本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
# 資料取用者
在集中式目錄使用 共用資料之後,資料消費者會使用來自資料生產者的資料 AWS Lake Formation。下圖顯示資料湖中的兩個資料取用者。
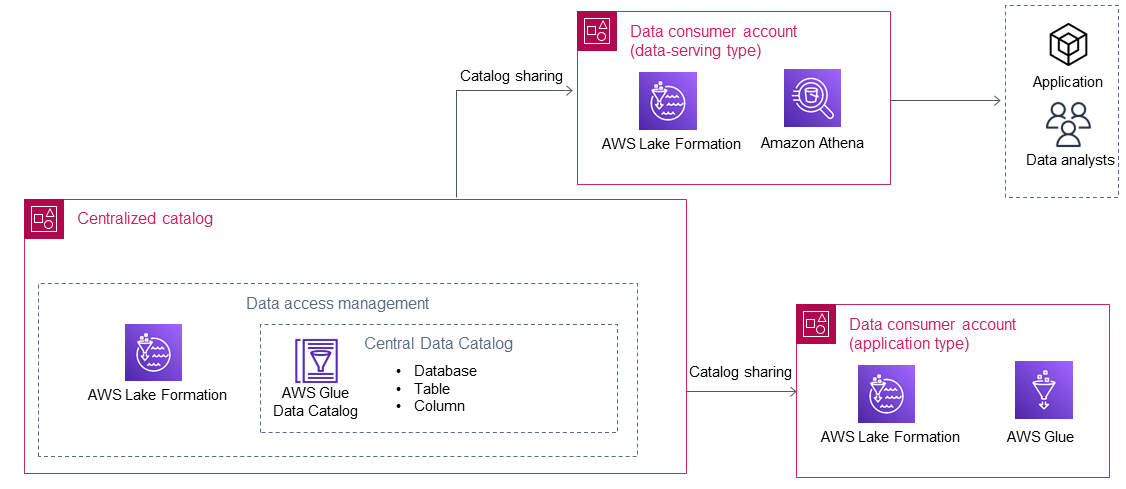
資料取用者有兩種類型:*應用程式*和*資料服務*。下表說明這兩種類型。
| | |
| --- |--- |
| 應用程式類型 | 應用程式資料消費者自行執行應用程式 AWS 帳戶。應用程式會使用 AWS Identity and Access Management (IAM) 角色從資料生產者存取共用資料,然後根據其邏輯進行處理。
一般而言,這種類型的資料消費者具有滿足應用程式需求的規範性資料需求。 |
| 資料服務類型 | 資料服務資料取用者通常適用於沒有自己的個人 (例如,資料分析師或資料科學家) 和應用程式 (例如,商業智慧應用程式) AWS 帳戶。
多個資料服務資料取用者可以存在於一個組織的資料湖中。例如,不同的業務單位可能會選擇設定自己的資料服務資料取用者,以協助使用者從資料湖取用資料。這些資料消費者在其 AWS 帳戶 (例如,與 相關聯的 IAM 角色[AWS IAM Identity Center](https://docs.aws.amazon.com//singlesignon/latest/userguide/what-is.html)) 中設定自己的 IAM 角色主體,供資料消費者帳戶中的最終使用者用來透過 AWS 服務 (例如,[Amazon Athena](https://docs.aws.amazon.com//athena/latest/ug/what-is.html)) 存取共用資料。
一般而言,這種類型的資料取用者具有廣泛且持續增加的資料需求。 |
AWS Lake Formation 是資料取用者用於跨帳戶資料共用和存取集中型錄的最重要 AWS 服務。在集中式目錄共用資料庫之後,可在資料消費者帳戶中的 Lake Formation 中使用共用資源。然後,資料取用者帳戶中的本機 IAM 主體可以存取資料,並在必要時獲得資料生產者的許可。然後,與 Lake Formation 整合 AWS 的服務可以使用共用資料 (例如,Amazon Athena 和 AWS Glue)。您可以使用下列 AWS 服務來存取資料取用者帳戶中的共用資料:
+ [Amazon Athena](https://docs.aws.amazon.com//athena/latest/ug/what-is.html) 是一種互動式查詢服務,可協助使用標準 SQL 直接分析 Amazon Simple Storage Service (Amazon S3) 中的資料。如需 Athena 和 Lake Formation 的詳細資訊,請參閱 Amazon Athena [文件中的 Athena 如何存取向 Lake Formation 註冊的資料](https://docs.aws.amazon.com//athena/latest/ug/lf-athena-access.html)。
+ [Amazon Redshift Spectrum](https://docs.aws.amazon.com//redshift/latest/dg/c-getting-started-using-spectrum.html) 可協助您從 Amazon S3 中的檔案有效率地查詢和擷取結構化和半結構化資料,而不必將資料載入 Amazon Redshift 資料表。如需 Redshift Spectrum 和 Lake Formation 的詳細資訊,請參閱 Amazon Redshift 文件中的[搭配使用 Redshift Spectrum 與 Lake Formation](https://docs.aws.amazon.com//redshift/latest/dg/spectrum-lake-formation.html)。
+ [AWS Glue](https://docs.aws.amazon.com//glue/latest/dg/what-is-glue.html) 是一種全受管擷取、轉換和載入 (ETL) 服務,可讓您以簡單且經濟實惠的方式分類資料、清理資料、擴充資料,並在不同的資料存放區和資料串流之間可靠地移動資料。如果 AWS Glue ETL 任務的相關聯 IAM 角色具有必要的存取許可,則可以存取 Lake Formation 管理的資料湖資料。
+ [Amazon EMR](https://docs.aws.amazon.com//emr/latest/ManagementGuide/emr-what-is-emr.html) 可協助執行大數據架構 (例如 [Apache Hadoop](https://aws.amazon.com//elasticmapreduce/details/hadoop) 和 [Apache Spark](https://aws.amazon.com//elasticmapreduce/details/spark)) 來處理和分析大量資料。如需 Amazon EMR 和 Lake Formation 的詳細資訊,請參閱[《Amazon EMR 文件》中的整合 Amazon EMR 與 Lake Formation](https://docs.aws.amazon.com//emr/latest/ManagementGuide/emr-lake-formation.html)。
+ [Amazon Quick](https://docs.aws.amazon.com//quicksight/latest/user/welcome.html) 是一種可擴展、無伺服器、可嵌入且採用機器學習 (ML) 技術的商業智慧服務,可用來分析和視覺化資料湖中的資料。如需 Quick 和 Lake Formation 的詳細資訊,請參閱 Quick 文件中的[透過 Lake Formation 授權連線](https://docs.aws.amazon.com//quicksight/latest/user/lake-formation.html)。
+ [Amazon SageMaker AI Data Wrangler (Data Wrangler)](https://docs.aws.amazon.com//sagemaker/latest/dg/data-wrangler.html) 可減少彙總和準備 ML 資料所需的時間。如需 Data Wrangler 和 Lake Formation 的詳細資訊,請參閱 [Amazon SageMaker AI 文件中的使用 Amazon SageMaker AI Data Wrangler 準備 ML](https://docs.aws.amazon.com//sagemaker/latest/dg/data-wrangler.html) 資料。 Amazon SageMaker