本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
平行化和散佈收集模式
許多進階推理和產生任務 – 例如摘要大型文件、評估多個解決方案路徑,或比較不同的觀點 – 受益於平行執行提示。需要可擴展性、回應能力和容錯能力時,傳統的循序工作流程會短暫。為了克服這個問題,可以使用事件驅動的散射集模式來重新構想 LLM 型平行化,其中任務會動態散發到自動代理程式,並以智慧方式合成結果。
下圖是 LLM 平行化工作流程的範例:
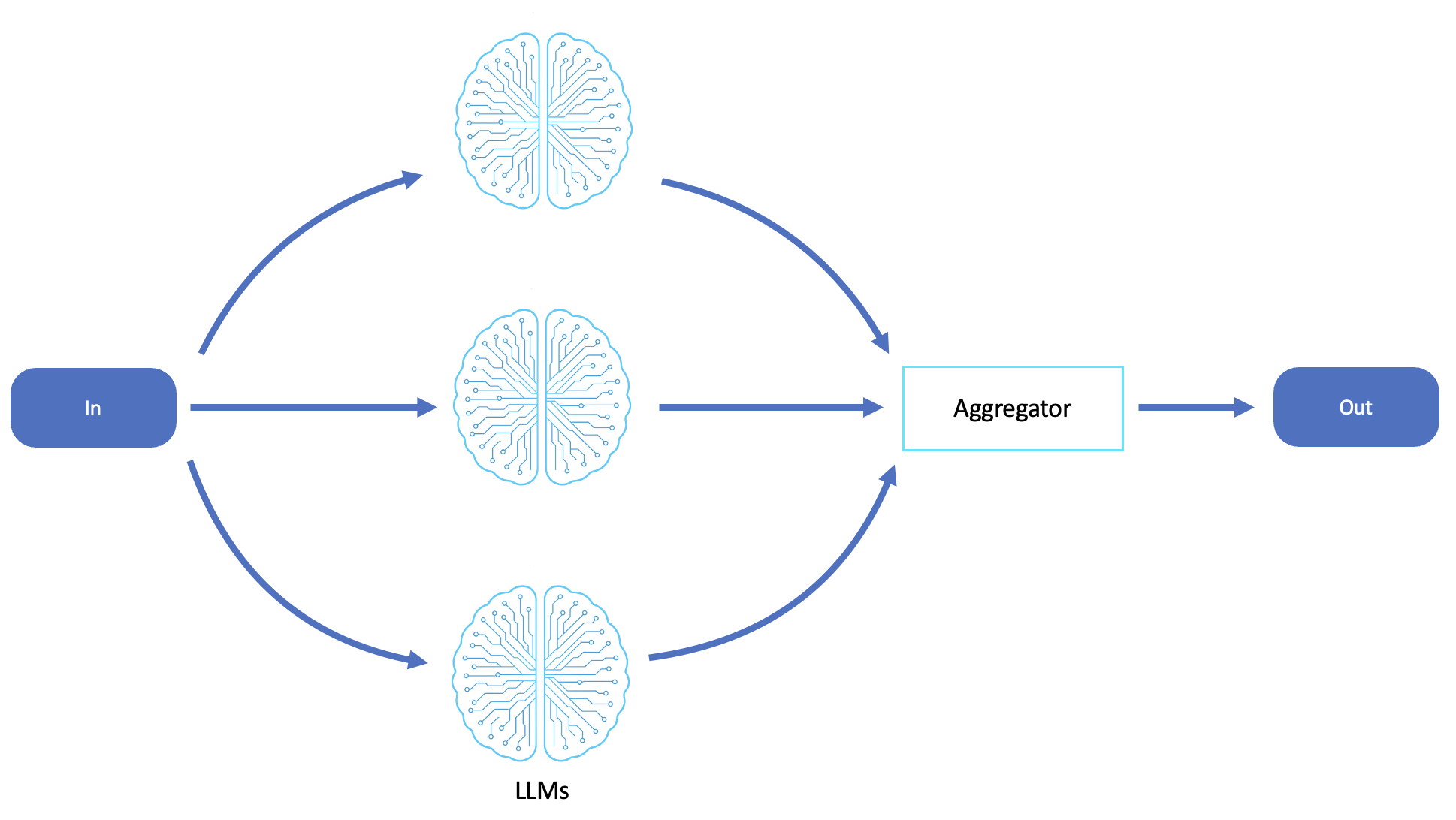
散佈集合
在分散式系統中,散佈集合模式會平行將任務傳送至多個服務或處理單位,等待其回應,然後將結果彙總到合併的輸出中。與廣發不同,散佈集會進行協調,因為它預期回應,通常會套用邏輯來合併、比較和選取結果。
平行化和散佈集合的常見實作包括下列項目:
-
AWS Step Functions 映射平行任務執行的狀態
-
AWS Lambda 並行,協調多個調用函數的結果
-
具有相互關聯 IDs Amazon EventBridge
-
使用 Amazon Simple Storage Service (Amazon S3)、Amazon DynamoDB 或佇列來管理廣發並收集結果的自訂控制器模式
下圖是散佈集的範例:
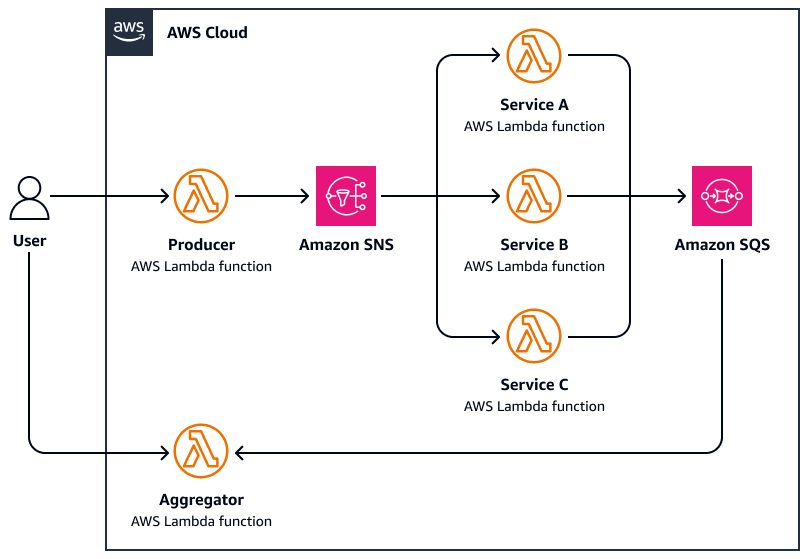
-
使用者將請求傳送至中央協調器函數,透過將平行訊息發佈至 Amazon Simple Notification Service (Amazon SNS) 主題來散佈任務。
-
每個訊息都包含任務中繼資料,並會路由至專門的工作者 AWS Lambda。
-
每個工作者都會 AWS Lambda 獨立處理其指派的子任務 (例如,查詢外部 API、處理文件和分析資料)。
-
結果會寫入常用儲存層,例如 Amazon Simple Queue Service (Amazon SQS)。
-
彙總器函數會等待所有回應完成,然後執行下列動作:
-
收集和彙總結果 (例如,合併摘要、選取最佳相符項目)
-
傳送最終回應或觸發下游工作流程
-
散佈收集模式的常見使用案例包括下列項目:
-
聯合搜尋
-
價格比較引擎
-
彙總資料分析
-
多模型推論
LLM 型平行處理 (散佈加法認知)
在代理程式系統中,平行處理透過將子任務分散到多個 LLM 呼叫或代理程式來緊密反映散佈集,每個子任務都會獨立推理一部分的問題。傳回的結果會由彙總程序收集和合成,通常是另一個 LLM 或控制器代理程式。
代理程式平行處理
-
客服人員提交請求「總結這 10 個報告的洞見」。
-
它會將報告分散至 10 個平行 LLM 摘要任務。
-
傳回所有摘要時,代理程式會執行下列動作:
-
將摘要彙總為統一的簡報
-
識別主題或矛盾
-
將合成的輸出傳送給使用者
-
此代理程式工作流程可實現可擴展性、模組化和適應性平行推理。這非常適合需要高認知輸送量的使用案例。
下圖是代理程式平行化的範例:
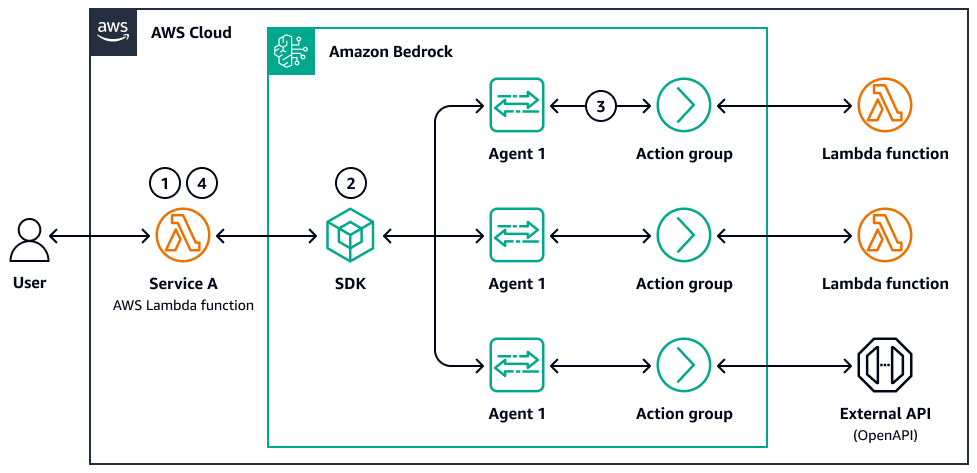
-
使用者提交分段查詢或文件集。
-
控制器 AWS Lambda 或步驟函數會分配子任務。每個任務都會使用自己的提示叫用 Amazon Bedrock LLM 呼叫或子代理程式。
-
當呼叫和子任務完成時,結果會儲存 (例如,在 Amazon S3 或記憶體存放區中),而彙總步驟會合併、比較或篩選輸出。
-
系統會將最終回應傳回給使用者或下游代理程式。
此系統具有分散式推理迴圈,具有可追蹤性、容錯能力和選用的結果加權或選擇邏輯。
要點
代理程式平行化使用散佈集合模式來分配 LLM 任務,從而實現平行處理和智慧型結果合成。
