Amazon Redshift 將不再支援在 2026 年 6 月 30 日之後使用 Python UDFs。我們將開始分階段強制執行。如需 Python 生命週期結束和遷移選項的詳細資訊,請參閱 2025 年 6 月 30 日發佈的部落格文章
本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
Amazon Redshift Serverless 的運算容量
Amazon Redshift Serverless 運算容量會自動擴展和縮減,以符合您的工作負載需求。運算容量是指分配給 Amazon Redshift Serverless 工作負載的處理能力和記憶體。常見的使用案例包括處理高峰流量期間、執行複雜的分析,或有效率地處理大量資料。下列術語提供 Amazon Redshift 如何管理運算容量的詳細資訊。
RPU
Amazon Redshift Serverless 會以 Redshift 處理單元 (RPU) 為單位來測量資料倉儲的容量。RPU 是用來處理工作負載的資源。一個 RPU 可提供 16 GB 的記憶體。
基本容量
此設定會指定 Amazon Redshift 用來為查詢提供服務的基本資料倉儲容量。基本容量會以 RPU 為單位來指定。您能以 Redshift 處理單元 (RPU) 為單位來設定基本容量。設定較高的基本容量可改善查詢效能,對於需要大量資源的資料處理任務來說更是如此。Amazon Redshift Serverless 的預設基本容量為 128 個 RPU。您可以將基本容量設定從 4 個 RPU 調整為 512 個 RPU。您可以將此值設定為 4 個 RPU,或以 8 為單位設定為等於或大於 8 個 RPU (8、16、24...512)。您可以使用 AWS 主控台、UpdateWorkgroupAPI 操作或 中的 update-workgroup操作來設定此值 AWS CLI。
最小基本容量為 4 個 RPU 時,您可以根據資料倉儲需求和效能需求,彈性地執行較簡單到較複雜的工作負載。4 個基本 RPU 容量的目標是包含的資料少於 32TB 的倉儲,而 8、16 和 24 個 RPU 基本 RPU 容量的目標是需要的資料少於 128TB 的工作負載。如果您的資料需求大於 128 TB,則至少須使用 32 個基本 RPU。此外,如果工作負載的資料表有大量的欄且並行數量較高,建議您使用 32 個以上的基本 RPU。
可用的基本 RPU 上限為 1024 個,此值會將最高層級的運算資源新增至您的工作負載。這樣就可提供更大的彈性來支援高度複雜的工作負載,並加速載入和查詢資料。
注意
擴充的基礎 RPU 容量上限為 1024,可在下列內容中使用 AWS 區域。在其他區域中,基本容量上限為 512 個 RPU。
美國東部 (維吉尼亞北部)
美國東部 (俄亥俄)
-
美國西部 (奧勒岡)
-
歐洲 (愛爾蘭)
-
歐洲 (法蘭克福)
設定 512 到 1024 個之間的基本容量時,可採用 32 為單位增量或減量 RPU。
如果您管理更大且更複雜的工作負載,請考慮增加 Redshift Serverless 資料倉儲的大小。倉儲越大,能夠存取的運算資源越多,如此就能更有效率地處理查詢。
以下是設定較高基本容量較為有利的一些範例:
您的查詢較複雜,執行時間較長
您的資料表擁有大量的欄。
您的查詢有大量 JOIN。
您的查詢會彙總或掃描外部來源 (例如資料湖) 的大量資料。
如需 Amazon Redshift Serverless 配額和限制的詳細資訊,請前往 Amazon Redshift Serverless 物件的配額。
Amazon Redshift Serverless 容量的考量和限制
以下是 Amazon Redshift Serverless 容量的考量和限制。如需一般 Redshift Serverless 考量事項,請參閱 使用 Amazon Redshift Serverless 時的考量。
-
4 個基本 RPU 的組態最多可支援 32 TB 的受管儲存容量。如果您要使用超過 32 TB 的受管儲存,則無法將基本 RPU 設定為少於 8 個 RPU。
-
8 個或 16 個基本 RPU 的組態最多可支援 128 TB 的 Redshift 受管儲存容量。如果您要使用超過 128 TB 的受管儲存,則無法將基本設定為少於 32 個 RPU。
-
編輯工作群組的基本容量,如此可能會取消工作群組上執行的某些查詢。
Redshift Serverless 使用以下增量擴展資料倉儲的 RPU:
4 到 8 個 RPU:以 4 個 RPU 為單位增加。
8 到 512 個 RPU:以 8 個 RPU 為單位增加。
512 到 1024 個 RPU:以 32 個 RPU 為單位增加。
-
只有 8 個以上的 RPU 才支援清空提升。對於 8 個以下的 RPU,請改用下列命令:
VACUUM [FULL | SORT ONLY | DELETE ONLY | REINDEX | RECLUSTER] [table_name] [TO threshold PERCENT]
具有 4 個 Redshift 處理單元 (RPU) 容量的 Redshift Serverless
具有 4 個基本 RPU 容量的 Redshift Serverless 適合較小或需求較低的工作負載。此起點提供既靈活又符合成本效益的解決方案。此入門層級組態支援最多擁有下列資源數的資料倉儲:
最多 32 TB 的 Redshift 受管儲存。
每個資料表最多 100 個欄
64 GB 記憶體
如果您的需求超過上述限制,則必須手動增加基本容量,而不是依賴自動擴展。一旦您將資料倉儲擴展到超過 4 個 RPU,您的資料倉儲將繼續使用更多 RPU,而 Amazon Redshift 不會將您的資料倉儲縮減至 4 個 RPU。
注意
您可以在使用 4 個基本 RPU 時建立包含超過 100 個欄的資料表,不過建議您將資料表限制為 100 個欄。超過此限制可能會導致您的資料倉儲在執行查詢時耗盡其記憶體,而造成效能降低。
您可以在下列內容中建立使用 4 個 RPUs的資料倉儲 AWS 區域:
美國東部 (俄亥俄)
美國東部 (維吉尼亞北部)
美國西部 (加利佛尼亞北部)
美國西部 (奧勒岡)
亞太地區 (孟買)
亞太地區 (新加坡)
亞太地區 (雪梨)
亞太地區 (東京)
歐洲 (愛爾蘭)
歐洲 (斯德哥爾摩)
AI 驅動的擴展和最佳化 (預覽版)
AI 驅動的擴展和最佳化功能可在提供 Amazon Redshift Serverless 的所有 AWS 區域中使用。
Amazon Redshift Serverless 提供進階 AI 驅動的擴展和最佳化功能,以因應各種不同的工作負載需求。資料倉儲可能發生下列佈建問題:
資料倉儲可能過度佈建,以改善資源密集型查詢的效能
資料倉儲可能佈建不足,以節省成本。
在資料倉儲工作負載的效能和成本之間取得適當的平衡具有挑戰性,尤其是在臨機查詢和資料量不斷增加的情況下。執行包含低和高資源密集型查詢的混合工作負載時,需要智慧型擴展。AI 驅動的擴展和最佳化功能會自動擴展無伺服器運算或 RPU,以應付資料成長。此功能也有助於將查詢效能維持在目標性價比目標內。AI 驅動的擴展和最佳化會在資料量增加時動態配置運算資源,確保查詢持續符合效能目標。AI 驅動的擴展和最佳化可讓服務順利適應不斷變化的工作負載需求,而不需要手動介入或複雜的容量規劃。
Amazon Redshift Serverless 根據查詢複雜性和資料量等因素,提供更全方位且即時回應的擴展解決方案。此功能允許在最佳化工作負載性價比的同時保持彈性,以有效率地處理不同的工作負載和不斷增長的資料集。Amazon Redshift Serverless 可以自動對 Amazon Redshift Serverless 端點進行 AI 驅動的最佳化,以滿足您針對 Serverless 工作群組指定的性價比目標。如果您不知道要為工作負載設定哪些基本容量,或是工作負載的某些部分可能會受益於更多配置的資源,則此自動定價效能優化特別有用。
範例
若您的組織通常執行的工作負載只需要 32 個 RPU,但突然導入了更複雜的查詢,您可能不知道應該要多少基本容量才算適當。設定較高的基本容量可產生更高的效能,但也會產生較高的成本,因此成本可能不符合您的預期。Amazon Redshift Serverless 使用 AI 驅動的擴展和資源最佳化功能,可自動調整 RPU 以符合您的價格效能目標,同時為您的組織最佳化成本把關。無論工作負載大小是多少,此自動最佳化都很有效用。如果您有任何數量的複雜查詢,自動最佳化可協助您達成組織的價格績效目標。
注意
價格效能目標是特定於工作群組的設定。不同的工作群組可以有不同的價格績效目標。
為了保持成本的可預測性,請設定允許 Amazon Redshift Serverless 配置給工作負載的最大容量限制。
若要設定價格效能目標,請使用 AWS 主控台。根據預設,所有新的 Serverless 工作群組都會啟用價格效能目標,並將 設定為平衡。您可以在建立 Serverless 工作群組後修改價格效能目標。
若要編輯工作群組的性價比目標:
在 Amazon Redshift Serverless 主控台中,選擇工作群組組態。
選擇您要為其編輯價格效能目標的工作群組。選擇效能索引標籤,然後選擇編輯。
選擇性價比目標,並將滑桿調整至所需的設定。
選擇儲存變更。
若要更新 Amazon Redshift Serverless 可分配給工作負載的 RPU 數量上限,請選擇工作群組區段的限制索引標籤。
您可以使用性價比目標滑桿,在成本和效能之間設定所需的平衡。移動滑桿即可選擇下列其中一個選項:
針對成本進行最佳化 - 此設定會優先考慮節省成本。若這樣做不會產生額外的費用,則 Amazon Redshift Serverless 會嘗試自動向上擴展運算容量。Amazon Redshift Serverless 也會嘗試縮減運算資源以降低成本,不過可能會增加查詢執行時期。
平衡 - 此設定會在效能和成本之間取得平衡。Amazon Redshift Serverless 會擴展以實現效能,並可能導致中等程度的成本增加或減少。這是大多數 Amazon Redshift Serverless 資料倉儲的建議設定。
針對效能進行最佳化 - 此設定會優先考慮效能。Amazon Redshift 會積極擴展以實現高效能,因而可能產生較高的成本。
中間位置:您也可以將滑桿設定為平衡和針對成本進行最佳化或針對效能進行最佳化之間的兩個中間位置之一。如果完全針對成本或效能最佳化太過極端,請使用這些設定。
選擇性價比目標時的考量事項
您可以使用性價比滑桿來為工作負載選擇所需的性價比目標。AI 驅動的擴展和最佳化演算法會隨著時間從您的工作負載歷史記錄學習,並改善預測和決策準確性。
範例
此範例假設查詢花 7 分鐘時間,且費用為 7 美元。下圖顯示未擴展的查詢執行時期和成本。
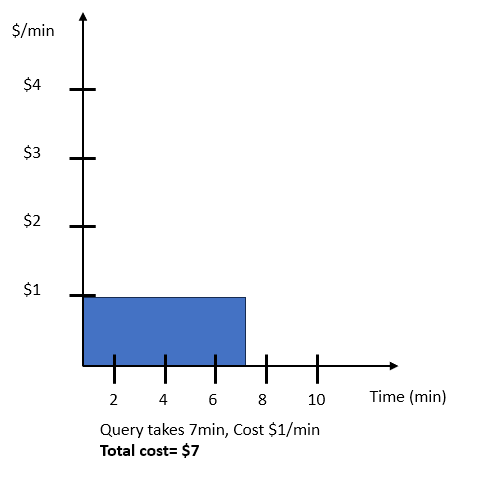
某一特定查詢可能會以幾種不同的方式擴展,如下所示。根據您選擇的性價比目標,AI 驅動的擴展會預測查詢如何權衡效能和成本,並據此進行擴展。選擇不同的滑桿選項會產生下列結果:
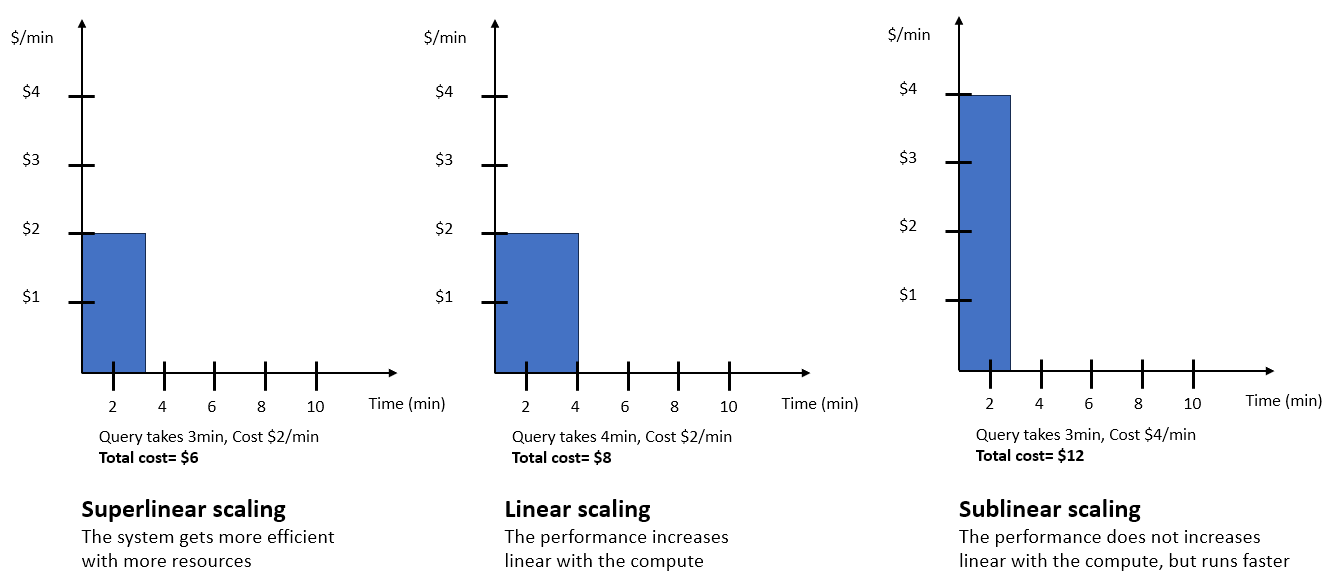
針對成本進行最佳化 - 使用針對成本進行最佳化選項時,您的資料倉儲會採用有利降低成本的選項進行擴展。在上述範例中,超線性擴展方法示範了此行為。擴展只會在根據擴展模型預測,能夠以符合成本效益的方式進行時完成。如果擴展模型預測無法針對所指工作負載進行成本最佳化擴展,則資料倉儲將不會擴展。
平衡 - 使用平衡選項時,系統會進行擴展,同時平衡成本和效能考量,且可能有限地增加成本。平衡選項會執行超線性、線性及可能亞線性工作負載擴展。
針對效能進行最佳化 - 使用針對效能進行最佳化選項,除了先前改善效能的方法之外,系統也會在即使成本較高的情況下擴展,而且可能不會與執行時期改善成正比。透過針對效能進行最佳化,系統會盡可能執行超線性擴展、線性擴展和亞線性擴展。滑桿位置越接近針對效能進行最佳化位置,Amazon Redshift Serverless 越會允許亞線性擴展。
設定性價比滑桿時,請注意下列事項:
您隨時可以變更性價比設定,但工作負載擴展不會立即變更。隨著系統了解目前工作負載,擴展也會隨著時間而變更。我們建議監控 Serverless 工作群組 1 到 3 天,以確認新設定的影響情形。
性價比滑桿選項最大容量和最大 RPU 小時數可一起運作。最大容量和最大 RPU 小時數是兩個控制項,分別用於限制 Amazon Redshift Serverless 允許資料倉儲擴展的最大 RPU,以及 Amazon Redshift Serverless 允許資料倉儲使用的最大 RPU 小時數。無論性價比目標設定為何,Amazon Redshift Serverless 一律遵守並強制執行這些設定。
監控資源自動擴展
您可以透過下列方式監控 AI 驅動的 RPU 擴展:
在 Amazon Redshift 主控台上檢閱使用的 RPU 容量圖。
監控 CloudWatch 中
AWS/Redshift-Serverless和Workgroup下的ComputeCapacity指標。查詢 SYS_QUERY_HISTORY 檢視。提供特定查詢 ID 或查詢文字以識別時段。使用此時段查詢 SYS_SERVERLESS_USAGE 系統檢視以尋找
compute_capacity值。compute_capacity欄位顯示查詢執行時期中擴展的 RPU。
使用以下範例查詢 SYS_QUERY_HISTORY 檢視。將範例值取代為您的查詢文字。
select query_id,query_text,start_time,end_time, elapsed_time/1000000.0 duration_in_seconds from sys_query_history where query_text like '<query_text>' and query_text not like '%sys_query_history%' order by start_time desc
執行下列查詢,以查看 compute_capacity 在 start_time 到 end_time 這段期間如何擴展。將下列查詢中的 start_time 和 end_time 取代為上述查詢的輸出:
select * from sys_serverless_usage where end_time >= 'start_time' and end_time <= DATEADD(minute,1,'end_time') order by end_time asc
如需使用這些功能的逐步指示,請參閱在 Amazon Redshift Serverless 中設定監控、限制和警示,以保持成本的可預測性
使用 AI 驅動的擴展和最佳化時的考量事項
使用 AI 驅動的擴展和最佳化時,請考慮下列事項:
對於需要 8 到 512 Base RPU 的 Amazon Redshift Serverless 現有工作負載,建議使用 Amazon Redshift Serverless AI 驅動的擴展和最佳化,以獲得最佳結果。不建議對 4 個基本 RPU 或超過 512 個基本 RPU 工作負載使用此功能。
性價比目標會自動最佳化工作負載,雖然結果可能有所不同。我們建議您經過一段時間後再使用此功能,讓系統能夠藉由執行代表性的工作負載來學習您的專屬模式。
AI 驅動的擴展和最佳化會使用最佳時間,根據 Amazon Redshift Serverless 執行個體上執行的工作負載將最佳化套用至 Serverless 工作群組。
若要深入了解 AI 驅動最佳化和資源擴展,請觀看以下影片。
