本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
用於研究運算的雲端爆量
美國某 R1 (Doctoral Universities – Very High Research Activity) 研究機構的研究運算群組已使用 Slurm 排程器執行內部部署高效能運算 (HPC) 叢集多年。除了數週的排程維護之外,叢集以 80-95% 的使用率執行,其中大部分佇列已滿。
機構中越來越多的研究活動帶來了容量和能力挑戰。一些高度關注的研究人員一直對某些佇列執行長時間執行的模擬,這增加了其他使用者的等待時間。新聘用的講師需要執行大量天氣模擬,以建置用於天氣預測的新型人工智慧和機器學習 (AI/ML) 模型,但他們需要的容量比現有的容量更多。研究運算群組也收到更多請求,要求最新的圖形處理單元 (GPUs) 來訓練機器學習模型。即使有了新 GPUs 的資金,團隊仍需要等待幾個月才能獲得資料中心中擴展機架空間的核准。
許多研究人員都不願意刪除舊資料,因此本機儲存容量也是一項挑戰。需要更具可擴展性的長期儲存選項,才能釋放現場部署中寶貴的高效能儲存。
雲端透過混合運算和儲存解決方案解決這些挑戰,可讓您在內部部署容量不足時將研究運算爆增到雲端。下列架構圖說明一些運算和儲存爆量方法,使用 AWS ParallelCluster
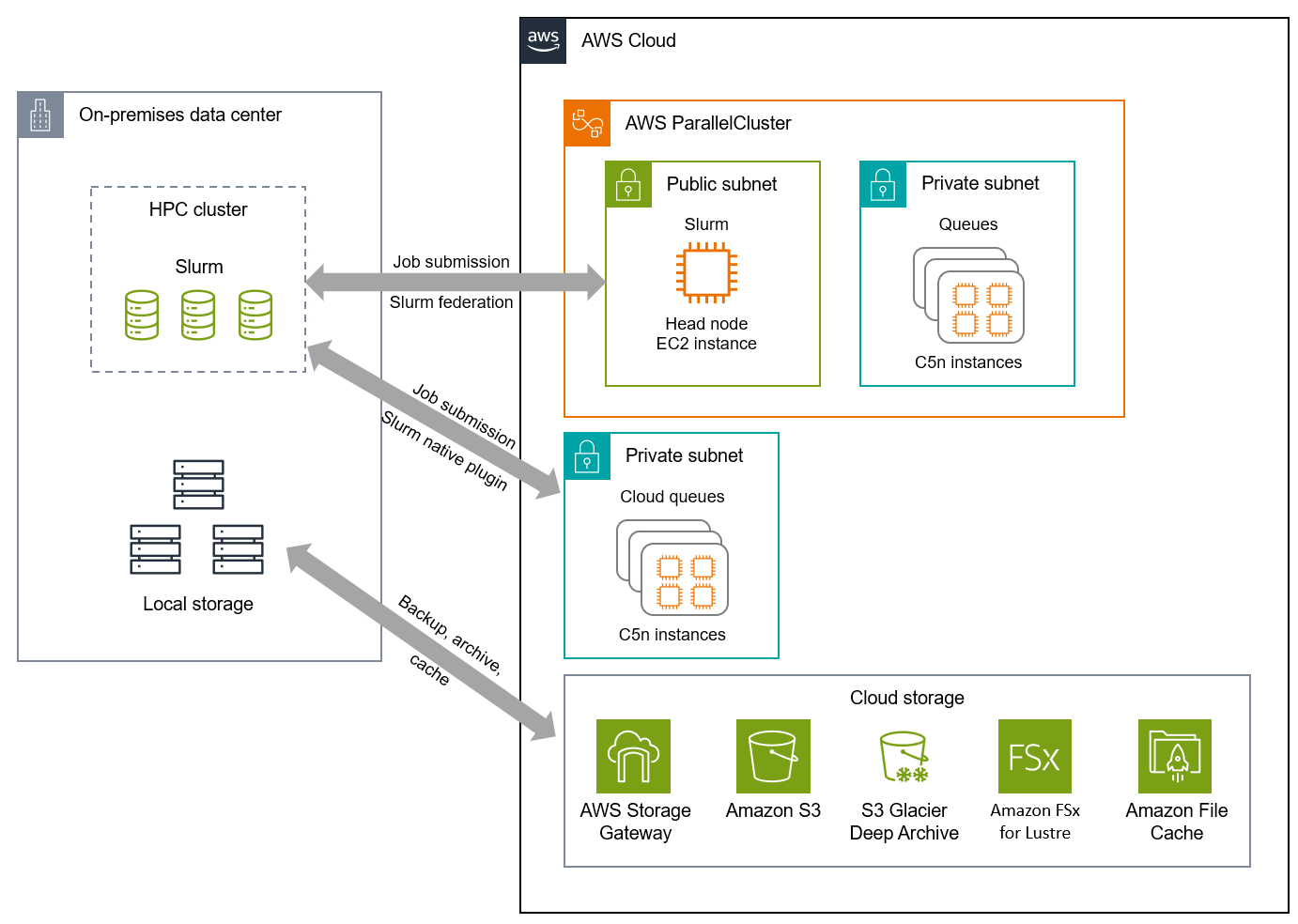
此架構遵循下列建議:
-
選取主要的策略性雲端供應商。 此架構使用一個主要雲端提供者,以避免受到最不常見的分母方法限制。透過這種方式,機構可以利用主要雲端供應商提供的創新和原生運算和儲存服務。研究運算團隊可以專注於最佳化主要雲端供應商所提供環境中的工作負載,而不是如何在不同的雲端環境中工作。
-
為每個雲端服務供應商建立安全與控管要求。 此架構中使用的每個服務和工具都可以設定為符合研究運算團隊的安全和管理要求,包括私有連線、傳輸中和靜態資料加密、活動記錄等。
-
盡可能且實際地採用雲端原生受管服務。 此架構可讓您使用受管儲存和運算服務,以及簡化叢集管理的工具。如此一來,研究運算團隊就不必擔心自行管理叢集或基礎基礎設施,這可能很複雜且耗時。
-
當現有的現場部署投資鼓勵持續使用時,實作混合架構。 此架構可讓機構繼續使用其內部部署資源,並利用雲端來增加容量並隨需擴展運算能力。透過雲端,機構可以調整運算類型的適當大小,以最大限度地提高價格效能,並存取最新的技術來促進創新,而無需對其他現場部署硬體進行大量預付投資。
