Amazon Redshift 將不再支援從修補程式 198 開始建立新的 Python UDFs。現有 Python UDF 將繼續正常運作至 2026 年 6 月 30 日。如需詳細資訊,請參閱部落格文章
本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
使用 SVL_QUERY_SUMMARY 檢視
若要使用 SVL_QUERY_SUMMARY 依串流分析摘要資訊,請執行下列操作:
-
執行下列查詢來判斷您的查詢 ID:
select query, elapsed, substring from svl_qlog order by query desc limit 5;在
substring欄位中檢查截斷的查詢文字,判斷代表您的查詢的query值。如果您已執行查詢超過一次,請使用來自具有較低query值資料列的elapsed值。那是編譯版本的資料列。如果您已執行許多查詢,您可以提升 LIMIT 子句使用的值,以確定您的查詢已包含在其中。 -
從 SVL_QUERY_SUMMARY 中,為您的查詢選取資料列。依串流、區段和步驟排列結果:
select * from svl_query_summary where query = MyQueryID order by stm, seg, step;以下是結果範例。
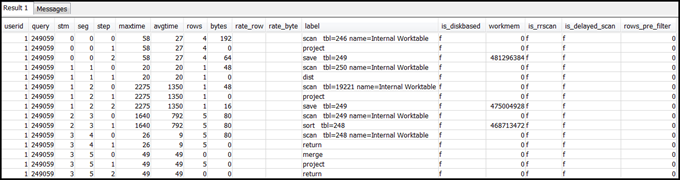
-
使用將查詢計劃映射到查詢摘要中的資訊,將步驟與查詢計畫中的操作映射。它們的資料列和位元組應該具有大約相同的值 (查詢計畫中的資料列 * 寬度)。如果不同,請參閱資料表統計資訊遺漏或過時以取得建議的解決方案。
-
查看任何步驟的
is_diskbased欄位是否具有t(true) 值。如果系統沒有為查詢處理配置足夠的記憶體,雜湊、彙整和排序為可能將資料寫入至磁碟的運算子。如果
is_diskbased為 true,請參閱配置給查詢的記憶體不足以取得建議的解決方案。 -
檢閱
label欄位值,並查看步驟中的任何位置是否有 AGG-DIST-AGG 序列。出現它表示兩個步驟彙整,其代價高昂。若要修正此問題,請將 GROUP BY 子句變更為使用散發索引鍵 (如果有多個則第一個索引鍵)。 -
檢閱每個區段的
maxtime值 (區段中的所有步驟是相同的)。識別具有最高maxtime值的區段,並檢閱此區段中下列運算子的步驟。注意
高的
maxtime值並不一定代表區段有問題。雖然值很高,但該區段可能並未耗費大量時間處理。串流中的所有區段會同時開始計時。不過,部分下游區段必須等到取得來自上游的資料後才能執行。此影響可能使得它們看起來耗費了長時間,因為其maxtime值將同時包含等候時間和處理時間。-
BCAST 或 DIST:在這些情況下,造成
maxtime高值的原因可能是重新配送大量資料列。如需建議的解決方案,請參閱次佳資料分佈。 -
HJOIN (雜湊聯結):如果有問題步驟的
rows欄位相較於查詢中最終 RETURN 步驟中的rows值有非常高的值,請參閱雜湊聯結以取得建議的解決方案。 -
SCAN/SORT:在聯結步驟之前尋找步驟的 SCAN、SORT、SCAN、MERGE 序列。這個模式指出未排序的資料會經過掃描、排序,然後與資料表排序的區域合併。
查看相較於查詢中最終 RETURN 步驟的資料列值,SCAN 步驟的資料列值是否有非常高的值。這個模式指出執行引擎正在掃描稍後將捨棄的資料列,這樣做缺乏效率。如需建議的解決方案,請參閱不足的限制性述詞。
如果 SCAN 步驟的
maxtime值很高,請參閱次佳的 WHERE 子句以取得建議的解決方案。如果 SORT 步驟的
rows值不是零,請參閱未排序或排序錯誤的資料列以取得建議的解決方案。
-
-
檢閱最終 RETURN 步驟之前的 5–10 步驟的
rows和bytes值,來了解傳回用戶端的資料量。此程序可以是一門藝術。例如,在下列範例查詢摘要中,第三個 PROJECT 步驟提供
rows值而非bytes值。查看前述步驟來找到具有相同rows值的步驟,您會找到同時提供列和位元組資訊的 SCAN 步驟。以下是範例結果。
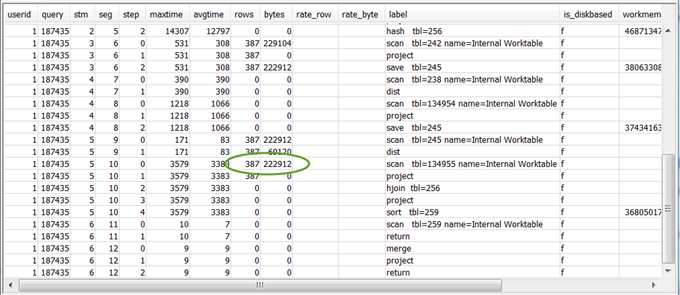
如果您要傳回異常大的資料量,請參閱非常大的結果集以取得建議的解決方案。
-
相較於其他步驟,查看
bytes值是否相對於任何步驟中的rows值來得高。這個模式可能指出您正選取許多資料欄。如需建議的解決方案,請參閱大型 SELECT 清單。
