本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
最佳化 AWS Blu Age 現代化應用程式的效能
Vishal Jaswani、Manish Roy 和 Himanshu Sah,Amazon Web Services
總結
使用 AWS Blu Age 進行現代化的大型主機應用程式需要先進行功能和效能相等性測試,才能部署到生產環境。在效能測試中,現代化應用程式的效能可能比傳統系統慢,尤其是在複雜的批次任務中。這種差異是因為大型主機應用程式是單體的,而現代應用程式使用多層架構。此模式提供最佳化技術,以解決透過使用自動重構搭配 AWS Blu Age 進行現代化應用程式的效能差距。
模式使用 AWS Blu Age 現代化架構搭配原生 Java 和資料庫調校功能,來識別和解決效能瓶頸。模式說明如何使用分析和監控來識別 SQL 執行時間、記憶體使用率和 I/O 模式等指標的效能問題。接著說明如何套用目標最佳化,包括資料庫查詢重組、快取和商業邏輯精簡。
改善批次處理時間和系統資源使用率,可協助您符合現代化系統中的大型主機效能等級。此方法在轉換為現代雲端架構期間維持功能等效性。
若要使用此模式,請依照 Epics 區段中的指示設定您的系統並識別效能熱點,並套用架構區段中詳細說明的最佳化技術。
先決條件和限制
先決條件
AWS Blu Age 現代化應用程式
安裝資料庫用戶端和分析工具的管理權限
AWS Blu Age Level 3 認證
中階了解 AWS Blu Age 架構、產生的程式碼結構和 Java 程式設計
限制
下列最佳化功能在此模式範圍之外:
應用程式層之間的網路延遲最佳化
透過 Amazon Elastic Compute Cloud (Amazon EC2) 執行個體類型和儲存最佳化進行基礎設施層級最佳化
並行使用者負載測試和壓力測試
產品版本
JProfiler 13.0 版或更新版本 (建議最新版本)
pgAdmin 8.14 版或更新版本
Architecture
此模式使用 JProfiler 和 pgAdmin 等工具,為 AWS Blu Age 應用程式設定分析環境。它支援透過 AWS Blu Age 提供的 DAOManager 和 SQLExecutionBuilder APIs進行最佳化。
本節的其餘部分提供詳細資訊和範例,用於識別現代化應用程式的效能熱點和最佳化策略。Epics 區段中的步驟會參考此資訊,以取得進一步指引。
識別現代化大型主機應用程式中的效能熱點
在現代化大型主機應用程式中,效能熱點是程式碼中會導致顯著變慢或效率不佳的特定區域。這些熱點通常是由大型主機和現代化應用程式之間的架構差異所造成。若要識別這些效能瓶頸並最佳化現代化應用程式的效能,您可以使用三種技術:SQL 記錄、查詢EXPLAIN計畫和 JProfiler 分析。
熱點識別技術:SQL 記錄
現代 Java 應用程式,包括使用 AWS Blu Age 進行現代化的應用程式,具有記錄 SQL 查詢的內建功能。您可以在 AWS Blu Age 專案中啟用特定記錄器,以追蹤和分析應用程式執行的 SQL 陳述式。此技術對於識別效率不佳的資料庫存取模式特別有用,例如過多的個別查詢或結構不良的資料庫呼叫,可透過批次處理或查詢精簡進行最佳化。
若要在 AWS Blu Age 現代化應用程式中實作 SQL 記錄,請將 application.properties 檔案中 DEBUG SQL 陳述式的日誌層級設定為 ,以擷取查詢執行詳細資訊:
level.org.springframework.beans.factory.support.DefaultListableBeanFactory : WARN level.com.netfective.bluage.gapwalk.runtime.sort.internal: WARN level.org.springframework.jdbc.core.StatementCreatorUtils: DEBUG level.com.netfective.bluage.gapwalk.rt.blu4iv.dao: DEBUG level.com.fiserv.signature: DEBUG level.com.netfective.bluage.gapwalk.database.support.central: DEBUG level.com.netfective.bluage.gapwalk.rt.db.configuration.DatabaseConfiguration: DEBUG level.com.netfective.bluage.gapwalk.rt.db.DatabaseInteractionLoggerUtils: DEBUG level.com.netfective.bluage.gapwalk.database.support.AbstractDatabaseSupport: DEBUG level.com.netfective.bluage.gapwalk.rt: DEBUG
使用記錄的資料來識別最佳化目標,以監控高頻率和效能緩慢的查詢。專注於批次程序中的查詢,因為它們通常具有最高的效能影響。
熱點識別技術:查詢 EXPLAIN 計劃
此方法使用關聯式資料庫管理系統的查詢規劃功能。您可以使用 EXPLAIN PostgreSQL 或 MySQL 或 Oracle EXPLAIN PLAN中的 等命令,來檢查資料庫執行指定查詢的方式。這些命令的輸出可提供查詢執行策略的寶貴洞見,包括將使用索引還是執行完整資料表掃描。此資訊對於最佳化查詢效能至關重要,尤其是在適當的索引可以大幅縮短執行時間的情況下。
從應用程式日誌中擷取最常重複的 SQL 查詢,並使用資料庫特有的EXPLAIN命令來分析執行緩慢查詢的執行路徑。以下是 PostgreSQL 資料庫的範例。
查詢:
SELECT * FROM tenk1 WHERE unique1 < 100;
EXPLAIN 命令:
EXPLAIN SELECT * FROM tenk1 where unique1 < 100;
輸出:
Bitmap Heap Scan on tenk1 (cost=5.06..224.98 rows=100 width=244) Recheck Cond: (unique1 < 100) -> Bitmap Index Scan on tenk1_unique1 (cost=0.00..5.04 rows=100 width=0) Index Cond: (unique1 < 100)
您可以解譯EXPLAIN輸出,如下所示:
從最內到最外 (從下到上) 操作讀取
EXPLAIN計劃。尋找關鍵術語。例如,
Seq Scan表示完整資料表掃描,並Index Scan顯示索引用量。檢查成本值:第一個數字是啟動成本,第二個數字是總成本。
請參閱預估輸出資料列數量
rows的值。
在此範例中,查詢引擎會使用索引掃描來尋找相符的資料列,然後只擷取這些資料列 (Bitmap Heap Scan)。這比掃描整個資料表更有效率,即使個別資料列存取的成本較高。
EXPLAIN 計劃輸出中的資料表掃描操作表示缺少索引。最佳化需要建立適當的索引。
熱點識別技術:JProfiler 分析
JProfiler 是全方位的 Java 分析工具,可透過識別緩慢的資料庫呼叫和 CPU 密集型呼叫,協助您解決效能瓶頸。此工具在識別慢速 SQL 查詢和低效率記憶體使用量方面特別有效。
查詢的範例分析:
select evt. com.netfective.bluage.gapwalk.rt.blu4iv.dao.Blu4ivTableManager.queryNonTrasactional
JProfiler 熱點檢視提供下列資訊:
時間欄
顯示總執行持續時間 (例如 329 秒)
顯示應用程式總時間的百分比 (例如 58.7%)
協助識別最耗時的操作
平均時間欄
顯示每個執行持續時間 (例如 2,692 微秒)
指出個別操作效能
協助找出慢速個別操作
事件欄
顯示執行計數 (例如 122,387 次)
指出操作頻率
協助識別經常呼叫的方法
針對範例結果:
高頻率:122,387 個執行表示可能進行最佳化
效能問題:平均時間 2,692 微秒表示效率低下
重大影響:總時間的 58.7% 表示重大瓶頸
JProfiler 可以分析應用程式的執行時間行為,以透過靜態程式碼分析或 SQL 記錄顯示可能不明顯的熱點。這些指標可協助您識別需要最佳化的操作,並判斷最有效的最佳化策略。如需 JProfiler 功能的詳細資訊,請參閱 JProfiler 文件
結合使用這三種技術 (SQL 記錄、查詢EXPLAIN計畫和 JProfiler) 時,您可以全面了解應用程式的效能特性。透過識別和解決最重要的效能熱點,您可以彌補原始大型主機應用程式與現代化雲端系統之間的效能差距。
識別應用程式的效能熱點後,您可以套用最佳化策略,下一節會說明這些策略。
大型主機現代化最佳化策略
本節概述最佳化從大型主機系統現代化應用程式的關鍵策略。它著重於三種策略:使用現有的 APIs、實作有效的快取,以及最佳化商業邏輯。
最佳化策略:使用現有的 APIs
AWS Blu Age 在 DAO 介面中提供數個強大的 APIs,您可以用來最佳化效能。兩個主要界面 — DAOManager 和 SQLExecutionBuilder — 提供增強應用程式效能的功能。
DAOManager
DAOManager 做為現代化應用程式中資料庫操作的主要界面。它提供多種方法來增強資料庫操作和改善應用程式效能,尤其是直接建立、讀取、更新和刪除 (CRUD) 操作和批次處理。
使用 SetMaxResults。在 DAOManager API 中,您可以使用 SetMaxResults 方法來指定單一資料庫操作中要擷取的記錄數目上限。根據預設,DAOManager 一次只會擷取 10 筆記錄,這可能會在處理大型資料集時導致多個資料庫呼叫。當您的應用程式需要處理大量記錄,且目前正在進行多個資料庫呼叫來擷取記錄時,請使用此最佳化。這在您透過大型資料集反覆運算的批次處理案例中特別有用。在下列範例中,左側的程式碼 (最佳化之前) 會使用 10 筆記錄的預設資料擷取值。右側的程式碼 (最佳化後) 會將 setMaxResults 設定為一次擷取 100,000 筆記錄。

注意
請仔細選擇較大的批次大小,並檢查物件大小,因為此最佳化會增加記憶體使用量。
將 SetOnGreatorOrEqual 取代為 SetOnEqual。此最佳化涉及變更您用來設定擷取記錄條件的方法。SetOnGreatorOrEqual 方法會擷取大於或等於指定值的記錄,而 SetOnEqual 只會擷取完全符合指定值的記錄。
當您知道需要完全相符,且目前使用 SetOnEqual SetOnGreatorOrEqual,如下列程式碼範例所示。 readNextEqual 此最佳化可減少不必要的資料擷取。

使用批次寫入和更新操作。您可以使用批次操作將多個寫入或更新操作分組為單一資料庫交易。這可減少資料庫呼叫的數量,並可大幅改善涉及多個記錄的操作效能。
在下列範例中,左側的程式碼會在迴圈中執行寫入操作,這會降低應用程式的效能。您可以使用批次寫入操作來最佳化此程式碼:在
WHILE迴圈的每個反覆運算期間,您可以將記錄新增至批次,直到批次大小達到預先決定的大小 100。然後,您可以在達到預定批次大小時排清批次,然後將任何剩餘的記錄排清至資料庫。這在您處理需要更新的大型資料集時特別有用。
新增索引。新增索引是一種資料庫層級最佳化,可大幅改善查詢效能。索引可讓資料庫快速找到具有特定資料欄值的資料列,而無需掃描整個資料表。在子
WHERE句、JOIN條件或ORDER BY陳述式中常用的資料欄上使用索引。這對大型資料表或快速資料擷取至關重要時尤其重要。
SQLExecutionBuilder
SQLExecutionBuilder 是一種靈活的 API,可用來控制將執行的 SQL INSERT 查詢、僅使用 擷取特定資料欄SELECT,以及使用動態資料表名稱。在下列範例中,SQLExecutorBuilder 會使用您定義的自訂查詢。

在 DAOManager 和 SQLExecutionBuilder 之間進行選擇
這些 APIs之間的選擇取決於您的特定使用案例:
如果您希望 AWS Blu Age Runtime 產生 SQL 查詢,而不是自行撰寫查詢,請使用 DAOManager。
當您需要寫入 SQL 查詢以利用資料庫特定的功能或寫入最佳的 SQL 查詢時,請選擇 SQLExecutionBuilder。
最佳化策略:快取
在現代化應用程式中,實作有效的快取策略可以大幅減少資料庫呼叫並改善回應時間。這有助於彌補大型主機和雲端環境之間的效能差距。
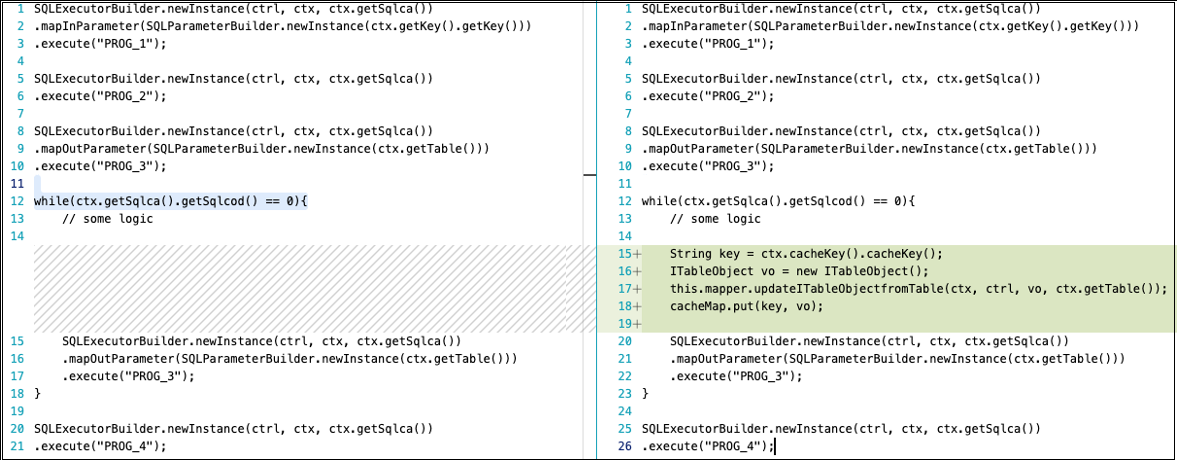
在 AWS Blu Age 應用程式中,簡單的快取實作使用內部資料結構,例如雜湊圖或陣列清單,因此您不需要設定需要成本和程式碼重組的外部快取解決方案。此方法對於經常存取但不常變更的資料特別有效。當您實作快取時,請考慮記憶體限制條件和更新模式,以確保快取的資料保持一致並提供實際的效能優勢。
成功快取的關鍵是識別要快取的正確資料。在下列範例中,左側的程式碼一律會從資料表讀取資料,而當本機雜湊映射沒有指定金鑰的值時,右側的程式碼會從資料表讀取資料。 cacheMap 是在程式內容中建立並在程式內容的清除方法中清除的雜湊映射物件。
使用 DAOManager 快取:

使用 SQLExecutionBuilder 進行快取:
最佳化策略:商業邏輯最佳化
商業邏輯最佳化著重於重組 Blu AWS Age 自動產生的程式碼,以更符合現代架構功能。當產生的程式碼維護與舊版大型主機程式碼相同的邏輯結構時,這會變得必要,這可能不適用於現代系統。目標是改善效能,同時維持與原始應用程式的功能等效性。
此最佳化方法不僅止於簡單的 API 調校和快取策略。它涉及應用程式處理資料和與資料庫互動方式的變更。常見的最佳化包括避免簡單更新不必要的讀取操作、移除備援資料庫呼叫,以及重組資料存取模式,以更符合現代應用程式架構。以下是幾個範例:
直接在資料庫中更新資料。 使用直接 SQL 更新而非具有迴圈的多個 DAOManager 操作來重組您的業務邏輯。例如,下列程式碼 (左側) 會進行多個資料庫呼叫,並使用過多的記憶體。具體而言,它會在迴圈中使用多個資料庫讀取和寫入操作、個別更新而非批次處理,以及在每次反覆運算時建立不必要的物件。
下列最佳化程式碼 (右側) 使用單一 Direct SQL 更新操作。具體而言,它使用單一資料庫呼叫,而不是多個呼叫,而且不需要迴圈,因為所有更新都是在單一陳述式中處理。此最佳化可提供更好的效能和資源使用率,並降低複雜性。它可防止 SQL 注入,提供更好的查詢計劃快取,並有助於提高安全性。

注意
一律使用參數化查詢來防止 SQL 插入,並確保適當的交易管理。
減少備援資料庫呼叫。備援資料庫呼叫可能會大幅影響應用程式效能,尤其是在迴圈中發生時。簡單但有效的最佳化技術是避免多次重複相同的資料庫查詢。下列程式碼比較示範將
retrieve()資料庫呼叫移至迴圈之外如何防止重複執行相同的查詢,進而提高效率。
使用 SQL 子句減少資料庫呼叫
JOIN。實作 SQLExecutionBuilder,將對資料庫的呼叫降至最低。SQLExecutionBuilder 提供更多對 SQL 產生的控制,對於 DAOManager 無法有效處理的複雜查詢特別有用。例如,下列程式碼使用多個 DAOManager 呼叫:List<Employee> employees = daoManager.readAll(); for(Employee emp : employees) { Department dept = deptManager.readById(emp.getDeptId()); // Additional call for each employee Project proj = projManager.readById(emp.getProjId()); // Another call for each employee processEmployeeData(emp, dept, proj); }最佳化程式碼在 SQLExecutionBuilder 中使用單一資料庫呼叫:
SQLExecutionBuilder builder = new SQLExecutionBuilder(); builder.append("SELECT e.*, d.name as dept_name, p.name as proj_name"); builder.append("FROM employee e"); builder.append("JOIN department d ON e.dept_id = d.id"); builder.append("JOIN project p ON e.proj_id = p.id"); builder.append("WHERE e.status = ?", "ACTIVE"); List<Map<String, Object>> results = builder.execute(); // Single database call for(Map<String, Object> result : results) { processComplexData(result); }
同時使用最佳化策略
這三種策略可協同運作:APIs提供有效率的資料存取工具、快取可減少重複資料擷取的需求,而商業邏輯最佳化可確保以最有效的方式使用這些 APIs。這些最佳化的定期監控和調整可確保持續提升效能,同時維持現代化應用程式的可靠性和功能。成功的關鍵在於了解根據您的應用程式特性和效能目標,何時以及如何套用每個策略。
工具
JProfiler
是一種 Java 分析工具,專為開發人員和效能工程師而設計。它可分析 Java 應用程式,並協助識別效能瓶頸、記憶體流失和執行緒問題。JProfiler 提供 CPU、記憶體和執行緒分析,以及資料庫和 Java 虛擬機器 (JVM) 監控,以深入了解應用程式行為。 注意
作為 JProfiler 的替代方案,您可以使用 Java VisualVM
。這是適用於 Java 應用程式的免費開放原始碼效能分析和監控工具,可提供 CPU 用量、記憶體消耗、執行緒管理和垃圾收集統計資料的即時監控。由於 Java VisualVM 是內建的 JDK 工具,因此對於基本分析需求,比 JProfiler 更具成本效益。 pgAdmin
是 PostgreSQL 的開放原始碼管理和開發工具。它提供圖形界面,可協助您建立、維護和使用資料庫物件。您可以使用 pgAdmin 來執行各種任務,從撰寫簡單的 SQL 查詢到開發複雜的資料庫。其功能包括強調 SQL 編輯器的語法、伺服器端程式碼編輯器、SQL、殼層和批次任務的排程代理程式,以及支援新手和經驗豐富的 PostgreSQL 使用者的所有 PostgreSQL 功能。
最佳實務
識別效能熱點:
開始最佳化之前,請記錄基準效能指標。
根據業務需求設定明確的效能改善目標。
進行基準測試時,請停用詳細記錄,因為它可能會影響效能。
設定效能測試套件並定期執行。
使用最新版本的 pgAdmin。(舊版不支援
EXPLAIN查詢計畫。)針對基準測試,請在最佳化完成後分離 JProfiler,因為它會增加延遲。
針對基準測試,請務必以啟動模式而非偵錯模式執行伺服器,因為偵錯模式會增加延遲。
最佳化策略:
在
application.yaml檔案中設定 SetMaxResults 值,根據您的系統規格指定適當大小的批次。根據資料磁碟區和記憶體限制來設定 SetMaxResults 值。
只有在後續呼叫為 時,才將 SetOnGreatorOrEqual 變更為 SetOnEqual
.readNextEqual()。在批次寫入或更新操作中,請分別處理最後一個批次,因為它可能小於設定的批次大小,且寫入或更新操作可能會遺漏。
快取:
在 中引入用於快取的欄位
processImpl,其會隨著每次執行而變動,應一律在該 的內容中定義processImpl。這些欄位也應該使用doReset()或cleanUp()方法清除。當您實作記憶體內快取時,請調整快取的大小。儲存在記憶體中的非常大型快取可能會佔用所有資源,這可能會影響應用程式的整體效能。
SQLExecutionBuilder:
對於您計劃在 SQLExecutionBuilder 中使用的查詢,請使用金鑰名稱,例如
PROGRAMNAME_STATEMENTNUMBER。當您使用 SQLExecutionBuilder 時,請務必檢查
Sqlcod欄位。此欄位包含一個值,指定查詢是否正確執行或遇到任何錯誤。使用參數化查詢來防止 SQL 注入。
商業邏輯最佳化:
在重組程式碼時維持功能等效性,並針對相關程式子集執行迴歸測試和資料庫比較。
維護分析快照以進行比較。
史詩
| 任務 | Description | 所需的技能 |
|---|---|---|
安裝和設定 JProfiler。 |
| 應用程式開發人員 |
安裝和設定 pgAdmin。 | 在此步驟中,您會安裝並設定資料庫用戶端來查詢資料庫。此模式使用 PostgreSQL 資料庫和 pgAdmin 做為資料庫用戶端。如果您使用的是另一個資料庫引擎,請遵循對應資料庫用戶端的文件。
| 應用程式開發人員 |
| 任務 | Description | 所需的技能 |
|---|---|---|
在 AWS Blu Age 應用程式中啟用 SQL 查詢記錄。 | 在 AWS Blu Age 應用程式的 | 應用程式開發人員 |
產生和分析查詢 | 如需詳細資訊,請參閱架構一節。 | 應用程式開發人員 |
建立 JProfiler 快照以分析效能緩慢的測試案例。 |
| 應用程式開發人員 |
分析 JProfiler 快照以識別效能瓶頸。 | 請依照下列步驟分析 JProfiler 快照。
如需使用 JProfiler 的詳細資訊,請參閱架構一節和 JProfiler 文件 | 應用程式開發人員 |
| 任務 | Description | 所需的技能 |
|---|---|---|
實作最佳化之前,請先建立效能基準。 |
| 應用程式開發人員 |
| 任務 | Description | 所需的技能 |
|---|---|---|
最佳化讀取呼叫。 | 使用 DAOManager SetMaxResults 方法最佳化資料擷取。如需此方法的詳細資訊,請參閱架構一節。 | 應用程式開發人員,DAOManager |
重構商業邏輯,以避免對資料庫進行多次呼叫。 | 使用 SQL | 應用程式開發人員,SQLExecutionBuilder |
重構程式碼以使用快取來降低讀取呼叫的延遲。 | 如需此技術的資訊,請參閱 架構一節中的快取。 | 應用程式開發人員 |
重寫使用多個 DAOManager 操作進行簡單更新操作的無效程式碼。 | 如需直接在資料庫中更新資料的詳細資訊,請參閱 架構一節中的商業邏輯最佳化。 | 應用程式開發人員 |
| 任務 | Description | 所需的技能 |
|---|---|---|
反覆驗證每個最佳化變更,同時保持功能等效性。 |
注意使用基準指標做為參考,可確保準確測量每個最佳化的影響,同時維護系統可靠性。 | 應用程式開發人員 |
疑難排解
| 問題 | 解決方案 |
|---|---|
當您執行現代應用程式時,您會看到錯誤為 的例外狀況 | 若要解決此問題:
|
您已新增索引,但沒有看到任何效能改善。 | 請依照下列步驟來確保查詢引擎正在使用 索引:
|
您遇到out-of-memory例外狀況。 | 驗證程式碼是否釋出資料結構所保留的記憶體。 |
批次寫入操作會導致資料表中的記錄遺失 | 檢閱程式碼,以確保在批次計數不為零時執行額外的寫入操作。 |
SQL 記錄不會出現在應用程式日誌中。 |
|
相關資源
使用 AWS Blu Age 自動重構應用程式 (AWS Mainframe Modernization 使用者指南)
