本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
處理階段
Amazon Textract 會將 PDF 檔案內容擷取為下游應用程式無法直接使用的字串 (例如,透過彙總數字來產生統計資料)。正確識別和轉換的資料值是必要的,因為下游應用程式可以更輕鬆地使用這些值 (例如,將成本趨勢繪製為時間序列)。若要實作 PDF 檔案處理,每個新 PDF 檔案類型中的一個 PDF 檔案必須透過 Amazon Textract 處理一次,然後產生 JSON 格式Template的檔案。
在 中啟動 AWS Lambda 函數後擷取階段,它會執行下圖所示的步驟。
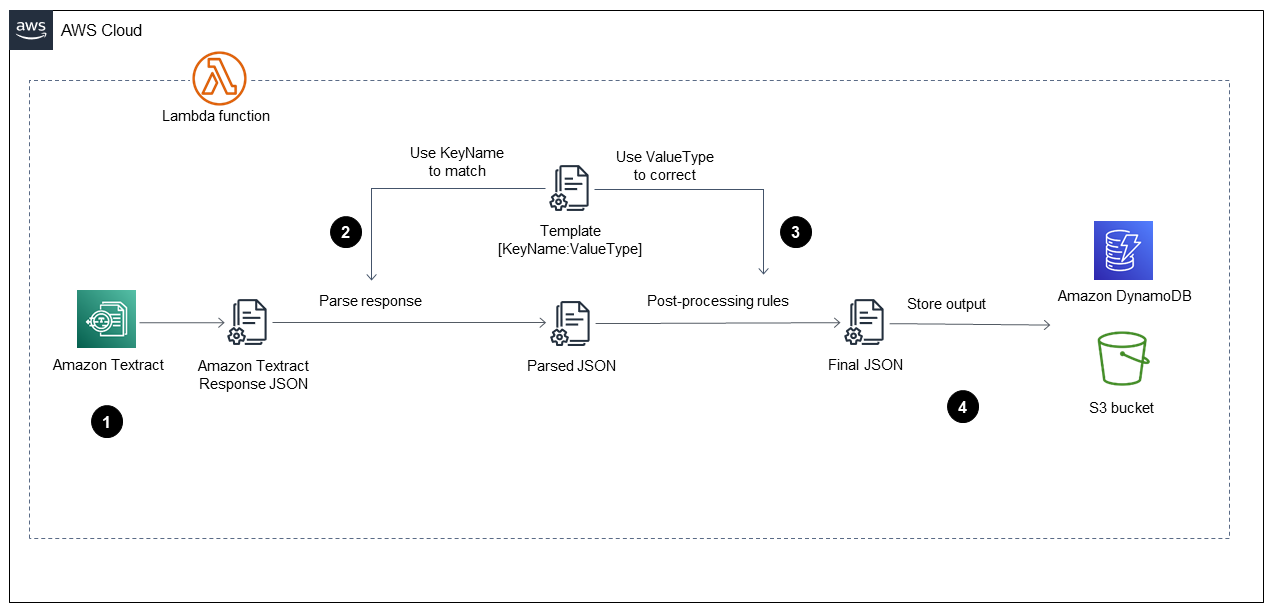
圖表顯示實作下列步驟的 Lambda 函數:
-
呼叫 Amazon Textract 來處理 PDF 檔案、擷取內容,並傳回 JSON 格式的檔案。
-
使用具有每個欄位正確索引鍵名稱和值類型的預先定義
TemplateJSON 檔案,來取得 JSON 檔案並剖析表單和資料表。此程序提供剖析的 JSON 檔案。 -
套用後製處理規則,並使用
TemplateJSON 檔案來更正剖析的 JSON 檔案中的每個值。這會產生FinalJSON 檔案。預先定義的TemplateJSON 檔案可以存放在 S3 儲存貯體中。 -
將
FinalJSON 檔案存放在 Amazon DynamoDB 中,做為每個 PDF 檔案的一個記錄,以及 S3 輸出儲存貯體中每個 PDF 檔案的一個 JSON 檔案。
如需使用 Amazon Textract 自動從 PDF 檔案擷取內容並將其處理為乾淨輸出step-by-step工作流程,請參閱 AWS 規範指引網站上的使用 Amazon Textract 從 PDF 檔案自動擷取內容的模式。模式使用範本比對技術來正確識別必要欄位、金鑰名稱和資料表,然後將後置處理更正套用至每個資料類型。
處理階段的最佳實務
使用下列四個最佳實務,以確保成功的處理階段:
-
為您要處理的每個 PDF 檔案類型建立範本 JSON 檔案。您可以將這些不同的範本 JSON 檔案存放在由 Lambda 函數呼叫的 S3 儲存貯體中。如果您想要在一個 Lambda 函數中處理不同的 PDF 檔案類型,您應該為每個 PDF 檔案類型使用唯一的識別符 (例如,S3 儲存貯體中的 PDF 檔案類型的資料夾名稱)。叫用 Lambda 函數之後,它會擷取適當的範本 JSON 檔案並進行處理。
-
設定機制以準確追蹤 Lambda 函數中每個步驟的狀態。例如,您可以在 Amazon Textract 呼叫後、最終 JSON 檔案儲存至 Amazon DynamoDB 資料表時,或 PDF 檔案儲存至 S3 儲存貯體時,新增
Success的狀態。您也可以建立單獨的 DynamoDB 資料表,以在不同步驟中追蹤每個 PDF 檔案的狀態,這可提供程序的可見性。 -
當您批次處理許多 PDF 檔案時,透過自動重試失敗的操作來管理限流和中斷連線。如果您的連線中斷或超過每秒交易數上限 (TPS),Amazon Textract 中可能會發生限流。如需自動重試失敗操作的詳細資訊和步驟,請參閱 Amazon Textract 文件中的處理調節呼叫和中斷連線。
-
如果您有包含多個頁面的 PDF 檔案,您可以使用非同步操作來處理整個檔案,或將 PDF 檔案分成個別頁面、使用同步操作來處理每個頁面,然後合併每個頁面的結果。如需非同步操作的完整程式碼實作,請參閱《Amazon Textract 文件》中的偵測和分析多頁文件中的文字。如需使用同步操作的詳細資訊,請參閱《Amazon Textract 文件》中的偵測和分析單頁文件中的文字。
