# 串流資料解決方案:範例
## 情境 1:基於位置的網際網路服務
公司 *InternetProvider* 為世界各地的使用者提供各種頻寬選項的網際網路服務。當使用者註冊網際網路時,公司 *InternetProvider* 會根據使用者的地理位置,為其提供不同的頻寬選項。鑑於這些要求,公司 *InternetProvider* 實作了 Amazon Kinesis Data Streams,來使用使用者詳細資訊和位置。在重新向應用程式發佈之前,會使用不同的頻寬選項來擴充使用者詳細資訊和位置。[AWS Lambda](https://aws.amazon.com/lambda/) 實現了這種即時擴充。
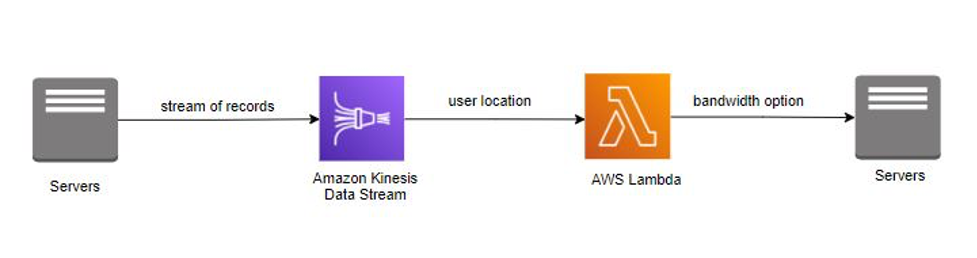
*使用 AWS Lambda 處理資料串流*
### Amazon Kinesis Data Streams
[Amazon Kinesis Data Streams](https://aws.amazon.com/kinesis/data-streams/) 可讓您使用常用的串流處理架構,建置自訂且即時的應用程式,並將串流資料載入至許多不同的資料存放區。Kinesis 串流可以設定為持續接收來自數十萬個資料生產者的事件,這些資料生產者的來源包括如網站點擊流、IoT 感應器、社交媒體摘要和應用程式日誌等。可在毫秒內將資料供您的應用程式讀取和處理使用。
使用 Kinesis Data Streams 實作解決方案時,您可以建立名為 Kinesis Data Streams 應用程式的自訂資料處理應用程式。典型的 Kinesis Data Streams 應用程式會從 Kinesis 串流中讀取資料作為資料記錄。
確保在 Kinesis Data Streams 投入的資料具有高可用性和彈性,並且可在毫秒內提供使用。您可以從數十萬個來源持續將點擊流、應用程式日誌和社交媒體等各種資料類型新增到 Kinesis 串流。[Kinesis 應用程式](https://www.amazonaws.cn/en/kinesis/data-streams/faqs/#kinesisapp)在幾秒鐘內就可以從串流讀取和處理資料。
Amazon Kinesis Data Streams 是一項全受管的串流資料服務。其可管理在資料輸送量層級串流資料所需的基礎設施、儲存、聯網和組態。
#### 將資料傳送至 Amazon Kinesis Data Streams
有多種方法可以將資料傳送到 Kinesis Data Streams,從而為解決方案設計提供靈活性。
+ 您可以使用多種常用語言支援的 [AWS SDK](https://aws.amazon.com/tools/) 之一編寫程式碼。
+ 您可以使用 [Amazon Kinesis 代理程式](https://docs.aws.amazon.com/streams/latest/dev/writing-with-agents.html),這是一種將資料傳送到 Kinesis Data Streams 的工具。
[Amazon Kinesis Producer Library](https://docs.aws.amazon.com/streams/latest/dev/developing-producers-with-kpl.html) (KPL) 簡化了生產者應用程式的開發,方法是讓開發人員對一或多個 Kinesis Data Streams 實現高寫入輸送量。
KPL 是一個您可在主機上安裝的易於使用、高度可設定的程式庫。此程式庫在您的生產者應用程式程式碼與 Kinesis Streams API 動作之間擔任媒介。如需 KPL 及其使用程式碼範例同步和異步產生事件之能力的詳細資訊,請參閲[使用 KPL 寫入 Kinesis Data Streams](https://docs.aws.amazon.com/streams/latest/dev/kinesis-kpl-writing.html)
在 Kinesis Data Streams API 中有兩種不同的操作可將資料新增到串流:`PutRecords` 和 `PutRecord`。`PutRecords` 操作會為每個 HTTP 請求,將多個記錄傳送到串流,同時,`PutRecord` 會為每個 HTTP 請求提交一條記錄。若要為大多數應用程式實現更高的輸送量,請使用 `PutRecords`。
如需這些 API 的詳細資訊,請參閲[向串流新增資料](https://docs.aws.amazon.com/streams/latest/dev/developing-producers-with-sdk.html#kinesis-using-sdk-java-add-data-to-stream)。每個 API 操作的詳細資訊都可以在 [Amazon Kinesis Data Streams API 參考](https://docs.aws.amazon.com/kinesis/latest/APIReference/Welcome.html)中找到。
#### 在 Amazon Kinesis Data Streams 中處理資料
若要讀取和處理 Kinesis 串流中的資料,您需要建立消費者應用程式。有多種方法可以為 Kinesis Data Streams 建立消費者。其中一些方法包括使用 [Amazon Kinesis Data Analytics](https://aws.amazon.com/kinesis/data-analytics/),來使用 KCL 分析串流資料、使用 [AWS Lambda](https://aws.amazon.com/lambda/)、[AWS Glue 串流 ETL 任務](https://docs.aws.amazon.com/glue/latest/dg/add-job-streaming.html),以及直接使用 Kinesis Data Streams API。
您可以使用 KCL 來開發 Kinesis Data Streams 的消費者應用程式,這有助於您使用和處理 Kinesis Data Streams 中的資料。KCL 將處理諸多與分散式運算相關聯的複雜任務,例如跨多個執行個體進行負載平衡、因應執行個體故障、對已處理的記錄執行檢查點作業,以及對重新分片做出反應。KCL 讓您能夠專注於記錄處理邏輯的編寫。如需如何建置自己的 KCL 應用程式的詳細資訊,請參閲[使用 Kinesis Client Library](https://docs.aws.amazon.com/streams/latest/dev/shared-throughput-kcl-consumers.html)。
您可以訂閲 Lambda 函數,來自動讀取 Kinesis 串流中的批次記錄,並在串流中偵測到記錄時處理這些記錄。AWS Lambda 會定期輪詢串流 (每秒一次) 是否有新記錄,當其偵測到新記錄時,則會叫用 Lambda 函數,將新記錄作為參數傳遞。Lambda 函數僅在偵測到新記錄時執行。您可以將 Lambda 函數映射到共用輸送量消費者 (標準反覆運算器)
當您需要專用輸送量,而不希望與從串流接收資料的其他消費者競爭時,您可以建置消費者,其會使用名為[增強散發](https://docs.aws.amazon.com/streams/latest/dev/enhanced-consumers.html)功能。藉助這項功能,消費者從串流接收的記錄可高達每個碎片每秒 2 MB 的資料輸送量。
在大多數情況下,應使用 Kinesis Data Analytics、KCL、AWS Glue 或 AWS Lambda 來處理串流中的資料。但是,如果您願意,您可以使用 Kinesis Data Streams API,從頭開始建立消費者應用程式。Kinesis Data Streams API 提供從串流中擷取資料的 `GetShardIterator` 和 `GetRecords` 方法。
在此提取模型中,程式碼會直接從串流的碎片中擷取資料。有關使用 API 編寫您自己的消費者應用程式的更多資訊,請參閲[使用適用於 Java 的 AWS SDK 開發具有共用輸送量的自訂消費者](https://docs.aws.amazon.com/streams/latest/dev/developing-consumers-with-sdk.html)。API 的詳細資訊可在 [Amazon Kinesis Data Streams API 參考](https://docs.aws.amazon.com/kinesis/latest/APIReference/Welcome.html)中找到。
### 使用 AWS Lambda 處理資料串流
[AWS Lambda](https://aws.amazon.com/lambda/faqs/) 可讓您執行程式碼,不必佈建或管理伺服器。使用 Lambda 時,您可以執行幾乎任何類型的應用程式或後端服務,無需任何管理。只需上傳程式碼,Lambda 會依照所需執行一切資料,並擴展程式碼以具備高可用性。您可以將自己的程式碼設成可以從其他 AWS 服務自動觸發,或從任何 Web 或行動應用程式直接呼叫。
AWS Lambda 可與 Amazon Kinesis Data Streams 原生整合。當您使用此原生整合時,輪詢、檢查點和錯誤處理複雜性就變得抽象化了。這允許 Lambda 函數程式碼專注於商業邏輯的處理。
您可以將 Lambda 函數映射至共用輸送量 (標準反覆運算器),或映射至具有增強散發功能的專用輸送量消費者。對於標準反覆運算器,Lambda 會使用 HTTP 通訊協定,輪詢 Kinesis 串流中的每個碎片以尋找記錄。若要將延遲降至最低並最大化讀取輸送量,您可以建立具有增強散發功能的資料串流消費者。此架構中的串流消費者可以獲得與每個碎片的專用連接,而無需與從同一串流讀取的其他應用程式競爭。Amazon Kinesis Data Streams 透過 HTTP/2 將記錄推送到 Lambda。
根據預設,當串流中有記錄可用時,AWS Lambda 就會叫用函數。要緩衝批次處理記錄的情境,您可以在事件來源處實作最多五分鐘的批次時段。如果您的函數傳回錯誤,Lambda 會不斷重試批次處理,直到處理成功或資料過期。
### 總結
公司 *InternetProvider* 利用 Amazon Kinesis Data Streams,來串流使用者的詳細資訊和位置。AWS Lambda 會使用記錄串流,透過存放在函數庫中的頻寬選項來擴充資料。擴充後,AWS Lambda 將頻寬選項重新發佈至應用程式。Amazon Kinesis Data Streams 和 AWS Lambda 處理伺服器的佈建和管理,使公司 *InternetProvider* 能夠更加專注於業務應用程式的開發。