本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
溫度擴展
在分類問題中,假設預測機率 (softmax 輸出) 代表預測類別的真實正確性機率。不過,雖然此假設對於 10 年前的模型而言可能很合理,但對於現今的現代神經網路模型而言,並非如此 (Guo et al. 2017 年)。模型預測機率與模型預測信心之間的連線中斷,將導致現代神經網路模型無法應用於實際問題,如同決策系統。確切了解模型預測的可信度分數,是建置強大且值得信任的機器學習應用程式所需的最關鍵風險控制設定之一。
現代神經網路模型通常具有大型架構,並具有數百萬個學習參數。在這類模型中預測機率的分佈通常高度偏向 1 或 0,這表示模型過於自信,而且這些機率的絕對值可能毫無意義。(此問題與資料集中是否存在類別不平衡無關。) 過去十年來,我們透過後製步驟開發了各種用於建立預測可信度分數的校正方法,以重新校正模型的未處理機率。本節描述一種名為溫度擴展的校正方法,這是一種簡單但有效的技術,用於重新校正預測機率 (Guo et al. 2017 年)。溫度擴展是 Platt Logistic Scaling (Platt 1999) 的單一參數版本。
溫度擴展使用單一純量參數 T > 0,其中 T 是溫度,在套用 softmax 函數之前重新調整日誌分數,如下圖所示。由於所有類別都使用相同的 T,具有擴展的 softmax 輸出與未擴展的輸出具有單調關係。當 T = 1 時,您可以使用預設 softmax 函數來復原原始機率。在 T > 1 的過度可信模型中,重新校正的概率值低於原始概率,且平均分佈在 0 和 1 之間。
為訓練模型取得最佳溫度 T 的方法,是透過將保留驗證資料集的負面日誌可能性降至最低。
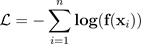
我們建議您將溫度擴展方法整合為模型訓練程序的一部分:模型訓練完成後,使用驗證資料集擷取溫度值 T,然後在 softmax 函數中使用 T 重新調整對數值。根據使用 BERT 型模型的文字分類任務實驗,溫度 T 通常會在 1.5 到 3 之間擴展。
下圖說明了溫度擴展方法,在將 logit 分數傳遞至 softmax 函數之前,套用溫度值 T。

溫度擴展的校正機率大約可以代表模型預測的可信度分數。這可以透過建立可靠性圖表 (Guo et al. 2017) 來量化評估,此圖表代表預期準確度的分佈與預測機率的分佈之間的一致性。
溫度擴展也被評估為量化已校正機率中總預測不確定性的有效方法,但它在資料偏離等情況下擷取流行不確定性並不強大 (Ovadia et al. 2019)。考慮到實作的便利性,我們建議您將溫度擴展套用至深度學習模型輸出,以建置強大的解決方案來量化預測不確定性。
