Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Replikation zwischen AWS Regionen, die globale Datenspeicher verwenden
Anmerkung
Global Datastore ist derzeit nur für knotenbasierte Cluster verfügbar.
Mithilfe der Global Datastore-Funktion können Sie mit einer vollständig verwalteten, schnellen, zuverlässigen und sicheren Valkey- oder Redis OSS-Clusterreplikation über Regionen hinweg arbeiten. AWS Mit dieser Funktion können Sie regionsübergreifende Read Replica-Cluster erstellen, um Lesevorgänge mit geringer Latenz und regionsübergreifende Disaster Recovery zu ermöglichen. AWS
In den folgenden Abschnitten finden Sie eine Beschreibung der Arbeit mit globalen Datenspeichern.
Themen
-Übersicht
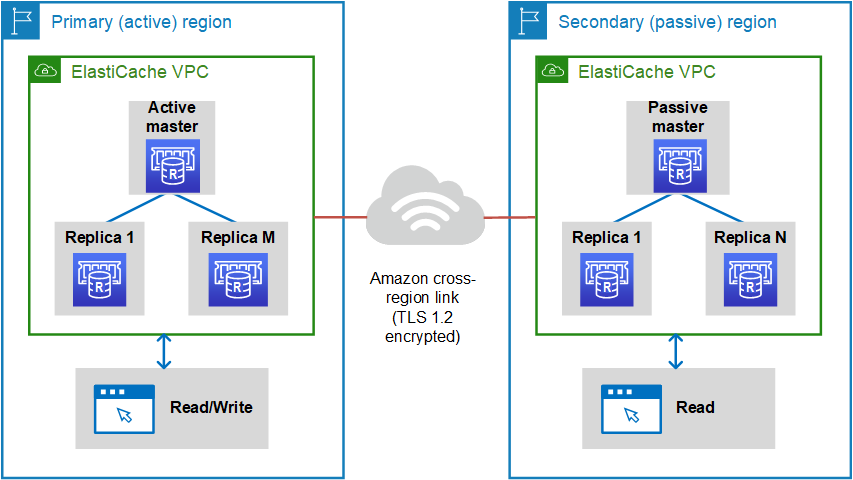
Jeder globale Datenspeicher ist eine Sammlung von einem oder mehreren Clustern, die zueinander repliziert werden.
Ein globaler Datenspeicher besteht aus folgenden Komponenten:
-
Primärer (aktiver) Cluster – Ein primärer Cluster nimmt Schreibvorgänge entgegen, die auf alle Cluster innerhalb des globalen Datenspeichers repliziert werden. Ein primärer Cluster akzeptiert auch Leseanfragen.
-
Sekundärer (passiver) Cluster – Ein sekundärer Cluster nimmt nur Leseanforderungen entgegen und repliziert Datenaktualisierungen von einem primären Cluster. Ein sekundärer Cluster muss sich in einer anderen AWS Region befinden als der primäre Cluster.
Wenn Sie einen globalen Datenspeicher ElastiCache für Valkey oder Redis OSS erstellen, repliziert dieser Ihre Daten automatisch vom primären Cluster auf den sekundären Cluster. Sie wählen die AWS Region aus, in der die Valkey- oder Redis OSS-Daten repliziert werden sollen, und erstellen dann einen sekundären Cluster in dieser Region. AWS ElastiCache richtet dann die automatische, asynchrone Replikation von Daten zwischen den beiden Clustern ein und verwaltet sie.
Die Verwendung eines globalen Datenspeichers für Valkey oder Redis OSS bietet die folgenden Vorteile:
-
Geolokale Leistung — Indem Sie Remote-Replikat-Cluster in zusätzlichen AWS Regionen einrichten und Ihre Daten zwischen diesen Regionen synchronisieren, können Sie die Latenz beim Datenzugriff in dieser Region reduzieren. AWS Ein globaler Datenspeicher kann dazu beitragen, die Reaktionsfähigkeit Ihrer Anwendung zu erhöhen, indem er geolokale Lesevorgänge mit niedriger Latenz in allen Regionen bereitstellt. AWS
-
Notfallwiederherstellung – Wenn Ihr primärer Cluster in einem globalen Datenspeicher eine Verschlechterung aufweist, können Sie einen sekundären Cluster als Ihren neuen primären Cluster heraufstufen. Sie können dies tun, indem Sie eine Verbindung zu einer beliebigen Region herstellen, die einen sekundären Cluster enthält AWS .
Das folgende Diagramm zeigt, wie globale Datenspeicher funktionieren können.