Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
ElastiCache Terminologie
Im Oktober 2016 ElastiCache hat Amazon die Unterstützung für Redis OSS 3.2 eingeführt. Zu diesem Zeitpunkt haben wir Unterstützung für die Partitionierung Ihrer Daten auf bis zu 500 Shards (in der ElastiCache API als Knotengruppen bezeichnet) hinzugefügt. AWS CLI Um die Kompatibilität mit früheren Versionen zu gewährleisten, haben wir den Betrieb der API-Version 2015-02-02 um die neue Redis OSS-Funktionalität erweitert.
Gleichzeitig haben wir begonnen, in der ElastiCache Konsole eine Terminologie zu verwenden, die in dieser neuen Funktion verwendet wird und in der gesamten Branche üblich ist. Durch diese Änderung kann es stellenweise dazu kommen, dass sich die in der API und der CLI verwendete Terminologie von der in der Konsole verwendeten unterscheidet. Die folgende Liste enthält Begriffe, die sich zwischen API, CLI und der Konsole unterscheiden können.
- Cache-Cluster oder Knoten vs. Knoten
-
Es besteht eine Eins-zu-Eins-Beziehung zwischen einem Knoten und einem Cluster, wenn es keine Replikatknoten gibt. Daher wurden die Begriffe in der ElastiCache Konsole häufig synonym verwendet. Die Konsole verwendet jetzt durchgängig den Begriff Knoten. Einzige Ausnahme ist die Schaltfläche Create Cluster, über die der Prozess zur Erstellung eines Clusters mit oder ohne Replikationsknoten gestartet wird.
Die ElastiCache API und AWS CLI ich verwenden die Begriffe weiterhin wie in der Vergangenheit.
- Cluster im Vergleich zu Valkey oder Redis OSS-Replikationsgruppe
-
Die Konsole verwendet jetzt den Begriff Cluster for all ElastiCache für Redis OSS-Cluster. Die Konsole verwendet den Begriff "Cluster" in den folgenden Fällen:
Wenn es sich bei dem Cluster um einen Valkey- oder Redis OSS-Cluster mit einem Knoten handelt.
Wenn es sich bei dem Cluster um einen Valkey- oder Redis OSS-Cluster (Clustermodus deaktiviert) handelt, der die Replikation innerhalb eines einzelnen Shards unterstützt (in der API und CLI, als Knotengruppe bezeichnet).
Wenn es sich bei dem Cluster um einen Valkey- oder Redis OSS-Cluster (Clustermodus aktiviert) handelt, der die Replikation innerhalb von 1—90 Shards oder bis zu 500 Shards mit einer Anforderung zur Erhöhung des Limits unterstützt. Um eine Erhöhung des Limits zu beantragen, siehe AWS -Service-Limits nach und wählen Sie den Limittyp Knoten pro Cluster pro Instance-Typ.
Weitere Informationen zu Valkey- oder Redis OSS-Replikationsgruppen finden Sie unter. Hohe Verfügbarkeit mit Replikationsgruppen
Das folgende Diagramm veranschaulicht die verschiedenen Topologien von ElastiCache Redis OSS-Clustern aus Sicht der Konsole.
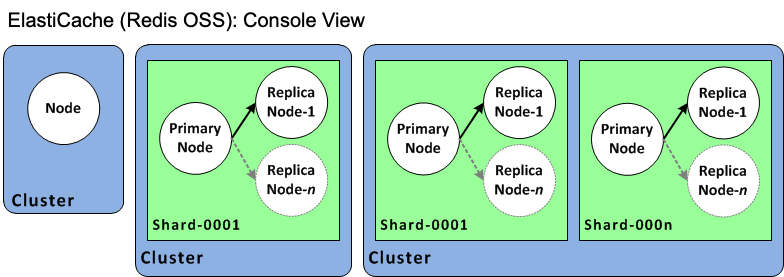
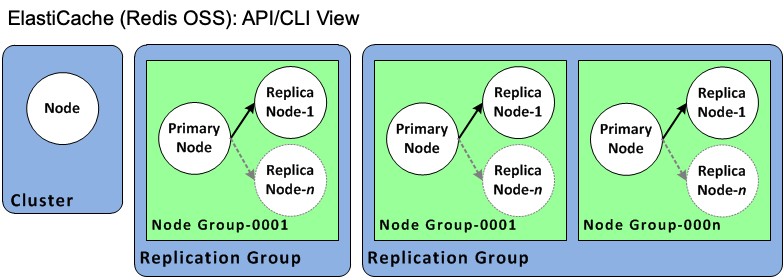
Die ElastiCache API und die AWS CLI Operationen unterscheiden immer noch zwischen einzelnen Knoten ElastiCache für Redis OSS-Cluster und Valkey- oder Redis OSS-Replikationsgruppen mit mehreren Knoten. Das folgende Diagramm veranschaulicht die verschiedenen OSS-Topologien ElastiCache für Redis aus der API und der Perspektive. ElastiCache AWS CLI
- Valkey- oder Redis OSS-Replikationsgruppe im Vergleich zu globalem Datenspeicher
Ein globaler Datenspeicher ist eine Sammlung von einem oder mehreren Clustern, die sich regionsübergreifend aufeinander replizieren, wohingegen eine Valkey- oder Redis-OSS-Replikationsgruppe Daten über einen Cluster mit aktiviertem Clustermodus mit mehreren Shards repliziert. Ein globaler Datenspeicher besteht aus folgenden Komponenten:
-
Primärer (aktiver) Cluster – Ein primärer Cluster nimmt Schreibvorgänge entgegen, die auf alle Cluster innerhalb des globalen Datenspeichers repliziert werden. Ein primärer Cluster akzeptiert auch Leseanfragen.
-
Sekundärer (passiver) Cluster – Ein sekundärer Cluster nimmt nur Leseanforderungen entgegen und repliziert Datenaktualisierungen von einem primären Cluster. Ein sekundärer Cluster muss sich in einer anderen AWS Region befinden als der primäre Cluster.
Informationen zu globalen Datenspeichern finden Sie unter Replikation zwischen AWS Regionen, die globale Datenspeicher verwenden.
-
