本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
上的 Apache Iceberg 參考架構 AWS
本節提供在不同使用案例中套用最佳實務的範例,例如批次擷取,以及結合批次和串流資料擷取的資料湖。
每天批次擷取
對於這個假設性使用案例,假設您的 Iceberg 資料表每晚擷取信用卡交易。每個批次只包含增量更新,必須合併到目標資料表。每年收到幾次完整的歷史資料。在此案例中,我們建議使用下列架構和組態。
注意:這只是範例。最佳組態取決於您的資料和需求。
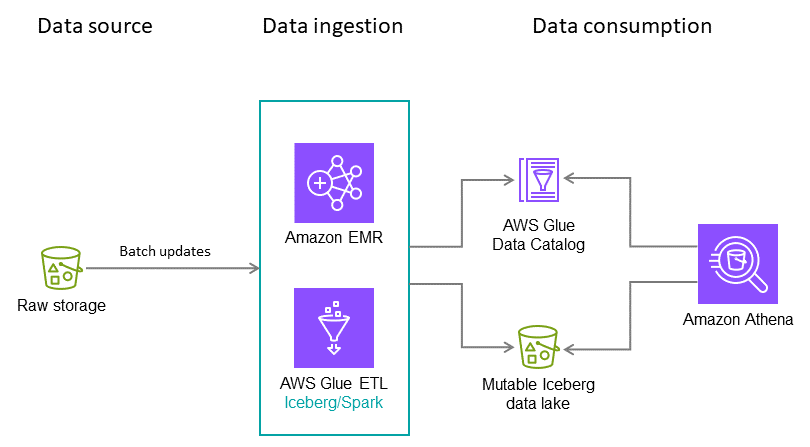
建議:
-
檔案大小:128 MB,因為 Apache Spark 任務會以 128 MB 區塊處理資料。
-
寫入類型:copy-on-write。如本指南先前所述,此方法有助於確保以讀取最佳化的方式寫入資料。
-
分割區變數:year/month/day。在我們的假設使用案例中,我們最常查詢最近的資料,雖然我們偶爾會執行過去兩年資料的完整資料表掃描。分割的目標是根據使用案例的需求,推動快速讀取操作。
-
排序順序:時間戳記
-
資料目錄: AWS Glue Data Catalog
結合批次和近乎即時擷取的資料湖
您可以在 Amazon S3 上佈建資料湖,以跨帳戶和區域共用批次和串流資料。如需架構圖表和詳細資訊,請參閱 AWS 部落格文章使用 Apache Iceberg 建置交易資料湖 AWS Glue,以及使用 AWS Lake Formation 和 Amazon Athena 進行跨帳戶資料共用
