Amazon Redshift 將不再支援從修補程式 198 開始建立新的 Python UDFs。現有 Python UDF 將繼續正常運作至 2026 年 6 月 30 日。如需詳細資訊,請參閱部落格文章
本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
機器學習
Amazon Redshift 機器學習 (Amazon Redshift ML) 是一種強大的雲端型服務,可讓各種技能等級的分析師和資料科學家更輕鬆地使用機器學習技術。Amazon Redshift ML 使用模型來產生結果。您可以透過以下方式使用模型:
您可以將想要訓練模型的資料,以及與資料輸入相關聯的中繼資料提供給 Amazon Redshift。然後 Amazon Redshift ML 會在 Amazon SageMaker AI 中建立模型,以便在輸入資料中擷取模式。透過將自有資料用於模型,您就可以使用 Amazon Redshift ML 來識別資料中的趨勢,例如流失預測、客戶生命週期價值或收入預測。您可以使用這些模型來產生新輸入資料的預測,而且不會產生額外費用。
您可以使用 Amazon Bedrock 提供的其中一個基礎模型 (FM),例如 Claude 或 Amazon Titan。使用 Amazon Bedrock 時,只需幾個步驟即可將大型語言模型 (LLM) 的強大功能與 Amazon Redshift 中的分析資料相互結合。藉由利用外部大型語言模型 (LLM),即可使用 Amazon Redshift 對資料執行自然語言處理 (NLP)。您可以將 NLP 用於文字產生、情緒分析或翻譯等應用程式。如需使用 Amazon Bedrock 搭配 Amazon Redshift 的相關資訊,請參閱 Amazon Redshift ML 與 Amazon Bedrock 整合。
注意
選擇不使用您的資料來改善服務
如果您使用的是 Amazon Bedrock 模型,建議您閱讀有關 Amazon Bedrock 服務如何處理您的資料 AWS 的政策。您應該判斷是否需要使用選擇退出政策,以防止服務使用您的資料來改進模型或服務 (假設 Amazon Bedrock 未來實作此類功能的話)。若要確保服務不會將您的資料用於此類目的,請使用一般 AWS 選擇退出政策。
如需詳細資訊,請參閱下列內容:
注意
LLM 可能會產生不正確或不完整的資訊。我們建議驗證 LLM 產生的資訊,以確保其正確且完整。
Amazon Redshift ML 如何與 Amazon SageMaker AI 搭配使用
Amazon Redshift 與 Amazon SageMaker AI Autopilot 搭配使用時,可自動獲得最佳模型,並在 Amazon Redshift 中使用預測功能。
下圖說明Amazon Redshift ML 的運作方式。
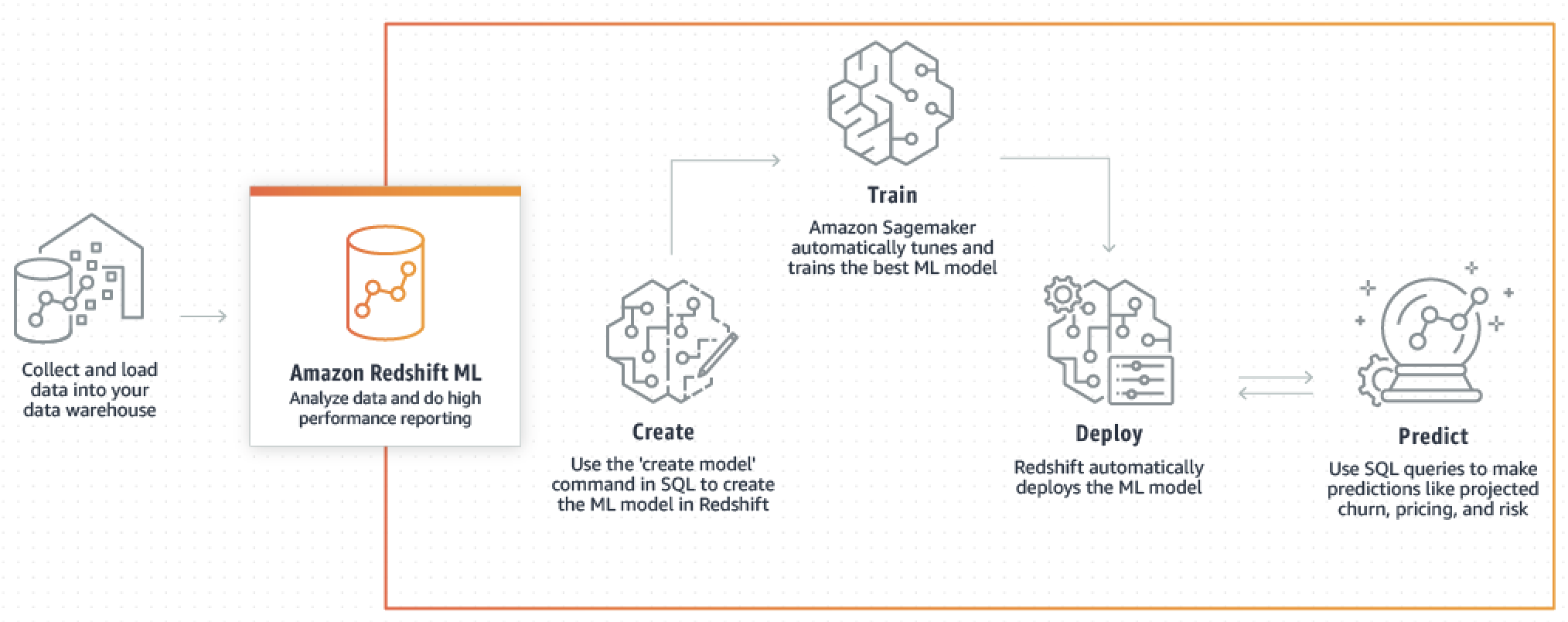
一般工作流程如下:
-
Amazon Redshift會 將訓練資料匯出至 Amazon S3。
-
Amazon SageMaker AI Autopilot 會預先處理訓練資料。預處理會執行重要功能,例如輸入遺漏值。其會識別特定資料欄是可分類的 (例如郵遞區號),正確格式化這些資料欄以進行訓練,並執行許多其他工作。選擇要套用於訓練資料集的最佳預處理器本身就是個問題,而 Amazon SageMaker AI Autopilot 會自動執行其解決方案。
-
Amazon SageMaker AI Autopilot 會尋找演算法和演算法超參數,提高模型最準確的預測。
-
Amazon Redshift 會將預測函數註冊為您 Amazon Redshift 叢集中的 SQL 函數。
-
當您執行 CREATE MODEL 陳述式時,Amazon Redshift 會使用 Amazon SageMaker AI 進行訓練。因此,訓練模型會產生相關的成本。這是 AWS 帳單中 Amazon SageMaker AI 的個別明細項目。您也需要支付 Amazon S3 用於存放訓練資料的儲存費用。使用透過 CREATE MODEL 建立且可在 Redshift 叢集上編譯和執行的模型進行推論不收費。使用 Amazon Redshift ML 不會收取額外的 Amazon Redshift 費用。
主題
