本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
就地遷移
就地遷移不需要重寫所有資料檔案。相反地,會產生 Iceberg 中繼資料檔案,並將其連結到您現有的資料檔案。此方法通常更快且更具成本效益,尤其是具有相容檔案格式的大型資料集或資料表,例如 Parquet、Avro 和 ORC。
注意
遷移至 Amazon S3 Tables 時,無法使用就地遷移。
Iceberg 提供實作就地遷移的兩個主要選項:
-
使用快照
程序建立新的 Iceberg 資料表,同時保持來源資料表不變。如需詳細資訊,請參閱 Iceberg 文件中的快照表 。 -
使用遷移
程序建立新的 Iceberg 資料表以取代來源資料表。如需詳細資訊,請參閱 Iceberg 文件中的遷移資料表 。雖然此程序適用於 Hive Metastore (HMS),但目前與 不相容 AWS Glue Data Catalog。本指南稍後章節中的複寫資料表遷移程序 AWS Glue Data Catalog提供了使用 Data Catalog 實現類似結果的解決方法。
使用 snapshot或 執行就地遷移後migrate,某些資料檔案可能會保持未遷移狀態。這通常發生在寫入器在遷移期間或之後繼續寫入來源資料表時。若要將這些剩餘檔案納入 Iceberg 資料表,您可以使用 add_files
假設您有一個在 Athena 中建立並填入的 Parquet 型products資料表,如下所示:
CREATE EXTERNAL TABLE mydb.products ( product_id INT, product_name STRING ) PARTITIONED BY (category STRING) STORED AS PARQUET LOCATION 's3://amzn-s3-demo-bucket/products/'; INSERT INTO mydb.products VALUES (1001, 'Smartphone', 'electronics'), (1002, 'Laptop', 'electronics'), (2001, 'T-Shirt', 'clothing'), (2002, 'Jeans', 'clothing');
下列各節說明如何搭配此資料表使用 snapshot和 migrate 程序。
選項 1:快照程序
snapshot 程序會建立新的 Iceberg 資料表,其名稱不同,但會複寫來源資料表的結構描述和分割。此操作會在動作期間和之後讓來源資料表完全保持不變。它有效地建立資料表的輕量型複本,這對於測試案例或資料探勘特別有用,而不會危及對原始資料來源的修改。此方法會啟用轉換期間,其中原始資料表和 Iceberg 資料表都會保持可用 (請參閱本節結尾的備註)。測試完成後,您可以將所有寫入器和讀取器轉換為新資料表,藉此將新的 Iceberg 資料表移至生產環境。
您可以在任何 Amazon EMR 部署模型 (例如,Amazon EMR on EC2、Amazon EMR on EKS、EMR Serverless) 和 中使用 Spark 來執行snapshot程序 AWS Glue。
若要使用 snapshot Spark 程序測試就地遷移,請遵循下列步驟:
-
啟動 Spark 應用程式並使用下列設定設定 Spark 工作階段:
-
"spark.sql.extensions":"org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" -
"spark.sql.catalog.spark_catalog":"org.apache.iceberg.spark.SparkSessionCatalog" -
"spark.sql.catalog.spark_catalog.type":"glue" -
"spark.hadoop.hive.metastore.client.factory.class":"com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory"
-
-
執行
snapshot程序以建立新的 Iceberg 資料表,指向原始資料表資料檔案:spark.sql(f""" CALL system.snapshot( source_table => 'mydb.products', table => 'mydb.products_iceberg', location => 's3://amzn-s3-demo-bucket/products_iceberg/' ) """ ).show(truncate=False)輸出資料框架包含
imported_files_count(已新增的檔案數目)。 -
透過查詢來驗證新資料表:
spark.sql(f""" SELECT * FROM mydb.products_iceberg LIMIT 10 """ ).show(truncate=False)
備註
-
執行程序後,來源資料表上的任何資料檔案修改都會將產生的資料表擲出不同步。您新增的新檔案不會出現在 Iceberg 資料表中,而您移除的檔案會影響 Iceberg 資料表中的查詢功能。若要避免同步問題:
-
如果新的 Iceberg 資料表適用於生產用途,請停止寫入原始資料表的所有程序,並將其重新導向至新資料表。
-
如果您需要轉換期間或新的 Iceberg 資料表用於測試目的,請參閱本節稍後的就地遷移後保持 Iceberg 資料表同步,以取得維護資料表同步的指引。
-
-
當您使用
snapshot程序時,gc.enabled屬性會在建立的 Iceberg 資料表的資料表屬性false中設定為 。此設定禁止expire_snapshots、remove_orphan_files或 等動作DROP TABLE搭配PURGE選項,這會實際刪除資料檔案。仍然允許不直接影響來源檔案的 Iceberg 刪除或合併操作。 -
若要讓您的新 Iceberg 資料表完全正常運作,而實際刪除資料檔案的動作沒有限制,您可以將
gc.enabled資料表屬性變更為true。不過,此設定將允許影響來源資料檔案的動作,這可能會損毀對原始資料表的存取。因此,只有在您不再需要維護原始資料表的功能時,才能變更gc.enabled屬性。例如:spark.sql(f""" ALTER TABLE mydb.products_iceberg SET TBLPROPERTIES ('gc.enabled' = 'true'); """)
選項 2:遷移程序
程序migrate會建立新的 Iceberg 資料表,其名稱、結構描述和分割與來源資料表相同。當此程序執行時,它會鎖定來源資料表並將其重新命名為 <table_name>_BACKUP_(或 backup_table_name 程序參數指定的自訂名稱)。
注意
如果您將drop_backup程序參數設定為 true,則原始資料表將不會保留為備份。
因此,migrate資料表程序要求在執行動作之前停止影響來源資料表的所有修改。執行migrate程序之前:
-
停止與來源資料表互動的所有寫入器。
-
修改原生不支援 Iceberg 的讀取器和寫入器,以啟用 Iceberg 支援。
例如:
-
Athena 可在不修改的情況下繼續運作。
-
Spark 需要:
-
要包含在 classpath 中的 Iceberg Java Archive (JAR) 檔案 (請參閱本指南稍早章節中的在 Amazon EMR 中使用 Iceberg 和使用 Iceberg AWS Glue)。
-
下列 Spark 工作階段目錄組態 (用於新增 Iceberg 支援
SparkSessionCatalog,同時維護非 Iceberg 資料表的內建目錄功能):-
"spark.sql.extensions":"org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" -
"spark.sql.catalog.spark_catalog":"org.apache.iceberg.spark.SparkSessionCatalog" -
"spark.sql.catalog.spark_catalog.type":"glue" -
"spark.hadoop.hive.metastore.client.factory.class":"com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory"
-
-
執行程序後,您可以使用新的 Iceberg 組態重新啟動寫入器。
目前, migrate 程序與 不相容 AWS Glue Data Catalog,因為 Data Catalog 不支援 RENAME操作。因此,建議您只在使用 Hive Metastore 時使用此程序。如果您使用的是 Data Catalog,請參閱下一節以取得替代方法。
您可以跨所有 Amazon EMR 部署模型 (Amazon EMR on EC2、Amazon EMR on EKS、EMR Serverless) 執行migrate此程序 AWS Glue,但需要已設定的 Hive Metastore 連線。建議選擇 Amazon EMR on EC2,因為它提供內建的 Hive 中繼存放區組態,可將設定複雜性降至最低。
若要從使用 Hive Metastore 設定的 EC2 叢集上的 Amazon EMR 使用 migrate Spark 程序測試就地遷移,請遵循下列步驟:
-
啟動 Spark 應用程式並設定 Spark 工作階段以使用 Iceberg Hive 目錄實作。例如,如果您使用的是
pysparkCLI:pyspark --conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions --conf spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog --conf spark.sql.catalog.spark_catalog.type=hive -
在 Hive 中繼存放區中建立
products資料表。這是來源資料表,已存在於典型的遷移中。-
在 Hive 中繼存放區中建立
products外部 Hive 資料表,以指向 Amazon S3 中的現有資料:spark.sql(f""" CREATE EXTERNAL TABLE products ( product_id INT, product_name STRING ) PARTITIONED BY (category STRING) STORED AS PARQUET LOCATION 's3://amzn-s3-demo-bucket/products/'; """ ) -
使用
MSCK REPAIR TABLE命令新增現有的分割區:spark.sql(f""" MSCK REPAIR TABLE products """ ) -
透過執行
SELECT查詢確認資料表包含資料:spark.sql(f""" SELECT * FROM products """ ).show(truncate=False)輸出範例:

-
-
使用 Iceberg
migrate程序:df_res=spark.sql(f""" CALL system.migrate( table => 'default.products' ) """ ) df_res.show()輸出資料框架包含
migrated_files_count(新增至 Iceberg 資料表的檔案數目):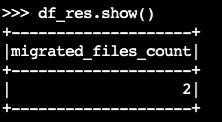
-
確認已建立備份資料表:
spark.sql("show tables").show()輸出範例:
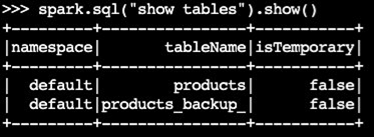
-
透過查詢 Iceberg 資料表來驗證操作:
spark.sql(f""" SELECT * FROM products """ ).show(truncate=False)
備註
-
執行程序後,如果未正確設定 Iceberg 支援,查詢或寫入來源資料表的所有目前程序都會受到影響。因此,我們建議您遵循下列步驟:
-
在遷移之前使用來源資料表停止所有程序。
-
執行遷移。
-
使用適當的 Iceberg 設定重新啟用程序。
-
-
如果在遷移程序期間發生資料檔案修改 (新增檔案或移除檔案),產生的資料表將會不同步。如需同步選項,請參閱本節稍後的就地遷移後保持 Iceberg 資料表同步。
在 中複寫資料表遷移程序 AWS Glue Data Catalog
您可以在 AWS Glue Data Catalog (備份原始資料表並以 Iceberg 資料表取代) 中複寫遷移程序的結果,方法如下:
-
使用 快照程序建立新的 Iceberg 資料表,指向原始資料表的資料檔案。
-
在 Data Catalog 中備份原始資料表中繼資料:
-
使用 GetTable API 擷取來源資料表定義。
-
使用 GetPartitions API 擷取來源資料表分割區定義。
-
使用 CreateTable API 在 Data Catalog 中建立備份資料表。
-
使用 CreatePartition 或 BatchCreatePartition API,將分割區註冊至 Data Catalog 中的備份資料表。
-
-
將
gc.enabledIceberg 資料表屬性變更為false,以啟用完整資料表操作。 -
捨棄原始資料表。
-
在資料表根位置的中繼資料資料夾中找到 Iceberg 資料表中繼資料 JSON 檔案。
-
使用 register_table
程序搭配原始資料表名稱和 snapshot程序所建立metadata.json檔案的位置,在 Data Catalog 中註冊新資料表:spark.sql(f""" CALL system.register_table( table => 'mydb.products', metadata_file => '{iceberg_metadata_file}' ) """ ).show(truncate=False)
在就地遷移後保持 Iceberg 資料表同步
add_files 此程序提供靈活的方式來將現有資料整合到 Iceberg 資料表中。具體而言,它會在 Iceberg 的中繼資料層中參考其絕對路徑,以註冊現有的資料檔案 (例如 Parquet 檔案)。根據預設,程序會從所有資料表分割區新增檔案至 Iceberg 資料表,但您可以選擇性地從特定分割區新增檔案。這種選擇性方法在幾種情況下特別有用:
-
初始遷移後將新分割區新增至來源資料表時。
-
資料檔案在初始遷移後新增至現有分割區或從現有分割區中移除時。不過,重新新增修改的分割區需要先刪除分割區。本節稍後將提供有關此項目的詳細資訊。
以下是在已執行就地遷移 (snapshot 或 migrate) 之後使用 add_file 程序的一些考量,以讓新的 Iceberg 資料表與來源資料檔案保持同步:
-
將新資料新增至來源資料表中的新分割區時,請使用
add_files程序搭配partition_filter選項,以選擇性地將這些新增項目納入 Iceberg 資料表:spark.sql(f""" CALL system.add_files( source_table => 'mydb.products', table => 'mydb.products_iceberg', partition_filter => map('category', 'electronics') ).show(truncate=False)或:
spark.sql(f""" CALL system.add_files( source_table => '`parquet`.`s3://amzn-s3-demo-bucket/products/`', table => 'mydb.products_iceberg', partition_filter => map('category', 'electronics') ).show(truncate=False) -
當您指定
partition_filter選項時,add_files程序會掃描整個來源資料表或特定分割區中的檔案,並嘗試將找到的所有檔案新增至 Iceberg 資料表。根據預設,check_duplicate_files程序屬性會設為true,如果 Iceberg 資料表中已有檔案,則會防止程序執行。這很重要,因為沒有內建選項可略過先前新增的檔案,而停用check_duplicate_files會導致新增檔案兩次,進而建立重複項目。將新檔案新增至來源資料表時,請遵循下列步驟:-
對於新分割區,使用
add_files搭配partition_filter,僅從新分割區匯入檔案。 -
對於現有的分割區,請先從 Iceberg 資料表刪除分割區,然後
add_files為該分割區重新執行,並指定partition_filter。例如:# We initially perform in-place migration with snapshot spark.sql(f""" CALL system.snapshot( source_table => 'mydb.products', table => 'mydb.products_iceberg', location => 's3://amzn-s3-demo-bucket/products_iceberg/' ) """ ).show(truncate=False) # Then on the source table, some new files were generated under the category='electronics' partition. Example: spark.sql(""" INSERT INTO mydb.products VALUES (1003, 'Tablet', 'electronics') """) # We delete the modified partition from the Iceberg table. Note this is a metadata operation only spark.sql(""" DELETE FROM mydb.products_iceberg WHERE category = 'electronics' """) # We add_files from the modified partition spark.sql(""" CALL system.add_files( source_table => 'mydb.products', table => 'mydb.products_iceberg', partition_filter => map('category', 'electronics') ) """).show(truncate=False)
-
注意
每個add_files操作都會產生具有附加資料的新 Iceberg 資料表快照。
選擇正確的就地遷移策略
若要選擇最佳的就地遷移策略,請考慮下表中的問題。
問題 |
建議 |
說明 |
|---|---|---|
您是否要在不重寫資料的情況下快速遷移,同時讓 Hive 和 Iceberg 資料表可供測試或逐步轉換使用? |
|
使用 |
您是否使用 Hive 中繼存放區,並且想要立即將 Hive 資料表取代為 Iceberg 資料表,而無需重寫資料? |
|
使用 注意:此選項與 Hive Metastore 相容,但與 不相容 AWS Glue Data Catalog。 使用 |
您是否正在使用 AWS Glue Data Catalog ,並且想要立即將 Hive 資料表取代為 Iceberg 資料表,而無需重寫資料? |
調整 |
複寫
注意:此選項需要手動處理中繼資料備份的 AWS Glue API 呼叫。 使用 |
