbank nicht direkt löschen. Stattdessen müssen Sie den Datenbankcluster ändern und diese Funktion deaktivieren, bevor Sie die Datenbank löschen.
-
Wählen Sie Datenbank erstellen aus.
Ihre neue Datenbank für Babelfish finden Sie in der Auflistung Datenbanken. Die Spalte Status zeigt Verfügbar an, wenn die Bereitstellung abgeschlossen ist.
Wenn Sie einen Babelfish für Aurora PostgreSQL erstellen AWS CLI, müssen Sie dem Befehl den Namen der DB-Cluster-Parametergruppe übergeben, die für den Cluster verwendet werden soll. Weitere Informationen finden Sie unter Voraussetzungen für DB-Cluster.
Bevor Sie den verwenden können AWS CLI , um einen Aurora PostgreSQL-Cluster mit Babelfish zu erstellen, gehen Sie wie folgt vor:
-
Wählen Sie Ihre Endpunkt-URL aus der Liste der Services unter Amazon Aurora Aurora-Endpunkte und -Kontingente aus.
-
Erstellen einer Parametergruppe für das Cluster. Weitere Informationen zu Parametergruppen finden Sie unter Parametergruppen für Amazon Aurora.
-
Ändern Sie die Parametergruppe und fügen Sie den Parameter hinzu, der Babelfish aktiviert.
Um einen Aurora PostgreSQL-DB-Cluster mit Babelfish zu erstellen, verwenden Sie den AWS CLI
Die folgenden Beispiele verwenden den standardmäßigen Hauptbenutzernamen, postgres. Ersetzen Sie den Namen nach Bedarf durch den Benutzernamen, den Sie für Ihren DB-Cluster erstellt haben, z. B. sa bzw. den Benutzernamen, den Sie anstelle des Standardwerts ausgewählt haben.
-
Erstellen Sie eine Parametergruppe.
Für Linux, macOS oder Unix:
aws rds create-db-cluster-parameter-group \ --endpoint-urlendpoint-url\ --db-cluster-parameter-group-nameparameter-group\ --db-parameter-group-familyaurora-postgresql14\ --description"description"Für Windows:
aws rds create-db-cluster-parameter-group ^ --endpoint-urlendpoint-URL^ --db-cluster-parameter-group-nameparameter-group^ --db-parameter-group-familyaurora-postgresql14^ --description"description" -
Ändern Sie Ihre Parametergruppe, um Babelfish zu aktivieren.
Für Linux, macOS oder Unix:
aws rds modify-db-cluster-parameter-group \ --endpoint-urlendpoint-url\ --db-cluster-parameter-group-nameparameter-group\ --parameters "ParameterName=rds.babelfish_status,ParameterValue=on,ApplyMethod=pending-reboot"Für Windows:
aws rds modify-db-cluster-parameter-group ^ --endpoint-urlendpoint-url^ --db-cluster-parameter-group-nameparamater-group^ --parameters "ParameterName=rds.babelfish_status,ParameterValue=on,ApplyMethod=pending-reboot" -
Geben Sie die DB-Subnetzgruppen- und VPC-Sicherheitsgruppen-ID für Ihr neues DB-Cluster an und rufen Sie dann den -Befehl create-db-cluster auf.
Für Linux, macOS oder Unix:
aws rds create-db-cluster \ --db-cluster-identifiercluster-name\ --master-usernamepostgres\ --manage-master-user-password \ --engine aurora-postgresql \ --engine-version14.3\ --vpc-security-group-idssecurity-group\ --db-subnet-group-namesubnet-group-name\ --db-cluster-parameter-group-nameparameter-groupFür Windows:
aws rds create-db-cluster ^ --db-cluster-identifiercluster-name^ --master-usernamepostgres^ --manage-master-user-password ^ --engine aurora-postgresql ^ --engine-version14.3^ --vpc-security-group-idssecurity-group^ --db-subnet-group-namesubnet-group^ --db-cluster-parameter-group-nameparameter-groupIn diesem Beispiel wird die Option
--manage-master-user-passwordzum Generieren des Hauptbenutzerpassworts und zum Verwalten dieses Passworts in Secrets Manager angegeben. Weitere Informationen finden Sie unter Passwortverwaltung mit Amazon Aurora und AWS Secrets Manager. Alternativ können Sie die Option--master-passwordverwenden, um das Passwort selbst festzulegen und zu verwalten. -
Erstellen Sie die primäre Instance für Ihren DB-Cluster explizit. Verwenden Sie den Namen des Clusters, den Sie in Schritt 3 erstellt haben, für das Argument
--db-cluster-identifierbeim Aufrufen des Befehls create-db-instance, wie nachfolgend dargestellt.Für Linux, macOS oder Unix:
aws rds create-db-instance \ --db-instance-identifierinstance-name\ --db-instance-classdb.r6g\ --db-subnet-group-namesubnet-group\ --db-cluster-identifiercluster-name\ --engine aurora-postgresqlFür Windows:
aws rds create-db-instance ^ --db-instance-identifierinstance-name^ --db-instance-classdb.r6g^ --db-subnet-group-namesubnet-group^ --db-cluster-identifiercluster-name^ --engine aurora-postgresql
