Amazon Redshift 將不再支援從修補程式 198 開始建立新的 Python UDFs。現有 Python UDF 將繼續正常運作至 2026 年 6 月 30 日。如需詳細資訊,請參閱部落格文章
本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
資料倉儲系統架構
本節說明組成 Amazon Redshift 資料倉儲架構的元件,如下圖所示。
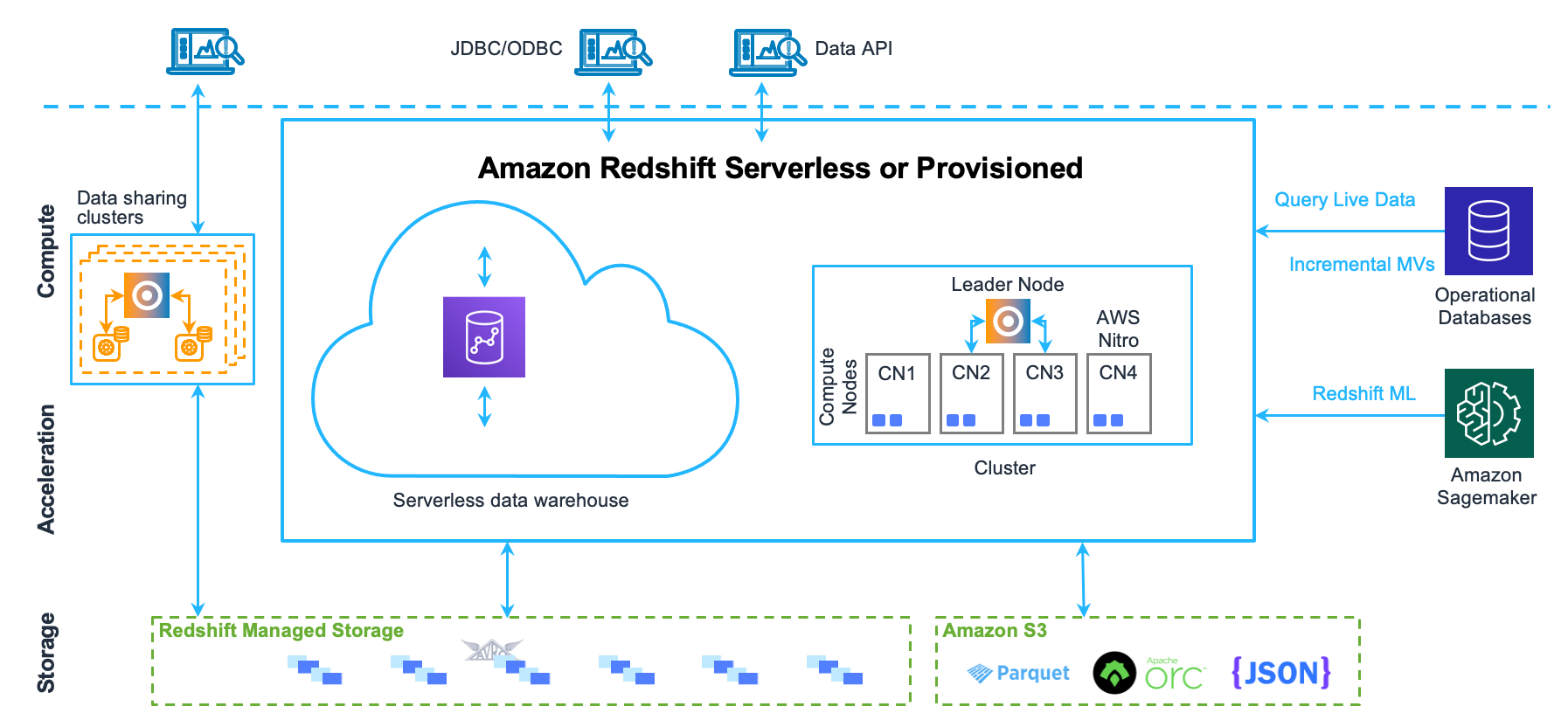
用戶端應用程式
Amazon Redshift 整合了各種資料載入和 ETL (擷取、轉換和載入) 工具,以及商業智慧 (BI) 報告、資料探勘和分析工具。Amazon Redshift 是以開放式標準 PostgreSQL 為基礎,因此大多數現有的 SQL 用戶端應用程式都只需進行最少的變更即可運作。關於 Amazon Redshift SQL 與 PostgreSQL 之間重要差異的相關資訊,請參閱 Amazon Redshift 和 PostgreSQL。
叢集
Amazon Redshift 資料倉儲的核心基礎設施元件是叢集。
叢集是由一或多個運算節點所組成。如果為叢集佈建了兩個或多個運算節點,則會有另外的領導節點負責統籌運算節點和處理外部通訊。您的用戶端應用程式只會直接和領導節點互動,外部應用程式不會知道運算節點的存在。
領導節點
領導節點會管理與用戶端程式的通訊,以及和運算節點的所有通訊。此節點會剖析和制定執行計畫,來執行資料庫的操作,尤其是取得複雜查詢結果所需的一系列步驟。領導節點會根據執行計畫,來編譯程式碼、將編譯過的程式碼分發到運算節點,並指派資料的各部分給每個運算節點。
只有當查詢參考儲存於運算節點上的資料表時,領導節點才會將 SQL 陳述式分發到運算節點。所有其他查詢僅在領導節點上執行。Amazon Redshift 的設計目的是僅在領導節點上實作某些 SQL 函數。如果查詢使用這些函式的任一個,而且參考位於運算節點上的資料表,則將會傳回錯誤。如需詳細資訊,請參閱領導節點上所支援的 SQL 函數。
運算節點
領導節點會針對執行計畫的個別元素,來編譯程式碼,並將程式碼指派給個別的運算節點。運算節點會執行編譯過的程式碼,並將中間的結果傳回領導節點,以進行最終的彙總。
每個運算節點都具有自己專屬的 CPU 和記憶體 (根據節點類型決定)。隨著工作負載的增長,您可以藉由增加節點的數量、將節點的類型升級,或是同時實行這兩種做法,來增加叢集的運算容量。
Amazon Redshift 會針對您的運算需求,提供數種節點類型。如需每個節點類型的詳細資訊,請參閱《Amazon Redshift 管理指南》中的<Amazon Redshift 叢集>。
Redshift 受管儲存
資料倉儲資料會儲存在個別的儲存層 Redshift 受管儲存 (RMS) 中。RMS 提供使用 Amazon S3 儲存體將儲存空間擴展到 PB 級的能力。RMS 可讓您單獨完成運算和儲存體的擴展與付費,因此您可以只根據運算需求調整叢集的大小。它會自動使用高效能 SSD 型本機儲存做為第 1 層快取。它還會利用資料區塊溫度、資料區塊存留時間和工作負載模式等最佳化功能提供高效能,同時在需要時自動將儲存擴展到 Amazon S3,而無需採取任何動作。
節點配量
運算節點可分割為分割。每個分割會分配到節點的一部分記憶體和磁碟空間,並且用以處理指派給節點的部分工作負載。領導節點會負責將資料分發給分割,並將任何查詢或其他資料庫操作的工作負載,分派給這些分割。這些分割接著會平行運作,以完成操作。
每個節點的分割數目,取決於叢集的節點大小。如需每個節點大小有多少配量的相關資訊,請移至《Amazon Redshift 管理指南》中的<關於叢集和節點>。
建立資料表時,您可以選擇性地指定一個欄做為分佈索引鍵。當資料載入資料表時,會根據為資料表定義的分佈索引鍵,將資料列分發給節點分割。選擇理想的分佈索引鍵,可讓 Amazon Redshift 利用平行處理作業,以高效率的方式載入資料和執行查詢。如需關於選擇分佈索引鍵的詳細資訊,請參閱選擇最佳的分佈方式。
內部網路
Amazon Redshift 善用了高頻寬連線、鄰近位置與自訂通訊協定,在領導節點和運算節點之間,提供私密的超高速網路通訊。運算節點會在獨立的隔離網路中執行,用戶端應用程式絕對不會直接存取此網路。
資料庫
叢集包含一個或多個資料庫。使用者資料儲存於運算節點上。您的 SQL 用戶端會和領導節點進行通訊,然後再由領導節點統籌使用運算節點的查詢執行作業。
Amazon Redshift 是關聯式資料庫管理系統 (RDBMS),因此和其他的 RDBMS 應用程式相容。雖然其提供與典型 RDBMS 相同的功能 (包括線上交易處理 (OLTP) 功能,例如插入和刪除資料),不過 Amazon Redshift 最適合應用於超大資料集的高效能分析與報告。
Amazon Redshift 是以 PostgreSQL 為基礎。在設計和開發您的資料倉儲應用程式時,您需要考量 Amazon Redshift 與 PostgreSQL 之間的許多很重要的差異。如需 Amazon Redshift SQL 與 PostgreSQL 之間差異的詳細資訊,請參閱 Amazon Redshift 和 PostgreSQL。
